[논문리뷰] Patched Denoising Diffusion Models For High-Resolution Image Synthesis (Patch-DM)
arXiv 2023. [Paper]
Zheng Ding, Mengqi Zhang, Jiajun Wu, Zhuowen Tu
University of California, San Diego | Stanford University
2 Aug 2023

Introduction
GAN은 폭발적인 발전을 이루었지만, 많은 GAN 모델은 아직 학습시키기 어렵다. VAE 모델은 학습하기가 더 쉽지만 결과 이미지 품질이 흐릿한 경우가 많다. Diffusion model은 최근 뛰어난 품질의 생성된 이미지로 엄청난 인기를 얻었다. Diffusion model의 뛰어난 모델링 능력에도 불구하고 현재 모델은 학습과 합성 모두에서 여전히 어려움에 직면해 있다.
픽셀 공간의 직접적인 최적화와 여러 timestep의 학습 및 inference로 인해 diffusion model은 고해상도 이미지 생성으로 확장하기가 어렵다. 따라서 현재의 SOTA 모델은 super-resolution 방법을 사용하여 생성된 이미지를 더 높은 해상도로 높이거나 픽셀 공간 대신 latent space를 최적화한다. 그러나 두 가지 접근 방식 모두 여전히 큰 모델 크기로 큰 메모리를 소비하는 고해상도 이미지 generator로 구성된다.
본 논문은 현재 diffusion model의 한계를 개선하기 위해 새로 도입된 feature collage 전략을 사용하여 고해상도 이미지를 생성하는 새로운 방법인 Patch-DM을 제안한다. Patch-DM이 기본적으로 동작하는 지점은 전체 이미지를 모델링하는 것에 비해 상대적으로 컴팩트한 패치 수준의 모델이다. 패치 기반 표현에 대한 절충안이 도입된 것으로 보이지만, Patch-DM은 이미지 패치 경계 근처의 픽셀에 대한 경계 효과의 아티팩트 없이 원활한 전체 크기 고해상도 이미지 합성을 수행할 수 있다. 고해상도 이미지를 직접 생성하는 Patch-DM의 효율성은 새로운 feature collage 전략을 통해 구현된다. 이 전략은 sliding window 기반의 이동된 이미지 패치 생성 프로세스를 구현하여 feature 공유를 돕고 인접한 이미지 패치 간의 일관성을 보장한다. 이는 추가 파라미터 없이 경계 아티팩트를 완화하기 위해 제안된 Patch-DM 방법의 핵심 디자인이다.
Patched Denoising Diffusion Model
Patch-DM은 학습을 위해 전체 이미지를 사용하는 대신 학습 및 inference를 위한 패치만 가져오고 feature collage를 사용하여 이웃 패치의 부분 feature를 체계적으로 결합한다. 결과적으로 Patch-DM은 해상도에 구애받지 않으므로 고해상도 이미지 생성과 관련된 높은 계산 비용 문제를 해결할 수 있다.
