[논문리뷰] Pretraining is All You Need for Image-to-Image Translation (PITI)
arXiv 2022. [Paper] [Page] [Github]
Tengfei Wang, Ting Zhang, Bo Zhang, Hao Ouyang, Dong Chen, Qifeng Chen, Fang Wen
The Hong Kong University of Science and Technology | Microsoft Research Asia
25 May 2022

Introduction
많은 콘텐츠 생성 task에는 입력 이미지 (ex. 일반 그림)를 사실적인 출력으로 변환하는 task가 포함된다. Image-to-image translation 문제는 본질적으로 심층 생성 모델을 사용하여 주어진 입력에 대한 자연 이미지의 조건부 분포를 학습하는 것과 관련이 있다. 수년에 걸쳐 우리는 꾸준히 SOTA를 발전시키는 task별 맞춤화를 통한 수많은 방법을 보아왔지만, 기존 솔루션으로는 실용적인 사용이 가능한 고화질 이미지 생성은 여전히 어려운 과제로 남아 있다.
본 논문은 다양한 비전 task와 자연어 처리에서 네트워크 사전 학습의 엄청난 성공에 힘입어 사전 학습을 사용하여 image translation을 개선하는 새로운 패러다임을 제안한다. 핵심 아이디어는 사전 학습된 신경망을 사용하여 자연스러운 이미지 매니폴드를 캡처하는 것이다. 따라서 image translation은 이 매니폴드를 탐색하고 입력 semantic과 관련된 실현 가능점을 찾는 것과 동일하다. 특히, 합성 네트워크는 대량의 이미지를 사용하여 사전 학습되어야 하며 latent space의 샘플링이 그럴듯한 출력으로 이어지기 전에 generative prior 역할을 해야 한다. 사전 학습된 합성 네트워크를 사용하면 다운스트림 학습은 단순히 사전 학습된 모델에서 인식할 수 있는 latent 표현에 사용자 입력을 적용한다. 규정된 semantic 레이아웃에 맞게 이미지 품질을 타협하는 이전 연구들과 비교하여 본 논문에서 제안된 프레임워크는 생성된 샘플이 자연 이미지 매니폴드에 엄격하게 배치되므로 변환 품질을 보장한다.
Generative prior는 다음과 같은 속성을 가져야 한다. 첫째, 사전 학습된 모델은 복잡한 장면을 모델링하고 전체 자연스러운 이미지 분포를 이상적으로 캡처할 수 있는 강력한 능력을 가져야 한다. 저자들은 특정 도메인 (ex. 얼굴)에 주로 작동하는 GAN을 사용하는 대신 다양한 이미지를 합성하는 인상적인 표현력을 보여주기 위해 diffusion model을 사용하였다. 둘째, 두 종류의 latent code로부터 이미지를 생성할 것으로 예상된다. 하나는 이미지 semantic을 특성화하고 다른 하나는 나머지 이미지 변형을 설명한다. 특히, semantic과 저차원 latent는 다운스트림 task에 중추적인 역할을 한다. 그렇지 않으면 별개의 modality 입력을 복잡한 latent space에 매핑하기가 어려울 것이다. 이러한 점을 고려하여 저자들은 사전 학습된 generative prior로 GLIDE를 채택했다. GLIDE는 거대한 데이터에 대해 학습된 diffusion model이며 다양한 이미지를 충실하게 생성할 수 있다. GLIDE는 텍스트 조건에 해당하는 latent space를 사용하므로 자연스럽게 원하는 semantic latent space를 허용한다.
다운스트림 task를 수용하기 위해 segmentation mask와 같은 변환 입력을 사전 학습된 모델의 latent space에 project하는 task별 head를 학습시킨다. 따라서 다운스트림 task를 위한 네트워크는 인코더-디코더 아키텍처를 채택한다. 인코더는 입력을 task에 구애받지 않는 latent space로 변환하고 그에 따라 그럴듯한 이미지를 생성하기 위해 강력한 디코더, 즉 diffusion model이 뒤따른다. 실제로는 먼저 사전 학습된 디코더를 수정하고 인코더만 업데이트한 다음 전체 네트워크를 공동으로 fine-tuning한다. 이러한 단계별 학습은 주어진 입력에 대한 충실도를 보장하면서 사전 학습된 지식을 최대한 활용할 수 있다.
본 논문은 diffusion model의 생성 품질을 향상시키는 기술을 추가로 제안하였다.
- 대략적인 이미지를 생성한 후 super-resolution을 수행하는 계층적 생성 전략을 채택하였다. 그러나 denoising step에서 Gaussian noise 가정으로 인해 diffusion 업샘플러가 과도하게 부드러운 결과를 생성하는 경향이 있으므로 denoising process에서 적대적 학습을 도입하여 지각 품질을 향상시킨다.
- 일반적으로 사용되는 classifier-free guidance로 인해 디테일이 사라져 지나치게 포화된 이미지가 생성된다. 이를 해결하기 위해 noise 통계를 명시적으로 정규화하는 것을 제안하였다. 이러한 정규화된 guidance 샘플링을 통해 보다 공격적인 guidance를 제공하고 생성 품질을 높일 수 있다.
