[논문리뷰] PARASOL: Parametric Style Control for Diffusion Image Synthesis
arXiv 2023. [Paper]
Gemma Canet Tarrés, Dan Ruta, Tu Bui, John Collomosse
University of Surrey, Adobe Research
11 Mar 2023

Introduction
심층 생성 모델은 창의적 표현을 위한 엄청난 잠재력을 가지고 있지만 제어 가능성은 여전히 제한적이다. 특히, diffusion model은 고품질의 다양한 출력을 합성할 수 있지만 시각적 스타일과 같은 속성을 세밀하게 제어하는 능력은 개별 텍스트 기반 프롬프트 또는 이미지 예시에 의존하는 경우가 많다. 반면, visual search model은 parametric style embedding을 사용하여 보다 미묘한 제어를 달성하는 경우가 많다. 저자들은 이 격차를 해소하기 위해 Parametric Style Control (PARASOL)을 제안한다. PARASOL은 이미지의 시각적 스타일에 대한 분리된 제어를 가능하게 하는 새로운 합성 모델로, semantic cue와 fine-grained visual style embedding (ALADIN) 모두로 조건부 합성이 가능하다. 사용자 의도에 맞도록 텍스트 기반 검색 결과를 적용하고 콘텐츠 및 스타일 descriptor 중 하나 또는 둘 모두를 보간하여 생성 검색을 위한 이 프레임워크의 잠재력을 보여준다.
본 논문의 기여는 다음과 같다.
- Fine-grained style-conditioned diffusion: 독립적인 콘텐츠 및 스타일 descriptor를 설명하는 multi-modal 입력을 조건으로 하는 LDM (latent diffusion model)을 사용하여 이미지를 합성하고, Disentangle한 제어를 장려하는 joint loss를 사용하여 학습한다. Inference 중에는 콘텐츠 이미지를 noisy한 latent로 되돌리고 콘텐츠 및 스타일 컨디셔닝을 modality별 classifier-free guidance와 통합하는 denoising process를 다시 실행하여 각 modality의 대상 및 영향에 대한 세밀한 제어를 가능하게 한다.
- Cross-modal training via search: LDM 학습의 supervision을 위한 triplet(콘텐츠 입력, 스타일 입력, 이미지 출력)을 형성하기 위해 보조 semantic 및 스타일 기반 검색 모델을 사용하여 콘텐츠 및 스타일 cue의 상호보완성을 보장하여 inference에서 disentangle한 제어를 장려한다.
PARASOL은 세분화된 스타일 제어를 위해 ALADIN parametric embedding(원래 스타일화된 아트워크 검색을 위해 제안됨)을 활용한다. 그러나 PARASOL은 검색 자체에도 적용될 수 있다. ALADIN 임베딩을 위한 텍스트 인코더와 PARASOL을 결합하면 텍스트 기반 검색 쿼리의 결과를 세밀하게 조정하여 사용자가 검색 의도와 더 밀접하게 일치하도록 검색 결과를 반복할 수 있도록 애플리케이션을 generative search에 적용할 수 있다.
Methodology
본 논문은 세분화된 스타일 및 콘텐츠 정보에서 새로운 이미지를 창의적으로 합성하는 방법인 PARASOL을 제안한다. 저자들은 PARASOL을 설계하여 구조와 스타일에 대한 세밀한 제어를 극대화한다. 이를 유도하는 주요 디자인 선택은 다음과 같다.
- 파이프라인에 parametric style encoder (ALADIN)를 통합함으로써 보다 미묘한 disentangle된 스타일 정보가 네트워크에 제공되어 세분화된 스타일을 전송할 수 있다.
- 두 modality별 인코더의 metric 속성을 통해 여러 스타일과 semantic을 결합하고 interpolate하여 고도로 창의적인 콘텐츠를 생성할 수 있다.
- Inverse diffusion step은 이미지 생성 프로세스 전반에 걸쳐 콘텐츠 디테일 및 구조를 보존할 수 있도록 샘플링 시간에 통합된다.
