[논문리뷰] PDT: Point Distribution Transformation with Diffusion Models
SIGGRAPH 2025. [Paper] [Page]
Jionghao Wang, Cheng Lin, Yuan Liu, Rui Xu, Zhiyang Dou, Xiao-Xiao Long, Hao-Xiang Guo, Taku Komura, Wenping Wang, Xin Li
Texas A&M University | The University of Hong Kong | HKUST | Nanjing University | Skywork AI
25 Jul 2025

Introduction
본 논문에서는 diffusion model을 이용한 Point Distribution Transformation (PDT)이라는 새로운 프레임워크를 소개한다. Shape geometry를 나타내는 입력 포인트 클라우드가 주어졌을 때, 본 방법은 입력 포인트 클라우드를 표면 확률 분포에서 추출한 샘플로 간주하여, 점들을 원래 표면 분포에서 semantic하게 유의미한 타겟 분포로 변환하는 방법을 학습시킨다. Keypoint나 feature line과 같은 타겟 점들은 3D 공간에서 별도의 확률 분포로 취급된다. 입력 포인트에 Gaussian noise를 주입하고, 표면 geometry 분포와 타겟 분포를 각 점에 대한 명시적인 guidance를 통해 상관시켜 타겟 점으로 점진적으로 denoising함으로써 두 분포 간의 확률적 매핑을 구축한다.
본 논문에서 제시하는 방법은 전반적으로 단순하면서도 효과적이며, 서로 다른 점 분포 간의 변환에 적합하도록 몇 가지 핵심적인 설계 특징을 갖추고 있다.
- Noise가 포함된 입력 점과 타겟 점 사이에 명시적인 대응 관계를 도입함으로써, denoising process가 특정 영역의 로컬 geometry를 효과적으로 인식하고, 해당 로컬 구조에 정렬되는 타겟 점을 생성할 수 있도록 했다.
- 타겟 점들의 분포는 일반적으로 밀집되어 있고 sparse한 반면, 입력 점 분포는 일반적으로 dense하기 때문에, 본 방법은 방대한 점 집합에서 각 점을 sparse한 목표 점 집합 내의 정확한 위치로 정확하게 매핑할 수 있어야 한다.
- 저자들은 세밀한 디테일을 포착하는 denoising process의 능력을 향상시키기 위해, 로컬 디테일 학습을 강화하는 noise schedule을 신중하게 설계했다.
- Inference 과정에서 gradient 기반 전략을 도입하여 PDT를 더욱 정밀하고 효과적으로 제어할 수 있도록 했다.
본 논문에서는 입력 점들을 서로 다른 prior를 반영하는 타겟 분포로 변환하는 세 가지 task에서 제안된 방법을 테스트하였다.
- 표면에 정렬된 메쉬 keypoint
- 내부 skeletal joint
- Continuous feature line
이 세 가지 분포는 목표 점과 소스 점 geometry 간의 서로 다른 구조적 의존성을 반영한다. PDT는 이러한 task 전반에 걸쳐 강력한 구조 예측 및 인식 능력을 보여주며, semantic하게 유의미한 점 분포를 효과적으로 생성할 수 있다.
Method
1. Geometry Distribution Transformation
본 논문의 목표는 diffusion model을 사용하여 임의의 표면 점 분포 \(p_S (\textbf{x})\)에서 semantic하게 유의미한 타겟 점 분포 \(p_T (\textbf{x})\)로의 변환을 학습하는 것이다. 소스 표면 분포 \(p_S (\textbf{x})\)에서 샘플링된 레퍼런스 포인트 클라우드 \(\textbf{P}_\textrm{ref} = \{p_\textrm{ref}^i \in \mathbb{R}^3 \vert i = 1, \ldots, N\}\)가 주어졌을 때, 모델은 구조적 특징을 나타내는 타겟 포인트 클라우드 \(\textbf{P}_\textrm{target} = \{p_\textrm{target}^i \in \mathbb{R}^3 \vert i = 1, \ldots, N\}\)을 생성해야 한다.
