[논문리뷰] Personalized Residuals for Concept-Driven Text-to-Image Generation
CVPR 2024. [Paper] [Page]
Cusuh Ham, Matthew Fisher, James Hays, Nicholas Kolkin, Yuchen Liu, Richard Zhang, Tobias Hinz
Georgia Institute of Technology | Adobe Inc.
21 May 2023

Introduction
대규모 text-to-image (T2I) diffusion model은 입력 텍스트를 따르는 고품질 이미지를 생성한다. 그러나 이러한 모델들은 본질적으로 특정 개념의 identity에 대한 정보를 인코딩하지 않으므로 생성된 이미지에 나타날 특정 인스턴스를 지정하는 제어가 제한된다. 최근에는 이를 해결하기 위해 새로운 환경과 스타일에서 특정 개념을 생성할 수 있도록 모델을 개인화하는 방법들이 제안되었다.
일부 개인화 방법들에서는 모델의 파라미터나 입력을 직접 fine-tuning하여 학습 데이터를 재구성한다. 이러한 접근 방식은 모든 종류의 개념에 적용될 수 있지만 fine-tuning은 개념별로 수행되어야 하며 각각에 대해 서로 다른 파라미터를 저장해야 한다. 다른 방법은 특정 도메인에 특정한 인코더를 학습시키고 diffusion model을 한 번 fine-tuning하여 인코더의 임베딩을 사용하여 해당 도메인 내의 특정 개념을 재구성한다. 후자 접근 방식의 장점은 모든 개념에 대해 재학습이 필요하지 않으며 대신 주어진 도메인에서 새로운 개념을 즉시 생성하는 데 사용할 수 있다는 것이다. 그러나 이 방식은 하나의 도메인으로 제한되며 인코더를 학습시키려면 대규모 데이터셋이 필요하다.
본 논문은 전자의 방식을 따른다. 즉, 도메인에 제약이 없도록 각 개념에 대한 모델의 파라미터를 fine-tuning한다. 이 접근 방식의 주요 과제는 모델이 원래 학습한 개념을 망각하는 것을 완화하기 위한 정규화의 필요성과 각 개념에 대한 새로운 파라미터들을 fine-tuning하는 데 필요한 계산량이다. 가장 일반적인 정규화 방식은 파라미터를 fine-tuning하는 동안 레퍼런스 이미지와 함께 대상 개념과 동일한 도메인의 이미지를 사용하는 것이다. 정규화 이미지의 선택은 최종 출력의 품질에 영향을 미친다. 또한 각 개념에 대해 완전히 새로운 모델을 fine-tuning하는 큰 오버헤드를 해결하기 위해 많은 접근 방식에서는 파라미터의 부분집합 또는 모델에 대한 입력만 fine-tuning한다.
본 논문에서는 학습 가능한 파라미터의 수를 더욱 줄이고 정규화 이미지에 의존하지 않는다. 대부분의 기존 방식들은 cross-attention layer의 key와 value를 fine-tuning하는 데 중점을 두는 반면, 본 논문에서는 대신 각 cross-attention layer 이후의 output projection conv layer의 가중치에 대하여 LoRA를 사용한다. 이를 통해 기존 방식보다 더 적은 수의 파라미터를 fine-tuning할 수 있다 (기본 모델의 약 0.1%). 또한 본 논문의 방식에는 정규화 이미지가 필요하지 않으므로 정규화 이미지를 얻기 위해 적절한 전략을 찾을 필요가 없기 때문에 접근 방식이 더 간단해지고 추가 학습이 필요하지 않으므로 더 빠르다.
저자들은 주어진 이미지를 개인화하기 위한 macro class의 선택이 성능에 영향을 미친다는 것을 보여주었다. 예를 들어 “Lamborghini” 대신 “car”를 사용하는 것은 결과의 품질에 영향을 미친다. 이미지의 필요성을 제거하면 추가 종속성이 제거되고 수동 선택의 필요성이 줄어든다.
