[논문리뷰] Pinco: Position-induced Consistent Adapter for Diffusion Transformer in Foreground-conditioned Inpainting
ICCV 2025. [Paper]
Guangben Lu, Yuzhen Du, Zhimin Sun, Ran Yi, Yifan Qi, Yizhe Tang, Tianyi Wang, Lizhuang Ma, Fangyuan Zou
Shanghai Jiao Tong University | Tencent
5 Dec 2024

Introduction
기존의 T2I diffusion model을 이용한 텍스트 기반 이미지 inpainting 방법은 크게 세 가지로 분류할 수 있다.
- 샘플링 수정 방법: Latent space 교체 등을 통해 diffusion 샘플링 전략을 조정하여 inpainting을 구현한다. 다양한 diffusion backbone에 원활하게 적용할 수 있지만, 원래의 latent 분포를 왜곡하여 비합리적인 레이아웃 구성이나 부적절한 물체 배치를 초래할 수 있다.
- 모델 fine-tuning 방법: 일반적으로 사전 학습된 T2I 모델의 네트워크 구조를 수정하고 소규모 데이터셋을 활용한다. 모델이 사전 학습된 지식을 잊어버리고 fine-tuning 데이터셋의 분포에 지나치게 적응하게 만들어, 결과적으로 생성된 이미지의 품질과 다양성에 영향을 미칠 수 있다.
- 조건 주입 방법: 보존 영역의 정보를 고정된 T2I 모델에 통합한다. 대부분 ControlNet 구조를 사용하여 T2I 모델의 절반 또는 전체를 복제하여 inpainting 주입에 활용한다. T2I 모델이 커질수록 점점 더 복잡해지고 구현하기 어려워진다. 또한 텍스트 cross-attention 처리가 완료된 후 추가적인 제어 정보를 추가하면 텍스트-이미지 일관성이 저하될 수 있다.
이러한 문제를 해결하기 위해, 본 논문은 DiT 기반 모델의 일관된 전경 조건부 inpainting을 지원하는 강력하면서도 효율적인 plug-and-play 어댑터인 Pinco를 제안하였다. 저자들은 세 가지 혁신적인 모듈을 설계했다.
- Self-Consistent Adapter: 기존의 이미지 프롬프트 어댑터 기반 조건 주입 방식은 cross-attention layer를 통해 feature를 주입하고 이를 base model의 텍스트 cross-attention과 통합한다. 그러나 이러한 통합 방식은 텍스트와 주입된 피사체 정보 간의 충돌을 쉽게 일으켜 텍스트와 생성된 배경 간의 불일치를 초래할 수 있다. 따라서 저자들은 subject-aware attention을 self-attention layer에 통합하여 텍스트와 피사체 feature 간의 충돌을 효과적으로 완화하는 Self-Consistent Adapter를 제안하였다.
- Semantic-Shape Decoupled Extractor: 제어 가능한 T2I 모델에서 사용되는 기존 feature 추출기인 CLIP과 VAE 인코더는 모두 피사체 feature 추출에 최적화되어 있지 않다. 본 논문에서는 서로 다른 소스에서 semantic feature와 shape feature를 추출하는 데 서로 다른 아키텍처를 사용하였다.
- 공유 위치 임베딩 앵커. 피사체 feature를 정확하게 활용하기 위해서는 피사체 영역에 subject-aware attention을 집중해야 한다. 이를 위해, subject-aware attention 계산 전에 위치 임베딩과 피사체 feature를 결합한다. 이 접근 방식은 피사체 영역과의 거리가 멀어질수록 attention 가중치를 감소시켜 피사체 영역 내부에 attention을 집중시킨다.
