[논문리뷰] Photoswap: Personalized Subject Swapping in Images
NeurIPS 2023. [Paper] [Page]
Jing Gu, Yilin Wang, Nanxuan Zhao, Tsu-Jui Fu, Wei Xiong, Qing Liu, Zhifei Zhang, He Zhang, Jianming Zhang, HyunJoon Jung, Xin Eric Wang
University of California, Santa Cruz | Adobe
29 May 2023

Introduction
개인화된 피사체 교환 (Personalized Subject Swapping)은 고유한 일련의 문제가 있는 복잡한 task이다. 이 task에는 원래 피사체와 대체 피사체 모두에 내재된 시각적 개념에 대한 심오한 이해가 필요하다. 동시에 새로운 피사체를 기존 이미지에 매끄럽게 통합할 것을 요구한다. 피사체 교환의 중요한 목표 중 하나는 대체 피사체의 유사한 포즈를 유지하는 것이다. 교체된 피사체가 원래의 포즈와 장면에 매끄럽게 맞아 자연스럽고 조화로운 시각적 구성을 만드는 것이 중요하다. 이를 위해서는 조명 조건, 원근감, 전반적인 미적 일관성과 같은 요소를 신중하게 고려해야 한다. 대체 피사체를 이러한 요소와 효과적으로 혼합함으로써 최종 이미지는 연속성과 진정성을 유지한다.
기존 이미지 편집 방법은 이러한 문제를 해결하는 데 부족하다. 이러한 기술 중 다수는 글로벌한 편집으로 제한되며 새로운 피사체를 기존 이미지에 매끄럽게 통합하는 데 필요한 기교가 부족하다. 예를 들어 대부분의 T2I(text-to-image) 모델의 경우 약간의 즉각적인 변경으로 완전히 다른 이미지가 될 수 있다. 최근 연구들은 사용자 브러시, semantic 레이아웃, 스케치와 같은 추가 입력으로 생성을 제어할 수 있다. 그러나 객체 형태, 질감, 아이덴티티의 생성에 대한 사용자의 의도를 따르도록 생성 프로세스를 guide하는 것은 여전히 어려운 일이다. 다른 접근법은 합성 이미지 생성의 맥락에서 이미지 콘텐츠를 편집하기 위해 텍스트 프롬프트를 사용하는 가능성을 탐구했다. 이러한 방법은 기존 이미지의 피사체를 사용자가 지정한 피사체로 교체하는 복잡한 작업을 처리할 수 있는 완전한 능력을 갖추고 있지 않다.
따라서 본 논문은 이미지에서 개인화된 피사체 교환을 위해 사전 학습된 diffusion model을 활용하는 새로운 프레임워크인 Photoswap을 제시한다. 본 논문의 접근 방식에서 diffusion model은 피사체($O_t$)의 개념을 나타내는 방법을 학습한다. 그러면 원본 이미지 생성 과정에서 저장된 대표 attention map과 attention 출력은 대상 이미지의 생성 과정으로 옮겨져 타겟이 아닌 픽셀은 그대로 두고 새로운 타겟을 생성하게 된다. Photoswap은 이미지에서 피사체를 매끄럽게 교체할 수 있을 뿐만 아니라 교체된 피사체의 포즈와 이미지의 전체적인 일관성을 유지한다.
The Photoswap Method
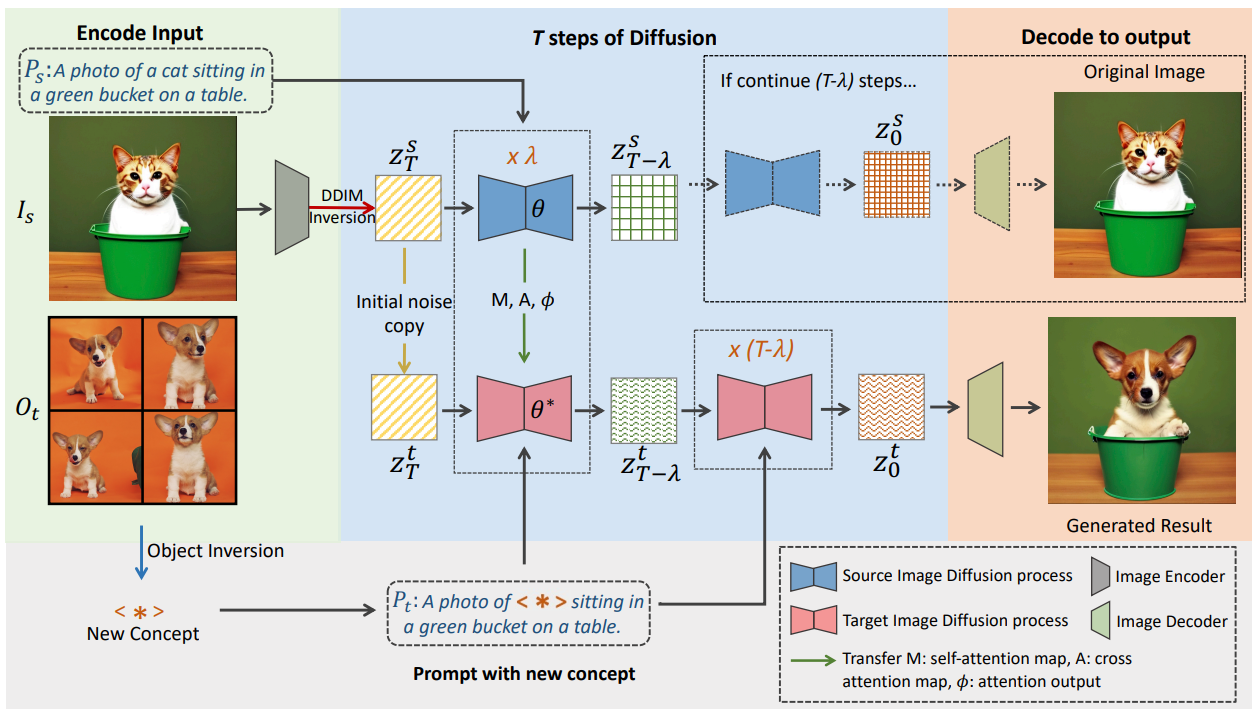
개인화된 타겟 피사체 $O_t$의 몇 가지 레퍼런스 이미지를 제공하는 Photoswap은 주어진 소스 이미지 $I_s$에서 다른 타겟 $O_s$와 원활하게 교체할 수 있다. Photoswap 파이프라인은 위 그림에 설명되어 있다. 타겟 피사체 $O_t$의 시각적 개념을 학습하기 위해 레퍼런스 이미지로 diffusion model을 fine-tuning하고 특수 토큰 $\ast$을 사용하여 $O_t$를 나타내는 object inversion을 수행한다. 그런 다음 소스 이미지에서 피사체를 대체하기 위해 먼저 소스 이미지 $I_s$를 재구성하는 데 사용할 수 있는 noise $z_T$를 얻는다. 다음으로 U-Net을 통해 $M$, $A$, $\phi$를 포함하는 self-attention과 cross-attention 레이어에서 필요한 feature map과 attention 출력을 얻는다. 마지막으로 $z_T$와 타겟 텍스트 프롬프트 $P_t$로 컨디셔닝되는 타겟 이미지 생성 프로세스 중에 처음 $\lambda$개의 step에서 이러한 중간 변수($M$, $A$, $\phi$)는 소스 이미지 생성 프로세스 중에 얻은 해당 변수로 대체된다. 나머지 $(T − \lambda)$개의 step에서는 attention 교환이 필요하지 않으며 최종 결과 이미지를 얻기 위해 평소와 같이 denoising process를 계속할 수 있다.