본 논문의 사전 학습 기반 image-to-image translation인 PITI는 mask-to-image, sketch-to-image, geometry-to-image translation과 같은 다양한 다운스트림 task에서 전례 없는 품질을 달성하였다. ADE20K, COCO-Stuff, DIODE를 포함한 까다로운 데이터셋에 대한 광범위한 실험은 SOTA와 사전 학습이 없는 모델에 비해 상당한 우월성을 보여주었다. 또한, 제안된 방법은 few-shot image-to-image translation에 대한 유망한 잠재력을 보여주었다.
Approach
1. Generative pretraining
Discriminative task의 경우 사전 학습과 다운스트림 task가 같은 도메인에서 이미지를 가져온다. 하지만 생성적 task의 경우 사전 학습된 모델과 별개의 다운스트림 task가 매우 다양한 종류의 이미지를 사용한다. 따라서 생성적 사전 학습 중에 diffusion model이 나중에 모든 다운스트림 task에 사용하기 위해 공유되는 latent space에서 이미지를 생성하기를 바란다. 중요한 것은 사전 학습된 모델이 고도로 의미론적인 공간을 갖는 것이 바람직하다. 즉 이 공간의 이웃 지점은 의미론적으로 유사한 이미지에 해당해야 한다. 이러한 방식으로 다운스트림 fine-tuning에는 task별 입력을 이해하는 것만 포함되며, 그럴듯한 레이아웃과 사실적인 텍스처를 렌더링하는 까다로운 이미지 합성은 사전 학습된 지식을 사용하여 수행된다.
이를 위해 본 논문은 semantic 입력에 따라 diffusion model을 사전 학습할 것을 제안한다. 저자들은 비전-언어 사전 학습의 인상적인 전달 능력에 영감을 받아 텍스트 조건을 적용하고 거대하고 다양한 텍스트-이미지 쌍에 대해 학습되는 GLIDE 모델을 채택했다. 특히 tranformer 네트워크는 텍스트 입력을 인코딩하고 diffusion model에 추가로 주입되는 텍스트 토큰을 생성한다. 텍스트 임베딩 공간은 본질적으로 의미론적이다. 많은 최근 연구와 유사하게 GLIDE는 64$\times$64 해상도의 base diffusion model로 시작하여 64$\times$64에서 256$\times$256 해상도로 diffusion upsampling model을 적용하는 계층적 생성 방식을 활용한다. 본 논문의 실험은 사람과 폭력적인 물체가 제거된 약 6700만 개의 텍스트-이미지 쌍에 대해 학습된 공개 GLIDE 모델을 기반으로 한다.
2. Downstream adaptation
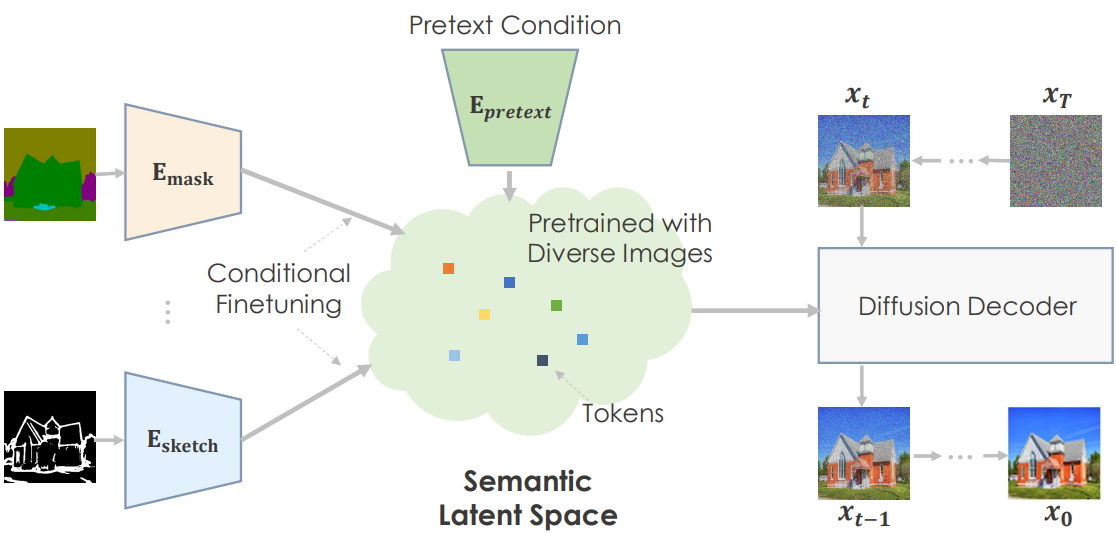
모델이 사전 학습되면 base model과 upsampler model을 각각 fine-tuning하는 다양한 전략을 사용하여 다양한 다운스트림 이미지 합성 task에 모델을 적용할 수 있다.
Base model finetuning
Base model을 사용한 생성은 \(x_t = \tilde{\mathcal{D}} \tilde{\mathcal{E}} (x_0, y)\)로 공식화될 수 있다. 여기서 \(\tilde{\mathcal{E}}\)와 \(\tilde{\mathcal{D}}\)는 각각 사전 학습된 인코더와 디코더를 나타내고 $y$는 사전 학습에 사용되는 조건이다. 텍스트 이상의 새로운 modality 조건을 수용하기 위해 task별 head \(\mathcal{E}_i\)를 학습시켜 조건부 입력을 사전 학습된 임베딩 공간에 매핑한다. 입력을 충실하게 project할 수 있는 경우 사전 학습된 디코더는 그럴듯한 출력을 생성한다.
본 논문은 2단계 fine-tuning 방식을 제안한다. 첫 번째 단계에서는 task별 인코더를 구체적으로 학습시키고 사전 학습된 디코더는 그대로 둔다. 이 단계의 출력은 입력의 semantic과 대략 일치하지만 정확한 공간 정렬은 없다. 그런 다음 인코더와 디코더를 모두 fine-tuning한다. 그 후, 훨씬 향상된 공간적 semantic 정렬을 얻는다. 이러한 단계별 학습은 사전 학습된 지식을 최대한 배양하는 데 도움이 되며 품질 향상에 매우 중요한 것으로 입증되었다.
Adversarial diffusion upsampler
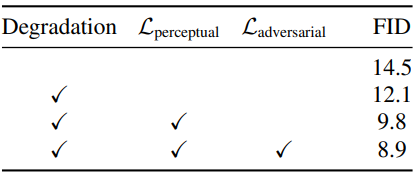
고해상도 생성을 위해 diffusion upsampler를 더욱 fine-tuning한다. CDM과 DALL-E 2를 따라 학습 입력에 랜덤 degradation, 특히 실제 BSR degradation를 적용하여 학습 이미지와 base model의 샘플 사이의 간격을 줄인다. 특히, oversmoothing된 효과를 모방하기 위해 $L_0$ 필터도 도입했다.
그럼에도 불구하고 강력한 data augmentation을 적용하더라도 여전히 oversmoothing된 결과가 관찰된다. 저자들은 이 문제가 denoising process의 Gaussian noise 가정에서 발생한다고 추측하였다. 따라서 noise 예측을 위한 표준 평균 제곱 오차 loss를 계산하는 것 외에도 perceptual loss와 adversarial loss를 부과하여 로컬 이미지 구조의 현실성을 향상시키는 것을 제안하였다. 이미지 예측
\[\begin{equation} \hat{x}_0^t = \frac{x_t - \sqrt{1 - \alpha_t} \epsilon_\theta (x_t y, t)}{\sqrt{\alpha_t}} \end{equation}\]에서 계산된 perceptual loss와 adversarial loss는 다음과 같이 공식화될 수 있다.