또한 많은 개인화 방법들은 대상 개념에 어느 정도 overfitting되어 특정 배경을 렌더링하거나 새 물체를 추가하는 데 어려움을 겪는다. 이러한 시나리오를 위해 본 논문에서는 원본 모델과 함께 fine-tuning된 residual을 사용하여 각각 개념과 이미지의 나머지 부분을 생성할 수 있는 localized attention-guided (LAG) sampling을 제안하였다. 각 timestep에서 diffusion model의 cross-attention layer의 attention map을 사용하여 생성된 이미지에서 개념의 위치를 예측한 다음 personalized residual로부터 생성된 feature를 예측 영역에만 적용한다. 이미지의 나머지 부분은 원본 모델에 의해 생성된다. 따라서 overfitting으로 인해 특정 배경이나 관련 없는 물체를 생성하는 능력을 잃지 않도록 보장한다. 또한 이 샘플링 방식에는 추가 학습이나 데이터가 필요하지 않으며 추가 모델 평가가 필요하지 않으므로 샘플링 시간이 늘어나지 않는다.
본 논문의 모델은 정규화 이미지에 의존하지 않고 훨씬 더 적은 수의 파라미터를 사용하며 학습 속도가 더 빠르면서도 현재의 SOTA와 동등하거나 더 나은 성능을 발휘한다.
Method
본 논문의 방법은 두 가지 구성 요소로 구성된다.
- Personalized residuals: 사전 학습된 T2I diffusion model의 일부 가중치에 적용되는 학습된 오프셋 집합을 통해 주어진 개념의 identity를 인코딩한다.
- Localized attention-guided (LAG) sampling: Attention map을 활용하여 residual이 적용되는 위치를 파악하고 기본 diffusion model과 personalized residual을 모두 활용하여 이미지를 효율적으로 생성할 수 있도록 한다.
1. Learning residuals for capturing identity

몇 개의 레퍼런스 이미지만 사용하여 개념을 학습하는 경우가 많기 때문에 생성 모델의 가중치를 직접 fine-tuning하면 학습된 언어 prior의 불필요한 부분을 쉽게 overfitting하거나 덮어쓸 수 있다. 대신 본 논문에서는 LoRA 기반 접근 방식을 사용할 것을 제안하였다. 따라서 inference 시 학습된 residual을 적용하지 않음으로써 원래 모델의 전체 생성 능력을 복구할 수 있다.
Diffusion model에는 self-attention layer와 cross-attention layer로 구성된 여러 transformer block이 포함되어 있으며, 각 block의 양쪽 끝에 $1 \times 1$ conv projection layer가 있다. 기존 방식들은 텍스트와 이미지 사이의 관계 학습으로 인해 주로 cross-attention layer를 선택하였지만, output projection conv layer의 로컬한 연산은 cross-attention의 글로벌한 연산보다 더 세밀한 디테일을 캡처할 수 있기 때문에 output projection conv layer에 대한 offset을 학습한다.
가중치가 $W_i \in \mathbb{R}^{m_i \times m_i \times 1}$인 $i$번째 transformer block의 output projection layer \(l_{\textrm{proj_out},i}\)에 대해
\[\begin{equation} \Delta W_i = A_i B_i \in \mathbb{R}^{m_i \times m_i} \\ \textrm{where} \quad A_i \in \mathbb{R}^{m_i \times r_i}, \quad B_i \in \mathbb{R}^{r_i \times m_i} \end{equation}\]를 학습시킨다. $\Delta W_i \in \mathbb{R}^{m_i \times m_i \times 1}$이 되도록 residual을 reshape하고 원래 가중치 $W_i$에 추가하여 $W_i^\prime = W_i + \Delta W_i$를 생성한다. $\Delta W_i$는 다음과 같은 원래 diffusion 목적 함수를 사용하여 업데이트된다.
\[\begin{equation} \mathcal{L}_\textrm{LDM} = \mathbb{E}_{z \sim \mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0,1), t} [\| \epsilon - \epsilon_\theta (z_t, t, \tau (y)) \|_2^2] \end{equation}\]다른 연구들과 비슷하게 개념을 고유한 식별자 토큰 $V^\ast$와 연관시키며, 이는 거의 발생하지 않는 토큰 임베딩을 사용하여 초기화된다. 각 레퍼런스 이미지에 대한 프롬프트는 다음과 같이 고유 토큰 $V^\ast$와 macro class를 사용한다.