DDPM 프레임워크를 따라, 초기 분포를 변형하기 위해 동일한 forward process를 사용한다. Reverse process는 현재 상태 \(\textbf{x}_t\)와 레퍼런스 포인트 \(\textbf{P}_\textrm{ref}\) 모두를 조건으로 noise 성분을 예측하는 모델 \(\epsilon_\theta (\textbf{x}_t, t, \textbf{P}_\textrm{ref})\)를 학습한다. 이를 통해 조건부 확률 \(p_\theta (\textbf{x}_{t-1} \vert \textbf{x}_t, \textbf{P}_\textrm{ref})\)를 이용한 guided denoising이 가능해진다.
Inference 시에는 \(\textbf{x}_t \sim \mathcal{N}(0,I)\)에서 시작하여 타겟 분포 \(p_T (\textbf{x})\)로 수렴하는 점들을 반복적으로 샘플링한다. \(\textbf{P}_\textrm{ref}\)에 대한 조건부 확률은 생성 프로세스 전반에 걸쳐 소스 표면과의 기하학적 관계를 유지하도록 한다.
2. Model Design
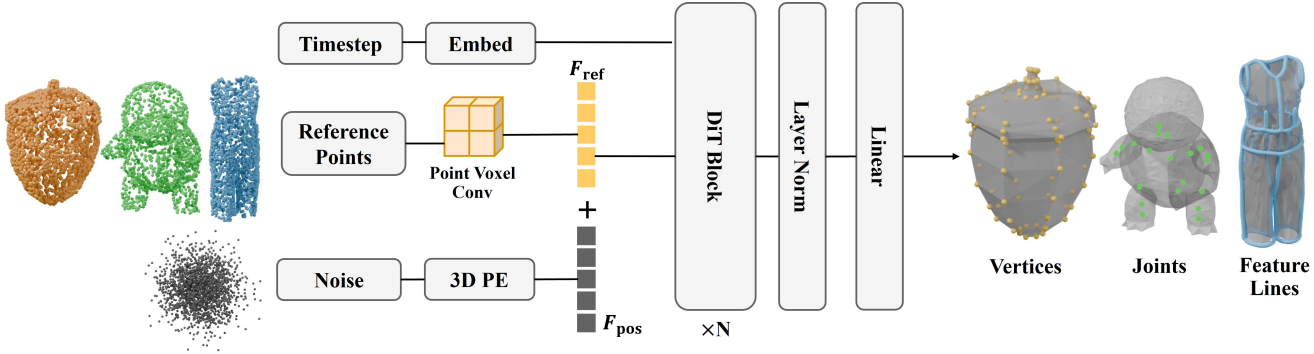
본 모델의 아키텍처는 diffusion process 전반에 걸쳐 명확한 점별 대응 관계를 유지하면서 소스 점 분포와 타겟 점 분포 간의 분포 변환을 효과적으로 학습하도록 설계되었다. 본 설계는 DiT 프레임워크와 PVCNN feature extractor를 통합한다. PVCNN은 robust한 point feature 추출을 가능하게 하고 DiT는 denoising process를 가이드한다. 이러한 설계 선택은 문제 정의에서 제시된 두 가지 핵심 요구 사항에 기인한다.
- \(\textbf{P}_\textrm{ref}\)와 그에 대응하는 타겟 위치 간의 점별 관계를 처리하고 유지해야 한다.
- 이러한 기하학적 관계에 기반하여 denoising process를 컨디셔닝해야 한다.
따라서 PVCNN은 \(\textbf{P}_\textrm{ref}\)에서 로컬한 geometric context를 포착하는 포인트별 feature를 효율적으로 추출하며, DiT의 transformer 아키텍처는 self-attention 메커니즘을 통해 조건부 확률 \(p_\theta (\textbf{x}_{t-1} \vert \textbf{x}_t, \textbf{P}_\textrm{ref})\)를 효과적으로 모델링할 수 있도록 한다. 이러한 조합을 통해 모델은 diffusion 궤적 전체에 걸쳐 점별 대응 관계를 유지하면서 \(p_S (\textbf{x})\)에서 \(p_T (\textbf{x})\)로의 변환을 지배하는 기하학적 관계를 학습할 수 있다.
