[논문리뷰] Personalize Segment Anything Model with One Shot (PerSAM)
arXiv 2023. [Paper] [Github]
Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Peng Gao, Hongsheng Li
Shanghai Artificial Intelligence Laboratory | CUHK MMLab | Tencent Youtu Lab | CFCS
4 May 2023
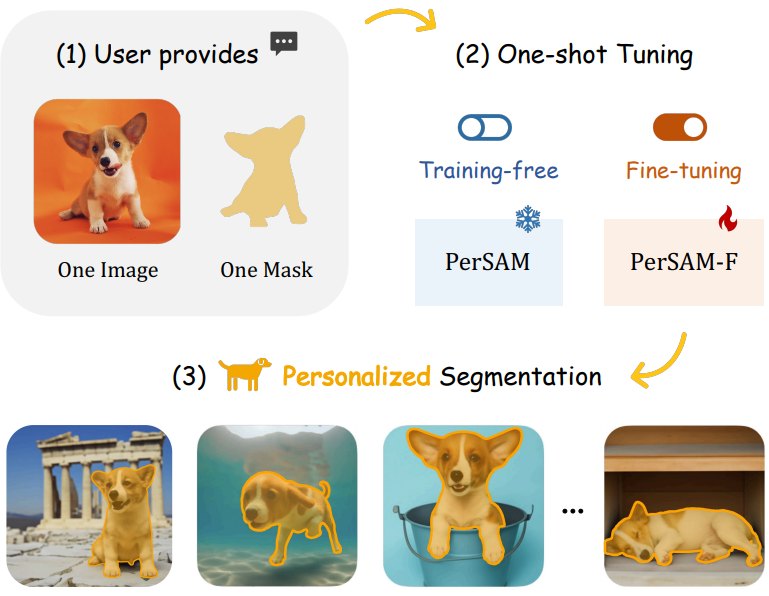
Introduction
비전, 언어, multi-modality의 foundation model은 사전 학습 데이터와 계산 리소스의 상당한 가용성으로 인해 전례 없이 널리 퍼졌다. 그들은 zero-shot 시나리오에서 놀라운 일반화 능력을 보여주고 인간의 피드백을 통합하는 상호 작용에서 다재다능함을 보여주었다. 대규모 언어 모델의 성과에 영감을 받은 Segment Anything (SAM)은 1,100만 개의 이미지 마스크 데이터를 수집하기 위한 정교한 데이터 엔진을 개발한 후 SAM으로 알려진 강력한 segmentation 기반 모델을 학습시켰다. 먼저 프롬프팅 가능한 새로운 segmentation 패러다임을 정의한다. 즉, 손으로 만든 프롬프트를 입력으로 사용하고 예상 마스크를 반환한다. SAM의 수용 가능한 프롬프트는 점, 박스, 마스크, 자유 형식 텍스트를 포함하여 시각적 맥락에서 모든 것을 분할할 수 있으며 충분히 일반적이다.
그러나 SAM은 본질적으로 특정 시각적 개념을 세분화하는 능력을 상실하였다. 사진 앨범에서 애완견을 자르거나 침실 사진에서 잃어버린 시계를 찾으려고 한다고 상상해 보자. 바닐라 SAM 모델을 활용하는 것은 노동 집약적이고 시간 소모적이다. 각 이미지에 대해 서로 다른 포즈 또는 컨텍스트에서 타겟 개체를 찾은 다음 분할을 위한 정확한 프롬프트로 SAM을 활성화해야 한다. 따라서 저자들은 질문하였다.
SAM을 개인화하여 고유한 시각적 개념을 간단하고 효율적인 방식으로 자동 분할할 수 있는가?