“a photo of a $V^\ast$ [macro class]”
Diffusion model의 가중치를 직접 업데이트하는 개인화 방식은 새로운 개념으로 기존 prior의 일부를 덮어쓸 수 있으므로 학습 중에 정규화 이미지를 통해 prior 보존이 명시적으로 필요하다. 본 논문의 방법은 diffusion model을 직접 업데이트하지 않기 때문에 이 문제를 완전히 방지하고 효과적인 정규화 이미지들을 결정할 필요가 없다. 또한 LoRA의 사용은 학습 가능한 파라미터의 수를 줄여서 본 논문의 방법을 더 간단하고 효율적으로 만든다.
2. Localized attention-guided sampling
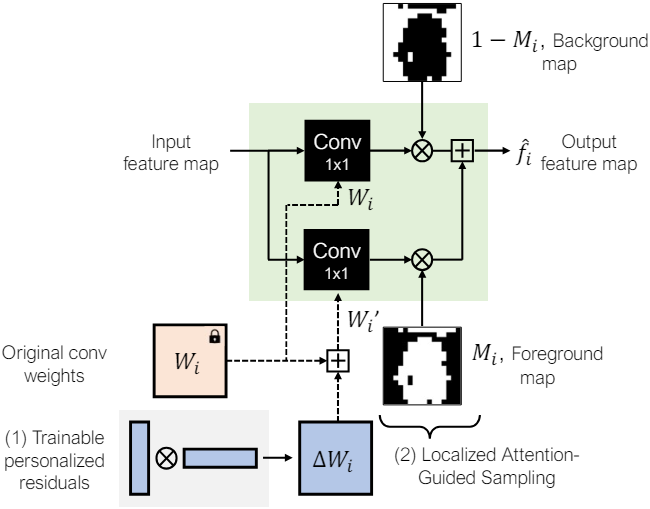
본 논문에서는 새로 학습된 개념과 diffusion model의 원래 prior를 더 잘 결합하기 위해 새로운 localized attention-guided (LAG) sampling 방법을 도입하였다. Diffusion model의 모든 trasnformer block에는 텍스트 토큰과 이미지 영역 간의 대응을 학습하는 것을 목표로 하는 cross-attention layer가 있다. 각 cross-attention layer는 프롬프트의 각 토큰 $y_i$에 대해 attention map $A_{y_i}$를 계산하여 토큰이 생성된 이미지에 영향을 미치는 위치를 나타낸다.
고유 식별자의 인덱스 $\mathcal{C}$와 macro class 토큰이 주어지면 transformer block $i$에서 해당 attention map의 값을 합산한다. 그리고 마스크를 얻기 위해 중앙값을 사용하여 binarize한다.
\[\begin{equation} A_{i, \mathcal{C}} = \sum_{j \in \mathcal{C}} A_j \\ M_i = \textrm{binarize} (A_{i, \mathcal{C}}) \end{equation}\]마지막으로 각 transformer block $i$의 output feature \(\hat{f}_i\)를 다음과 같이 계산한다.
\[\begin{equation} \hat{f}_i = (1 - M_i) \otimes f_i + M_i \otimes f_i^\prime \\ \textrm{where} \quad f_i = W_i x, \quad f_i^\prime = W_i^\prime x \end{equation}\]이를 통해 personalized residual로 표현되는 identity는 대상 개념에 해당하는 영역에만 적용되고, 나머지 영역은 원래의 diffusion model에 의해 생성된다.
LAG 샘플링은 object mask나 특정 학습이 필요없으며, 두 layer의 feature를 명시적으로 병합하므로 속도에 미치는 영향은 무시할 수 있다. 또한 학습된 residual이 배경에 영향을 미치지 않도록 위치를 파악할 수 있어 레퍼런스 이미지에 overfitting되고 대상 개념을 배경에서 효과적으로 분리하지 못하는 시나리오에서 유용할 수 있다.