\[\begin{aligned} \mathcal{L}_\textrm{perc} &= \mathbb{E}_{t, x_0 \epsilon} \| \psi_m (\hat{x}_0^t) - \psi_m (x_0) \| \\ \mathcal{L}_\textrm{adv} &= \mathbb{E}_{t, x_0, \epsilon} [\log D_\theta (\hat{x}_0^t)] + \mathbb{E}_{x_0} [\log (1 - D_\theta (x_0))] \end{aligned}\]여기서 $D_\theta$는 \(\mathcal{L}_\textrm{adv}\)를 최대화하려고 시도하는 adversarial discriminator이고, $\psi_m$은 사전 학습된 VGG 네트워크의 multilevel feature이다.
3. Normalized classifier-free guidance
Diffusion model은 조건부 입력을 무시하고 이 입력과 상관 없는 결과를 생성할 수 있다. 이 문제를 해결하는 한 가지 방법은 샘플링 중에 $p(y \vert x_t)$와 함께 $p(x_t \vert y)$를 고려하는 classifier-free guidance이다. 로그 확률 $p(y \vert x_t)$의 기울기는 다음과 같이 추정할 수 있다.
\[\begin{equation} \nabla_{x_t} \log p (y \vert x_t) \propto \nabla_{x_t} \log p(x_t \vert y) - \nabla_{x_t} \log p(x_t \vert y) - \nabla_{x_t} \log p (x_t) \propto \epsilon_\theta (x_t \vert y) - \epsilon_\theta (x_t) \end{equation}\]샘플링하는 동안 주어진 조건 $y$와 null 조건 $\varnothing$로 각각 noise를 추정하고 $\epsilon_\theta (x_t \vert \varnothing)$에서 더 멀리 떨어진 샘플을 생성할 수 있다.
\[\begin{equation} \hat{\epsilon}_\theta (x_t \vert y) = \epsilon_\theta (x_t \vert y) + w \cdot (\epsilon_\theta (x_t \vert y) - \epsilon_\theta (x_t \vert \varnothing)) \end{equation}\]여기서 $w \ge 0$은 guidance 강도를 제어한다. 이러한 classifier-free guidance는 샘플링 다양성을 절충하여 개별 샘플의 품질을 향상시킨다.
그러나 이러한 샘플링 절차로 인해 후속 denoising을 방해하는 평균 및 분산 이동이 발생한다. 구체적으로 말하면, 위 식의 \(\hat{\epsilon}_\theta (x_t \vert y)\)는 평균을 $\hat{\mu} = \mu + w(\mu − \mu_\varnothing)$로 취하며, 이는 classifier-free guidance에 의해 평균 이동이 있음을 나타낸다. 마찬가지로, noise 샘플의 분산은 \(\epsilon_\theta (x_t \vert y)\)와 \(\epsilon_\theta (x_t \vert \varnothing)\)가 독립 변수라는 가정 하에 $\hat{\sigma}^2 = (1 + w)^2 \sigma^2 + w^2 \sigma_\varnothing^2$로 이동한다. 이러한 변화는 모든 $T$개의 denoising step를 통해 누적되어 지나치게 부드러운 텍스처를 지닌 과포화 이미지를 생성하도록 만든다.
이를 해결하기 위해 본 논문은 원래 추정 \(\epsilon_\theta (x_t \vert y)\)에 따라 가이드된 noise 샘플 \(\hat{\epsilon}_\theta (x_t \vert y)\)의 평균 및 분산과 명시적으로 일치하는 정규화된 classifier-free guidance를 제안한다. 구체적으로 다음과 같다.
\[\begin{equation} \hat{\epsilon}_\theta (x_t \vert y) = \frac{\sigma}{\hat{\sigma}} (\hat{\epsilon}_\theta (x_t \vert y) - \hat{\mu}) + \mu \end{equation}\]정규화된 classifier-free guidance는 특히 큰 guidance 강도 $w$에 대해 샘플링 품질을 효과적으로 향상시킬 수 있다.
Experiments
- 구현 디테일
- 1단계: 디코더 고정, 인코더 학습
- learning rate: $3.5 \times 10^{-5}$
- batch size: 128
- 2단계: 전체 모델을 공동으로 학습
- learning rate: $3 \times 10^{-5}$
- optimizer: AdmaW
- EMA rate: 0.9999
- 샘플링 step
- base model: 250
- upsmapler model: 27
- 1단계: 디코더 고정, 인코더 학습
1. Results
Quantitative results
다음은 다양한 image translation task에서 FID를 비교한 표이다.

