[논문리뷰] Zero-shot Image-to-Image Translation (pix2pix-zero)
SIGGRAPH 2023. [Paper] [Page] [Github]
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, Jun-Yan Zhu
Carnegie Mellon University | Adobe Research
6 Feb 2023
Introduction
DALL·E 2, Imagen, Stable Diffusion과 같은 최근의 text-to-image diffusion model은 복잡한 물체와 장면으로 다양하고 사실적인 합성 이미지를 생성하여 강력한 구성 능력을 보여주었다. 그러나 실제 이미지를 편집하기 위해 이러한 모델을 용도 변경하는 것은 여전히 어려운 일이다.
첫째, 이미지는 자연스럽게 텍스트 설명과 함께 제공되지 않는다. 텍스트를 지정하는 것은 번거롭고 시간이 많이 걸린다. 왜냐하면 그림은 많은 텍스처 디테일, 조명 조건, 미묘한 모양을 포함하기 때문이다. 둘째, 초기 텍스트 프롬프트와 타겟 텍스트 프롬프트가 있더라도 기존 text-to-image 모델은 입력 이미지의 레이아웃, 모양, 개체 포즈를 따르지 않는 완전히 새로운 콘텐츠를 합성하는 경향이 있다. 결국 텍스트 프롬프트를 편집하면 변경하려는 내용만 알 수 있고 보존하려는 내용은 전달되지 않는다. 마지막으로 사용자는 다양한 실제 이미지 세트에 대해 모든 종류의 편집을 수행하기를 원할 수 있다. 따라서 막대한 비용으로 인해 각 이미지 및 편집 유형에 대해 대형 모델을 fine-tuning하고 싶지 않다.
위의 문제를 극복하기 위해 학습이 필요 없고 프롬프트가 필요 없는 diffusion 기반 image-to-image translation 접근 방식인 pix2pix-zero를 도입한다. 사용자는 입력 이미지에 대한 텍스트 프롬프트를 수동으로 생성하지 않고 소스 도메인에서 타겟 도메인으로 가는 형태로 편집 방향을 즉석에서 지정하기만 하면 돤다. pix2pix-zero는 각 편집 유형과 이미지에 대한 추가 학습 없이 사전 학습된 text-to-image diffusion model을 직접 사용할 수 있다.
본 논문에서 두 가지 주요 기여를 하였다.
- 입력 텍스트 프롬프트가 없는 효율적인 자동 편집 방향 검색 메커니즘: 광범위한 입력 이미지에 적용되는 일반 편집 방향을 자동으로 검색한다. 원래 단어와 편집된 단어가 주어지면 원래 단어와 편집된 단어를 별도로 포함하는 두 개의 문장 그룹을 생성한다. 그런 다음 두 그룹 간의 CLIP 임베딩 방향을 계산한다. 이 편집 방향은 여러 문장을 기반으로 하기 때문에 원래 단어와 편집된 단어 사이에서만 방향을 찾는 것보다 더 견고하다. 이 단계는 약 5초밖에 걸리지 않으며 미리 계산할 수 있다.
- Cross-attention guidance를 통한 콘텐츠 보존: Cross-attention map은 생성된 객체의 구조에 해당한다. 소스 구조를 유지하기 위해 텍스트-이미지 cross-attention map이 변환 전후에 일관되도록 한다. 따라서 diffusion process 전반에 걸쳐 이러한 일관성을 강화하기 위해 cross-attention guidance를 적용한다.
일련의 기술을 사용하여 결과와 inference 속도를 더욱 향상시킨다.
- 자기 상관 정규화: DDIM을 통해 inversion을 적용할 때 DDIM inversion이 중간 예측 noise를 덜 가우시안으로 만드는 경향이 있어 반전된 이미지의 편집 가능성이 감소한다. 따라서 inversion 중에 noise가 가우시안에 가까워지도록 자기 상관 정규화를 도입한다.