- 각 modality가 이미지 생성에 독립적으로 영향을 미칠 수 있도록 특정 classifier-free guidance 형식이 도입되었다.
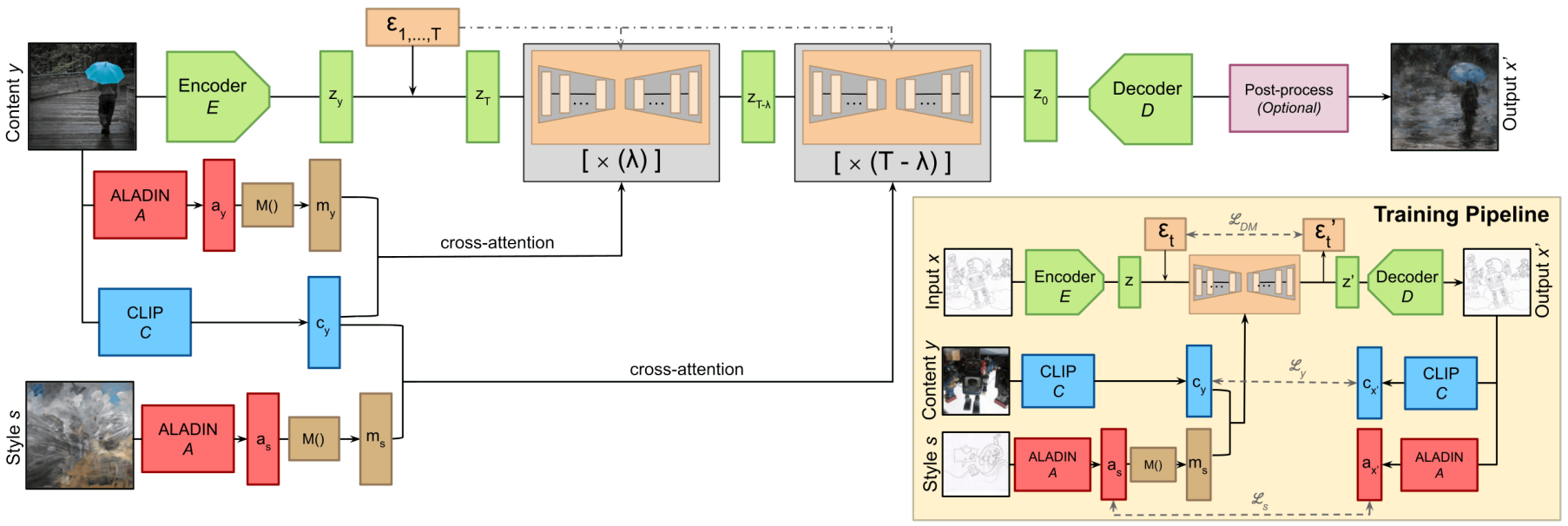
PARASOL의 핵심은 multimodal한 조건을 수용하기 위해 finetuning된 사전 학습된 LDM이다. 위 그림과 같이 파이프라인은 6개의 구성 요소로 구성된다.
- 이미지를 diffusion latent space로 인코딩/디코딩하기 위한 Autoencoder
- U-Net 기반 denoising network
- 시각적 모양에 대한 parametric control을 가능하게 하는 세분화된 스타일 인코더
- 콘텐츠 제어를 표현하는 시맨틱 인코더
- 모델 컨디셔닝을 위해 두 modality를 동일한 feature space로 연결하는 projector network
- 색상 보정을 위한 선택적 후처리 단계
1. Obtaining Training Supervision Data via Cross-Modal Search
PARASOL이 기반으로 하는 LDM을 finetuning하려면 triplet $(x, y, s)$의 데이터셋이 필요하다. 각 셋에서 출력 이미지 $x$는 스타일 이미지 $s$의 예술적 스타일과 콘텐츠 이미지 $y$의 semantic 콘텐츠와 일치하는 이미지이다.
