[논문리뷰] Pixie: Fast and Generalizable Supervised Learning of 3D Physics from Pixels
arXiv 2025. [Paper] [Page]
Long Le, Ryan Lucas, Chen Wang, Chuhao Chen, Dinesh Jayaraman, Eric Eaton, Lingjie Liu
University of Pennsylvania | MIT
20 Aug 2025
Introduction
본 논문에서는 직접적인 supervised learning을 통해 geometry, 외형, 물리적 성질의 학습을 통합하는 새로운 프레임워크인 Pixie를 제안하였다. 본 논문의 접근 방식은 인간이 직관적으로 물리 법칙을 이해하는 방식에서 영감을 받았다. 바람에 흔들리는 나무를 볼 때, 인간은 각 좌표 $(x, y, z)$에 대한 강성(stiffness) 값을 기억하는 대신, 나무와 유사한 시각적 특징을 가진 물체가 힘이 가해졌을 때 특정 방식으로 행동한다는 것을 학습한다. 시각적 단서를 통한 이러한 물리적 이해를 통해 완전히 새로운 맥락에서 다른 나무나 풀과 같은 다른 식물의 움직임을 예측할 수 있다.
따라서 본 논문의 핵심은 CLIP에서 추출한 것과 같은 풍부한 3D visual feature를 활용하여 직접적인 supervised learning과 feed-forward 방식으로 material을 예측하는 것이다. 학습된 모델은 시각적 패턴과 물리적 행동을 연관시켜 여러 장면에서 빠른 inference와 일반화를 가능하게 한다.
저자들은 1,624개의 3D object와 10개의 semantic 클래스에 걸친 material들로 구성된 데이터셋인 PixieVerse를 큐레이션하고 레이블링하였다. 저자들은 Gemini와 CLIP 등의 사전 학습된 모델을 distillation하여 데이터셋에 통합하는 다단계 반자동 데이터 레이블링 프로세스로 PixieVerse를 만들었다. PixieVerse는 3D 에셋과 material 레이블 쌍으로 구성된 가장 큰 규모의 오픈소스 데이터셋이다.
PixieVerse에서 학습된 feed-forward 네트워크는 test-time 최적화 방식보다 1.46~4.39배 더 우수하고 훨씬 빠른 material field를 예측할 수 있다. 사전 학습된 visual feature를 활용하여, Pixie는 합성 데이터로만 학습되었음에도 불구하고 실제 장면에 대한 zero-shot 일반화를 수행할 수 있다.
Method
1. Pixie Physics Learning
Problem Formulation
본 논문의 목표는 정적 장면 \(\mathcal{I} = \{I_k\}_{k=1}^K\)와 이들의 공동 카메라 사양 $\Pi$를 입력으로 받아 continuous한 3차원 material field로의 매핑을 배우는 것이다.
\[\begin{equation} f_\theta \, : \, (\mathcal{I}, \Pi) \, \mapsto \, \hat{\mathcal{M}} \end{equation}\]장면 경계 내의 모든 점 $\textbf{p} \in \mathbb{R}^3$에 대해, material field는 다음을 반환한다.