- 조건부 GAN distillation: 비용이 많이 드는 diffusion process의 다단계 inference로 인해 diffusion model이 느리다. 인터랙티브한 편집을 위해 diffusion model에서 소스 이미지와 편집된 이미지의 쌍 데이터를 제공하여 diffusion model을 빠른 조건부 GAN 모델로 증류하여 실시간 inference를 가능하게 한다.
Method
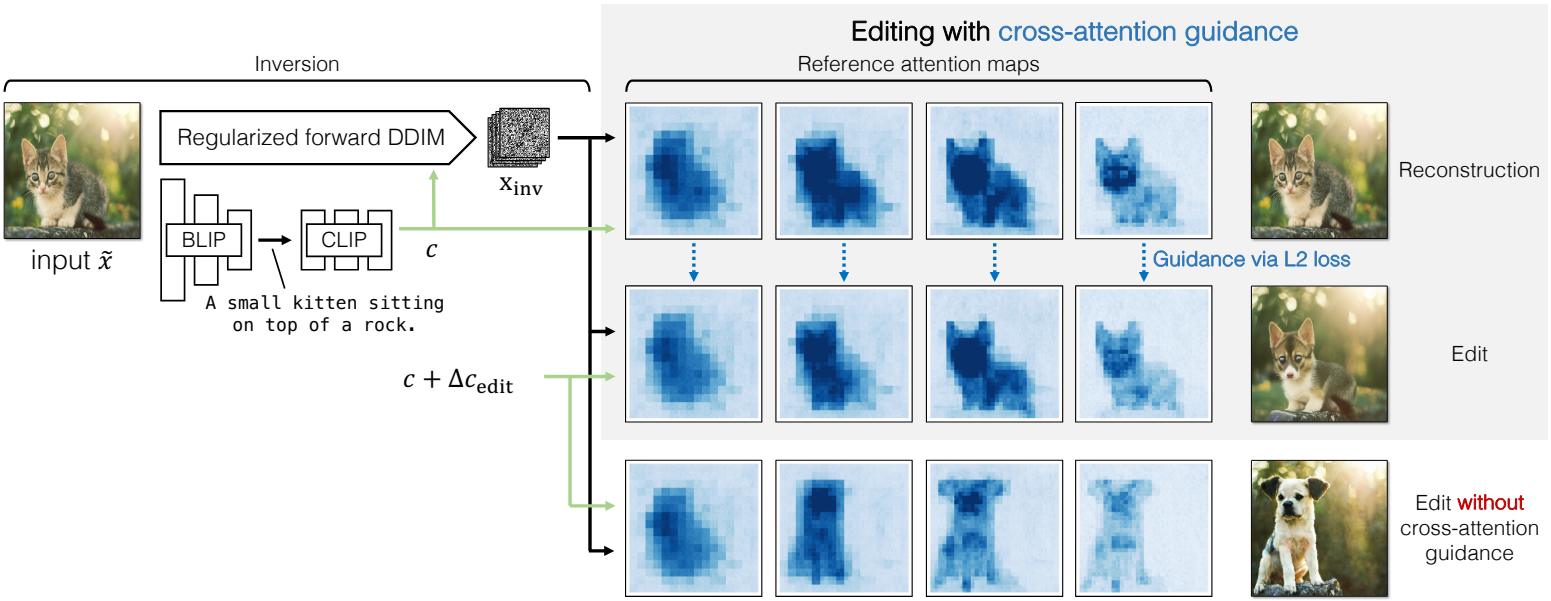
본 논문은 편집 방향에 따라 입력 이미지를 편집할 것을 제안한다. 먼저 입력 $\tilde{x}$를 결정론적 방식으로 해당 noise map으로 반전한다. 텍스트 임베딩 space에서 편집 방향을 자동으로 발견하고 미리 계산하는 방법을 제시한다. 순진하게 편집 방향을 적용하면 종종 이미지 내용이 원치 않게 변경된다. 이 문제를 해결하기 위해 diffusion sampling process를 가이드하고 입력 이미지의 구조를 유지하는 데 도움이 되는 cross-attention guidance를 제안한다. 본 논문의 방법은 다른 text-to-image model에 적용할 수 있지만 본 논문에서는 입력 이미지 $\tilde{x} \in \mathbb{R}^{X \times X \times 3}$을 latent code $x_0 \in \mathbb{R}^{S \times S \times 4}$로 인코딩하는 Stable Diffusion을 사용한다. 실험에서 $X = 512$는 이미지 크기이고 $S = 64$는 다운샘플링된 latent 크기이다. Inversion과 편집은 latent space에서 발생한다. 입력 이미지 $\tilde{x}$를 설명하기 위해 BLIP를 사용하여 초기 텍스트 프롬프트 $c$를 생성한다.