Method
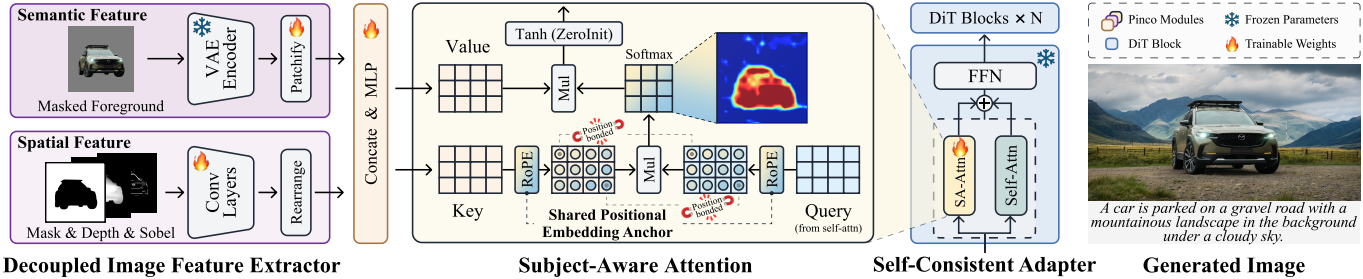
Pinco는 T2I DiT 모델과 원활하게 통합되어 전경 조건에 맞춘 일관된 inpainting을 가능하게 하는 plug-and-play 방식의 inpainting 어댑터이다. 본 inpainting 시스템의 입력은 피사체 이미지 $I$, 마스크 이미지 $m$, 원하는 배경을 설명하는 텍스트 프롬프트 $T$로 구성되며, 피사체 깊이 이미지 $d$와 Sobel 이미지 $s$는 조건 신호로 사용된다. Pinco는 전경 피사체는 변경되지 않은 상태로 유지하면서, 생성된 배경이 텍스트 설명과 일치하고 시각적으로 자연스럽도록 배경 영역을 inpainting하는 것을 목표로 한다.
1. Self-Consistent Adapter
전경 조건부 inpainting에서 전경 피사체의 feature는 기본 T2I diffusion model에 주입되어야 한다. 이미지 프롬프트 어댑터를 사용하는 방법은 latent feature와 피사체 feature 간에 cross-attention을 하고 이를 텍스트 cross-attention 출력과 통합한다. 그러나 이러한 통합은 텍스트 feature와 피사체 feature 간의 충돌을 일으켜 생성된 이미지에서 피사체가 바깥쪽으로 확장되거나 왜곡되는 현상을 초래하거나, 텍스트와 생성된 배경 간의 불일치를 초래할 수 있다.
저자들은 기존 논문들의 cross-attention과 self-attention 분석에서 영감을 얻었다. 이 논문들은 self-attention map을 효과적으로 활용하여 원본 이미지의 공간 구조적 특성을 보존할 수 있음을 보여준다. 이러한 관찰은 self-attention이 최종 출력의 레이아웃과 더 밀접하게 연관되어 있음을 시사한다.
이를 바탕으로, 저자들은 subject-aware attention을 self-attention layer에 직접 통합하는 Self-Consistent Adapter를 제안하였다. 일반적인 attention을 사용하는 DiT의 경우, subject-aware attention은 latent feature와 피사체 feature 간의 cross-attention이며, 본 논문의 메커니즘은 다음과 같이 표현할 수 있다.
\[\begin{aligned} Z &= \alpha \odot \textrm{Self-Attention}(Q, K, V) \\ &+ \beta \odot \textrm{Cross-Attention} (Q, K_\textrm{sub}, V_\textrm{sub}) \end{aligned}\]($Q$는 query, $K$, \(K_\textrm{sub}\), $V$, \(V_\textrm{sub}\)은 latent feature와 피사체 feature에서 계산된 key와 value)
또한, base model에 대한 주입 강도를 점진적으로 제어하기 위해 Zero-init Tanh Gating을 사용한다. 이 접근 방식은 피사체 feature와 텍스트 간의 충돌을 방지하여 생성된 이미지에서 피사체의 형태를 더 잘 보존하고 배경과 텍스트 간의 정렬을 유지한다.