먼저 PVCNN을 사용하여 \(\textbf{P}_\textrm{ref}\)에서 각 포인트별 feature를 추출한다. 그 결과 feature 행렬 \(\textbf{F}_\textrm{ref} \in \mathbb{R}^{N \times C}\)가 생성된다 ($N$은 포인트 개수, $C$는 feature 차원). 이렇게 추출된 feature들은 noise가 더해진 주요 포인트들을 타겟 위치로 가이드하는 레퍼런스 역할을 한다.
학습 가능한 위치 임베딩 함수 \(\textbf{E}_\textrm{pos} : \mathbb{R}^3 \rightarrow \mathbb{R}^C\)가 적용된다. 이 함수는 \(\textbf{P}_\textrm{ref}\)의 각 점의 $(x, y, z)$ 좌표를 입력으로 받아 각 점에 해당하는 feature 임베딩을 출력한다. 추출된 \(\textbf{F}_\textrm{ref}\)와 위치 임베딩 \(\textbf{F}_\textrm{pos} = \textbf{E}_\textrm{pos} (\textbf{P}_\textrm{ref})\)를 결합하여 DiT의 입력 토큰 \(\textbf{F}_\textrm{in} = \textbf{F}_\textrm{ref} + \textbf{F}_\textrm{pos}\)를 생성한다.
또한, 기존 DiT 구조와 일관되게 timestep 임베딩 \(\textbf{F}_\textrm{time} \in \mathbb{R}^C\)을 DiT의 조건 신호로 통합한다. 각 DiT block은 self-attention branch와 feed-forward network (FFN) branch로 구성된다. Self-attention branch는 모든 포인트 간의 글로벌 정보 교환을 가능하게 하는 반면, FFN branch는 point feature를 독립적으로 처리한다. 두 branch 모두 timestep 임베딩을 조건으로 하는 AdaLN과 scale-shift 연산을 통해 처리된다.
3. Noise Schedule
Diffusion model에서 noise schedule은 시퀀스 \(\beta_t\)로 표현되며, forward process의 각 timestep에서 더해지는 Gaussian noise level을 결정한다. 기존 DDPM에서는 간단한 linear schedule이 사용되었다.
Semantic하게 중요한 점들은 일반적으로 수가 적고 밀집되어 있는 반면, 샘플링 포인트의 수는 상대적으로 많다. 따라서 샘플링 포인트가 소수의 포인트 주변에 조밀하게 클러스터링되는 것이 이상적인 시나리오이다. 그러나 실험 결과, 기존의 noise schedule은 생성된 점들이 타겟 점에 정확하게 수렴하지 않는다. 이러한 현상의 원인은 diffusion process 후반부 ($t=0$에 가까운 timestep)에서 noise level이 상대적으로 높기 때문이다. 이 timestep에서는 생성된 포인트들이 이상적으로는 밀집된 클러스터를 형성해야 한다. 후반 timestep에서 noise 규모가 크면 분산이 과도하게 증가하여 생성된 점들이 정확하게 수렴하지 못하게 된다.
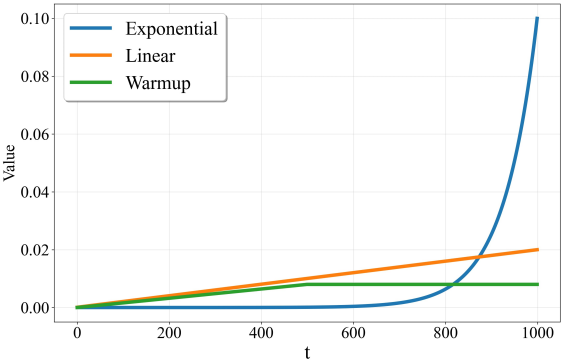
저자들은 이 문제를 해결하기 위해, $t=0$에 가까운 \(\beta_t\) 값이 상당히 작은 exponential schedule을 사용했다. 수정된 schedule은 작은 timestep에서 더 작은 \(\beta_t\) 값을 가지므로 denoising process의 디테일한 부분에 더 많은 노력을 기울인다.