1. Visual Concept Learning
피사체 교환은 피사체의 아이덴티티와 특정 특성에 대한 철저한 이해가 필요하다. 이 지식을 통해 원본 피사체와 일치하는 정확한 표현을 생성할 수 있다. 피사체의 아이덴티티는 형태, 비율, 질감 등 이미지의 구도와 원근법에 영향을 미치며 전체적인 요소 배치에 영향을 미친다. 그러나 기존의 diffusion model은 text-to-image 생성 모델을 위한 학습 데이터에 개인화된 피사체가 포함되지 않기 때문에 가중치에 타겟 피사체 $O_t$에 대한 정보가 부족하다. 이 한계를 극복하고 주어진 레퍼런트 세트에서 시각적으로 일관된 피사체 변형을 생성하려면 text-to-image diffusion model을 정확하게 개인화해야 한다. 최근 연구들은 이러한 “개인화”를 위해 특정 피사체와 관련된 고유한 토큰으로 diffusion model을 fine-tuning하는 것과 같은 다양한 방법을 도입했다. 본 논문의 실험에서는 주로 시각적 개념 학습 방법으로 DreamBooth를 활용한다.
2. Controllable Subject Swapping via Training-free Attention Swapping
피사체 교환은 소스 이미지의 공간 레이아웃과 기하학을 유지하면서 동일한 포즈 내에서 새로운 피사체 개념을 통합해야 하는 흥미로운 문제를 제기한다. 이를 위해서는 소스 이미지 정보를 캡슐화하는 소스 latent 변수의 중요한 feature를 보존하고 개념 토큰을 전달하는 타겟 이미지 텍스트 프롬프트 $P_t$의 영향을 활용하여 이미지에 새로운 피사체를 주입해야 한다.
생성된 이미지의 레이아웃을 조율하는 attention layer의 중심 역할은 이전 연구들에서 잘 확립되었다. 타겟이 아닌 픽셀을 그대로 유지하기 위해 중요한 변수를 타겟 이미지 생성 프로세스로 전송하여 타겟 이미지 $I_t$의 생성을 조율한다. 여기에서 attention layer 내의 뚜렷한 중간 변수가 피사체 교환의 맥락에서 제어 가능한 생성에 어떻게 기여할 수 있는지 탐구한다.
소스 이미지 생성 프로세스 내에서 cross-attention map을 $A_i^s$로, self-attention map을 $M_i^s$로, cross-attention 출력을 $\psi_i^s$로, self-attention 출력을 $\phi_i^s$로 표시한다. 타겟 이미지 생성 프로세스에서 해당 변수는 $A_i^t$, $M_i^t$, $\psi_i^t$, $\phi_i^t$로 표시되며, 여기서 $i$는 현재 diffusion step을 나타낸다.
Self-attention 블록에서 latent feature $z_i$는 query $q_i$, key $k_i$, value $v_i$에 project된다. 다음 식을 사용하여 self-attention 블록의 출력 $\phi_i$를 얻는다.
\[\begin{equation} \phi_i = M_i v_i, \quad \textrm{where} \quad M_i = \textrm{Softmax} (q_i k_i^\top) \end{equation}\]여기서 $M_i$는 self-attention map이고 $\phi_i$는 self-attention 레이어의 feature 출력이다. Cross-attention 블록의 출력 $\psi_i$는 다음과 같다.
\[\begin{equation} \psi_i = A_i v_i, \quad \textrm{where} \quad A_i = \textrm{Softmax} (q_i k_i^\top) \end{equation}\]여기서 $A_i$는 cross-attention map이다. Self-attention과 cross-attention 모두에서 attention map $M_i$와 $A_i$는 $q_i$와 $k_i$ 사이의 유사성과 관련되어 $v_i$의 정보 조합을 지시하는 가중치 역할을 한다. 본 논문에서 diffusion model의 조작은 U-Net 내에서 self-attention과 cross-attention, 특히 $\phi$, $M$, $A$를 교환하고 $\psi$는 변경하지 않고 유지하는 데 중점을 둔다.