Self-Consistent Adapter는 self-attention 메커니즘의 변형인 MM-Attention을 사용하는 MM-DiT에도 적용 가능하다. MM-DiT의 경우, latent feature와 피사체 feature를 융합하는 MM-Attention을 subject-aware attention으로 설계하였다. 수정된 어텐션 메커니즘은 다음과 같다.
\[\begin{aligned} Z &= \alpha \odot \textrm{MM-Attention}(Q, K, V) \\ &+ \beta \odot \textrm{MM-Attention} (Q, [K, K_\textrm{sub}], [V, V_\textrm{sub}]) \end{aligned}\]($[\cdot, \cdot]$는 토큰 차원에 걸친 concat)
2. Decoupled Image Feature Extractor
T2I 모델 기반 전경 조건부 inpainting을 위해서는 전경 피사체의 feature를 추출하여 base model에 주입해야 한다. 피사체 feature는 일반적으로 피사체 이미지, 마스크 이미지, 그리고 피사체와 관련된 다른 이미지들(ex. depth map, Sobel 이미지)을 concat하여 추출한다. 기존의 이미지 feature 추출은 주로 CLIP 또는 VAE 인코더에 의존했다. 그러나 CLIP 이미지 인코더는 주로 전체 이미지의 고수준 글로벌 semantic 정보를 추출하는 반면, VAE 인코더는 피사체의 윤곽선을 정확하게 보존하기 어려워 전경의 높은 일관성을 요구하는 조건을 충족하지 못한다.
따라서 본 논문에서는 주어진 피사체의 semantic 정보와 형태 정보를 충분히 추출할 수 있는 Semantic-Shape Decoupled Image Feature Extractor를 제안하였으며, 세 부분으로 구성된다.
- Semantic feature 추출: Semantic feature는 배경이 제거된 RGB 피사체 이미지에서 추출된다. 추출된 feature를 사전 학습된 diffusion model의 데이터 분포와 일치시키기 위해, 기존 VAE 인코더 $\epsilon$을 semantic feature 추출기로 재사용하여 추가 학습 오버헤드를 줄였다.
- Shape feature 추출: Shape feature 추출이 부정확하면 출력 이미지에서 피사체가 확대될 수 있다. 따라서 피사체 shape feature를 정확하게 추출하기 위해 피사체의 마스크, depth map, Sobel 이미지를 활용하여 피사체의 형태 디테일을 보완한다. 로컬 형태 디테일의 효과적인 추출을 보장하기 위해, convolution 기반 feature 추출기를 사용하여 shape feature를 추출한다.
- Feature 융합: Semantic feature와 shape feature를 추출한 후, 두 feature를 channel-wise concat하고 MLP 모듈을 사용하여 융합한다.
이러한 feature 추출 방법을 통해 제공된 조건 이미지에 포함된 정보를 최대한 활용할 뿐만 아니라 피사체 형태의 미세한 디테일까지 추출하여 출력 이미지에서 피사체 형태가 바깥쪽으로 확장되는 현상을 크게 줄일 수 있다.
3. Shared Positional Embedding Anchor
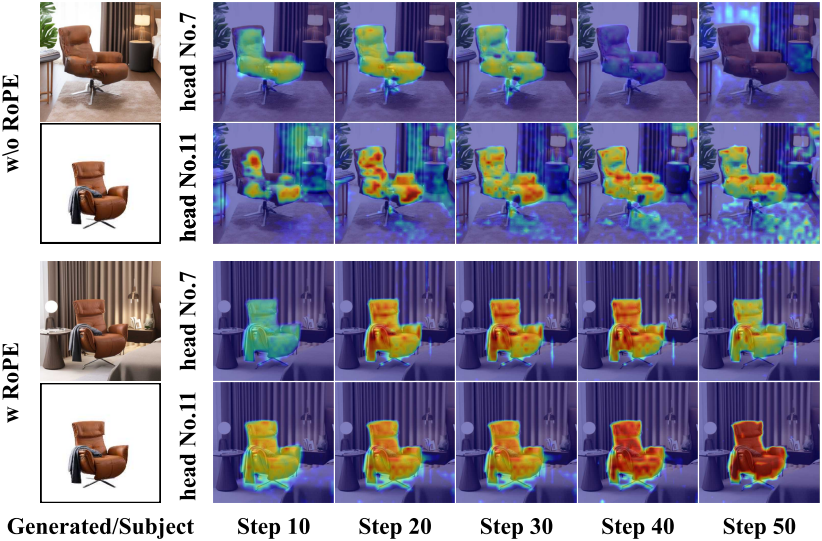
고품질의 피사체 feature를 얻은 후, subject-aware attention layer를 사용하여 피사체 feature와 latent feature를 융합하고, 이를 Self-Consistent Adapter를 통해 self-attention layer와 통합한다. 그러나 위치 임베딩을 통합하지 않고 피사체 feature를 subject-aware attention layer에 직접 입력할 경우, attention이 피사체의 텍스처 및 컨텐츠와 유사한 영역으로 분산되는 경향이 있다. 이로 인해 생성된 이미지에서 피사체의 텍스처와 부분적인 semantic은 보존되지만, 피사체의 형태와 윤곽이 눈에 띄게 변형되는 현상이 발생한다.
