[논문리뷰] Peekaboo: Text to Image Diffusion Models are Zero-Shot Segmentors
arXiv 2022. [Paper] [Page] [Github]
Ryan Burgert, Kanchana Ranasinghe, Xiang Li, Michael S. Ryoo
Stony Brook University
23 Nov 2022

Introduction
Image segmentation은 이미지를 의미 있는 공간 영역(또는 세그먼트)으로 분할한다. Semantic segmentation는 이러한 세그먼트의 의미를 미리 정의된 레이블 집합에 연결하는 반면, referring segmentation는 의미를 모든 자연어 프롬프트에 연결할 수 있는 개방형 레이블을 사용하여 더 자유로울 수 있다. 후자는 또한 multi-modal 출력 space를 생성한다. 주어진 단일 이미지에 대해 서로 다른 언어 프롬프트에 해당하는 여러 개의 개별 분할이 존재할 수 있으므로 task가 더 어려워진다.
Supervision을 위해 값비싼 수동 주석에 의존하는 다양한 segmentation별 신경망 아키텍처를 활용하는 semantic segmentation의 진행은 최근 약한 supervision 하의 학습, 특히 contrastive image language pre-training model의 활용으로 대체되었다. Referring segmentation의 경우 자연어 구성 요소는 언어별 아키텍처 구성 요소를 활용하도록 초기 연구를 주도했으며 최근 연구도 유사하게 구축되었다. 최근의 일부 semantic segmentation 접근 방식은 분할을 위해 완전히 supervise되지 않은 학습을 위해 픽셀 단위의 인간 주석에 대한 의존성을 제거할 수 있었지만 이러한 접근 방식은 특히 referring segmentation에서 더 복잡한 언어 프롬프트에 대하여 실패하는 경우가 많다.
Contrastive image language pre-training 기반 모델은 이러한 segmentation task를 위한 강력한 기반 모델로 작용했다. 하지만 diffusion model은 사실적인 텍스트 기반 이미지 생성에서 인상적인 성능을 보여주지만 segmentation task에는 활용되지 않았다. 또한 diffusion 기반 모델을 구축하는 대부분의 접근 방식은 생성 task로 제한되었다. 저자들은 사전 학습된 diffusion model의 시각적 개념에 대한 이해를 활용하여 자연어를 이미지의 관련 공간적 영역에 연관시킬 수 있는지 확인하고자 하였다. 본 논문에서는 Stable Diffusion 모델이 언어를 이미지에 localize하는 데 필요한 정보를 포함하는 방법과 segmentation task를 위한 기본 모델로 작동할 수 있는 방법을 탐색한다. 특히 unsupervised 방식의 semantic 및 referring segmentation을 시도한다.
본 논문이 제안한 Peekaboo는 semantic 및 referring segmentation가 모두 가능한 최초의 unsupervised 방식이다. Segmentation 관련 아키텍처나 목적 함수가 없는 zero-shot, 개방형 vocabulary 설정에서 segmentation을 수행한다. 또한, 본 논문의 접근 방식은 사전 학습된 Stable Diffusion 모델을 사용하여 재학습 없이 segmentation을 수행한다. 즉, Peekaboo는 모든 특성과 강점을 유지하면서 원래 모델과 정확히 동일한 가중치를 사용한다. 본 논문은 Stable Diffusion 모델에 포함된 localizaiton 관련 정보를 추출할 수 있는 inference time 최적화 테크닉을 제안한다.
제안된 inference time 최적화는 주어진 이미지와 짝을 이룬 언어 캡션에 대한 최적의 segmentation으로 수렴하는 alpha mask를 반복적으로 업데이트하는 것을 포함한다. 저자들은 alpha mask의 향상된 학습을 위한 암시적 신경망 표현을 탐색하고 최적화가 적절한 segmentation을 생성하는 새로운 알파 합성 기반 loss를 제안한다.
Proposed Method
본 논문은 zero-shot 방식으로 이미지를 분할하기 위해 인터넷 스케일의 대규모 데이터 셋에서 사전 학습된 text-to-image Stable Diffusion model을 활용한다. 주어진 이미지에서 관심 영역에 대한 분할을 반복적으로 생성하기 위해 알파 채널 합성 프로세스가 사용된다. Zero-shot 기능은 언어와 시각 modality를 연결하는 latent space에서 작동하는 score 추출 메커니즘에 의해 부여된다. Latent space score distillation을 허용하는 암시적 신경망 함수로 반복 분할 프로세스에 사용되는 알파 채널을 나타낸다.