데이터셋의 학습 이미지는 $x_0 \in \mathbb{R}^{C \times H \times W}$이다. $x_0$를 $x_0^{(i,j)}$으로 분할한다. 여기서 $i$, $j$는 패치의 행과 열 번호이고, $x_0^{(i,j)} \in \mathbb{R}^{C \times h \times w}$이다. 대부분의 방법처럼 $x_0$를 직접 생성하는 대신 Patch-DM은 $x_0^{(i,j)}$만 생성하고 이를 concat하여 완전한 이미지를 형성한다.
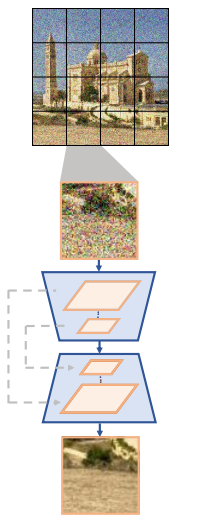
이를 수행하는 매우 기본적인 방법은 위 그림과 같이 denoising model이 noisy한 이미지 패치 $x_t^{(i,j)}$를 입력으로 사용하고 해당 noise \(\hat{\epsilon}_t^{(i,j)}\)를 출력하는 것이다. 그러나 패치가 서로 상호 작용하지 않으므로 심각한 경계 아티팩트가 발생한다.
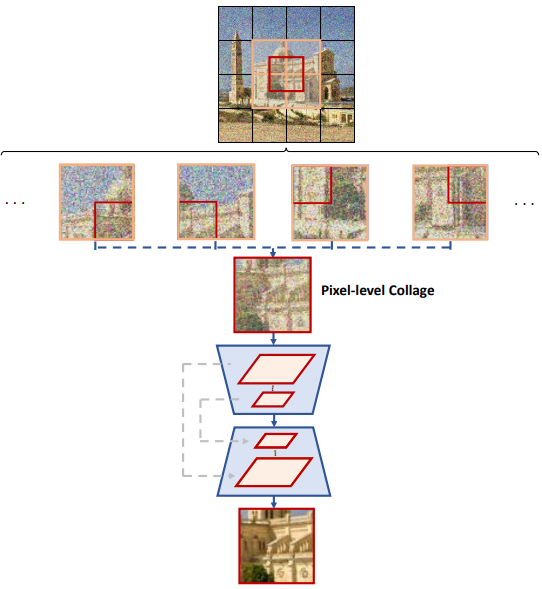
또 다른 방법은 위 그림과 같이 각 timestep 동안 이미지 패치를 이동하는 것이다. 서로 다른 timestep에서 모델은 원래 분할 패치 $x_t^{(i,j)}$ 또는 이동된 분할 패치 $x_t^{\prime (i,j)}$를 사용하여 경계 아티팩트를 완화할 수 있다. 이를 “픽셀 공간의 패치 콜라주”라고 부른다. 하지만 경계 아티팩트가 여전히 존재한다.
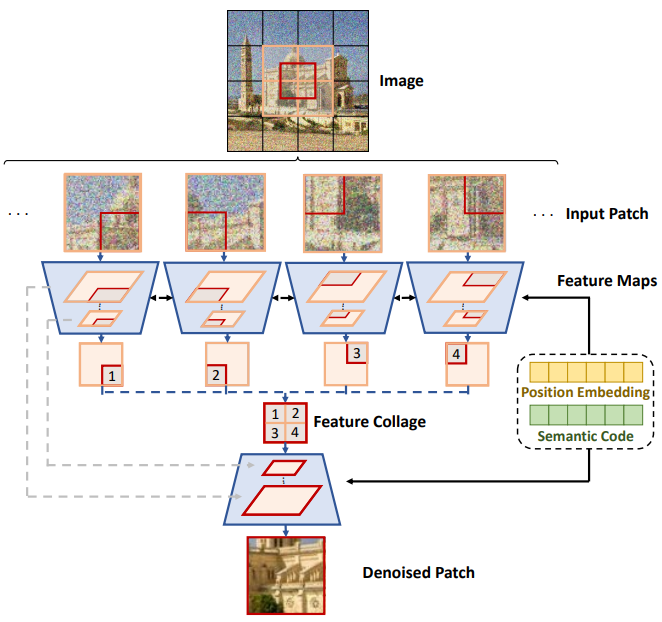
이 방법을 더욱 개선하기 위해 본 논문은 위 그림에 묘사된 새로운 feature collage 메커니즘을 제안한다. 픽셀 공간에서 패치 콜라주를 수행하는 대신 feature space에서 수행한다. 이를 통해 패치는 인접한 feature를 더 잘 인식할 수 있으며 전체 이미지를 생성하는 동안 경계 아티팩트가 나타나는 것을 방지할 수 있다.
여기서 $f_\theta^E$는 UNet 인코더이고 $z_1^{(i,j)}, z_2^{(i,j)}, \ldots, z_n^{(i,j)}$은 내부 feature map이다. 그런 다음 feature map을 분할하고 분할 feature map을 콜라주하여 shift patch를 생성한다.
\[\begin{equation} z_k^{\prime (i,j)} = [P_1 (z_k^{(i,j)}), P_2 (z_k^{(i, j+1)}), P_3 (z_k^{(i+1, j)}), P_4 (z_k^{(i+1, j+1)})] \end{equation}\]여기서 $P_1$, $P_2$, $P_3$, $P_4$는 분할 함수이다. 그런 다음 이러한 콜라주된 shift feature \(z_k^{\prime (i,j)}\)를 UNet 디코더로 보내 예측된 shift patch noise를 얻는다.
\[\begin{equation} \epsilon_t^{\prime (i,j)} = f_\theta^D ([z_1^{\prime (i,j)}, z_2^{\prime (i,j)}, \ldots, z_n^{\prime (i,j)}], t) \end{equation}\]모델이 보다 의미론적으로 일관된 이미지를 생성하도록 하기 위해 모델에 위치 임베딩 $\mathcal{P}(i, j)$와 semantic 임베딩 $\mathcal{E}(x_0)$도 추가하며, $f_\theta$가 두 개의 입력을 더 받도록 한다.