Latent feature와 피사체 feature 간의 cross-attention을 계산할 때 피사체 영역 외부의 위치에 대한 attention을 억제해야 한다. 따라서 저자들은 key 계산에 위치 인코딩을 통합하여 위치 정보를 효과적으로 활용하는 Shared Positional Embedding Anchor를 제안하였다. 이를 통해 attention 분산 현상을 억제하고 피사체 영역에 attention을 집중시킬 수 있다.
저자들은 base model의 RoPE를 재사용하여 subject-aware attention의 key에 매핑할 때 피사체 feature에 위치 임베딩을 추가하였다. 이러한 연산을 통해 피사체 feature와 latent space 간의 상호 작용이 피사체 윤곽의 동일한 로컬 영역에 집중되도록 하여 피사체 정보가 글로벌 컨텍스트에 미치는 영향을 완화할 수 있다.
Experiments
1. Comparisons
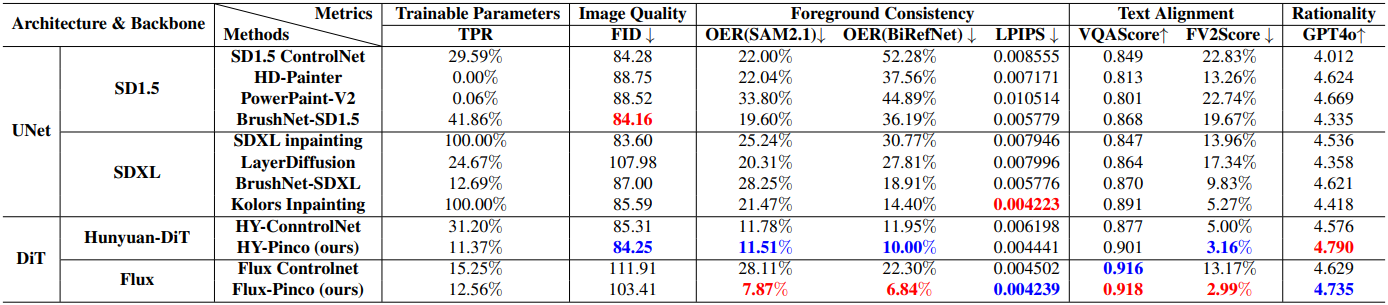
다음은 Pinco와 기존 방법들을 비교한 결과이다.

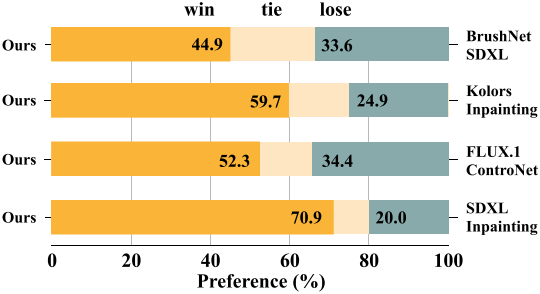
다음은 user study 결과이다.
2. Ablation Study
다음은 Pinco의 모듈들에 대한 ablation study 결과이다.


다음은 RoPE 유무에 따른 attention map을 비교한 것이다.
다음은 RoPE 유무에 따른 수렴 과정을 비교한 것이다.