Qualitative results
다음은 COCO와 ADE20K에서의 시각적 비교이다.

다음은 다른 데이터셋에서의 시각적 비교이다.

Huamn evaluation
다음은 COCO에서의 user study 결과이다.

2. Ablation study
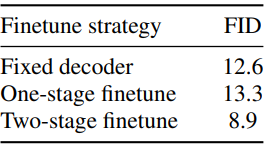
Effect of two-stage finetune strategy
다음은 fine-tuning 전략에 대한 ablation 결과이다.
다음은 디코더를 고정하였을 때 생성되는 이미지이다. 고품질 이미지를 생성하지만 조건과 정렬되지 않는다.

Adversarial diffusion upsampler
다음은 업샘플링 전략에 대한 ablation 결과이다.
Normalized classifier-free guidance
다음은 normalized classifier-free guidance 샘플링의 효과를 나타낸 그림이다.

Smaller training dataset
다음은 다양한 학습 이미지 크기에 대하여 FID를 비교한 표이다.

Limitations
PITI의 한 가지 한계점은 샘플링된 이미지가 주어진 입력과 충실하게 정렬하는 데 어려움이 있고 작은 객체를 놓칠 수 있다는 것이다. 한 가지 가능한 이유는 사전 학습된 모델의 중간 공간에 정확한 공간 정보가 부족하기 때문이다.