[논문리뷰] PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
ICLR 2024. [Paper] [Page] [Github] [Demo]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, Zhenguo Li
Huawei Noah’s Ark Lab | Dalian University of Technology | HKU | HKUST
30 Sep 2023

Introduction
최근 DALL·E 2, Imagen, Stable Diffusion과 같은 text-to-image (T2I) 생성 모델의 발전으로 사실적인 이미지 합성의 새로운 시대가 열리면서 수많은 다운스트림 애플리케이션에 큰 영향을 미치고 있다.
그러나 이러한 고급 모델을 학습시키려면 엄청난 계산 리소스가 필요하다. 예를 들어, SDv1.5 학습에는 6천 A100 GPU day가 필요하며 약 32만 달러의 비용이 든다. 그리고 최신 대형 모델인 RAPHAEL은 약 308만 달러가 필요하며 6만 A100 GPU day가 필요하다. 또한 학습은 상당한 이산화탄소 배출량에 기여한다. 예를 들어 RAPHAEL의 학습으로 인해 한 사람이 7년 동안 배출하는 양에 해당하는 35톤의 이산화탄소가 배출되었다. 이러한 막대한 비용은 해당 모델에 접근하는 데 상당한 장벽을 부과하여 심각한 장애를 초래한다. 이러한 문제점들을 고려할 때 다음과 같은 중요한 질문이 제기된다.
저렴한 리소스 소비로 고품질 이미지 생성 모델을 개발할 수 있을까?
본 논문에서는 현재의 SOTA 이미지 생성 모델과 비슷한 이미지 생성 품질을 유지하면서 학습의 계산량 요구를 크게 줄이는 PixArt-$\alpha$를 소개하였으며, 세 가지 핵심 디자인을 제안하였다.
- 학습 전략 분해: 복잡한 text-to-image 생성 task를 이미지의 픽셀 분포 학습, 텍스트-이미지 정렬 학습, 이미지의 미적 품질 향상이라는 세 가지 간소화된 하위 task로 분해한다. 첫 번째 하위 task에서는 T2I 모델을 저비용 클래스 조건부 모델로 초기화하여 학습 비용을 크게 줄이는 것을 제안하였다. 두 번째 및 세 번째 하위 task의 경우 사전 학습과 fine-tuning으로 구성된 학습 패러다임을 제안하였다. 즉, 정보 밀도가 풍부한 텍스트-이미지 쌍 데이터에 대한 사전 학습을 수행한 다음 우수한 미적 품질을 갖춘 데이터로 fine-tuning하여 학습 효율성을 높인다.
- 효율적인 T2I Transformer: Diffusion Transformer (DiT)를 기반으로 cross-attention 모듈을 통합하여 텍스트 조건을 주입하고 계산 집약적인 클래스 조건부 분기를 간소화하여 효율성을 향상시킨다. 또한 조정된 text-to-image 모델이 원래 클래스 조건부 모델의 파라미터를 직접 로드할 수 있도록 하는 reparameterization 기술을 도입하였다. 결과적으로 이미지 분포에 대해 ImageNet에서 배운 사전 지식을 활용하여 T2I Transformer에 대한 합리적인 초기화를 제공하고 학습을 가속화할 수 있다.
- 정보가 풍부한 데이터: LAION과 같은 기존 텍스트-이미지 쌍 데이터셋은 텍스트 캡션의 정보 제공 콘텐츠 부족과 심각한 롱테일 효과 등 여러 단점이 드러났다. 이러한 결함으로 인해 T2I 모델의 학습 효율성이 크게 저하되고 안정적인 텍스트-이미지 정렬을 학습하기 위해 수백만 번의 iteration이 발생한다. 이 문제를 해결하기 위해 저자들은 SOTA 비전-언어 모델(LLaVA)을 활용하여 SAM에 캡션을 생성하는 자동 라벨링 파이프라인을 제안하였다. SAM 데이터셋은 풍부하고 다양한 객체 컬렉션으로 인해 유리하며, 텍스트-이미지 정렬 학습에 더 적합한 정보 밀도가 높은 텍스트-이미지 쌍을 생성하는 데 이상적인 리소스이다.
