[논문리뷰] Person Image Synthesis via Denoising Diffusion Model (PIDM)
CVPR 2023. [Paper]
Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Jorma Laaksonen, Mubarak Shah, Fahad Shahbaz Khan
Mohamed bin Zayed University of AI | Australian National University | Linkoping University | Aalto University | University of Central Florida
22 Nov 2022
Introduction
포즈 기반 사람 이미지 합성 task는 사람의 이미지를 원하는 포즈와 모습으로 렌더링하는 것을 목표로 한다. 특히 외모는 주어진 소스 이미지로 정의되고 포즈는 일련의 키포인트로 정의된다. 포즈와 스타일 측면에서 합성된 사람 이미지를 제어하는 것은 애플리케이션에 중요한 필수 조건이다. 또한 생성된 이미지를 사용하여 사람 재식별과 같은 다운스트림 작업의 성능을 향상시킬 수 있다. 문제는 주어진 포즈 및 모양 정보와 밀접하게 일치하는 사실적인 출력을 생성하는 것이다.
사람 합성 문제는 일반적으로 단일 forward pass를 사용하여 원하는 포즈로 사람을 생성하려고 시도하는 GAN을 사용하여 해결된다. 그러나 새로운 포즈에서 일관된 구조, 외모 및 전반적인 신체 구성을 유지하는 것은 한 번에 달성하기 어려운 task이다. 결과 출력은 특히 가려진 신체 부위를 합성할 때 일반적으로 변형된 텍스처와 비현실적인 신체 모양을 생성한다. 또한 GAN은 학습이 불안정하고 생성된 샘플의 다양성이 제한되는 경향이 있다. 마찬가지로 VAE 기반 솔루션은 상대적으로 안정적이지만 디테일이 흐릿하기 때문에 GAN보다 낮은 품질의 출력을 제공한다.
본 논문에서는 사람 합성 문제를 원본 이미지의 사람을 타겟 포즈로 점진적으로 전송하는 일련의 diffusion step으로 구성한다. Diffusion model은 입력 샘플에 noise를 천천히 추가한 다음 (forward pass) noise에서 원하는 샘플을 재구성하는 Markov chain (reverse pass)을 정의한다. 이러한 방식으로 복잡한 전송 특성을 한 번에 모델링하는 대신 제안된 PIDM은 문제를 일련의 forward-backward diffusion step으로 분해하여 그럴듯한 전송 궤적을 학습한다. PIDM은 사람의 포즈와 외모의 복잡한 상호 작용을 모델링할 수 있으며 더 높은 다양성을 제공하고 질감 변형 없이 사실적인 결과를 이끌어낸다. 인체 부위를 나타내는 parser map 등으로 주요 포즈 변화를 처리하는 기존 접근 방식과 달리, 본 논문의 접근 방식은 이러한 상세한 주석 없이 사실적이고 실제적인 이미지를 생성하는 방법을 학습할 수 있다.
Proposed Method
Motivation
기존 포즈 기반 사람 합성 방법은 모델이 단일 forward pass에서 소스 이미지의 스타일을 지정된 타겟 포즈로 직접 전송하려고 시도하는 GAN 기반 프레임워크에 의존한다. 공간 변환의 복잡한 구조를 직접 캡처하는 것은 매우 어렵기 때문에 현재 CNN 기반 아키텍처는 옷감 텍스처 패턴의 복잡한 디테일을 전송하는 데 어려움을 겪는 경우가 많다. 결과적으로 기존 방법은 눈에 띄는 아티팩트를 생성하며 generator가 주어진 소스 이미지에서 가려진 신체 영역을 추론해야 할 때 더욱 아티팩트가 분명해진다.
복잡한 구조를 하나의 단계로 직접 학습하는 대신 연속적인 중간 전송 단계를 사용하여 최종 이미지를 유도하면 학습을 더 간단하게 만들 수 있다. 점진적 변환 체계를 가능하게 하기 위해 생성 프로세스를 여러 조건부 denoising diffusion step으로 나누는 diffusion 기반 사람 이미지 합성 프레임워크인 Person Image Diffusion Model (PIDM)을 도입한다. 각 step은 비교적 모델링이 간단하다. Diffusion step의 단일 step은 간단한 가우시안 분포로 근사화할 수 있다. PIDM은 다음과 같은 이점을 있다.