1. Inverting Real Images
Deterministic inversion
Inversion은 샘플링 시 입력 latent code $x_0$을 재구성하는 noise map $x_\textrm{inv}$를 찾는 것을 수반한다. DDPM에서 이는 고정된 forward process에 해당하고 뒤이어 reverse process로 denoising이 뒤따른다. 그러나 DDPM의 forward process와 reverse process는 모두 확률적이며 충실한 재구성을 가져오지 않는다. 대신 아래와 같이 deterministic DDIM reverse process를 채택한다.
\[\begin{equation} x_{t+1} = \sqrt{\vphantom{1} \bar{\alpha}_{t+1}} f_\theta (x_t, t, c) + \sqrt{1 - \bar{\alpha}_{t+1}} \epsilon_\theta (x_t, t, c) \end{equation}\]여기서 $x_t$는 timestep $t$의 noised latent code이고, $\epsilon_\theta (x_t, t, c)$는 timestep $t$와 인코딩된 텍스트 feature $c$에 따라 $x_t$에서 추가된 noise를 예측하는 UNet 기반 denoiser이며, \(\sqrt{\vphantom{1} \bar{\alpha}_{t+1}}\)은 noise scaling factor이다. DDIM에 정의된 대로 $f_\theta(x_t, t, c)$는 최종 denoised latent code $x_0$를 예측한다.
\[\begin{equation} f_\theta (x_t, t, c) = \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon_\theta (x_t, t, c)}{\sqrt{\vphantom{1} \bar{\alpha}_t}} \end{equation}\]DDIM process를 사용하여 초기 latent code $x_0$에 점진적으로 noise를 추가하고 inversion이 끝나면 최종 noised latent code $x_T$를 $x_\textrm{inv}$로 할당한다.
Noise regularization
DDIM inversion $\epsilon_\theta (z_t, t, c) \in \mathbb{R}^{S \times S \times 4}$에 의해 생성된 반전된 noise map은 종종 상관관계가 없는 Gaussian noise의 통계적 속성을 따르지 않아 편집 가능성이 떨어진다. Gaussian noise map은 다음 두 가지 속성을 만족해야 한다.
- 임의의 위치 쌍 사이에 상관 관계 없음
- 각 공간 위치에서 평균이 0이고 단위 분산 (자기 상관 함수이 Kronecker delta function가 됨)
이를 만족하면 개별 픽셀 위치에서 쌍별 항 \(\mathcal{L}_\textrm{pair}\)와 KL divergence 항 \(\mathcal{L}_\textrm{KL}\)로 구성된 자기 상관 목적 함수를 사용하여 inversion process를 가이드한다.
모든 위치 쌍을 조밀하게 샘플링하는 데 비용이 많이 들기 때문에 초기 노이즈 레벨 $\eta^0 \in \mathbb{R}^{64 \times 64 \times 4}$가 예측된 noise map $\epsilon_\theta$이고 각 후속 noise map은 2$\times$2 이웃 (예상 분산을 유지하기 위해 2를 곱함)으로 average pooling된다. Feature 크기 8$\times$8에서 멈추고 \(\{\eta^0 , \eta^1, \eta^2, \eta^3\}\) 집합을 형성하는 4개의 noise map을 생성한다.