Experiments
- Base model: Stable Diffusion v1.4
- 구현 디테일
- $r_i = 0.05 m_i$
- 각 low-rank 행렬은 랜덤 초기화됨
- iteration: 150
- batch size: 4
- learning rate: $1 \times 10^{-3}$
- 총 학습되는 파라미터 수: 120만 개 (전체 모델의 0.1%)
- 학습은 A100 GPU 1개에서 3분 소요
1. Results
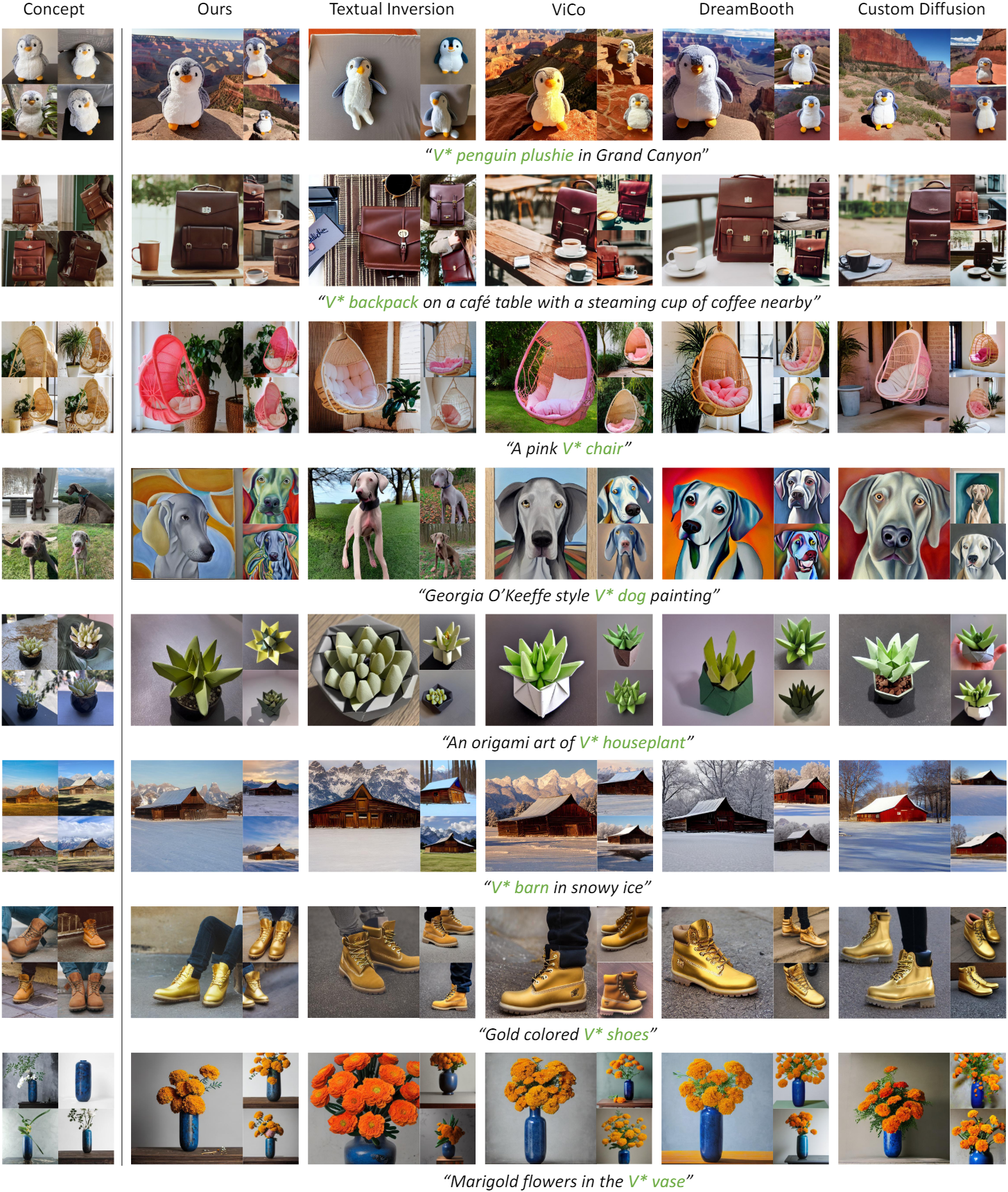
다음은 기존 방법들과 생성 결과를 비교한 것이다.