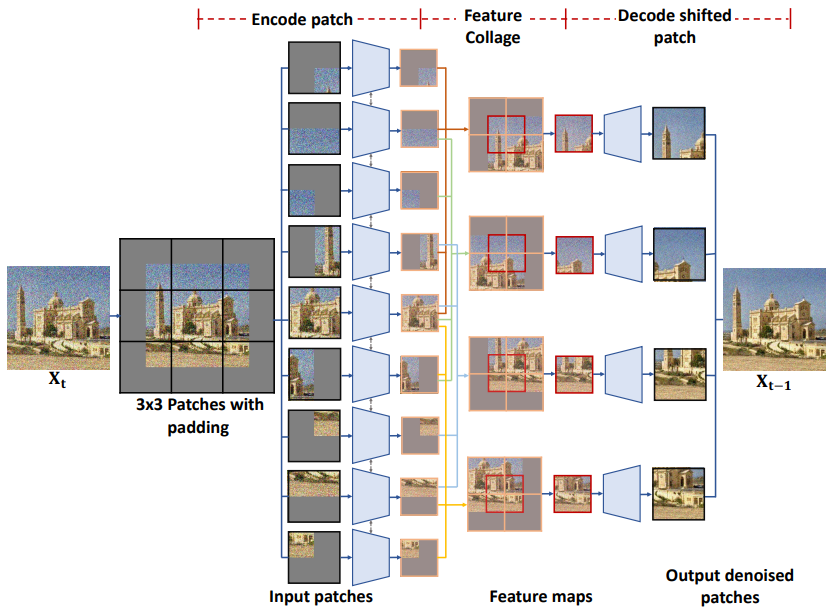
위 그림은 3$\times$3 패치를 사용하는 inference 예시이다. 경계 패치를 생성하기 위해 먼저 정보 손실 없이 각 패치에 대해 feature collage가 수행될 수 있도록 이미지를 패딩한다. 각 timestep $t$에서 이미지 $x_t$는 후속 인코더에 공급되는 패치로 분해된다. Feature map이 디코더를 통과하기 전에 분할 및 콜라주 연산이 적용된다. 따라서 디코더는 이동된 패치의 예측된 noise를 출력한다. Diffusion model의 식을 사용하면 $x_{t−1}$을 얻을 수 있고, 따라서 최종 완전한 이미지를 생성할 수 있다.
Experiments
- 아키텍처
- ADM의 U-Net model에 글로벌 조건과 위치 임베딩을 추가
- 글로벌 조건
- 1024$\times$512 데이터셋: CLIP에서 얻은 이미지 feature를 글로벌 조건으로 사용
- 256$\times$256 데이터셋: 이미지 인코더를 공동으로 학습시키고 그 출력을 글로벌 조건으로 사용
- Classifier-free guidance
- 글로벌 조건과 위치 임베딩 모두에 classifier-free guidance를 사용
- dropout rate: 글로벌 조건은 0.1, 위치 임베딩은 0.5
- 패치 크기: 64$\times$64
- Inference
- denoising U-Net 모델이 학습되면 unconditional 이미지 합성을 위한 또 다른 latent diffusion model (LDM)을 학습시킴
- LDM의 아키텍처는 Diffusion Autoencoder에 설명된 아키텍처를 기반으로 함
- LDM 학습하는 데 사용하는 데이터는 학습된 이미지 인코더의 출력 또는 직접 최적화된 이미지 임베딩에서 나온 것
- 이미지를 합성하기 위해 먼저 LDM에서 latent code를 샘플링한 다음 이 latent code를 사용하여 이미지 샘플링을 위한 글로벌 조건으로 사용
- 샘플링 단계에서는 DDIM에서 제안한 inference 프로세스를 사용하고 샘플링 step은 50
1. Results on 1024×512 Images
- 데이터셋: Wallpaperscraft의 자연 이미지 21,443개
다음은 이전 패치 기반 이미지 생성 방법들과 정량적으로 비교한 표이다.
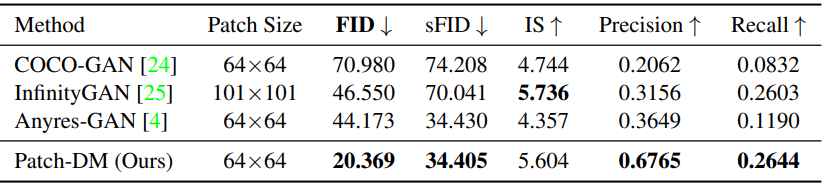
2. Results on 256×256 Images
- 데이터셋: FFHQ, LSUN-Bedroom, LSUN-Church
다음은 FFHQ, LSUN-Bedroom, LSUN-Church에서의 unconditional 이미지 생성 성능을 비교한 표이다.
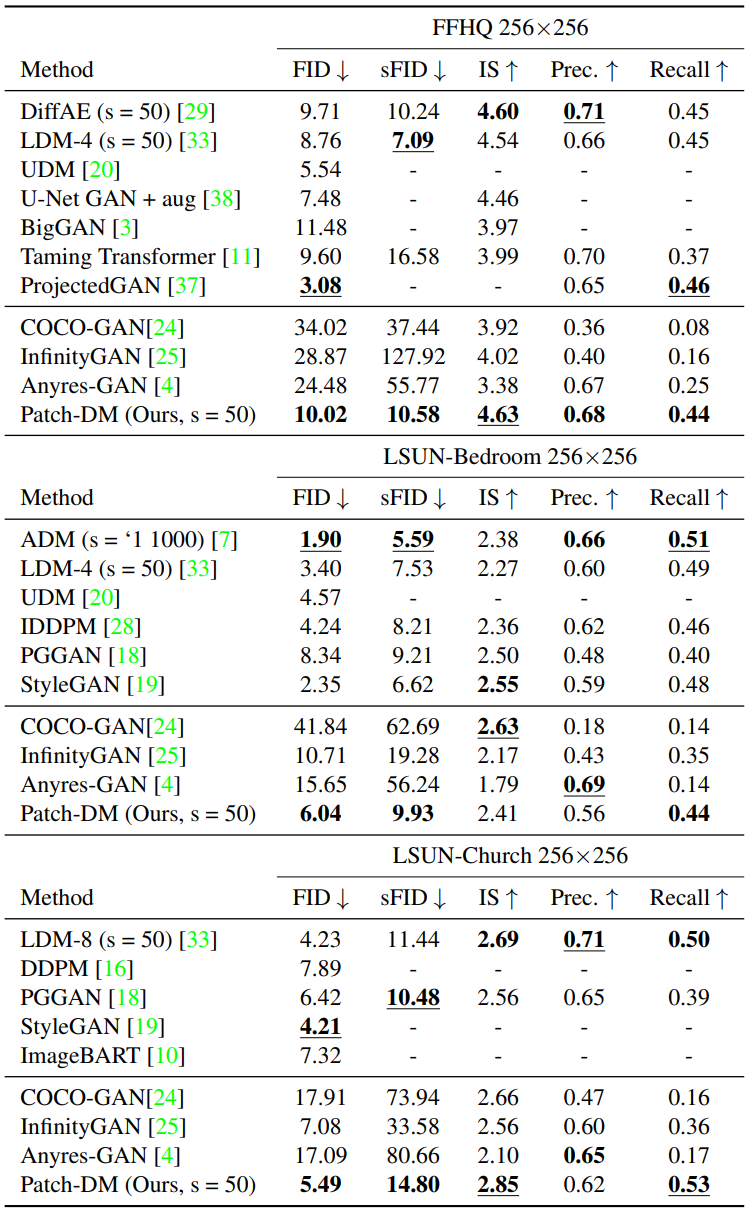
다음은 FFHQ, LSUN-Bedroom, LSUN-Church에서 생성된 이미지들이다.