Self-attention map $M$은 linear projection 후 공간적 feature 내 유사성을 계산하므로 생성 프로세스에서 공간적 콘텐츠를 관리하는 데 중추적인 역할을 한다. 위 그림은 이미지 생성 중에 $M$을 캡처하고 특이값 분해(SVD)를 통해 주요 구성 요소를 강조 표시한 것이다. 이 시각화는 $M$과 생성된 이미지의 형상과 내용 간의 높은 상관관계를 나타낸다.
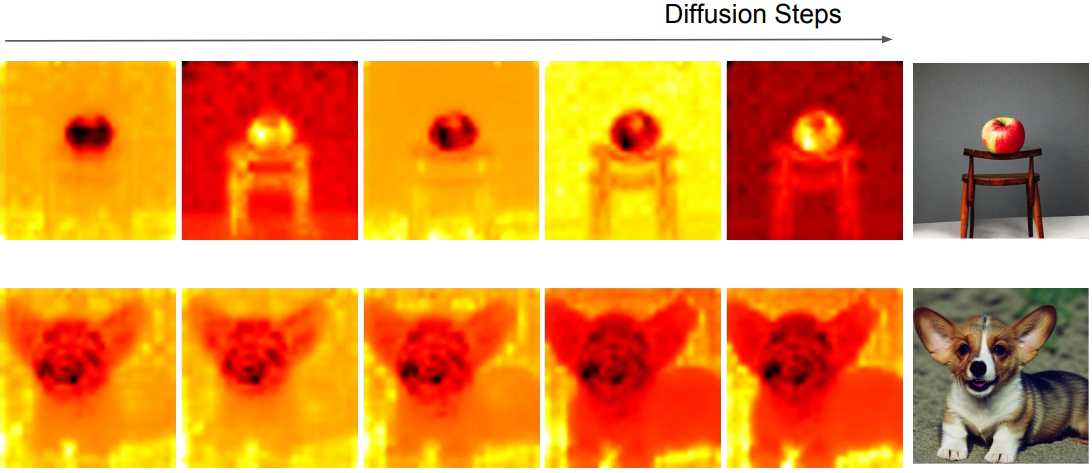
또한, 위와 같이 diffusion process의 전체 step을 시각화할 때, 레이아웃 정보가 초기 step부터 self-attention에 미러링됨을 확인할 수 있다. 이 통찰력은 새롭고 고유한 레이아웃의 출현을 방지하기 위해 조기에 교환을 시작해야 할 필요성을 강조한다.
Cross-attention map $A$는 latent 변수와 텍스트 프롬프트에 의해 결정되며 $A_i^s v$는 텍스트 프롬프트에서 얻은 정보의 가중 합으로 볼 수 있다. 타겟 이미지 생성 프로세스 중에 $A_i^s$를 $A_i^t$로 복사하면 원본 이미지와 타겟 이미지 간의 레이아웃 정렬이 향상된다.
Self-attention 레이어에서 나오는 self-attention 출력 $\phi$는 텍스트 feature을 사용한 직접 계산과 관계없이 소스 이미지의 풍부한 콘텐츠 정보를 캡슐화한다. 따라서 $\phi_i^t$를 $\phi_i^s$로 바꾸면 원본 이미지의 컨텍스트와 구성이 더 잘 보존된다. $\phi$가 cross-attention map $A$보다 이미지 레이아웃에 더 큰 영향을 미친다.
Cross-attention 레이어에서 나오는 cross-attention 출력 $\psi$는 타겟 피사체의 시각적 개념을 구현한다. Cross-attention 출력 $\psi_i^s$를 $\psi_i^t$로 대체하면 타겟 텍스트 프롬프트 $P_t$의 모든 정보가 지워진다. $k_i^t$와 $v_i^t$가 타겟 프롬프트 임베딩의 projection임을 감안할 때 타겟 피사체의 아이덴티티를 보호하기 위해 $\psi_i^s$를 변경하지 않고 유지한다.
Algorithm 1은 전체 Photoswap 알고리즘의 pseudo code이다.