이를 위해 SAM에 대한 학습이 필요 없는 개인화 (personalization) 접근 방식인 PerSAM을 제안한다. 본 논문의 방법은 사용자가 제공한 이미지와 개인 개념을 지정하는 대략적인 마스크인 one-shot 데이터만을 사용하여 SAM을 효율적으로 커스터마이징한다. 특히, 먼저 SAM의 이미지 인코더와 주어진 마스크를 활용하여 레퍼런스 이미지에 타겟 개체의 임베딩을 인코딩한다. 그런 다음 새 테스트 이미지에서 객체와 모든 픽셀 간의 특징 유사성을 계산한다. 또한 프롬프트 토큰으로 인코딩되고 SAM의 위치 prior 역할을 하는 긍정-부정 쌍으로 두 지점이 선택된다. 테스트 이미지를 처리하는 SAM의 디코더 내에서 파라미터 튜닝 없이 개인화 잠재력을 발휘할 수 있는 세 가지 기술을 도입한다.
- Target-guided Attention: 계산된 feature 유사도로 SAM 디코더의 모든 토큰-이미지 cross-attention 레이어를 가이드한다. 이는 효과적인 feature 상호 작용을 위해 프롬프트 토큰이 주로 전경 타겟 영역에 집중하도록 한다.
- Target-semantic Prompting: SAM에 높은 수준의 타겟 semantic을 더 잘 제공하기 위해 원래의 낮은 레벨의 프롬프트 토큰을 포함된 타겟 개체와 융합하여 개인화된 분할을 위한 더 충분한 시각적 신호를 디코더에 제공한다.
- Cascaded Post-refinement: 보다 세밀한 분할 결과를 위해 2단계의 정제 전략을 채택한다. SAM을 활용하여 생성된 마스크를 점진적으로 개선한다. 이 프로세스는 추가로 100ms만 소요된다.

앞서 언급한 설계를 통해 PerSAM은 위 그림에 시각화된 것처럼 다양한 포즈와 컨텍스트에서 고유한 주제에 대해 놀라운 개인화된 분할 성능을 발휘한다. 그럼에도 불구하고 주제가 세분화할 계층적 구조로 구성되는 경우 가끔 실패하는 경우가 있을 수 있다. 로컬한 부분과 글로벌한 모양이 모두 픽셀 레벨에서 SAM에 의해 유효한 마스크로 간주될 수 있기 때문에 이러한 모호성은 분할 출력으로 마스크의 적절한 배율을 결정하는 데 있어 PerSAM에 대한 문제를 제기한다.
이를 완화하기 위해 PerSAM-F 접근 방식의 fin-tuning 변형을 추가로 도입한다. 사전 학습된 지식을 보존하기 위해 전체 SAM을 동결하고 10초 이내에 2개의 파라미터만 fine-tuning한다. 자세히 설명하면 SAM이 서로 다른 마스크 스케일로 여러 분할 결과를 생성할 수 있다. 다양한 객체에 대한 최상의 스케일을 적응적으로 선택하기 위해 각 스케일에 대해 학습 가능한 상대 가중치를 사용하고 최종 마스크 출력으로 가중치 합산을 수행한다. 이러한 효율적인 원샷 교육을 통해 PerSAM-T는 더 나은 분할 정확도를 나타낸다. 즉각적인 튜닝이나 어댑터를 사용하는 대신 멀티스케일 마스크를 효율적으로 가중하여 모호성 문제를 효과적으로 억제할 수 있다.
또한 본 논문의 접근 방식은 개인화된 text-to-image 생성을 위해 Stable Diffusion을 더 잘 fine-tuning하도록 DreamBooth를 지원할 수 있다. 특정 시각적 개념을 포함하는 몇 가지 이미지가 주어지면 DreamBooth와 다른 연구들은 이러한 이미지를 단어 임베딩 space의 identifier [V]로 변환한 다음 문장에서 타겟 개체를 나타내는 데 활용된다. 그러나 identifier는 주어진 이미지의 배경의 시각적 정보를 동시에 포함한다. 이것은 생성된 이미지의 새로운 배경을 재정의할 뿐만 아니라 타겟 개체의 표현 학습을 방해한다. 따라서 PerSAM을 활용하여 타겟 객체를 효율적으로 분할하고, few-shot 이미지에서 전경 영역으로만 Stable Diffusion을 supervise하여 보다 다양하고 높은 충실도의 합성을 가능하게 한다.