하지만 적절한 학습을 보장하기 위해 $t = 1000$에 가까운 timestep의 \(\beta_t\) 값이 상당히 커야 한다. 학습 분포와 inferece 분포 간의 차이를 최소화하기 위해서는 $t$가 클 때 분산 \(\sqrt{1 - \bar{\alpha}_t}\)가 1에 가까워야 하며, 이를 통해 forward process가 표준 Gaussian 분포를 적절히 근사화할 수 있다. 저자들은 최종 \(\beta_t\) 값을 0.1로 설정했으며, \(\sqrt{1 - \bar{\alpha}_t} \approx 0.9998\)이 되어 표준 Gaussian 분포에 충분히 근접하면서도 안정적인 학습을 제공한다.
4. Sampling gradient adjustment
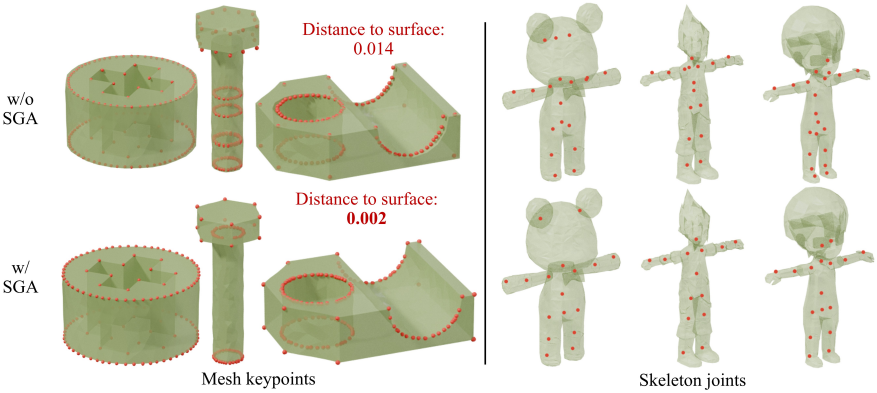
모델 학습이 완료되면 inferece 시에 분포 수렴 방향에 제약을 가하여 타겟 점 분포를 원하는 결과로 유도하고 기하학적 정확도를 향상시킬 수 있다. 이를 위해 저자들은 다양한 타겟 분포에 맞게 커스터마이징할 수 있는 sampling gradient adjustment (SGA) 전략을 도입했다.

샘플링 프로세스는 각 denoising step에서 보정 gradient 항을 도입한다. 주어진 timestep $t$에 대해 현재 추정 위치 \(\hat{\textbf{x}}_0\)와 타겟 제약 조건을 기반으로 geometry 정보를 고려한 gradient를 계산한다. 그런 다음 이 gradient를 step size $\rho$로 적용하여 점들을 기하학적으로 최적의 위치로 유도한다.
타겟 분포의 특성에 따라 다양한 제약 조건을 적용할 수 있다. 예를 들어, 타겟 분포가 표면에 정렬된 경우 (ex. 메쉬 keypoint), gradient는 점들을 입력 표면 $\mathcal{M}$ 쪽으로 유도하여 생성된 점들이 표면에 가깝게 정렬되도록 한다. Gradient는 각 예측된 점과 가장 가까운 표면 점 사이의 거리를 제곱하여 계산한다. 타겟 점 분포가 표면 내부에 있는 경우 (ex. 내부 skeletal joint), normal 방향 반전과 같은 방향 조정을 사용하여 joint를 중심축에 더 가깝게 유도할 수 있다.