피라미드 레벨 $p$에서 쌍별 정규화는 noise map 크기 $S_p$에 대해 정규화된, 가능한 $\delta$ 오프셋에서 자기 상관 계수의 제곱합이다.
\[\begin{equation} \mathcal{L}_\textrm{pair} \sum_p \frac{1}{S_p^2} \sum_{\delta = 1}^{S_p - 1} \sum_{x, y, c} \eta_{x, y, c}^p (\eta_{x-\delta, y, c}^p + \eta_{x, y-\delta, c}^p) \end{equation}\]여기서 $\eta_{x,y,c}^p \in \mathbb{R}$은 순환 인덱싱과 채널을 사용하여 공간 위치를 인덱싱한다. Diffusion 맥락에서 성능을 향상시키기 위해 자기 상관 아이디어에 몇 가지 변경 사항을 도입한다. 장거리 연결을 전파하기 위해 여러 번의 반복에 의존하면 중간 timestep이 분포에서 벗어나기 때문에 diffusion 맥락에서 각 timestep이 잘 정규화되는 것이 중요하다.
또한 정규화를 통해 엄격하게 0-평균 단위 분산 기준을 적용하면 denoising process 중에 발산이 발생한다. 대신 VAE에서 사용되는 loss \(\mathcal{L}_\textrm{KL}\)로 부드럽게 공식화한다. 이를 통해 두 loss 사이에서 부드럽게 균형을 잡을 수 있다. 최종 자기 상관 정규화는
\[\begin{equation} \mathcal{L}_\textrm{auto} = \mathcal{L}_\textrm{pair} + \lambda \mathcal{L}_\textrm{KL} \end{equation}\]이며, 여기서 $\lambda$는 두 항의 균형을 맞춘다.
2. Discovering Edit Directions
최근의 대형 생성 모델을 통해 사용자는 출력 이미지를 설명하는 문장을 지정하여 이미지 합성을 제어할 수 있다. 대신 소스 도메인에서 타겟 도메인으로 원하는 변경 사항만 제공하면 되는 인터페이스를 제공한다.
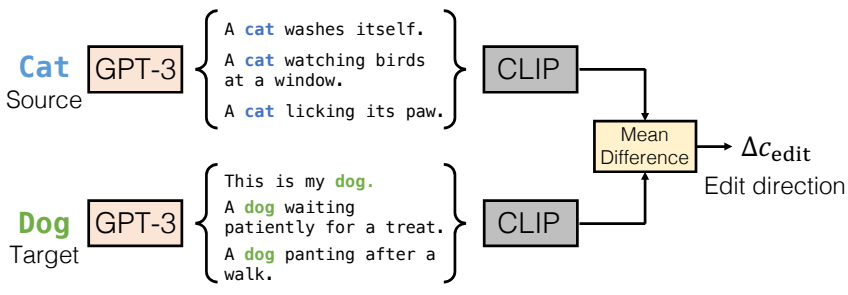
위 그림과 같이 소스에서 타겟까지 해당 텍스트 임베딩 방향 벡터 $\Delta c_\textrm{edit}$를 자동으로 계산한다. 기존 문장을 사용하거나 소스 $s$와 타겟 $t$ 모두에 대해 다양한 문장의 대규모 bank를 생성한다. GPT-3와 같은 generator를 사용하거나 소스 및 타겟 주위에 사전 정의된 프롬프트를 사용한다. 그런 다음 문장의 CLIP 임베딩 간의 평균 차이를 계산한다. 텍스트 프롬프트 임베딩에 방향을 추가하여 편집된 이미지를 생성할 수 있다. 단일 단어보다 여러 문장을 사용하는 텍스트 방향을 찾는다. 편집 방향을 계산하는 이 방법은 약 5초밖에 걸리지 않으며 한 번만 미리 계산하면 된다. 다음으로 편집 방향을 image-to-image translation 방법에 통합한다.