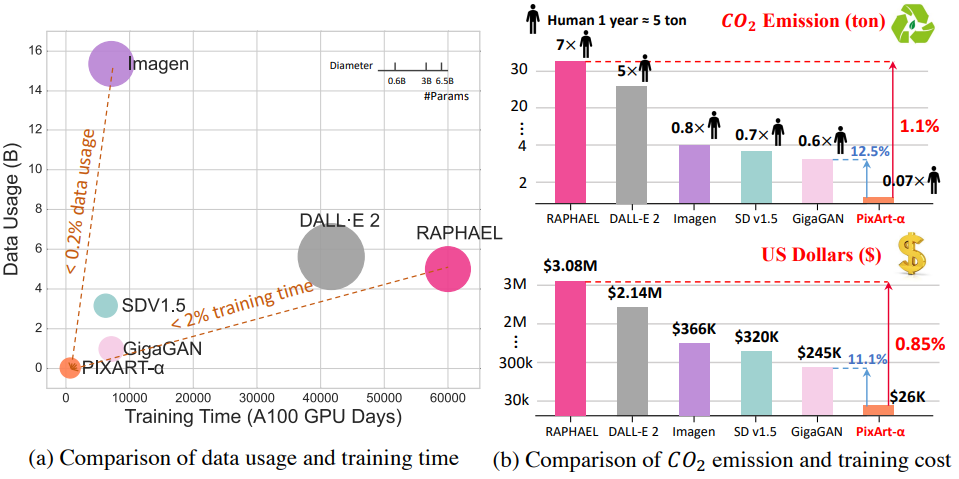
PixArt-$\alpha$의 효과적인 디자인은 675 A100 GPU day와 2.6만 달러의 비용으로 모델에 대한 놀라운 학습 효율성을 제공한다. PixArt-$\alpha$는 Imagen에 비해 학습 데이터 볼륨을 0.2% 미만으로 소비하고 RAPHAEL에 비해 학습 시간은 2% 미만이다. RAPHAEL과 비교하면 학습 비용은 1%에 불과하여 약 300만 달러를 절약한다. PIXART-α는 기존 SOTA T2I 모델에 비해 우수한 이미지 품질과 semantic 일치를 제공하며 T2I-CompBench에서의 성능도 semantic 제어 측면에서 장점을 입증하였다.
Method
1. 동기
T2I 학습이 느린 이유는 학습 파이프라인과 데이터라는 두 가지 측면이 있다.
T2I 생성 task는 세 가지 측면으로 분해될 수 있다.
- 픽셀 의존성 캡처: 사실적인 이미지 생성에는 이미지 내의 복잡한 픽셀 수준 의존성을 이해하고 분포를 캡처하는 task가 포함된다.
- 텍스트와 이미지 사이의 정렬: 텍스트 설명과 정확하게 일치하는 이미지를 생성하는 방법을 이해하려면 정확한 정렬 학습이 필요하다.
- 높은 미적 품질: 충실한 텍스트 설명 외에도 미적 품질은 생성된 이미지의 또 다른 중요한 특성이다.
현재 방법은 이 세 가지 문제를 하나로 엮어 방대한 양의 데이터를 사용하여 처음부터 직접 학습하므로 비효율적인 학습이 된다. 이 문제를 해결하기 위해 본 논문은 이러한 측면을 세 단계로 분리한다.
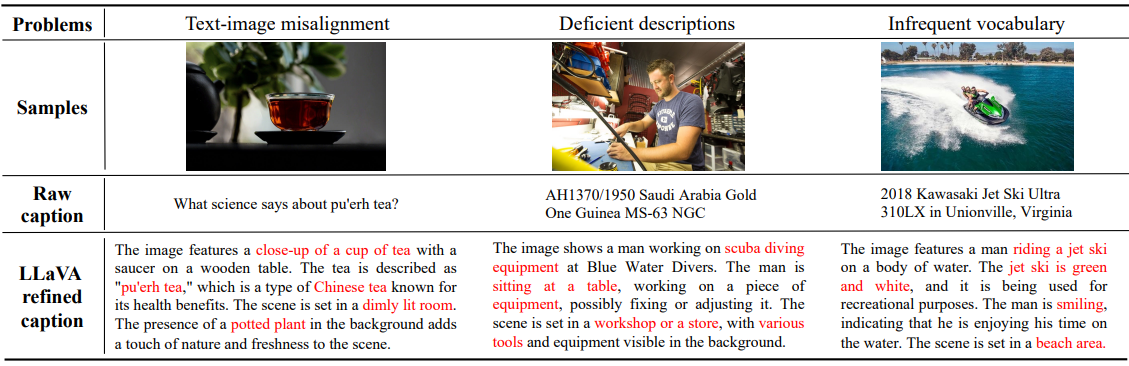
위 그림에 볼 수 있듯이 또 다른 문제는 현재 데이터셋의 캡션 품질에 있다. 현재의 텍스트-이미지 쌍은 종종 텍스트-이미지 정렬 불량, 설명 부족, 드물게 다양한 어휘 사용, 낮은 품질의 데이터 포함으로 인해 어려움을 겪는다. 이러한 문제로 인해 학습이 어려워지고 텍스트와 이미지 간의 안정적인 정렬을 달성하기 위해 불필요하게 수백만 번의 iteration이 발생한다. 본 논문은 이러한 문제를 해결하기 위해 정확한 이미지 캡션을 생성하는 혁신적인 자동 라벨링 파이프라인을 도입한다.