Experiments
- 구현 디테일
- DDIM inversion을 사용하여 이미지를 초기 noise로 변환
- Inference 시 50 denoising step의 DDIM sampling 사용 (classifier-free guidance 7.5)
- $\lambda_A = 20$, $\lambda_M = 25$, $\lambda_\phi = 10$
- 타겟 프롬프트 $P_t$는 개체 토큰이 새 개념 토큰으로 대체되는 소스 프롬프트 $P_s$
- 개념 학습은 DreamBooth를 주로 사용하여 Stable Diffusion 2.1을 fine-tuning하여 35개의 이미지에서 새로운 개념을 학습
- Learning rate: $10^{-6}$
- 학습 step: 80,000
- Optimizer: Adam
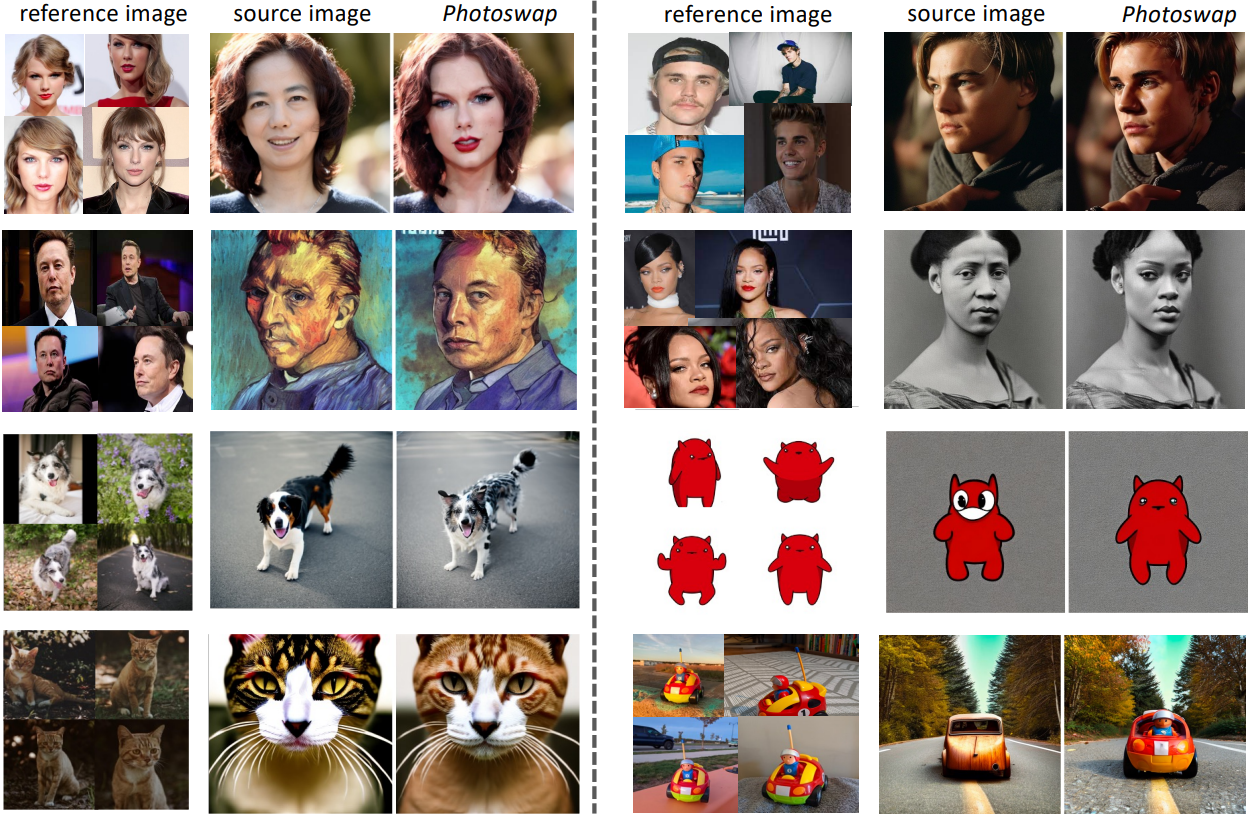
1. Personalized Subject Swapping Results
다음은 다양한 개체와 이미지 도메인에 대한 Photoswap 결과이다.
다음은 다중 피사체(a)와 가려진 피사체(b)에 대한 Photoswap 결과이다.