1. Peekaboo: Architecture
이미지 $x_i$가 주어지면 Peekaboo는 텍스트 캡션 $c_i$로 표시된 관심 영역을 분할한다. Cross-modal 유사성을 측정하기 위해 사전 학습된 diffusion model인 $Q_\theta$를 활용한다. 이는 예상 분할 마스크 $y_i$를 반복적으로 생성하는 데 사용된다. 인코더 $\mathcal{E}$는 latent $z_i \in \mathbb{R}^{H/f \times W/f \times 4}$를 생성하기 위해 일부 입력 $\hat{x}_i \in \mathbb{R}^{H \times W \times 3}$을 $f = 8$의 계수로 다운 샘플링하며, 디코더 $\mathcal{D}$는 $z_i$를 되돌려 $\hat{x}_i$를 생성한다. 텍스트 캡션은 CLIP ViTL/14 사전 학습된 텍스트 인코더 $\mathcal{T}$를 사용하여 인코딩되며 최종 average pooling 연산 이전의 출력이 feature vector로 사용된다. Diffusion denoising process는 Stable Diffusion에서 사용되는 U-Net의 변형에 의해 수행된다. 이것은 position-wise MLP와 cross-attention 연산 (인코딩된 텍스트 캡션으로 컨디셔닝)을 통합한 표준 diffusion model U-Net의 수정본이다. 학습 가능한 신경망 함수 \(\psi_{\phi_i}\)로 표현되는 시스템의 최종 segmentation 예측은 채널이 1개인 alpha mask이다.
Peekaboo의 개요는 아래 그림과 같다.
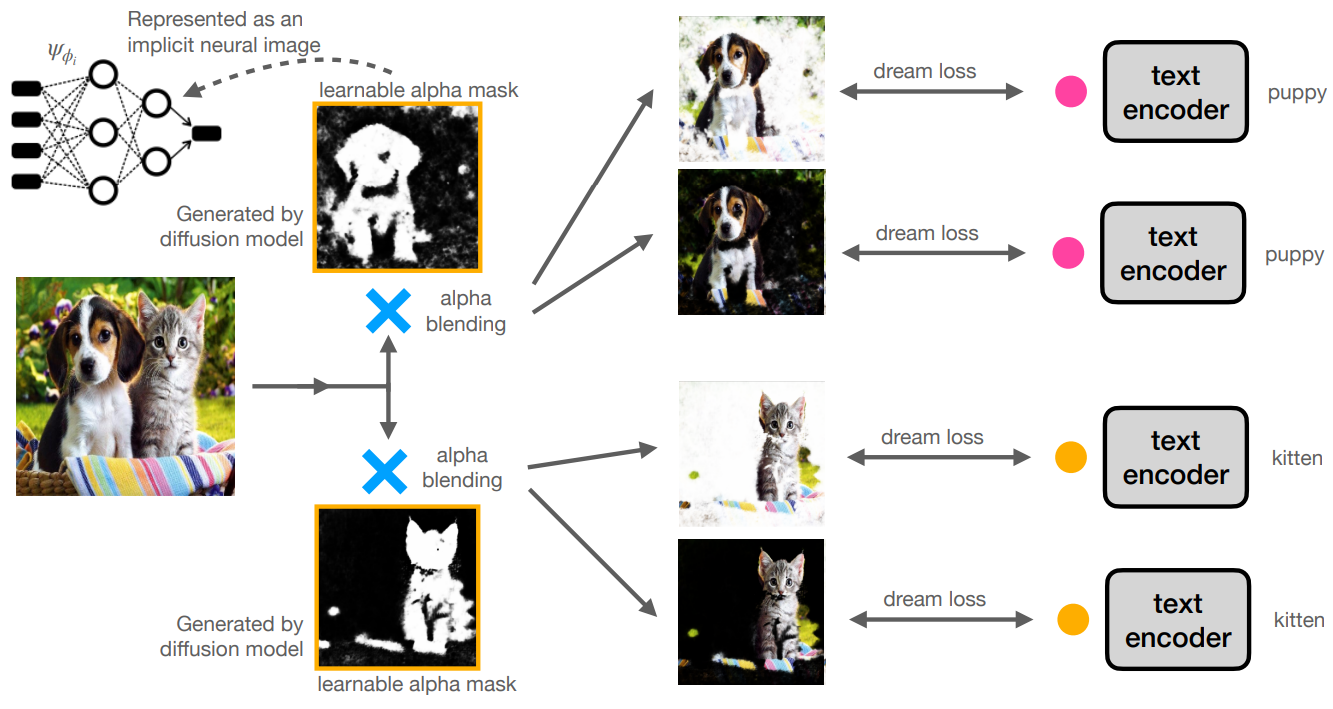
2. Learnable Alpha Compositing
Alpha compositing 또는 alpha blending은 주어진 이미지를 주어진 배경과 결합하여 부분적 또는 완전한 투명도를 생성한다. 본 논문에서는 주어진 이미지에서 관심 영역에 초점을 맞추는 학습 가능한 alpha mask의 개념을 도입한다. Alpha mask(또는 데이터와 같은 이미지)는 일반적으로 배열 데이터 구조로 표현되지만 여기서는 암시적 신경망 표현을 사용한다.