Applications
1. Surface mesh keypoints
입력 메쉬 $\mathcal{M}$이 주어지면, 먼저 메쉬 표면에서 dense한 레퍼런스 포인트 집합 \(\textbf{P}_\textrm{ref}\)를 샘플링한다. 그런 다음, PDT 프레임워크는 이러한 레퍼런스 점들을 아티스트가 만든 메쉬에서 관찰되는 구조적 특성을 유지하면서 주요 기하학적 특징을 포착하는 포인트 위치 집합으로 변환한다. 이러한 예측 위치는 가장 가까운 표면 삼각형 vertex에 projection되고, 수정된 Quadric Error Metrics (QEM) 단순화 프로세스에서 위치 제약 조건으로 사용된다.
2. Inner skeletal joints
입력 캐릭터 메쉬 $\mathcal{M}$이 주어졌을 때, PDT 프레임워크를 사용하여 볼륨 내에 존재하는 skeletal joint 위치를 예측한다. 입력 메쉬의 표면 샘플 \(\textbf{P}_\textrm{ref}\)를 처리하여, 이러한 외부 점들을 캐릭터의 해부학적 구조를 포착하는 내부 skeletal joint로 변환한다.
3. Continuous feature lines
의류 표면에서의 \(\textbf{P}_\textrm{ref}\)가 주어지면, 이러한 입력 포인트를 패턴 사이의 스티치나 경계선과 같은 중요한 구조적 요소를 나타내는 continuous feature line 상의 포인트로 변환한다. PDT는 의미 있는 feature 경로를 따라 위치한 포인트들을 식별하고 연결하는 방법을 학습하여, 로컬 디테일과 전체적인 의류 구조를 모두 포착하는 dense한 선을 생성한다.
Experiments
1. Comparisons: remeshing
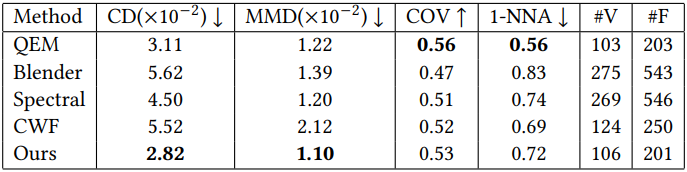
다음은 remeshing에 대한 비교 결과이다.

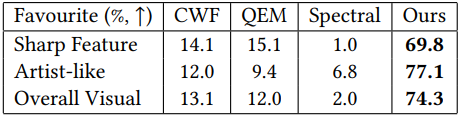
다음은 sharp-feature 보존에 대한 user study 결과이다.
2. Comparisons: skeletal joints
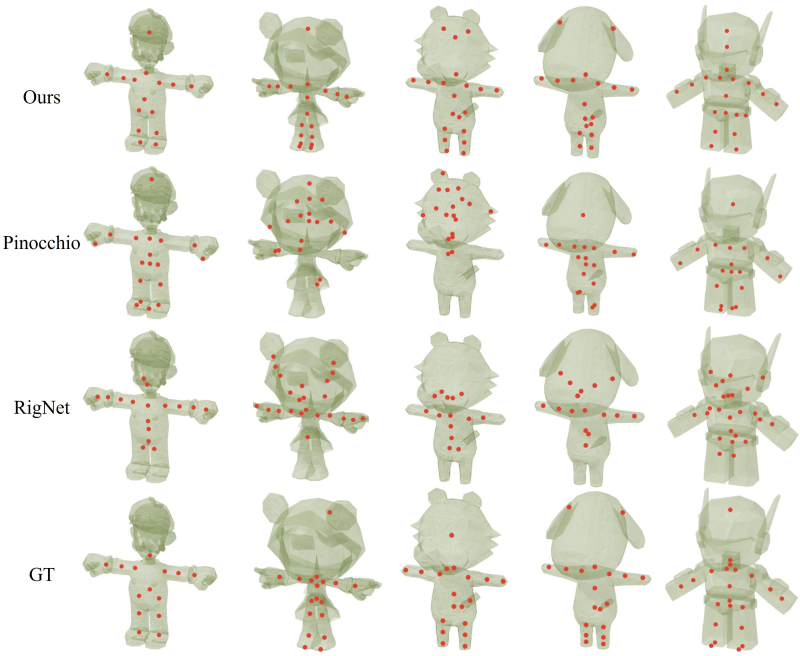
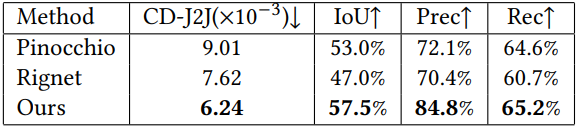
다음은 skeletal joint 예측에 대한 비교 결과이다.