Method
1. Preliminary
Segment Anything
SAM은 프롬프팅 가능한 새로운 segmentation task를 정의하며, 그 목표는 지정된 프롬프트에 대한 segmentation mask를 반환하는 것이다. SAM은 1,100만 개의 이미지에서 10억 개의 마스크로 완전히 사전 학습되어 강력한 일반화 능력을 지원한다. SAM은 프롬프트 인코더, 이미지 인코더, 경량 마스크 디코더의 세 가지 주요 구성 요소로 구성되며 각각 \(\textrm{Enc}_P\), \(\textrm{Enc}_I\), \(\textrm{Dec}_M\)으로 표시된다. 프롬프팅 가능한 프레임워크로서 SAM은 입력으로 이미지 $I$와 일련의 프롬프트 $P$ (ex. 전경 또는 배경 포인트, bounding box, 세분화할 대략적인 마스크)를 사용한다. SAM은 먼저 \(\textrm{Enc}_I\)를 사용하여 입력 이미지 feature를 얻고 \(\textrm{Enc}_P\)를 사용하여 사람이 제공한 프롬프트를 다음과 같이 $c$차원 토큰으로 인코딩한다.
\[\begin{equation} F_I = \textrm{Enc}_I (I) \in \mathbb{R}^{h \times w \times c} \\ T_P = \textrm{Enc}_P (P) \in \mathbb{R}^{k \times c} \end{equation}\]여기서 $h$와 $w$는 이미지 feature의 해상도이며 $k$는 프롬프트의 길이이다. 그런 다음 인코딩된 이미지와 프롬프트는 attention 기반 feature 상호 작용을 위해 디코더 \(\textrm{Dec}_M\)에 공급된다. SAM은 여러 학습 가능한 토큰 $T_M$을 프롬프트 토큰의 접두사로 concat하여 디코더의 입력 토큰을 구성한다. 이러한 마스크 토큰은 최종 마스크 출력 생성을 담당한다. 디코딩 프로세스는 다음과 같다.
\[\begin{equation} M = \textrm{Dec}_M (F_I, \textrm{Concat} (T_M, T_P)) \end{equation}\]여기서 $M$은 SAM에 의한 zero-shot 마스크 예측을 나타낸다.
개인화된 segmentation Task
그럼에도 불구하고 SAM은 사용자가 요청한 모든 것을 분할하도록 일반화되어 있지만 특정 주제 인스턴스를 분할하는 능력이 부족하다. 이를 위해 개인화된 segmentation을 위한 새로운 task를 정의한다. 사용자는 타겟 시각적 개념을 나타내는 마스크와 함께 단일 레퍼런스 이미지만 제공한다. 주어진 마스크는 정확한 분할이거나 온라인에서 사용자가 그린 대략적인 스케치일 수 있다. 본 논문의 목표는 SAM을 커스터마이징하여 사람의 지시 없이 새 이미지 또는 동영상 내에서 지정된 주제를 세분화하는 것이다. 저자들은 모델 평가를 위해 PerSeg라는 개인화된 segmentation를 위한 새로운 데이터셋에 주석을 달았다. 이미지는 다양한 포즈 또는 장면에서 다양한 카테고리의 시각적 개념을 포함하는 주제 중심 diffusion model 연구에서 가져온 것이다. 본 논문에서는 이 task를 위한 두 가지 효율적인 솔루션인 PerSAM과 PerSAM-F를 제안한다.