학습 가능한 alpha mask는 입력 이미지 $x_i$를 배경 $b_j$와 합성하는 데 사용된다. 이 경우 랜덤 색상의 균일한 배경(동일한 색상의 모든 픽셀)을 사용한다. 그 결과 합성 이미지 \(\hat{x}_{i,j}\)는 $b_j$의 마스크 색상을 사용하여 원본 이미지(제한된 공간 영역만 표시됨)의 마스크 버전이 된다. 단일 alpha mask를 사용하여 여러 랜덤한 색상 배경을 가진 $n_b$개의 출력의 집합을 생성한다. 모든 합성 이미지에서 보이는 영역은 학습 가능한 alpha mask에 의해 결정된다.
본 논문에서 제안된 Dream Loss $\mathcal{L}_d (\hat{x}, c)$는 합성 이미지와 텍스트 캡션 간의 cross-modal 유사성을 측정하는 것으로 볼 수 있다. Dream Loss와 관련하여 alpha mask $\hat{y}$를 반복적으로 최적화하여 각 보이는 영역이 공통 텍스트 프롬프트와 관련되도록 한다. 이 최적화는 입력 텍스트 캡션과 관련된 영역으로 localize되는 alpha mask로 수렴된다.
단일 이미지는 서로 다른 텍스트 캡션 $c_i^k$와 관련된 여러 영역을 포함할 수 있으므로 각 텍스트 캡션에 대해 별도의 alpha mask \(\hat{y}_{i,k}\)를 학습한다. 이들 각각을 병렬로 최적화하면 각 영역을 개별적으로 분할할 수 있다.
\[\begin{equation} \hat{x}_{i, j, k} = \hat{y}_{i,k} x_i + (1 - \hat{y}_{i,k}) \cdot b_j \\ \mathcal{L}_{cd} (x_i, c_i) = \sum_k \sum_{j=1}^{n_b} \mathcal{L}_d (\hat{x}_{i,j,k}, c_i^k) \end{equation}\]여기에서 여러 캡션 $c_i^k$를 포함하는 단일 이미지 $x_i$에 대해 compound Dream Loss \(\mathcal{L}_{cd}\)를 얻는다.