이 데이터셋은 콘텐츠와 스타일의 두 가지 입력 modality에 대한 cross-modal 검색을 통해 구축된다. 이미지 $x$가 주어지면 해당 semantics descriptor $c_x = C(x)$와 style descriptor $a_x = A(x)$는 parametric modality specific encoders($C$와 $A$)를 사용하여 계산된다. Parametric 속성을 활용하여 각 feature space에서 nearest neighbours을 찾아 각 modality에 대해 가장 유사한 이미지를 검색할 수 있다.
두 입력 modality 사이의 disentanglement를 보장하기 위해 몇 가지 제한 사항이 적용된다. 첫째, 각 modality의 검색에 대해 서로 다른 데이터가 인덱싱된다. 스타일 및 미적 속성을 가진 이미지셋은 Style Database ($S$)로 정의된다. 이들은 parametric style encoder를 사용하여 인덱싱되고 스타일 이미지를 찾는 데 사용된다. 동시에 다양한 콘텐츠가 포함된 사실적인 이미지셋을 “Semantics Database” ($C$)로 정의하고 콘텐츠 이미지 $y$를 찾기 위해 parametric semantics encoder를 사용하여 인덱싱한다.
쿼리로 $a_x$를 사용하여 $S$에서 가장 스타일이 유사한 이미지 상위 $k$개를 스타일 이미지 $s$의 후보로 검색한다. Semantics feature space에서 $x$에 대한 유사성이 계산되고 이 유사성이 특정 임계값을 초과하면 후보로 폐기된다. 마지막으로 스타일 이미지 $s$는 모든 제한 사항을 충족하는 $S$에서 가장 가까운 이미지로 선택된다. Semantics 설명 $c_y$를 쿼리로 사용하여 $C$에서 콘텐츠 이미지 $y$를 찾는 것과 동일한 절차를 수행한다.
2. Encoding the Style and Semantics Inputs
Triplet(콘텐츠 이미지 $y$, 스타일 이미지 $s$, 출력 이미지 $x$)이 주어지면 diffusion model은 각각의 인코더를 통해 스타일 및 콘텐츠 이미지를 인코딩한 후 $y$와 $s$를 조건으로 $x$를 재구성하도록 학습된다.
두 가지 modality를 설명하는 데 동일한 사전 학습된 인코더를 사용할 수 있다. 그러나 task별로 큐레이트된 데이터에 대해 사전 학습된 modality별 인코더의 사용은 diffusion process 컨디셔닝에 유익했다. 또한 조건별 인코더(즉, 스타일 또는 semantic별)를 사용하면 콘텐츠 및 스타일 feature을 분리하는 데 크게 기여하고 각 속성에 대한 네트워크의 개별적이고 독립적인 컨디셔닝을 가능해진다.
그럼에도 불구하고 각 modality에 대해 서로 다른 인코더를 사용하는 것은 새로운 문제를 제기한다. 대부분의 경우 각 modality의 표현 형식이 동일하지 않거나 동일한 feature space에 속하지 않는다. 두 가지 개별 modality의 정보를 이해하고 통합하기 위해 하나의 조건부 modality에 대해 사전 학습된 LDM을 finetuning하는 것은 데이터와 컴퓨팅이 많이 필요할 수 있다. 따라서 저자들은 MLP 기반 projector network $M()$을 학습시켜 두 descriptor에 대한 joint space을 얻는다. 네트워크는 $s$의 style descriptor를 입력으로 사용하여 $y$의 semantics descriptor인 $c_y$와 동일한 feature space에 있는 새로운 임베딩 $m_s$로 project한다.