2. Training-free PerSAM
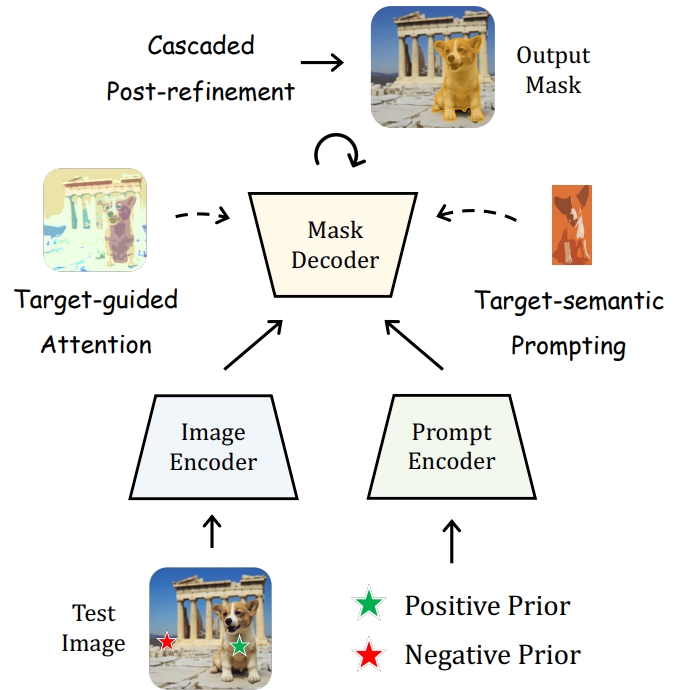
위 그림은 학습이 필요 없는 PerSAM의 전체 파이프라인을 나타낸다.
긍정-부정 위치 Prior
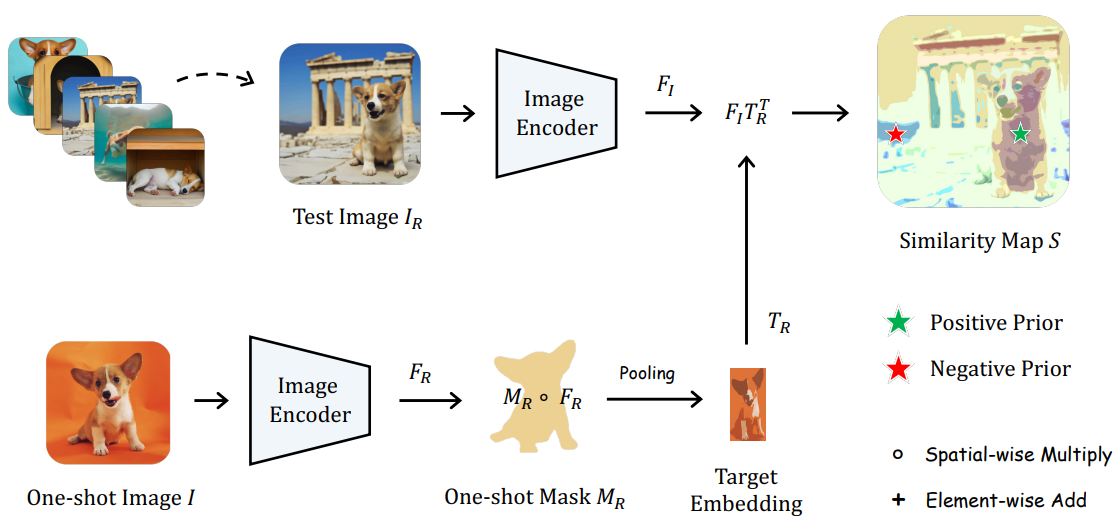
먼저, 사용자 제공 이미지 $I_R$과 마스크 $M_R$에 따라 PerSAM은 SAM을 사용하여 새 테스트 이미지 $I$에서 타겟 개체의 위치 prior를 얻는다. 세부적으로 위 그림과 같이 SAM의 사전 학습된 이미지 인코더를 적용하여 $I$와 $I_R$의 시각적 feature를 다음과 같이 추출한다.