2. 학습 전략 분해
모델의 생성 능력은 다양한 데이터 유형을 사용하여 학습을 3단계로 분할하여 점진적으로 최적화할 수 있다.
Stage1: 픽셀 의존성 학습
현재 클래스 기반 접근 방식은 개별 이미지에서 의미상 일관되고 합리적인 픽셀을 생성하는 데 있어 모범적인 성능을 보여주었다. 클래스 조건부 이미지 생성 모델을 학습하는 것은 상대적으로 쉽고 저렴하다. 또한 저자들은 적절한 초기화를 통해 학습 효율성을 크게 높일 수 있다는 사실을 발견했다. 따라서 ImageNet에서 사전 학습된 모델로 모델을 강화하고 모델 아키텍처는 사전 학습된 가중치와 호환되도록 설계되었다.
Stage2: 텍스트-이미지 정렬 학습
사전 학습된 클래스 조건부 이미지 생성에서 text-to-image 생성으로 전환하는 데 있어 주요 과제는 크게 증가된 텍스트 개념과 이미지 간의 정확한 정렬을 달성하는 방법이다.
이 정렬 프로세스는 시간이 많이 걸릴 뿐만 아니라 본질적으로 까다롭다. 이 프로세스를 효율적으로 촉진하기 위해 저자들은 개념 밀도가 높은 정확한 텍스트-이미지 쌍으로 구성된 데이터셋을 구성하였다. 정확하고 정보가 풍부한 데이터를 사용함으로써 학습 프로세스는 각 iteration에서 더 많은 수의 명사를 효율적으로 처리하는 동시에 이전 데이터셋에 비해 모호성을 상당히 줄일 수 있다. 이러한 전략적 접근 방식을 통해 네트워크는 텍스트 설명과 이미지를 효과적으로 정렬할 수 있다.
Stage3: 고해상도 미적 이미지 생성
세 번째 단계에서는 고해상도 이미지 생성을 위해 고품질 미적 데이터를 사용하여 모델을 fine-tuning한다. 놀랍게도, 이전 단계에서 확립된 강력한 사전 지식으로 인해 이 단계의 적응 과정이 훨씬 더 빠르게 수렴된다.
학습 과정을 여러 단계로 분리하면 학습의 어려움이 크게 완화되고 매우 효율적인 학습이 가능하다.
3. 효율적인 T2I Transformer
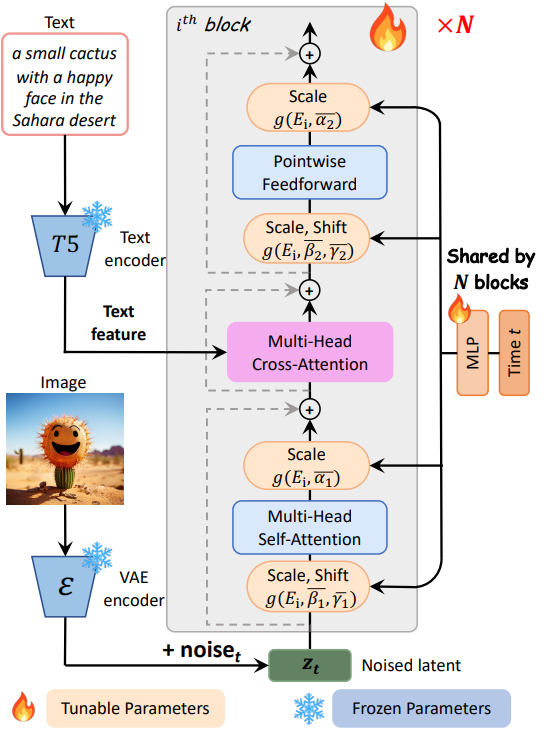
PIXART-$\alpha$는 Diffusion Transformer (DiT)를 기본 아키텍처로 채택하고 위 그림에 설명된 대로 T2I의 고유한 과제를 처리하기 위해 Transformer 블록을 혁신적으로 커스터마이징한다. 몇 가지 전용 디자인은 다음과 같다.