\[\begin{equation} \hat{\mathcal{M}} (\textbf{p}) = \left( \hat{\ell} (\textbf{p}), \hat{E} (\textbf{p}), \hat{\nu} (\textbf{p}), \hat{d} (\textbf{p}) \right) \end{equation}\](\(\hat{\ell} : \mathbb{R}^3 \mapsto \{1, \ldots, L\}\)은 discrete한 material 클래스, $\hat{E}, \hat{\nu}, \hat{d} : \mathbb{R}^3 \mapsto \mathbb{R}$는 각각 continuous한 Young’s modulus, Poisson’s ratio, 밀도 값)
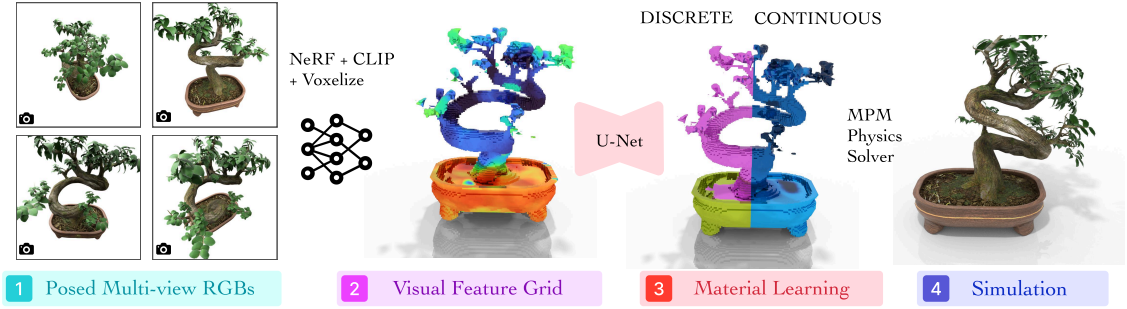
2D 이미지에서 3D 재료로의 매핑을 직접 학습하는 것은 분명 간단하지도 않고 효율적이지 않다. 그 대신, 본 논문에서는 2D 이미지와 3D visual feature 사이의 중간 매핑을 표현하기 위해 풍부한 시각적 prior를 가진 정제된 feature field를 활용하고, 그런 다음 별도의 U-Net 아키텍처를 사용하여 3D visual feature와 material 사이의 매핑을 계산한다.
3D Visual Feature Distillation
본 논문에서는 색상과 밀도 외에도 뷰에 독립적인 feature 벡터를 예측하기 위해 기존 NeRF 표현을 보완하였다.
\[\begin{equation} F_\theta \, : \, (\textbf{x}, \textbf{d}) \; \mapsto \; \left( \textbf{f}(\textbf{x}), c (\textbf{x}, \textbf{d}), \sigma (\textbf{x}) \right) \end{equation}\]($c \in \mathbb{R}^3$와 \(\sigma \in \mathbb{R}_{\ge 0}\)는 NeRF의 색상 및 radiance 출력, $\textbf{f} \in \mathbb{R}^d$는 visual semantics를 캡처하는 고차원 descriptor)
표준 볼륨 렌더링으로 색상과 feature를 렌더링하고 각각 RGB 이미지와 이미지에서 추출한 픽셀별 CLIP 임베딩을 사용하여 학습시킨다. 학습 후, 알려진 장면 경계 내에서 feature field는를 voxelize하여 $N \times N \times N \times D$ 차원의 그리드 $F_G$를 얻는다. 여기서 격자 크기 $N$은 64이고 $D$는 CLIP feature 차원인 768이며, $F_G$는 material 네트워크의 입력으로 사용된다.
Material Grid Learning
Material 학습 네트워크 $f_M$은 feature projector $f_P$와 U-Net $f_U$로 구성되어 있다. Feature projector $f_P$는 3개의 3D convolution layer로 구성되어 768차원의 CLIP feature를 64차원 매니폴드로 매핑한다. 그런 다음, U-Net 아키텍처 $f_U$를 사용하여 projection된 feature grid $F_G$에서 material grid \(\hat{\mathcal{M}}_G (\textbf{p})\)로의 매핑을 학습시킨다. 이는 material field \(\hat{\mathcal{M}} (\textbf{p})\)의 voxelize된 버전이다. $f_P$와 $f_U$는 cross-entropy loss와 MSE loss를 통해 end-to-end로 공동으로 학습되어 discrete한 material 클래스와 continuous한 material 값을 예측한다.