그런 다음 레퍼런스 마스크 $M_R \in \mathbb{R}^{h \times w \times 1}$을 활용하여 $F_R$에서 타겟 시각적 개념 내 픽셀의 feature를 도출하고 average pooling을 채택하여 글로벌한 시각적 임베딩 $T_R \in \mathbb{R}^{1 \times c}$을 다음과 같이 집계한다.
\[\begin{equation} T_R = \textrm{Pooling} (M_R \circ F_R) \end{equation}\]여기서 $\circ$는 공간별 곱셈을 나타낸다. 타겟 임베딩 $T_R$을 사용하여 $T_R$과 테스트 이미지 feature $F_I$ 사이의 코사인 유사도 $S$를 다음과 같이 계산하여 위치 신뢰도 맵을 얻을 수 있다.
\[\begin{equation} S = F_I T_R^\top \in \mathbb{R}^{h \times w} \end{equation}\]여기서 $F_I$와 $T_R$은 픽셀별로 L2 정규화된다. 그런 다음 SAM에 테스트 이미지의 위치 prior를 제공하기 위해 $S$에서 가장 높은 유사도 값과 가장 낮은 유사도 값을 가진 두 개의 픽셀 좌표 $P_h$와 $P_l$를 선택한다. $P_h$는 타겟 개체의 가장 가능성이 높은 전경 위치를 나타내고 $P_l$은 역으로 배경을 나타낸다. 그런 다음 그들은 긍정-부정 포인트 쌍으로 간주되고 다음과 같이 프롬프트 인코더에 공급된다.
\[\begin{equation} T_P = \textrm{Enc}_P (P_h, P_l) \in \mathbb{R}^{2 \times c} \end{equation}\]여기서 $T_P$는 SAM의 디코더에 대한 프롬프트 토큰 역할을 한다. 이러한 방식으로 SAM은 테스트 이미지에서 부정 포인트를 버리면서 긍정 포인트를 둘러싼 연속 영역을 분할하는 경향이 있다.
Target-guided Attention
긍정-부정 prior가 사용되었지만 전경 타겟 영역 내에서 feature 집계에 집중하는 SAM 디코더의 cross-attention 메커니즘에 대한 보다 명확한 guidance를 추가로 제안한다.
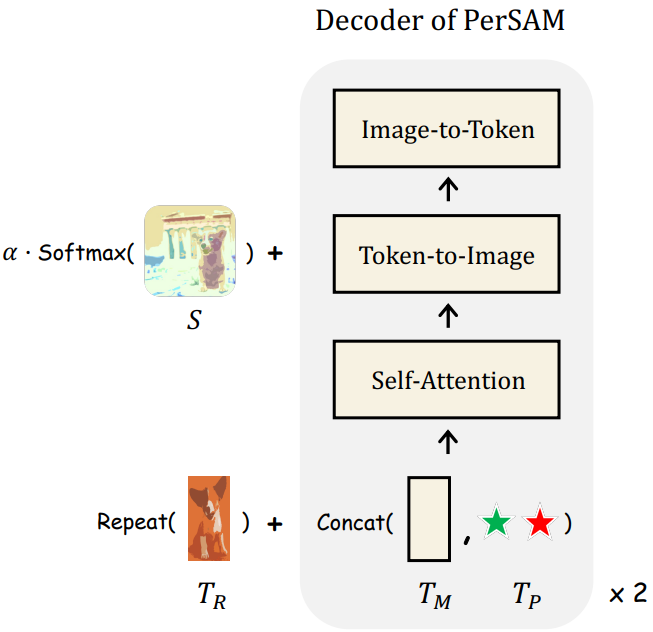
위 그림에서와 같이 유사도 맵 $S$는 테스트 이미지에서 타겟 시각적 개념 내의 픽셀을 명확하게 나타낼 수 있다. 이를 감안할 때 $S$를 활용하여 모든 토큰-이미지 cross-attention 레이어에서 attention map을 변조한다. Softmax 함수 이후의 attention map을 $A \in \mathbb{R}^{h \times w}$로 표시하고 분포를 다음과 같이 가이드한다.
여기서 $\alpha$는 balance factor이다. Attention bias에 의해 토큰은 중요하지 않은 배경이 아닌 타겟 주제와 관련된 더 많은 시각적 semantic을 캡처해야 한다. 이는 attention 레이어에서 보다 효과적인 feature 상호 작용에 기여하고 학습이 필요 없는 방식으로 PerSAM의 최종 segmentation 정확도를 향상시킨다.