- 고품질 합성: 기존의 GAN 기반 방법과 달리 복잡한 천 텍스처와 극단적인 포즈 각도를 처리할 때 사실적인 결과를 생성한다.
- 안정적인 학습: GAN 기반 방법보다 더 나은 학습 안정성과 모드 커버리지를 나타낸다. 또한 hyperparameter에 덜 취약하다.
- 의미 있는 보간: Latent space에서 매끄럽고 일관된 선형 보간이 가능하다.
- 유연성: 기존 모델은 일반적으로 task 종속적이며 다양한 작업에 대해 서로 다른 모델이 필요하다. 반대로 PIDM은 여러 task를 수행할 수 있다. 또한 다양한 다운스트림 task가 가능한 diffusion model의 유연성과 제어 가능성을 상속한다.
Overall Framework
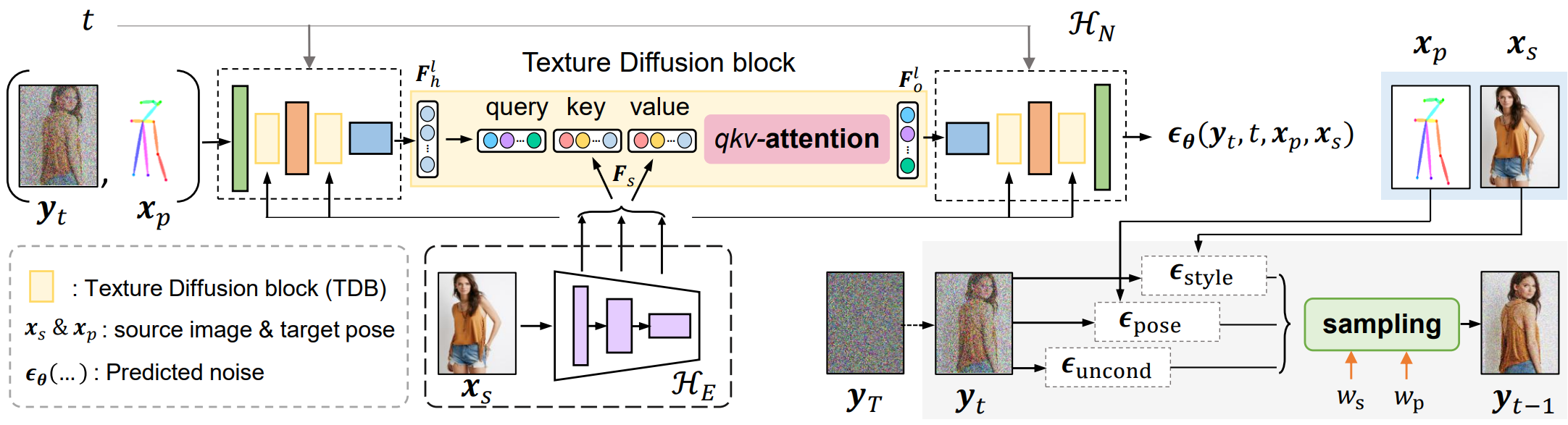
위 그림은 제안된 생성 모델의 개요를 보여준다. 원본 이미지 $x_s$와 타겟 포즈 $x_p$가 주어지면 조건부 diffusion model $p_\theta (y \vert x_s, x_p)$를 학습하는 것이 목표이다. 여기서 최종 출력 이미지 $y$는 타겟 포즈 일치 요구 사항을 충족할 뿐만 아니라 $x_s$와 동일한 스타일 조건을 가져야 한다.
PIDM에서 denoising network $\epsilon_\theta$는 noise 예측 모듈 \(\mathcal{H}_N\)과 텍스처 인코더 \(\mathcal{H}_E\)로 구성된 UNet 기반 디자인이다. 인코더 \(\mathcal{H}_E\)는 소스 이미지 $x_s$의 텍스처 패턴을 인코딩한다. 멀티스케일 feature를 얻기 위해 \(\mathcal{H}_E\)의 여러 레이어에서 출력을 파생하여 누적 feature 표현 $F_s = [f_1, f_2, \cdots, f_m]$를 생성한다. 소스 이미지 분포에서 noise 예측 모듈 \(\mathcal{H}_N\)으로 풍부한 멀티스케일 텍스처 패턴을 전송하기 위해 \(\mathcal{H}_N\)의 서로 다른 레이어에 포함된 cross-attention 기반 Texture diffusion blocks (TDB)을 사용한다. 이를 통해 네트워크는 원본과 타겟 모양 간의 대응 관계를 완전히 활용하여 왜곡 없는 이미지를 얻을 수 있다. Inference 하는 동안 샘플링된 이미지에서 $x_s$와 $x_p$의 조건부 신호를 증폭하기 위해 샘플링 기술에서 classifier-free guidance를 조정하여 disentangled guidance를 달성한다. 생성의 전반적인 품질을 향상시킬 뿐만 아니라 텍스처 패턴의 정확한 전송을 보장한다.