3. Implicit Mask Representation
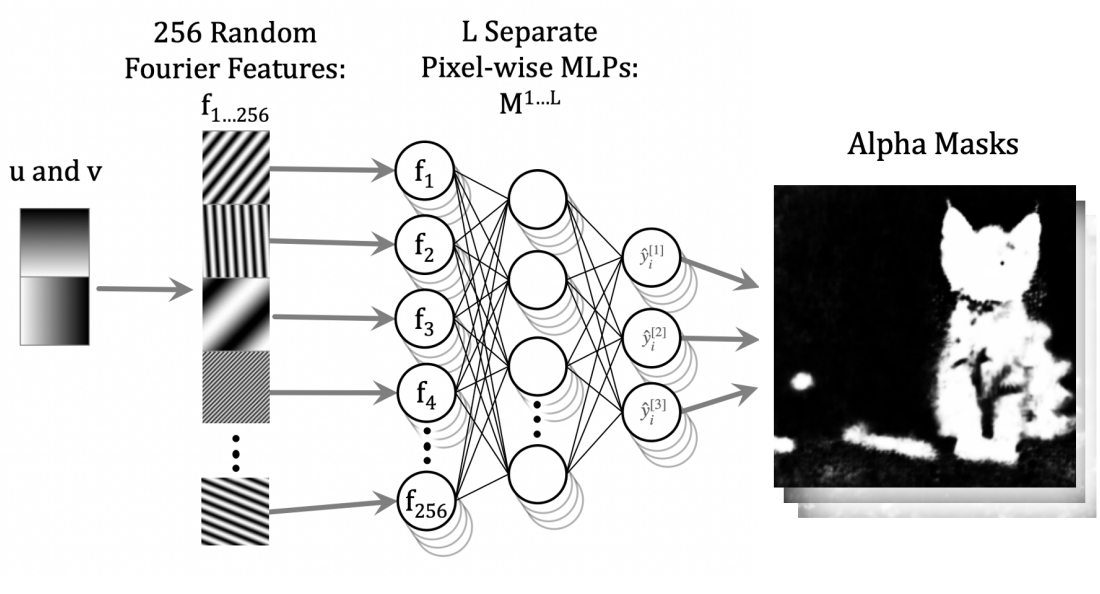
학습 가능한 alpha mask $\hat{y}_i$는 신경망에 의해 모델링된 함수로 표현된다. 특히 Neural Neural Textures Make Sim2Real Consistent 논문에서 영감을 얻은 parametric Fourier domain representation이 사용된다. 마스크 파라미터를 생성하기 위해 4개의 fully connected layer가 있는 MLP 네트워크 \(\psi_{\phi_i}\)를 사용한다. MLP 네트워크에 대한 입력은 Fourier domain parameter $u, v$의 집합이고 출력은 각 이미지 캡션과 관련된 $k$개의 alpha mask 집합, 즉 $\hat{y}_i \in \mathbb{R}^{k \times H \times W}$이다.
이 암시적 마스크 표현이 주어지면 inference 중에 분할될 각 이미지 $x_i$에 대해 마스크 $\hat{y}_i$를 정의하는 파라미터인 $\phi_i$를 반복적으로 업데이트한다. 이 parameterization 측면에서, 푸리에 도메인에서 작동하는 것은 마스크에 대한 의미 있는 제약 조건을 쉽게 지원한다. 또한 암시적 마스크 표현은 다음이 가능하다.
- 학습 데이터(RGB)와 다른 modality (alpha mask) 예측
- 최적화에 다양한 loss function 형태의 제약 조건 적용
- 공통 네트워크에서 여러 마스크 (이미지 내의 다른 관심 영역) 생성
4. Dream Loss
이제 텍스트와 이미지 양식을 연결하여 예상 segmentation mask를 생성하는 제안된 Dream Loss에 대해 설명한다. LAION-5B(및 부분 집합)에서 사전 학습된 latent diffusion model (LDM)에는 광범위한 cross-modal 정보가 포함되어 있다. 이 LDM을 활용하여 시각적 영역과 언어 영역 간의 cross-modal 유사성을 측정한다. “Loss”이라는 용어에도 불구하고 Dream Loss는 어떤 학습에도 사용되지 않는다.
이미지-텍스트 쌍 $(\hat{x}, c)$가 주어지면 diffusion model $Q_\theta$는 각 timestep에서 생성될 최종 출력을 향해 초기 noise vector $\epsilon$을 반복적으로 업데이트하는 데 필요한 noise content $\hat{\epsilon}$을 추정한다. 본질적으로 텍스트 캡션 $c$와 함께 noisy한 입력 버전 $\alpha_t \hat{x} + \sigma_t \epsilon$이 주어지면 noise를 추정한다. 본 논문의 경우 이 프로세스는 latent space 내에서 작동한다. 이러한 설정에 따라 목적 함수는 다음과 같이 다시 쓸 수 있다.
\[\begin{equation} \mathbb{E}_{z, c, \epsilon, t} [w_t \cdot \| Q_\theta (\mathcal{E}(\hat{x}^{[t]}), \mathcal{T}(c), t) - \epsilon \|_2^2 ] \end{equation}\]이 목적 함수만으로도 cross-modal 유사성 측정의 역할을 할 수 있지만 diffusion model $Q_\theta$를 통한 기울기 업데이트는 계산 비용이 많이 들고 최적화 불안정성을 초래할 수 있다. 따라서 diffusion model 전체의 기울기를 무시하여 다음과 같이 Dream Loss $\mathcal{L}_d$를 얻을 수 있다.