3. Discussions
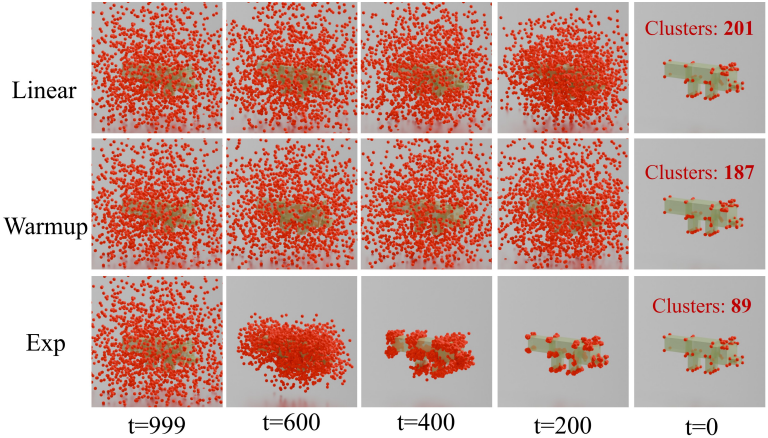
다음은 denoising 과정을 시각화한 것이다.
다음은 SGA에 대한 ablation 결과이다.
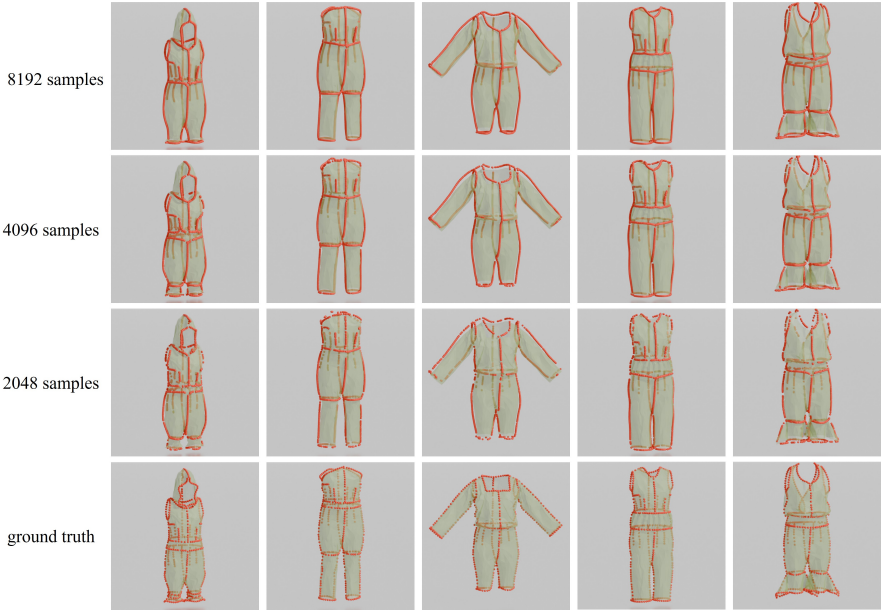
다음은 입력 샘플링 포인트 수에 따른 feature line 추출 결과를 비교한 것이다.