3. Incorporating Latent Diffusion Models
PARASOL은 사전 학습된 LDM 위에 구축된다. 사전 학습된 이 모델에는 Autoencoder와 U-Net denoising network로 구성된다. Autoencoder는 학습 내내 고정된 상태로 유지되는 반면 U-Net은 새로운 조건을 수용하도록 finetuning된다. Autoencoder는 인코더 $\mathcal{E}$와 디코더 $\mathcal{D}$로 구성된다. 각 이미지 $x$에 대해 인코더 $\mathcal{E}$는 이미지를 $z = \mathcal{E}(x)$에 임베딩하고 디코더 $\mathcal{D}$는 $z$에서 $x’ = \mathcal{D}(z)$를 재구성할 수 있다. Diffusion은 Autoencoder의 latent space에서 발생한다.
Latent Diffusion Model Background
$q()$를 데이터 분포하 하고 $z$를 샘플로 두자. 소량의 Gaussian noise $\epsilon_t, t = 1, \cdots, T$를 변수 $z$에 순차적으로 추가하여 noisy한 변수 $z_t$의 Markov chain을 생성할 수 있다. Diffusion model은 “Reverse diffusion process”라고 하는 Markov Chain의 reverse process을 통해 $z_t$를 denoise하여 $q()$를 학습한다.
이 프로세스는 직접 계산할 수 없기 때문에 이를 근사화하기 위해 신경망을 사용한다. 따라서 diffusion model은 더 noisy한 $z_t$에서 $z_{t-1}$을 추정하는 denoising autoencoder $\epsilon_\theta (z_t, t)$의 시퀀스로 해석될 수 있다. Reparametrization trick을 통해 이러한 각 denoising autoencoder는 다음을 최소화하도록 학습될 수 있다.
\[\begin{equation} L_{DM} = \mathbb{E}_{z_t, \epsilon_t \sim \mathcal{N}(0, 1), t} [\|\epsilon_t - \epsilon_t'\|^2], \quad \epsilon_t' = \epsilon_\theta (z_t, t) \end{equation}\]Conditioning through Cross-Attention
학습 과정에서 multimodal한 조건을 통합하도록 LDM을 finetuning한다. 특히, diffusion process는 $m_s$와 $c_y$라는 두 개의 독립적인 신호로 컨디셔닝되어야 한다. Denoising autoencoder $\epsilon_\theta$를 noisy한 샘플 $z_t$와 타임스탬프 $t$뿐만 아니라 두 신호로 컨디셔닝한다.
\[\begin{equation} \epsilon_\theta (z_t, t, m_s, c_y) \end{equation}\]LDM 논문과 Retrieval-augmented diffusion models (RDM)에서 영감을 받아 두 개의 신호 $m_s$와 $c_y$를 함께 스택하고 이를 cross-attention layer를 통해 U-Net의 모든 중간 layer에 매핑함으로써 cross-attention을 사용하여 이러한 새로운 신호를 U-Net backbone에 통합한다. 결과적으로 각 타임스텝 $t$에서 모델 $\epsilon_\theta$의 출력 $z_{t-1}$은 조건 $m_s$와 $c_y$를 모두 고려하여 계산된다.
Conditioning using Classifier-free Guidance
GLIDE 논문과 Diffusion models beat gans on image synthesis 논문에 제시된 바와 같이 조건부 diffusion model의 샘플은 classifier(-free) guidance을 사용하여 개선할 수 있다. 이것의 이면에 있는 아이디어는 특정 이미지의 생성으로 이어지는 컨디셔닝 modality의 로그 확률의 기울기에 의해 diffusion model의 평균과 분산을 부가적으로 교란시키는 것이다.