Target-semantic Prompting
일반 SAM은 점이나 박스의 좌표와 같은 낮은 수준의 위치 정보를 전달하는 프롬프트만 수신한다. 보다 개인화된 단서를 통합하기 위해 PerSAM에 대한 높은 수준의 semantic 프롬프트로 타겟 개념의 시각적 임베딩 $T_R$을 추가로 활용한다. 특히 모든 디코더 블록에 공급하기 전에 모든 입력 토큰과 함께 타겟 임베딩을 element-wise하게 추가한다.
\[\begin{equation} \textrm{Repeat} (T_R)+ \textrm{Concat} (T_M, T_P) \end{equation}\]여기서 $\textrm{Repeat}$ 연산은 토큰 차원에서만 수행된다. 간단한 토큰 통합의 도움을 받아 PerSAM은 낮은 수준의 위치 prior뿐만 아니라 보조 시각적 신호가 있는 높은 수준의 타겟 semantic에 의해 프롬프트된다.
Cascaded Post-refinement
위의 기술을 통해 SAM의 디코더에서 테스트 이미지에 대한 초기 segmentation mask를 얻었지만 거친 가장자리와 배경과 분리된 noise가 포함될 수 있다. 추가 개선을 위해 2단계 후처리를 통해 반복적으로 마스크를 SAM의 디코더에 다시 공급한다. 첫 번째 단계에서는 긍정-부정 위치 prior와 함께 초기 마스크로 SAM의 디코더를 프롬프팅한다. 그런 다음 두 번째 단계에서는 첫 번째 단계에서 마스크의 bounding box를 계산하고 더 정확한 객체 위치 파악을 위해 이 박스로 디코더를 추가로 프롬프팅한다. 대규모 이미지 인코더 없이 반복적 정제를 위해 경량 디코더만 필요하므로 후처리가 효율적이며 추가 비용은 100ms뿐이다.
3. Fine-tuning of PerSAM-F
마스크 스케일의 모호성
학습이 필요 없는 PerSAM은 만족스러운 segmentation 정확도로 대부분의 사례를 처리할 수 있다. 그러나 일부 타겟 개체에는 계층 구조가 포함되어 있어 크기가 다른 여러 마스크를 분할해야 한다.

위 그림에서 볼 수 있듯이 플랫폼 상단의 주전자는 뚜껑과 본체의 두 부분으로 구성된다. 긍정 prior (녹색 별표)가 본체에 있는 반면 부정 prior (빨간색 별표)가 유사한 색상의 플랫폼을 제외하지 않는 경우 PerSAM은 분할에 대해 모호하다. 이러한 문제는 SAM에서도 논의되었으며 객체의 전체, 부분, 하위 부분에 각각 해당하는 세 가지 스케일의 다중 마스크를 동시에 생성하는 대안을 제안하였다. 그러면 사용자가 수동으로 3개의 마스크 중 하나를 선택해야 하므로 효율적이지만 추가 인력이 필요하다. 대조적으로, 본 논문의 개인화된 task는 사람의 프롬프트 없이도 자동 개체 분할을 위해 SAM을 커스터마이징하는 것을 목표로 한다. 이는 몇 가지 파라미터만 효율적으로 fine-tuning하여 SAM에 대한 scale-aware 개인화 접근 방식을 개발하도록 한다.