Cross-Attention layer
Multi-head cross-attention layer를 DiT 블록에 통합한다. 모델이 언어 모델에서 추출된 텍스트 임베딩과 유연하게 상호 작용할 수 있도록 self-attention layer와 feed-forward layer 사이에 위치시킨다. 사전 학습된 가중치를 용이하게 하기 위해 cross-attention layer의 출력 projection layer를 0으로 초기화하여 효과적으로 항등 매핑 역할을 하고 이후 레이어에 대한 입력을 보존한다.
AdaLN-single
저자들은 DiT의 adaptive normalization layer (adaLN) 모듈의 linear projection이 파라미터의 상당 부분(27%)을 차지하는 것을 발견했다. 본 논문의 T2I 모델에는 클래스 조건이 사용되지 않기 때문에 그렇게 많은 수의 파라미터는 유용하지 않다. 따라서 저자들은 독립적인 제어를 위해 첫 번째 블록의 입력으로 시간 임베딩만 사용하는 adaLN-single을 제안하였다.
구체적으로, $i$번째 블록에서 $S^{(i)} = [\beta_1^{(i)}, \beta_2^{(i)}, \gamma_1^{(i)}, \gamma_2^{(i)}, \alpha_1^{(i)}, \alpha_2^{(i)}]$를 adaLN의 모든 scale 및 shift 파라미터의 튜플이라고 가정하자. DiT에서 $S^{(i)}$는 블록별 MLP $S^{(i)} = f^{(i)} (c+t)$를 통해 구하며, 여기서 $c$와 $t$는 각각 클래스 조건과 시간 임베딩을 나타낸다. 그러나 adaLN-single에서는 scale 및 shift의 글로벌 집합 하나가 모든 블록에서 공유되는 첫 번째 블록에서만 $\bar{S} = f(t)$로 계산된다. 그런 다음, $S^{(i)}$는 $S^{(i)} = g(\bar{S}, E^{(i)})$로 얻어진다. 여기서 $g$는 합산 함수이고, $E^{(i)}$는 $\bar{S}$와 동일한 모양을 갖는 레이어별 학습 가능한 임베딩이며, 다양한 블록의 scale 및 shift 파라미터를 적응적으로 조정한다.
Re-parameterization
앞서 언급한 사전 학습된 가중치를 활용하기 위해 모든 $E^{(i)}$는 선택된 $t$에 대해 $c$가 없는 DiT와 동일한 $S^{(i)}$를 생성하는 값으로 초기화된다 (경험적으로 $t = 500$). 이 디자인은 사전 학습된 가중치와의 호환성을 유지하면서 레이어별 MLP를 글로벌 MLP와 레이어별 학습 가능한 임베딩으로 효과적으로 대체한다.
Timestep 정보를 위한 글로벌 MLP와 레이어별 임베딩, 텍스트 정보 처리를 위한 cross-attention layer를 통합하면 모델의 생성 능력을 유지하면서 크기를 효과적으로 줄일 수 있다.
4. 데이터셋 구성
LAION 데이터셋의 캡션은 텍스트-이미지 정렬 불량, 설명 부족, 빈번하지 않은 어휘 등 다양한 문제를 가지고 있다. 저자들은 정보 밀도가 높은 캡션을 생성하기 위해 SOTA 비전-언어 모델 LLaVA를 활용하였다. “Describe this image and its style in a very detailed manner”라는 프롬프트를 사용하여 캡션의 품질을 크게 향상시켰다.
그러나 LAION 데이터셋은 주로 쇼핑 웹사이트의 단순한 제품 미리보기로 구성되어 있어 객체 조합의 다양성을 추구하는 text-to-image 생성 학습에는 적합하지 않다. 따라서 저자들은 원래 segmentation task에 사용되었지만 다양한 객체가 풍부한 이미지를 제공하는 SAM 데이터셋을 활용하기로 결정했다. 저자들은 SAM에 LLaVA를 적용하여 높은 개념 밀도를 특징으로 하는 고품질 텍스트-이미지 쌍을 성공적으로 획득했다.
세 번째 단계에서는 실제 사진을 넘어 생성된 이미지의 미적 품질을 향상시키기 위해 JourneyDB와 1천만 개의 내부 데이터셋울 통합하여 학습 데이터셋을 구성하였다.
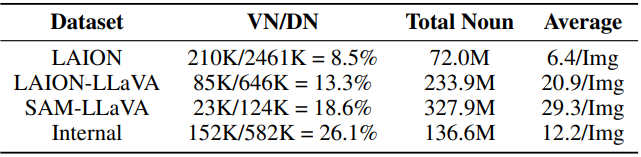
어휘 분석 결과는 위 표와 같다. VN은 유효한 고유명사이며 데이터셋에서 10회 이상 나타나는 명사로 정의된다. DN은 전체 고유 명사이다.