여러 modality를 독립적으로 수용하기 위해 classifier-free guidance의 아이디어를 확장한다. 학습 시 두 입력 조건은 네트워크가 unconditional한 출력을 생성하는 방법을 학습할 수 있도록 고정된 확률을 가진 null 조건 $\epsilon_\theta(z_t, t, \emptyset, \emptyset)$로 대체된다. 그런 다음 샘플링 시 이 출력은 $\epsilon_\theta (z_t, t, m_s, \emptyset)$와 $\epsilon_\theta (z_t, t, \emptyset, c_y)$ 방향으로 guide되고 $\epsilon_\theta(z_t, t, \emptyset, \emptyset)$에서 멀어진다.
\[\begin{aligned} \epsilon_\theta (z_t, t, m_s, c_y) &= \epsilon_\theta (z_t, t, \emptyset, \emptyset) \\ &+ g_s [\epsilon_\theta (z_t, t, m_s, \emptyset) - \epsilon_\theta (z_t, t, \emptyset, \emptyset)] \\ &+ g_y [\epsilon_\theta (z_t, t, \emptyset, c_y) - \epsilon_\theta (z_t, t, \emptyset, \emptyset)] \end{aligned}\]따라서 파라미터 $g_s$와 $g_y$는 이미지 생성 프로세스에서 스타일 또는 semantic 입력이 갖는 가중치를 결정하기 위해 도입된다. 따라서 두 파라미터의 비율을 조정함으로써 사용자는 스타일 및 semantic 입력이 출력에 미치는 영향의 정도를 근사화할 수 있다. 그러나 두 파라미터의 값이 높으면 이미지 품질이 높아지고 출력의 다양성이 낮아진다는 점에 유의해야 한다.
4. Training Pipeline
PARASOL은 RDM에서 사전 학습된 모델을 finetuning하여 학습한다. 각 학습 step에서 임의의 timestep $t \in [1, T]$가 선택된다. 각 학습 이미지 $x$는 사전 학습된 인코더 $\mathcal{E}$를 사용하여 $z$로 인코딩되고 Gaussian noise $\epsilon_t$로 noise 처리된다. 스타일 $s$와 콘텐츠 $y$ 측면에서 유사한 이미지는 $m_s$와 $c_y$로 인코딩된다. 임베딩 $z_t$는 U-Net denoising autoencoder에 입력되며, cross-attention을 통해 $m_s$와 $c_y$에 대해서도 컨디셔닝된다. 이 네트워크는 projector network $M()$과 함께 학습되는 파이프라인의 유일한 부분이다.
Training Objectives
학습은 3가지 loss의 결합을 최소화하여 수행된다.
- Diffusion Loss: $z_t$를 추정할 때 예측 noise $\epsilon_t’$와 실제 noise $\epsilon_t$ 사이의 거리를 최소화
- Modality-Specific Losses: 출력 이미지가 $s$와 동일한 스타일과 $y$와 동일한 semantic을 갖도록 하기 위해 재구성된 이미지 $x’$의 스타일 및 semantic은 각각 style encoder와 semantic encoder를 사용하여 인코딩된다. 따라서 두 loss는 $L_s = \textrm{MSE}(a_s, a_{x’})$와 $L_y = \textrm{MSE}(c_y, c_{x’})$로 계산된다.
세 가지 loss 모두 가중합으로 결합되고 동시에 최적화된다.
\[\begin{equation} L = L_{DM} + \omega_s \cdot L_s + \omega_y \cdot L_y \end{equation}\]Sampling Pipeline
샘플링 시 $y$의 세밀한 콘텐츠 디테일이 최종 이미지에 보존되도록 inversion process가 수행된다. 먼저, semantic 이미지 $y$는 $\mathcal{E}$를 통해 인코딩되고 완전한 forward diffusion process를 통해 noise 처리된다. 이 과정에서 각 timestep $t = 1, \cdots, T$에서 도입된 noise $\epsilon_t$가 저장된다. 다음으로, 앞서 설명한 reverse diffusion process는 각 step에서 저장된 $\epsilon_t$ 값으로 denoise한다. 전체 denoising process에서 입력 조건이 변경되지 않으면 이미지 $y$가 충실하게 재구성된다.
이미지의 세밀한 콘텐츠 디테일을 유지하면서 새로운 스타일을 전송할 수 있는 가능성을 제공하기 위해 매개변수 $\lambda \in [1, T]$가 도입되었다. 처음 $\lambda$개의 denoising step에서 U-Net은 $y$의 style 및 semantic descriptor에 대한 cross-attention으로 컨디셔닝되는 반면, 마지막 $T - \lambda$개의 step에서는 스타일 조건이 $s$에서 인코딩된 스타일인 $m_s$로 전환된다.