3. Editing via Cross-Attention Guidance
최근의 대규모 diffusion model은 denoising network $\epsilon_\theta$를 cross-attention layer로 확장하여 컨디셔닝을 통합한다. LDM을 기반으로 구축된 Stable Diffusion을 사용한다. 이 모델은 CLIP 텍스트 인코더를 사용하여 텍스트 임베딩 $c$를 생성한다. 다음으로 텍스트에 대한 생성을 컨디셔닝하기 위해 모델은 인코딩된 텍스트와 denoiser $\epsilon_\theta$의 중간 feature 간의 cross-attention을 계산한다.
\[\begin{equation} \textrm{Attention} (Q, K, V) = M \cdot V \\ \textrm{where} \quad M = \textrm{Softmax} \bigg( \frac{QK^\top}{\sqrt{d}} \bigg) \end{equation}\]여기서 query $Q = W_Q \phi (x_t)$, key $K = W_K c$, value $V = W_V c$는 denoising UNet $\epsilon_\theta$와 텍스트 임베딩 $c$의 중간 feature $\phi (x_t)$에 적용된 학습된 projection $W_Q$, $W_K$, $W_V$로 계산된다. $d$는 예상 key와 query의 차원이다. 특히 흥미로운 점은 이미지의 구조와 긴밀한 관계가 있는 것으로 관찰되는 cross-attention map $M$이다. 마스크의 개별 entry $M_{i,j}$는 $i$번째 공간 위치에 대한 $j$번째 텍스트 토큰의 기여도를 나타낸다. 또한 cross-attention mask는 timestep에 따라 다르며 각 timestep $t$마다 다른 attention mask $M_t$를 얻는다.
편집을 적용하기 위한 순진한 방법은 사전 계산된 편집 방향 $\Delta c_\textrm{edit}$를 $c$에 적용하고 샘플링 프로세스에 $c_\textrm{edit} = c + \Delta c_\textrm{edit}$를 사용하여 $x_\textrm{edit}$를 생성하는 것이다. 이 접근 방식은 편집에 따라 이미지를 변경하는 데 성공하지만 입력 이미지의 구조를 유지하지 못한다. 샘플링 프로세스 중 cross-attention map의 편차는 이미지 구조의 편차를 초래한다. 이와 같이 cross-attention map에서 일관성을 장려하기 위해 새로운 cross-attention guidance를 사용한다.

Algorithm 1과 같이 2단계 프로세스를 따른다. 먼저 편집 방향을 적용하지 않고 이미지를 재구성한다. 입력 텍스트 $c$를 사용하여 각 timestep $t$에 대한 레퍼런스 cross-attention map $M_t^\textrm{ref}$를 얻는다. 이러한 cross-attention map은 보존하려는 소스 이미지의 구조 $e$에 해당한다. 다음으로 $c_\textrm{edit}$를 사용하여 편집 방향을 적용하여 cross-attention map $M_t^\textrm{edit}$를 생성한다. 그런 다음 $M_t^\textrm{ref}$와 일치하는 방향으로 $x_t$에 gradient step을 수행하여 아래의 cross-attention loss \(\mathcal{L}_\textrm{xa}\)를 줄인다.
이 loss는 $M_t^\textrm{edit}$가 $M_t^\textrm{ref}$에서 벗어나지 않고 원래 구조를 유지하면서 편집을 적용하도록 한다.