학습 가능한 스케일 가중치
적절한 마스크 스케일을 사용한 적응형 분할을 위해 fine-tuning 변형인 PerSAM-F를 도입한다. 하나의 마스크만 생성하는 무학습 모델과 달리 PerSAM-F는 먼저 SAM의 솔루션을 참조하여 3단계 마스크 $M_1$, $M_2$, $M_3$를 출력한다. 여기에 학습 가능한 두 개의 마스크 가중치 $w_1$, $w_2$를 채택하고 가중 합계로 최종 마스크 출력을 다음과 같이 계산한다.
\[\begin{equation} M = w_1 \cdot M_1 + w_2 \cdot M_2 + (1 - w_1 - w_2) \cdot M_3 \end{equation}\]여기서 $w_1$, $w_2$는 모두 $1/3$로 초기화된다. 최적의 가중치를 학습하기 위해 레퍼런스 이미지에 대해 one-shot fine-tuning을 수행하고 주어진 마스크를 ground truth로 간주한다. 사전 학습된 지식을 보존하기 위해 전체 SAM 모델을 동결하고 10초 이내에 $w_1$, $w_2$의 파라미터 2개만 fine-tuning한다. One-shot 데이터에 대한 overfitting을 피하기 위해 학습 가능한 프롬프트 또는 어댑터 모듈을 채택하지 않는다. 이러한 방식으로 PerSAM-F는 다양한 시각적 개념에 대한 최상의 마스크 스케일을 효율적으로 학습하고 학습이 필요 없는 PerSAM보다 더 강력한 segmentation 성능을 나타낸다.
4. Better Personalization of Stable Diffusion
DreamBooth
개인화된 segmentation과 마찬가지로 Textual Inversion, DreamBooth 등은 사전 학습된 text-to-image 모델 (ex. Stable Diffusion, Imagen)을 fine-tuning하여 사용자가 표시한 특정 시각적 개념의 이미지를 합성한다. 예를 들어 고양이의 ground-truth 사진 3~5장이 주어지면 DreamBooth는 few-shot 학습을 수행하고 “a [V] cat”이라는 텍스트 프롬프트를 입력하여 해당 고양이를 생성하는 방법을 학습한다. 거기에서 [V]는 단어 임베딩 space에서 특정 고양이를 나타내는 고유 identifier 역할을 한다. 학습 후 개인화된 DreamBooth는 “a [V] cat on a beach”와 같이 다양한 맥락에서 고양이의 참신한 표현을 합성할 수 있다. 그러나 DreamBooth는 재구성된 전체 이미지와 ground-truth 사진 사이의 L2 loss를 계산한다. 이는 few-shot 이미지의 중복된 배경 정보를 identifier를 주입하여 새로 생성된 배경을 무시하고 타겟 개체의 표현 학습을 방해한다.
PerSAM-assisted DreamBooth
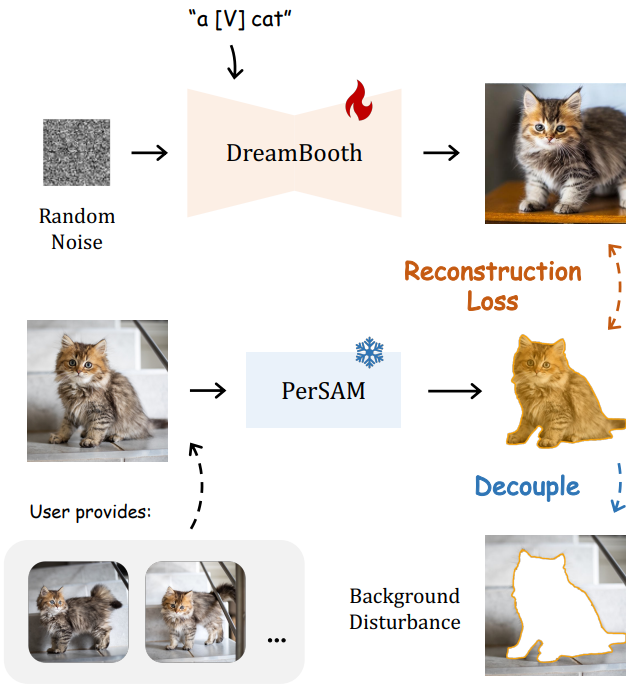
위 그림에서는 DreamBooth에서의 배경 교란을 완화하기 위한 전략을 소개한다. 사용자가 few-shot 이미지에 대해 개체 마스크를 추가로 제공하는 경우 PerSAM 또는 PerSAM-F를 활용하여 모든 전경 대상을 분할하고 배경 영역 내의 픽셀에 대한 기울기 역전파를 버릴 수 있다. 그런 다음 Stable Diffusion은 타겟 물체의 시각적 외관을 기억하도록 fine-tuning될 뿐이며 다양성을 유지하기 위해 배경에 대한 supervision은 없다. 그 후, PerSAM-assisted DreamBooth는 더 나은 시각적 대응으로 주제 인스턴스를 합성할 뿐만 아니라 텍스트 프롬프트에 의해 가이드되는 새로운 컨텍스트에 대한 가변성을 증가시킨다.