1. Texture-Conditioned Diffusion Model
PIDM의 생성 모델링 방식은 DDPM을 기반으로 한다. DDPM의 일반적인 아이디어는 타겟 분포 $y_0 \sim q(y_0)$에서 샘플링된 데이터에 점진적으로 noise를 추가하는 diffusion process를 설계하고 reverse process는 역 매핑을 학습하려고 시도하는 것이다. Denoising diffusion process는 결국 Gaussian noise $y_T \sim \mathcal{N} (0, I)$을 $T$개의 step으로 타겟 데이터 분포로 변환한다. 기본적으로 이 체계는 복잡한 분포 모델링 문제를 일련의 간단한 denoising 문제로 나눈다. DDPM의 forward diffusion 경로는 다음과 같은 조건부 분포를 갖는 Markov chain이다.
\[\begin{equation} q(y_t \vert y_{t-1}) = \mathcal{N} (y_t; \sqrt{1 - \beta_t} y_{t-1}, \beta_t I) \end{equation}\]$\beta_1, \beta_2, \cdots \beta_T$는 $\beta_t \in (0, 1)$인 고정 분산 schedule이다. 임의의 timestep $t$에서 closed form으로 $q(y_t \vert y_0)$에서 샘플링할 수 있다.
\[\begin{equation} y_t = \sqrt{\vphantom{1} \bar{\alpha}_t} y_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \\ \alpha_t = 1 - \beta_t, \quad \bar{\alpha}_t = \prod_{i=1}^t \alpha_i \end{equation}\]True posterior $q(y_{t-1} \vert y_t)$는 다음 parameterization을 통해 $y_{t−1}$의 평균과 분산을 예측하기 위해 심층 신경망에 의해 근사화될 수 있다.
\[\begin{equation} p_\theta (y_{t-1} \vert y_t, x_p, x_s) = \mathcal{N} (y_{t-1}; \mu_\theta (y_t, t, x_p, x_s), \Sigma_\theta (y_t, t, x_p, x_s)) \end{equation}\]Noise prediction module \(\mathcal{H}_N\)
$\mu_\theta$를 직접 도출하는 대신 noise 예측 모듈 \(\mathcal{H}_N\)을 사용하여 noise $\epsilon_\theta (y_t, t, x_p, x_s)$를 예측한다. Noisy한 이미지 $y_t$는 타겟 포즈 $x_p$와 concat되고 noise를 예측하기 위해 \(\mathcal{H}_N\)을 통과한다. $x_p$는 denoising process를 guide하고 중간 noise 표현과 최종 이미지가 주어진 스켈레톤 구조를 따르도록 한다. 원하는 텍스처 패턴을 noise predictor에 주입하기 위해 Texture diffusion blocks (TDB)를 통해 텍스처 인코더 \(\mathcal{H}_E\)의 멀티스케일 feature를 제공한다. Denoising process를 학습하기 위해 먼저 Gaussian noise를 $y_0$에 추가하여 노이즈 샘플 $y_t \sim q (y_t \vert y_0)$를 생성한 다음 조건부 denoising 모델 $\epsilon_\theta (y_t, t, x_p, x_s)$를 학습하여 추가된 noise를 예측한다.
\[\begin{equation} L_\textrm{mse} = \mathbb{E}_{t \sim [1, T], y_0 \sim q(y_0), \epsilon} [\| \epsilon - \epsilon_\theta (y_t, t, x_p, x_s) \|^2] \end{equation}\]iDDPM은 더 적은 step이 필요한 DDPM의 개선된 버전으로 효과적인 학습 전략을 제시하고 추가 loss 항 $L_\textrm{vlb}$를 적용하여 분산 $\Sigma_\theta$를 학습한다. 본 논문이 채택한 전체 하이브리드 목적 함수는 다음과 같다.