Experiments
1. Qualitative Results
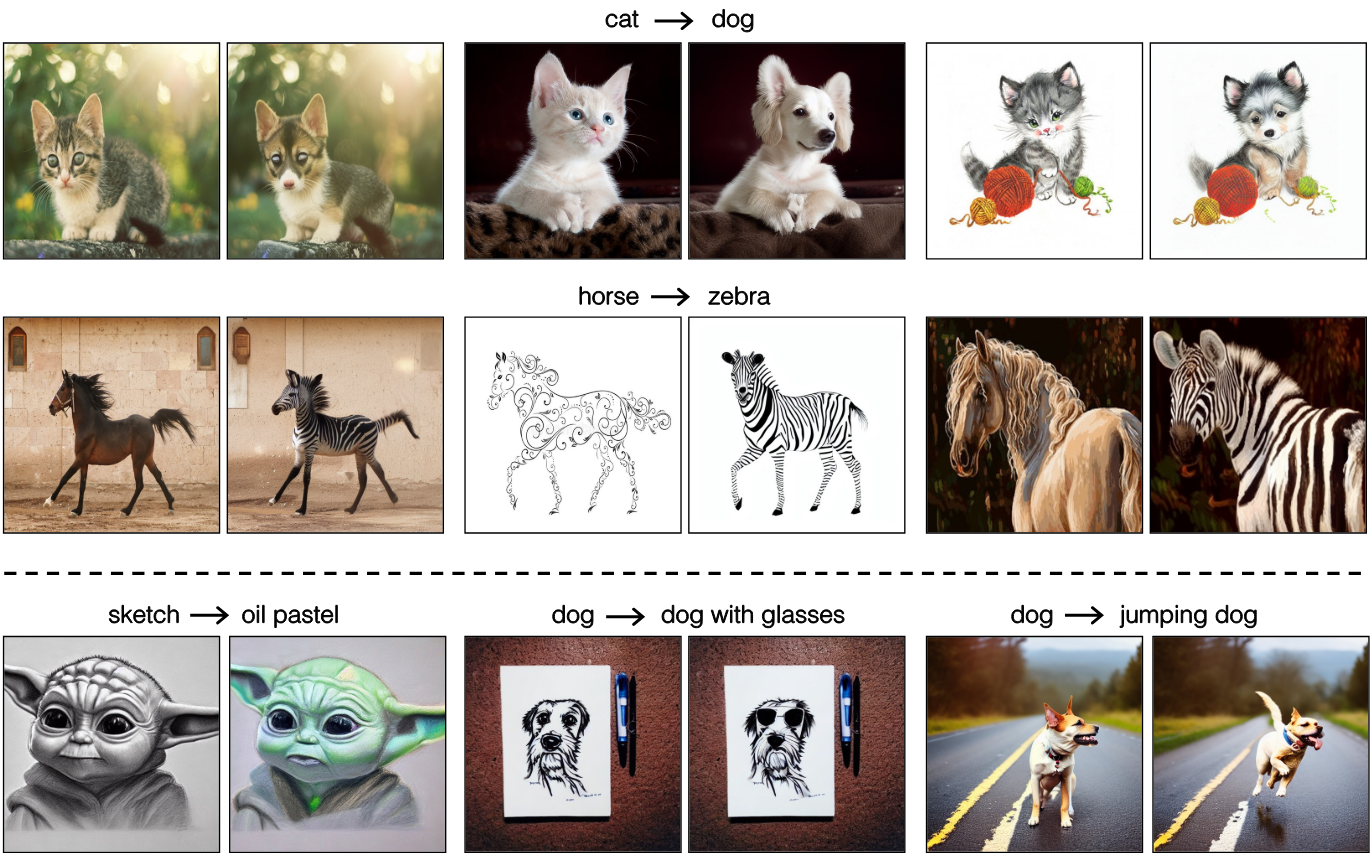
다음은 pix2pix-zero 결과의 예시들이다.

2. Comparisons
다음은 실제 이미지들에 대하여 여러 baseline들과 결과를 비교한 것이다.

다음은 이전 diffusion 기반 편집 방법들과 비교한 표이다.

3. Ablation Study
다음은 ablation study 결과이다.

아래 그림은 구조 보존에 대한 cross-attention guidance의 효과를 나타낸 것이다.

4. Model Acceleration with Conditional GANs
다음은 조건부 GAN으로 모델을 가속한 결과이다.

Limitations

- 구조 guidance가 cross-attention map의 해상도에 의해 제한된다
- 객체가 비정형 포즈를 가진 어려운 경우에 방법이 실패할 수 있다.