Voxel grid가 매우 sparse하며, 약 98%의 voxel이 배경이다. 단순하게 학습된 $f_M$은 항상 배경을 예측하도록 학습한다. 따라서 NeRF 밀도가 threshold $\alpha = 0.01$ 미만인 모든 voxel을 필터링하여 occupancy mask grid $\mathbb{M} \in \mathbb{R}^{N \times N \times N}$을 별도로 계산한다. Loss는 점유된 voxel에만 적용된다. 구체적으로, loss는 다음과 같다.
\[\begin{aligned} \mathcal{L}_\textrm{sup} = \frac{1}{N_\textrm{occ}} \mathbb{M} (\textbf{p}) [ & \lambda \cdot \textrm{CE} (\hat{\ell} (\textbf{p}), \ell^\textrm{GT} (\textbf{p})) + (\hat{E} (\textbf{p}) - E^\textrm{GT} (\textbf{p}))^2 \\ &+ (\hat{\nu} (\textbf{p}) - \nu^\textrm{GT} (\textbf{p}))^2 + (\hat{d} (\textbf{p}) - d^\textrm{GT} (\textbf{p}))^2 ] \end{aligned}\](\(N_\textrm{occ} = \sum_{\textbf{p} \in \mathcal{G}} \mathbb{M}(\mathbb{p})\)는 그리드에서 점유된 총 voxel 수, $\textrm{CE}$는 cross-entropy loss)
Physics Simulation
물리 시뮬레이션을 위해 Material Point Method (MPM)를 사용한다. MPM solver는 초기 입자의 포인트 클라우드와 예측된 물질 특성, 외력을 사용하여 입자의 변형과 변환을 시뮬레이션한다. NeRF 모델에서 입자를 샘플링하는 것도 가능하지만, 3D Gaussian Splatting (3DGS)을 사용하면 각 Gaussian을 자연스럽게 MPM 입자로 생각할 수 있으므로 3DGS를 사용하는 것이 더 쉽다. 따라서 카메라 포즈를 알고 있는 멀티뷰 RGB 이미지에서 3DGS 모델을 별도로 학습시킨다. 그런 다음, 예측된 material grid의 material 특성을 nearest neighbor interpolation을 통해 3DGS 모델로 변환한다.
2. PixieVerse Dataset

저자들은 3D 에셋의 가장 큰 오픈소스 데이터셋인 Objaverse에서 object들을 가져와 PixieVerse를 구성하였다. Objaverse에는 material 주석이 없으므로, 저자들은 Gemini-2.5-Pro와 같은 VLM, 정제된 CLIP feature field, 사람이 직접 튜닝한 in-context 물리 예제들을 활용하는 반자동 다단계 레이블링 파이프라인을 개발하였다. PixieVerse는 10가지 semantic 클래스로 구성된다.
Experiments
1. Synthetic Scene Experiments
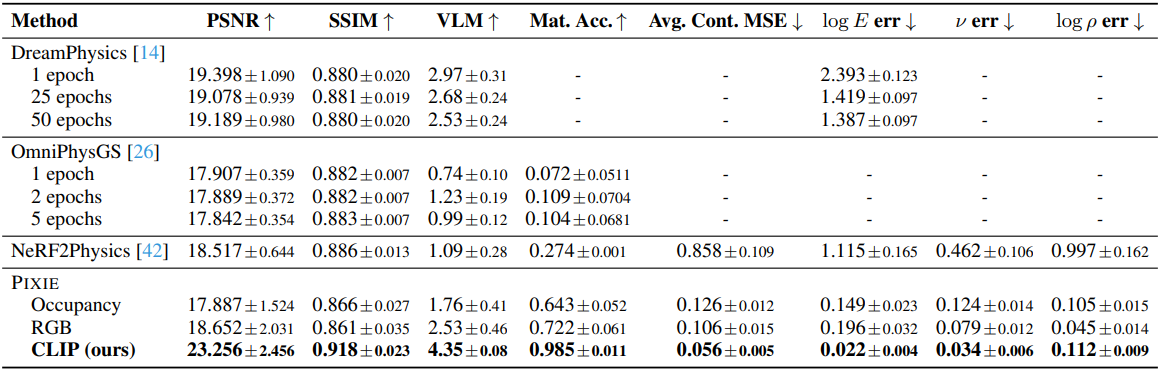
다음은 PixieVerse에 대한 정량적 비교 결과이다.