LAION 데이터셋에는 246만 개의 고유 명사가 있지만 8.5%만 유효하다. 이 유효한 명사 비율은 LLaVA 레이블이 붙은 캡션을 사용하면 8.5%에서 13.3%로 크게 증가한다. LAION의 원본 캡션에는 무려 21만 개의 고유 명사가 포함되어 있지만 전체 명사 수는 7,200만 개이다. 그러나 LAION-LLaVA에는 8.5만 개의 고유 명사와 함께 2.34억 개의 명사가 포함되어 있으며 이미지당 평균 명사 수가 6.4에서 21로 증가하여 원본 LAION 캡션이 불완전함을 나타낸다. 또한 SAM-LLaVA는 총 명사 수가 3.28억 개이고 이미지당 평균 명사 수가 30개로 LAION-LLaVA보다 성능이 뛰어나며, SAM이 이미지당 더 풍부한 목적어와 뛰어난 정보 밀도가 포함되어 있음을 보여준다. 마지막으로 내부 데이터도 fine-tuning에 충분한 유효 명사와 평균 정보 밀도를 보장한다. LLaVA의 레이벨이 붙은 캡션은 유효한 명사 비율과 이미지당 평균 명사 수를 크게 늘려 개념 밀도를 향상시킨다.
Experiment
- 학습 디테일
1. Performance Comparisons and Analysis
Fidelity Assessment
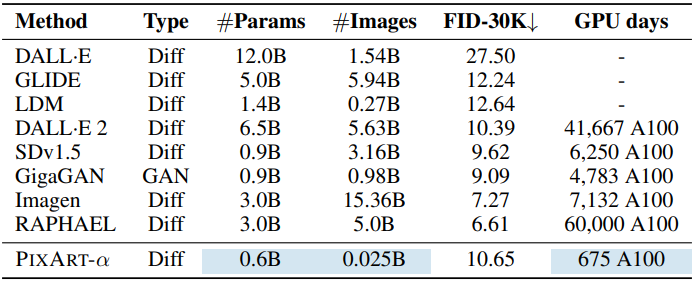
다음은 최신 T2I 모델들과 PixArt-$\alpha$를 비교한 표이다.
Alignment Assessment
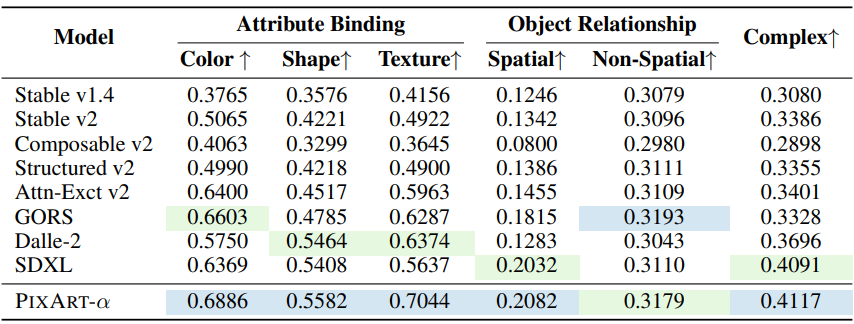
다음은 T2I-CompBench에서 정렬을 평가한 표이다.
User Study
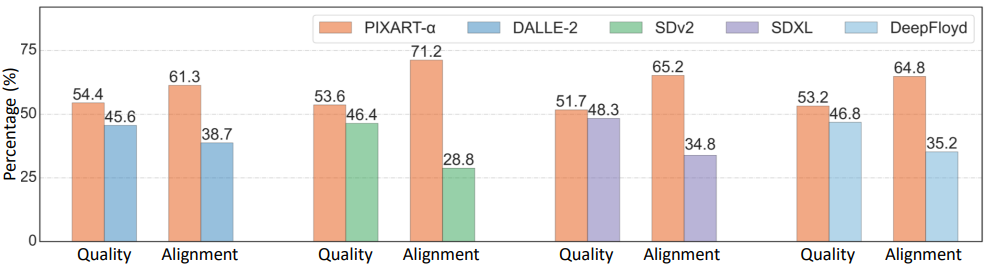
다음은 300개의 프롬프트에 대한 user study 결과이다.
2. Ablation Study
다음은 ablation study 결과이다. 왼쪽은 시각적으로 비교한 결과이고 오른쪽은 SAM에서의 zero-shot FID-2K와 GPU 메모리 사용량을 비교한 것이다.