따라서 $\lambda$를 $T$에 가깝게 설정하면 구조적으로 $y$와 더 유사한 이미지가 생성되는 반면, $\lambda$ 값이 낮을수록 $s$와 더 스타일이 유사한 이미지가 생성된다.
Colour Distribution Post-Processing
Diffusion을 통해 레퍼런스 이미지 $s$의 스타일을 지각적으로 일치시킬 때의 문제는 $y$에 대한 이미지 fidelity가 높음에도 색상 분포가 일치하지 않는다는 것이다. 저자들은 ARF에서 영감을 받은 추가 후처리 단계를 통해 이 문제를 해결한다. 이 선택적 단계에서는 생성된 이미지가 스타일 이미지의 평균 및 공분산과 일치하도록 수정되어 색상 분포를 이동한다.
Results
1. Comparison to Baselines
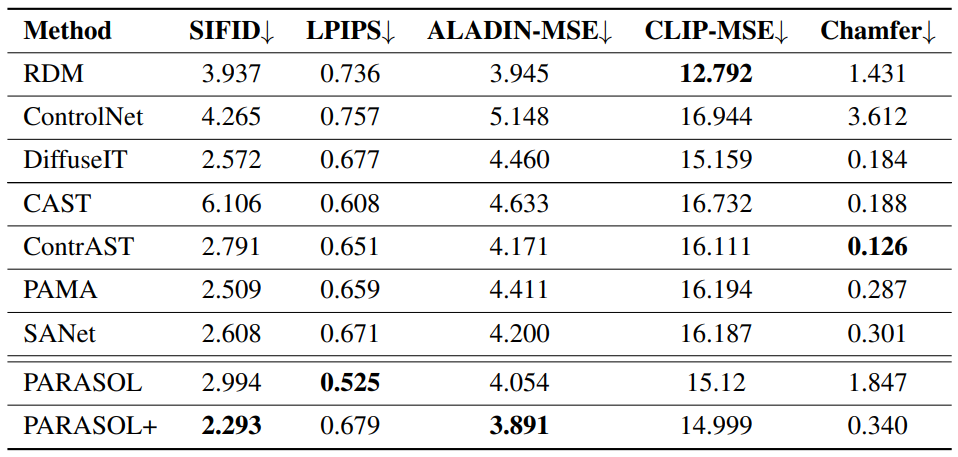
다음은 스타일(SIFID, ALADIN-MSE, Chamfer)과 콘텐츠(LPIPS, CLIPMSE)에 대한 정량적 평가를 비교한 표이다.
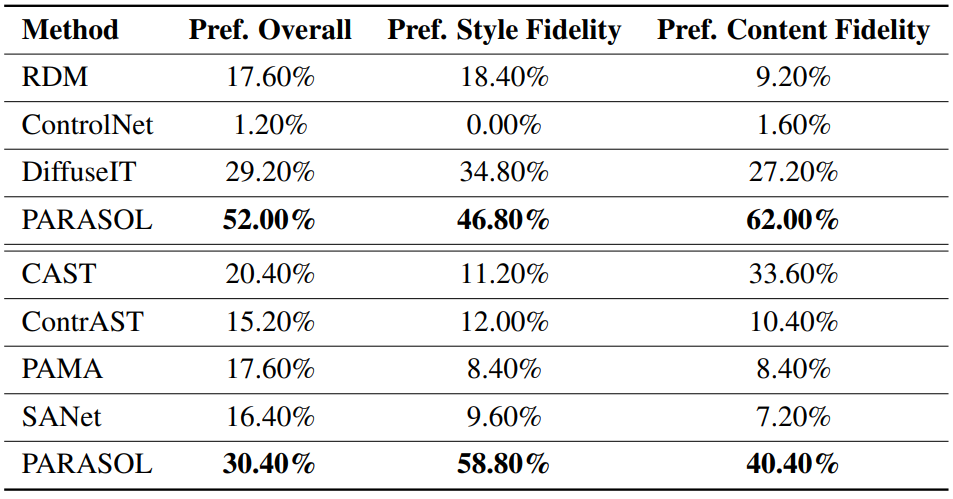
다음은 AMT 실험을 기반으로 본 논문의 방법과 다른 baseline들을 비교한 평가 결과이다.