\[\begin{equation} L_\textrm{hybrid} = L_\textrm{mse} + L_\textrm{vlb} \end{equation}\]2. Texture Diffusion Blocks (TDB)
Noise 예측 branch 내에서 소스 이미지의 스타일을 혼합하기 위해 \(\mathcal{H}_N\)의 다른 레이어에 내장된 cross-attention 기반 TDB unit을 사용한다. $F_h^l$를 noise 예측 branch의 레이어 $l$에 있는 noise feature라고 하자. TDB unit에 대한 입력으로 \(\mathcal{H}_E\)에서 파생된 멀티스케일 텍스처 feature $F_s$가 주어지면 attention 모듈은 기본적으로 각 query 위치와 관련하여 관심 영역을 계산한다. 이는 이후 원하는 텍스처 패턴 방향으로 주어진 noisy한 샘플을 denoising하는 데 중요하다. Key $K$와 value $V$는 \(\mathcal{H}_E\)에서 파생되는 반면 query $Q$는 noise feature $F_h^l$에서 가져온다. Attention 연산은 다음과 같이 공식화된다.
\[\begin{equation} Q = \phi_q^l (F_h^l), \quad K = \phi_k^l (F_s), \quad V = \phi_v^l (F_s) \\ F_\textrm{att}^l = \frac{QK^\top}{\sqrt{C}}, \quad F_o^l = W^l \textrm{softmax} (F_\textrm{att}^l) V + F_h^l \end{equation}\]여기서 $\phi_q^l$, $\phi_k^l$, $\phi_v^l$는 레이어별 1$\times$1 convolution 연산이다. $W^l$은 cross-attended feature $F_0^l$를 생성하기 위한 학습 가능한 가중치이다. 특정 해상도에서 feature를 위해 TDB를 채택한다.
3. Disentangled Guidance based Sampling
모델이 조건부 분포를 학습하면 먼저 Gaussian noise $y_T \sim \mathcal{N}(0, I)$을 샘플링한 다음 $p_\theta (y_{t−1} \vert y_t, x_p, x_s)$에서 샘플링하여 inference를 수행한다 ($t = T$에서 $t = 1$까지 반복적으로). 생성된 이미지는 사실적으로 보이지만 조건부 소스 이미지와 타겟 포즈 입력과 강한 상관 관계가 없는 경우가 많다. 샘플링된 이미지에서 컨디셔닝 신호 $x_s$와 $x_p$의 효과를 증폭하기 위해 다중 조건 샘플링 절차에 classifier-free guidance를 적용한다. 스타일 요구 사항을 충족할 뿐만 아니라 타겟 포즈 입력과 일치하는 이미지를 샘플링하려면 스타일과 포즈 모두에 대해 disentangled guidance를 사용하는 것이 중요하다. Disentangled guidance를 활성화하기 위해 다음 방정식을 사용한다.
\[\begin{aligned} \epsilon_\textrm{cond} &= \epsilon_\textrm{uncond} + w_p \epsilon_\textrm{pose} + w_s \epsilon_\textrm{style} \\ \epsilon_\textrm{uncond} &= \epsilon_\theta (y_t, t, \emptyset, \emptyset) \\ \epsilon_\textrm{pose} &= \epsilon_\theta (y_t, t, x_p, \emptyset) - \epsilon_\textrm{uncond} \\ \epsilon_\textrm{style} &= \epsilon_\theta (y_t, t, \emptyset, x_s) - \epsilon_\textrm{uncond} \end{aligned}\]여기서 $w_p$와 $w_s$는 각각 포즈와 스타일의 guidance scale이다. 실제로, diffusion model은 샘플의 $\eta$%에 대해 조건 변수 $x_p$와 $x_s = \emptyset$를 랜덤하게 설정하여 학습 중에 conditional 및 unconditional 분포를 모두 학습하므로 $\epsilon_\theta (y_t, t, \emptyset, \emptyset)$는 $p(y_0)$에 더 가까워진다.