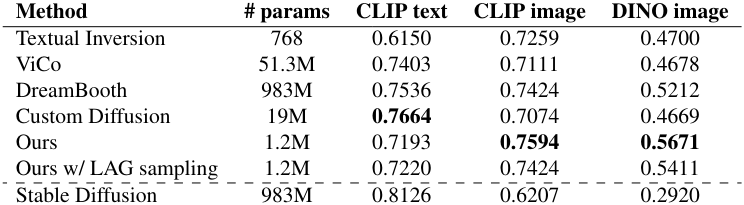
다음은 CLIP 및 DINO feature들의 유사도로 텍스트-이미지 정렬을 평가한 표이다.
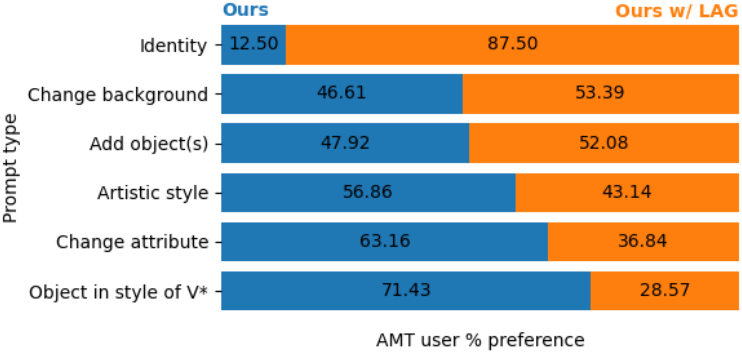
다음은 인간 선호도 평가 결과이다.

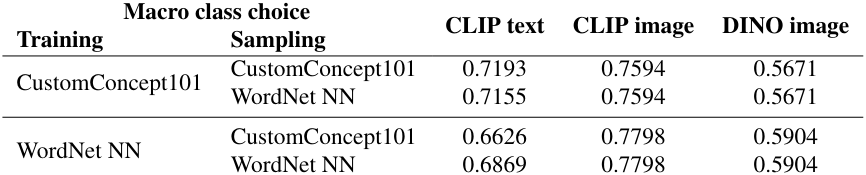
다음은 WordNet macro class를 사용하였을 때의 성능을 비교한 표이다.
2. Ablation studies
다음은 LAG 샘플링 유무에 따른 생성 결과를 비교한 것이다 (동일한 noise map에서 시작). 왼쪽은 LAG 샘플링을 사용했을 때 더 좋은 결과를 생성하는 예시이고, 오른쪽은 LAG 샘플링을 사용하지 않았을 때 더 좋은 결과를 생성하는 예시이다.

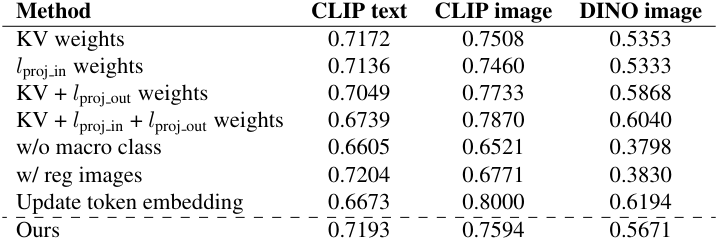
다음은 residual에 대한 두 가지 다른 목적 함수를 사용하고 다양한 학습 설정으로 본 논문의 방법을 평가한 표이다.
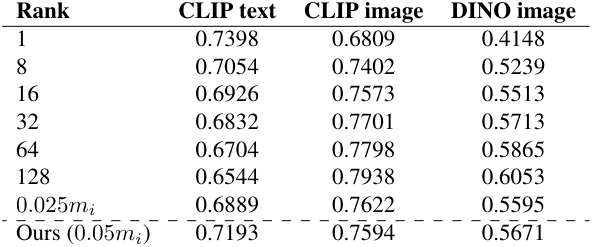
다음은 residual의 rank $r_i$에 대한 ablation 결과이다.
다음은 프롬프트 타입에 따른 LAG 샘플링의 효과를 비교한 것이다.