다음은 RDM, DDiffuseIT, CAST, PARASOL의 대표 예시들이다.

2. Ablation Study
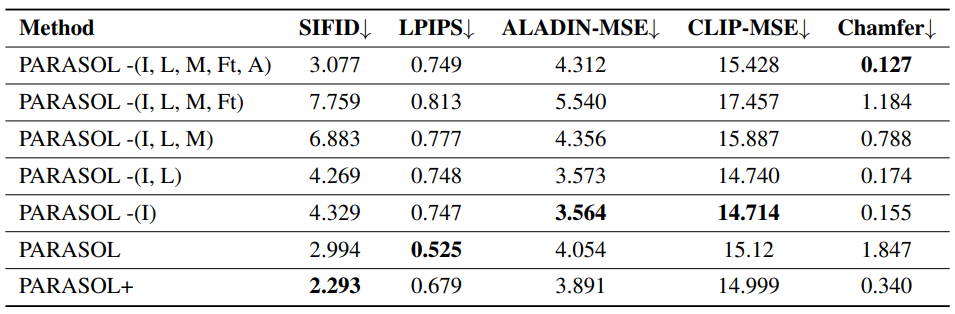
다음은 본 논문의 최종 모델의 다양한 ablation에 대한 정량적 평가 결과이다.
다음은 다양한 ablation의 합성 이미지들이다.

3. Controllability Experiments
Disentangled Style and Content
다음은 $\lambda$의 영향을 나타낸 예시이다.

10가지 다른 값의 $\lambda$를 사용하여 동일한 스타일 및 콘텐츠 정보에서 이미지를 합성한다. $\lambda$ 값이 높을수록 입력에 대한 보다 충실한 구조를 보장하는 반면 값이 낮을수록 스타일 전송이 더욱 촉진된다.
다음은 $g_s$와 $g_y$의 영향을 나타낸 예시이다.

첫 번째 행은 $g_y$는 상수이고 $g_s$는 증가하여 입력 스타일 정보의 영향이 더 많이 나타난다. 두 번째 행은 $g_s$는 상수이고 $g_y$는 증가하여 컨디셔닝 콘텐츠 cue에서 더 눈에 띄는 semantic 영향을 얻는다.
다음은 $\lambda$와 $g_s$의 영향을 나타낸 예시이다.