\[\begin{aligned} \hat{\epsilon}_t &= Q_\theta (\mathcal{E} (\hat{x}^{[t]}), \mathcal{T}(c), t) \\ \nabla_\phi \mathcal{L}_d (\hat{x}, c) &= \mathbb{E}_{\epsilon, t} \bigg[ w_t \cdot (\hat{\epsilon}_t - \epsilon) \cdot \frac{\partial \hat{y}}{\partial \phi} \bigg] \end{aligned}\]여기에서 텍스트 캡션 $c$에 따라 최적의 segmentation을 얻기 위해 Dream Loss $\mathcal{L}_d$에 대해 alpha mask $\hat{x}$를 최적화한다.
5. Auxiliary Losses
분할 프로세스를 향상시키기 위해 두 가지 보조 loss, Gravity Loss $\mathcal{L}_g$와 Intersection Loss $\mathcal{L}_i$를 포함한다. 이들은 각각 이미지 배경과 객체의 intersection에 관한 휴리스틱을 통합한다. 특히 Gravity Loss는 텍스트 캡션과 가장 유사한 영역 외부에 배경(또는 텍스트 캡션과 관련 없는 영역)이 있다고 가정하고 이러한 영역의 alpha mask 값을 0으로 만드는 것을 목표로 한다. 이것은 모든 alpha mask 값의 합계에 대한 loss로 구현되어 기본적으로 0으로 만든다.
Intersection Loss는 단일 픽셀 위치가 단일 객체에 해당하는 휴리스틱에 따라 공간적으로 겹치는 영역을 포함하는 마스크에 불이익을 준다. 이 두 번째 loss는 개체 기반 segmentation task에만 통합되며 이러한 휴리스틱이 적용되지 않을 수 있는 referring segmentation에는 포함되지 않는다. 총 loss $\mathcal{L}_f$는 세 가지 loss 모두의 합이다.
\[\begin{aligned} \mathcal{L}_g (\hat{y}) &= \sum \hat{y} \\ \mathcal{L}_f &= \mathcal{L}_{cd} + \mathcal{L}_g + \mathcal{L}_i \end{aligned}\]Analagous Example
저자들은 Peekaboo의 직관을 설명하기 위해 Peekaboo에 영감을 준 유사한 실험 결과를 보여준다.
먼저 LAION-5B에서 사전 학습된 Stable Diffusion 모델을 분석한다. 저자들의 목표는 개별 개체의 경계 및 localizaiton에 관한 모델의 내부 지식에 접근하여 segmentation과 같은 task에 활용할 수 있는지 여부를 탐색하는 것이다. 일부 배경에서 단일 합성 개체를 생성하는 경우에 초점을 맞추고 전경 개체에 속하는 영역을 구분하는 alpha mask를 생성하려고 시도한다. 저자들은 제안된 Dream Loss를 전경 개체를 설명하는 텍스트 캡션과 그것이 위치한 이미지 영역에 연결하는 cross-modal 유사성 함수로 활용한다. 이 유사성을 최적화 목적 함수로 사용하여 전경, 배경, alpha mask를 생성한다. 저자들은 암시적 신경망 함수를 사용하여 배경에 대한 하나의 네트워크와 전경 및 alpha mask에 대한 공유 네트워크를 사용하여 이러한 각 요소를 나타낸다. 후자의 디자인 선택은 생성된 전경과 alpha mask 간의 정보 공유를 목표로 한다.

이 과정에서 얻은 결과는 위 그림에 설명되어 있다. 저자들의 방법은 전경과 관련된 좋은 segmentation mask를 생성할 수 있지만 생성된 이미지는 비현실적이다. 저자들은 생성된 이미지 품질이 단일 채널 alpha mask를 생성하는 segmentation 구성 요소와 무관하다는 점을 강조한다. 본 논문의 나머지 부분은 독립형 이미지, 즉 diffusion model에 의해 생성된 이미지를 넘어서는 이미지를 분할하는 데 이 기술을 어떻게 활용할 수 있는지에 초점을 맞춘다. 본질적으로 자유 형식 텍스트 캡션으로 실제 이미지를 분할하려고 한다.