다음은 다양한 256$\times$256 해상도의 diffusion model의 파라미터 수를 비교한 표이다.
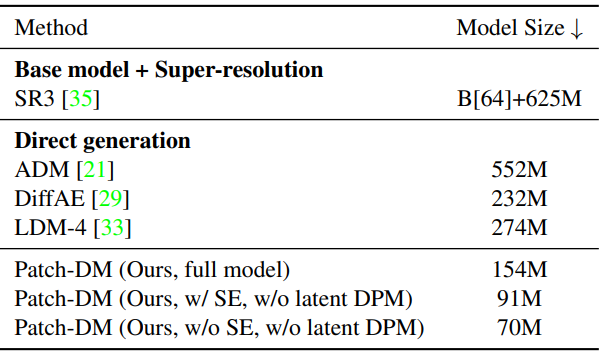
3. Applications
Beyond patch generation
다음은 생성된 2048$\times$1024 이미지이다. 패치의 수를 2배로 하여 2배 해상도의 이미지를 생성하였다.

다음은 256$\times$256 이미지에서 학습된 모델로 생성한 384$\times$384 이미지이다.

Image outpainting
다음은 LSUN-Bedroom과 LSUN-Church에서의 outpainting 예시이다.

Image inpainting
다음은 LSUN-Church에서의 inpainting 예시이다.

Ablation Study
다음은 글로벌 조건 (a), 위치 임베딩 (b), feature-level shift (c, d)에 대한 ablation 결과이다.

다음은 semantic 조건, 위치 임베딩, feature-level window shift에 대한 ablation 결과이다.