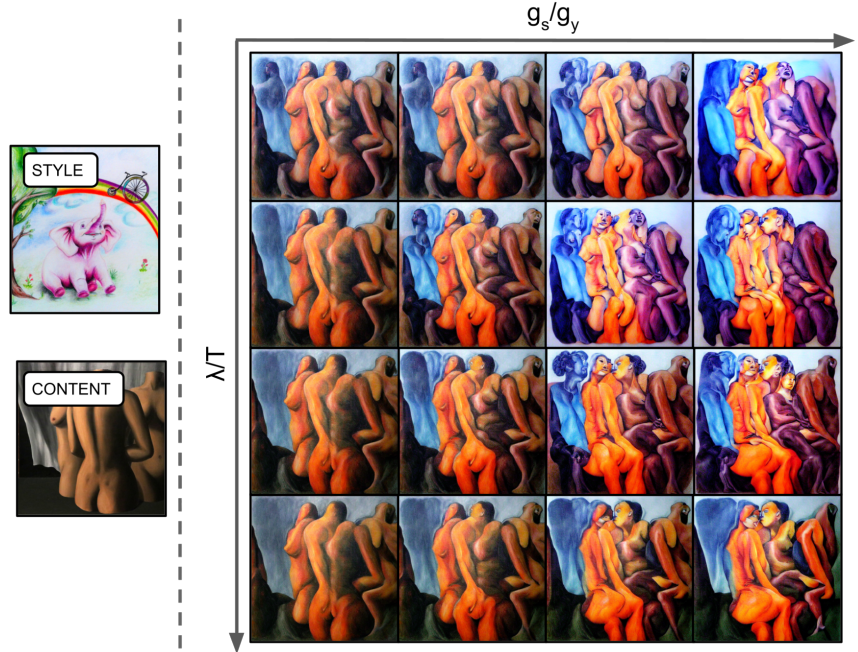
위로 갈수록 (낮은 $\lambda$)은 더 창의적인 구조를 보여준다. 오른쪽으로 갈수록 (높은 $g_s$)은 고도로 stylize된다. 왼쪽 아래 모서리(높은 $\lambda$, 낮은 $g_s$)는 스타일이 지정되지 않은 콘텐츠 입력에 가장 가깝다.
Content and Style Interpolation
다음은 스타일과 콘텐츠 interpolation의 예시로, 2개의 스타일과 2개의 콘텐츠 이미지를 interpolate하여 이미지를 생성하였다.

다음은 스타일과 콘텐츠에 대한 AMT user evaluation 결과이다.

Textual Captions as Conditioning Inputs
다음은 두 modality에 대한 텍스트 프롬프트에서 생성된 이미지이다.

Content Diversity with Consistent Semantics
다음은 세분화된 콘텐츠의 다양성을 보여주는 예시이다.

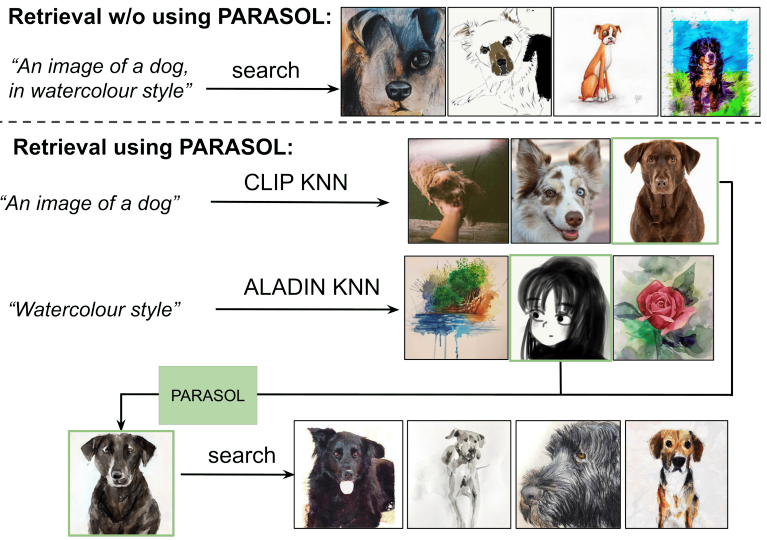
Generative Visual Search
다음은 generative search의 예시이다.
Limitations

Modality별 인코더를 사용하면 속성 disentanglement와 parametric control 측면에서 여러 가지 이점을 제공하여 Interpolation과 검색이 가능하다. 그러나 제공하는 표현이 항상 완전히 disentangle된 것은 아니며 때로는 새 이미지를 생성할 때 아티팩트와 원치 않는 결과가 생성된다 (위 그림의 (c,d)). 또 다른 제한점은 위 그림의 (a,b)에 묘사되어 있다. 도전적인 스타일이나 콘텐츠(ex: 얼굴)가 PARASOL에 제공될 때 콘텐츠의 특정 구조에 대한 성공적인 스타일 전송이 항상 보장될 수는 없다.