다음은 PixieVerse에 대한 정성적 비교 결과이다.

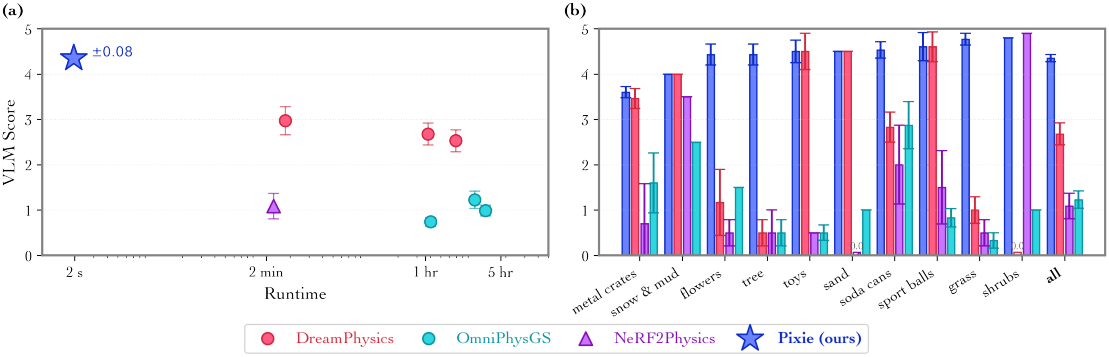
다음은 Gemini-2.5-Pro로 평가한 VLM score를 비교한 것이다. (PixieVerse)
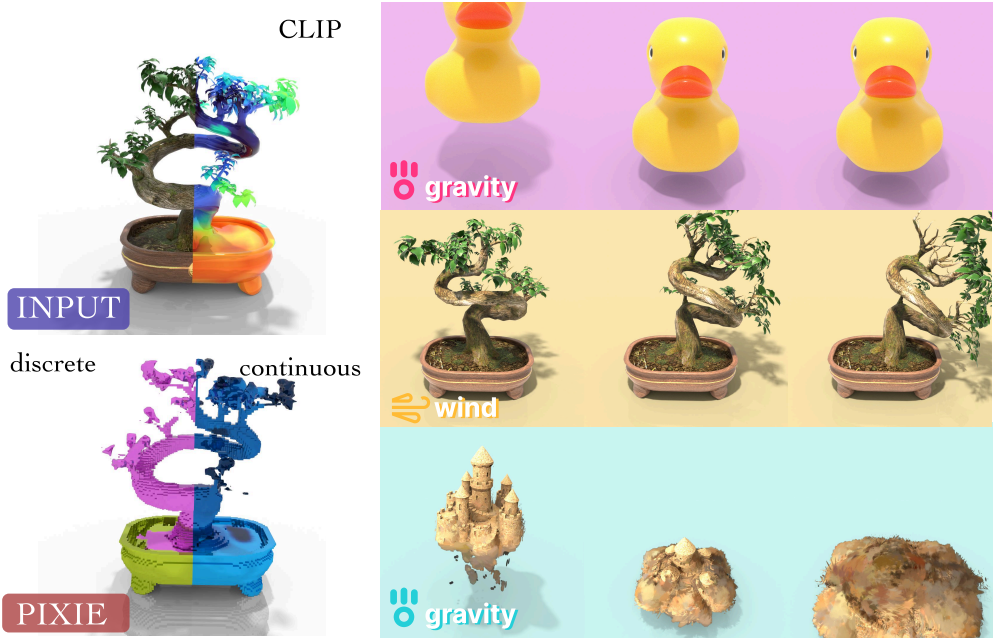
2. Zero-shot Generalization to Real-World Scenes
다음은 현실 장면에 대한 zero-shot 일반화 예시들이다.