Experiments
- 데이터셋: Pascal VOC (semantic segmentation), RefCOCO (referring segmentation)
- 학습 세부 사항
- 본 논문의 접근법은 모델의 재학습이 필요 없으며 inference time 최적화만 수행
- 이미지 1개를 분할하는 데 NVIDIA RTX 3090Ti GPU으로 3분 소요
1. Referring Segmentation
다음은 RefCOCO의 이미지에 커스텀 텍스트 프롬프트를 사용하여 referring segmentation을 적용한 샘플들이다. 왼쪽 그림의 프롬프트는 왼쪽 하단에 나와 있으며, 오른쪽 6개의 그림에 대한 프롬프트는 각각 “baby”, “brown cow”, “elephant on right”, “guy in red”, “red jacket”, “the front horse”이다.

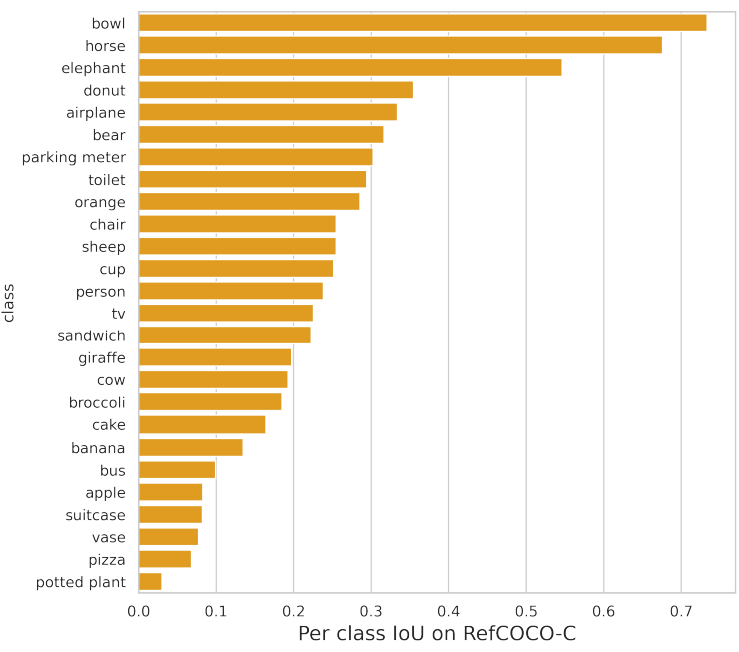
다음은 수정된 RefCOCO (RefCOCO-C) 데이터셋에서의 정량적 평가 결과이다.

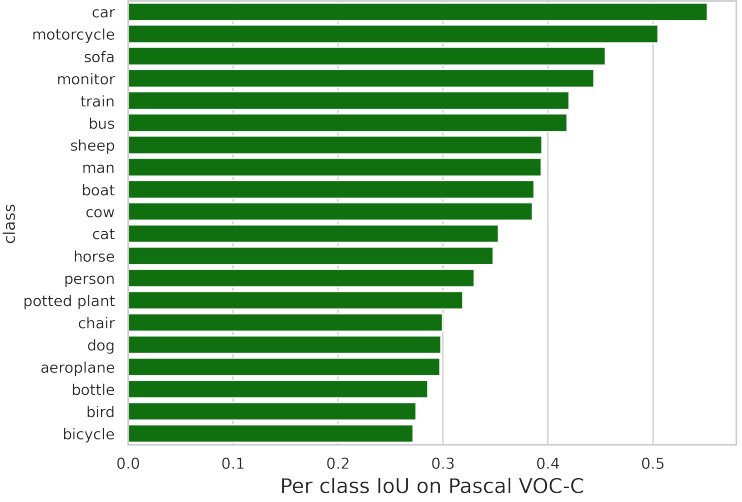
다음은 RefCOCO-C에서의 클래스별 IoU 값을 나타낸 그래프이다.
2. Semantic Segmentation
다음은 수정된 Pascal VOC (Pascal VOC-C) 데이터셋에서의 정량적 평가 결과이다.

다음은 Pascal VOC-C에서의 클래스별 IoU 값을 나타낸 그래프이다.