2. Comparison with Baseline Methods
다음은 P2P+DreamBooth와 정성적으로 비교한 결과이다.

다음은 사람들이 평가한 결과이다.

3. Controlling Subject Identity
다음은 $\lambda_M$에 대한 ablation study 결과이다.

$\lambda_M$을 증가시키면 생성된 이미지가 소스 이미지의 스타일과 아이덴티티와 더 비슷해지고 레퍼런스 피사체와 덜 비슷해진다.
4. Attention Swapping Step Analysis
다음은 다양한 swapping step에 대한 결과이다.

5. Results of Other Concept Learning Methods
다음은 개념 학습 모듈로 DreamBooth 대신 Text Inversion을 사용하였을 때의 결과이다.

6. Ethics Exploration
다음은 다양한 인종의 실제 사람 얼굴 이미지에 대한 결과이다.

7. Failure Cases

두 가지 일반적인 실패 사례가 있다.
- 모델은 손을 정확하게 재현하는 데 어려움을 겪는다. 피사체에 손과 손가락이 포함된 경우 교환 결과가 원래 손 동작이나 손가락 수를 정확하게 반영하지 못하는 경우가 많다. 이 문제는 Stable Diffusion에서 상속받은 문제일 수 있다.
- 이미지가 복잡한 추상 정보로 구성되어 있을 때 어려움을 겪을 수 있다. (ex. 화이트보드의 복잡한 공식)