Experiments
- 데이터셋: DeepFashion In-shop Clothes Retrieval Benchmark, Market-1501
- 구현 디테일
- $T = 1000$, linear noise schedule
- EMA decay: 0.9999
- Batch size: 8
- Optimizer: Adam
- Learning rate: $2 \times 10^{-5}$
- $\eta = 10$, $w_p = w_s = 2.0$
1. Quantitative and Qualitative Comparisons
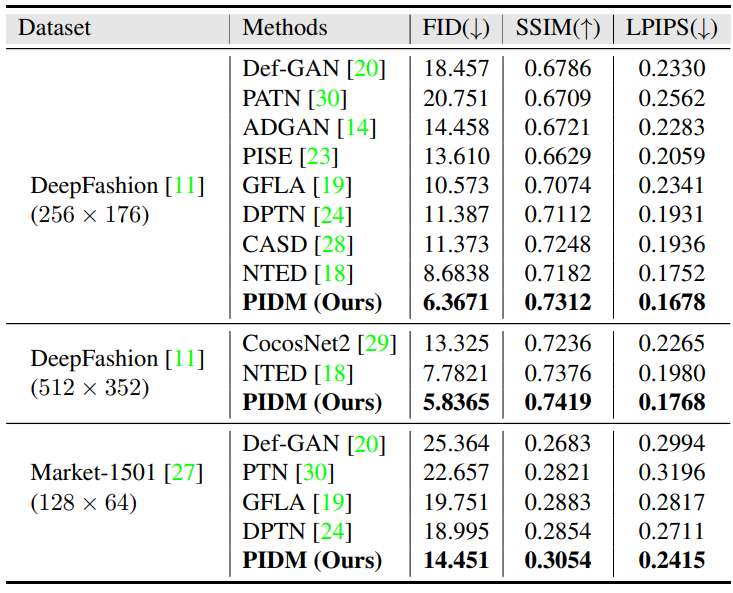
다음은 SOTA 모델들과 정량적으로 비교한 표이다.
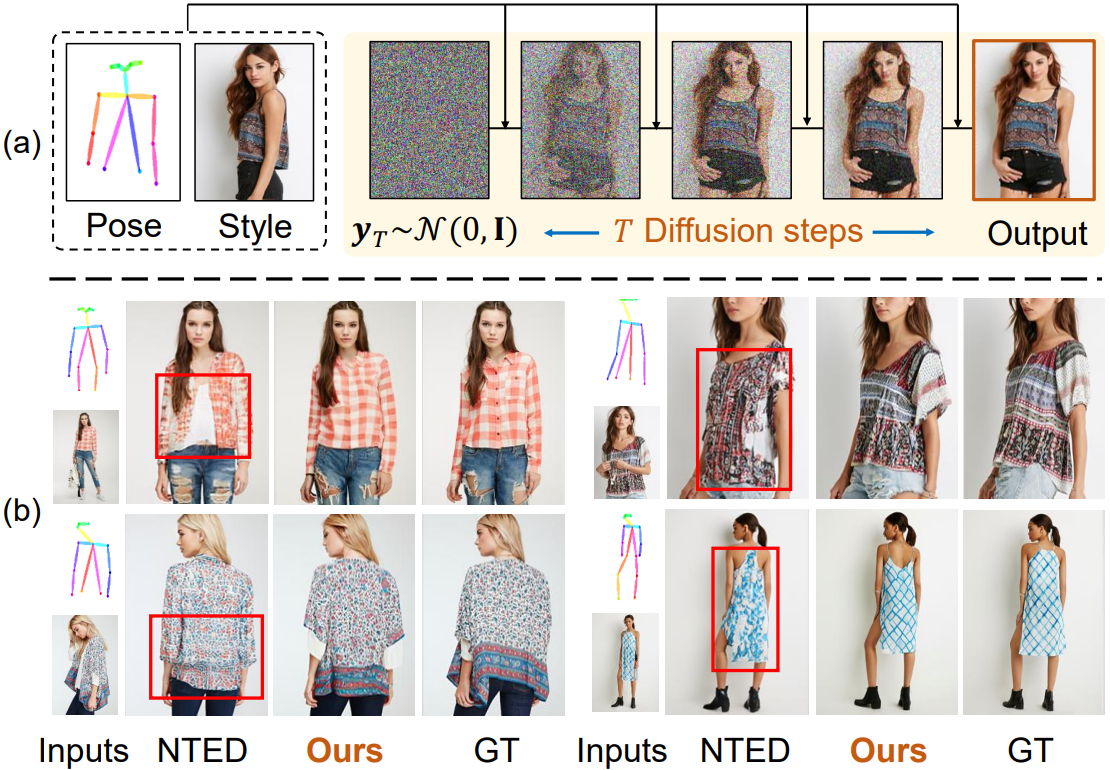
다음은 DeepFashion 데이터셋에서 SOTA 모델들과 정성적으로 비교한 결과이다.