Experiment
1. Personalized Evaluation
- 테스트 데이터셋: PerSeg (저자들이 새로 구축)
- DreamBooth, Textual Inversion, Custom Diffusion의 학습 데이터에서 수집
- 다양한 카테고리의 개체 총 40개로 구성
- 각 개체는 포즈와 장면이 다른 5~7개의 이미지와 주석이 달린 마스크로 구성
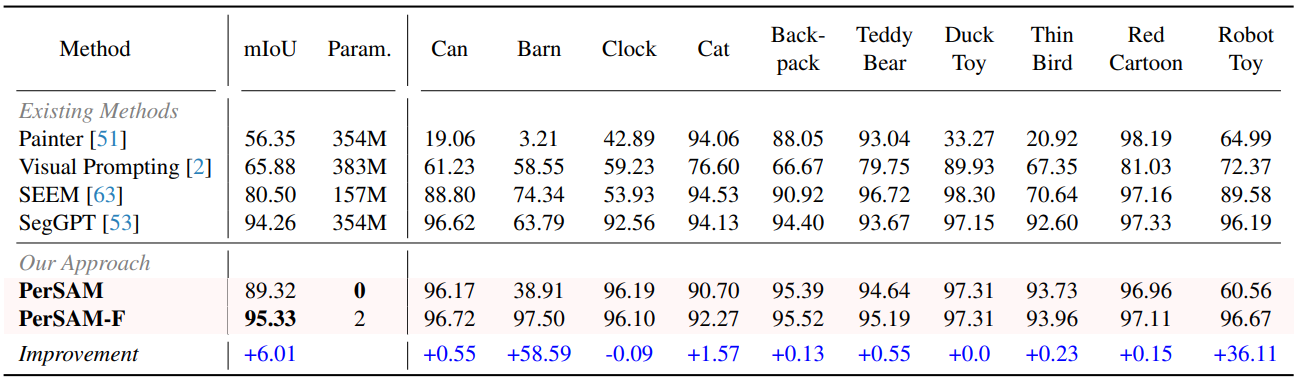
다음은 PerSeg 데이터셋에서의 개인화된 segmentation 결과를 비교한 표이다.
다음은 PerSeg 데이터셋에서 PerSAM-F의 결과를 시각화한 것이다.

2. Video Object Segmentation
- 테스트 데이터셋: DAVIS 2017
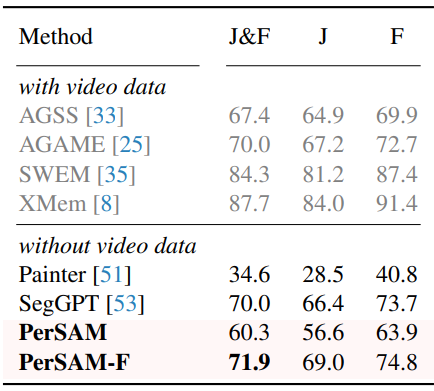
다음은 DAVIS 2017에서의 동영상 개체 분할 (%) 결과이다.
다음은 DAVIS 2017에서 PerSAM-F의 결과를 시각화한 것이다.

3. PerSAM-assisted DreamBooth
다음은 PerSAM-guided DreamBooth의 결과를 시각화한 것이다.


4. Ablation Study
다음은 PerSAM과 PerSAM-F의 ablation study 결과이다.