다음은 Market-1501 데이터셋에서 SOTA 모델들과 정성적으로 비교한 결과이다.

2. User Study
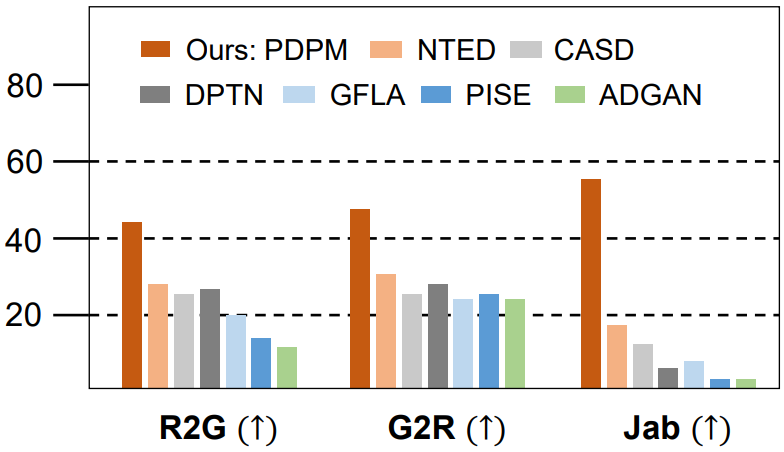
다음은 DeepFashion 데이터셋에서의 user study 결과이다.
3. Ablation Study
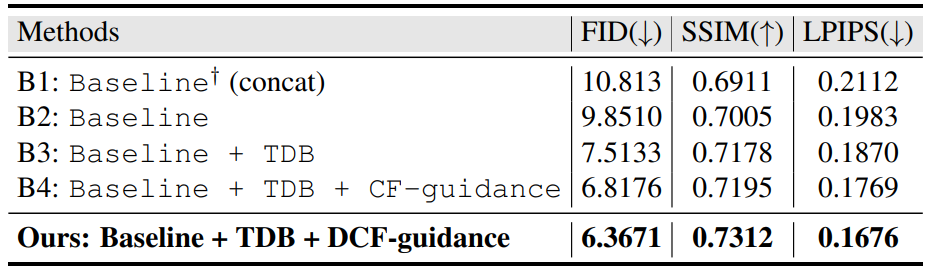
다음은 texture diffusion block (TDB)와 distangled classifier-free (DCF) guidance의 영향을 나타낸 표이다. (DeepFashion)
다음은 정성적 ablation 결과이다.

4. Appearance Control and Editing
다음은 외형 제어 및 편집 결과이다.


(a)는 이진 마스크 $m$을 사용하여
로 레퍼런스 이미지에 스타일을 입힌 것이다. (b)는 noise $y_T^1$과 $y_T^2$ 사이에 spherical linear interpolation를 사용하고 style feature $F_s^1$과 $F_s^2$에 linear interpolation을 사용하여 스타일을 보간한 것이다.
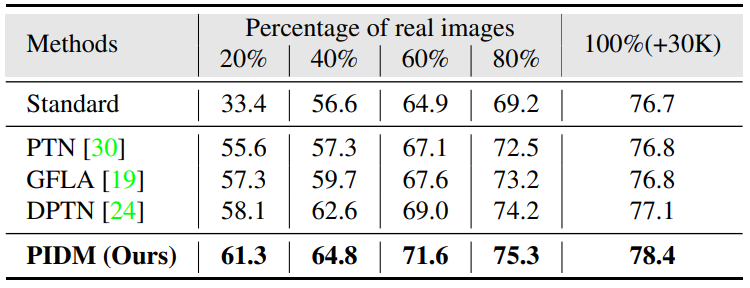
5. Application to Person Re-identification
다음은 여러 방법으로 생성된 이미지를 사용한 ResNet50 backbone에서의 re-ID 결과이다.