[논문리뷰] PaperBanana: Automating Academic Illustration for AI Scientists
arXiv 2026. [Paper] [Page] [Github]
Dawei Zhu, Rui Meng, Yale Song, Xiyu Wei, Sujian Li, Tomas Pfister, Jinsung Yoon
Peking University | Google Cloud AI Research
30 Jan 2026
Introduction
본 논문에서는 고품질 학술 일러스트레이션 제작을 자동화하는 에이전트 기반 프레임워크인 PaperBanana를 소개한다. Methodology 설명과 다이어그램 캡션을 입력으로 받으면, PaperBanana는 SOTA VLM과 이미지 생성 모델으로 구동되는 특수 에이전트들을 조율하여 참조 사례를 검색하고, 콘텐츠 및 스타일 관련 상세 계획을 수립하고, 이미지를 렌더링하고, 자체 비판을 통해 반복적으로 개선한다. 이러한 레퍼런스 기반 협업 워크플로를 통해 시스템은 학술 일러스트레이션에 필요한 논리적 구성과 스타일 규범을 효과적으로 습득할 수 있다. Methodology 다이어그램을 넘어 통계 그래프까지 확장 가능한 PaperBanana 프레임워크는 과학 시각화를 위한 포괄적인 솔루션을 제공하며 뛰어난 활용성을 보여준다.
본 프레임워크를 엄격하게 평가하고 자동화된 학술 일러스트레이션에 대한 전용 벤치마크가 부재한 문제를 해결하기 위해, methodology 다이어그램 생성에 대한 종합적인 벤치마크인 PaperBananaBench를 도입하였다. 이 벤치마크는 NeurIPS 2025 논문에서 선별한 292개의 테스트 케이스와 292개의 레퍼런스 케이스로 구성되어 있으며, 다양한 연구 주제와 일러스트레이션 스타일을 포괄한다. 생성 품질을 평가하기 위해, VLM-as-a-Judge 방식을 사용하여 네 가지 차원(충실도, 간결성, 가독성, 미적 요소)에서 사람이 직접 그린 일러스트레이션과 비교하여 레퍼런스 기반 점수를 매기고, 사람의 판단과의 상관관계를 통해 신뢰성을 검증했다.
Task Formulation
- 입력
- $S$: 핵심 정보를 담고 있는 원본 컨텍스트
- $C$: 원하는 그림의 범위와 초점을 명시하는 의도
- (선택) \(\mathcal{E} = \{E_n\}_{n=1}^N\): 참조 예제 세트 ($E_n = (S_n, C_n, I_n)$). \(\mathcal{E} = \varnothing\)이 default (zero-shot 생성).
- 목표
- $C$를 충족하면서 $S$를 충실하게 시각화하는 이미지 $I$를 생성
Methodology
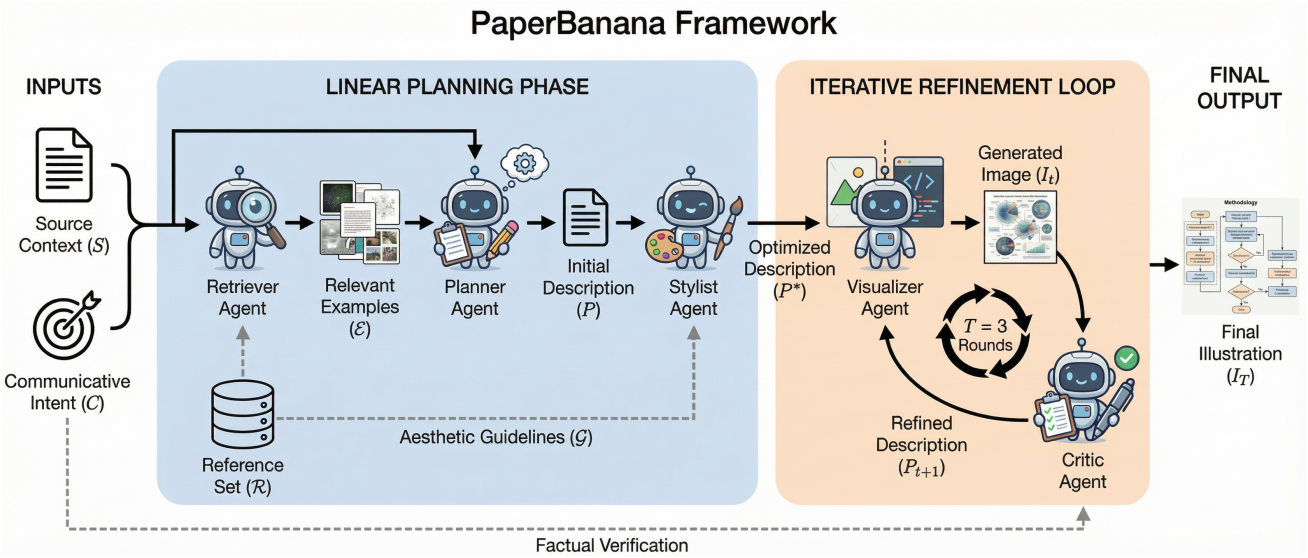
Retriever Agent
주어진 소스 컨텍스트 $S$와 사용자 의도 $C$를 기반으로, Retriever 에이전트는 고정된 레퍼런스 집합 $\mathcal{R}$에서 다른 에이전트를 가이드하기 위해 $N$개의 가장 관련성이 높은 예제 \(\mathcal{E} = \{E_n\}_{n=1}^N \subset \mathcal{R}\)를 식별한다. 각 예제 $E_i \in \mathcal{R}$은 $(S_i, C_i, I_i)$의 세 쌍으로 구성된다. VLM의 추론 능력을 활용하기 위해, 본 연구에서는 VLM이 후보 메타데이터에 대한 선택을 수행하는 생성적 검색 방식을 채택하였다.
\[\begin{equation} \mathcal{E} = \textrm{VLM}_\textrm{Ret} (S, C, \{(S_i, C_i)\}_{E_i \in \mathcal{R}}) \end{equation}\]구체적으로, VLM은 연구 영역과 다이어그램 유형을 모두 고려하여 후보의 순위를 매기도록 지시받으며, 주제 유사성보다 시각적 구조를 우선시한다. 검색기는 현재 요구 사항과 가장 잘 일치하는 컨텍스트 $(S_i, C_i)$를 갖는 레퍼런스 그림 $I_i$를 명시적으로 추론하여 선택함으로써 구조적 논리와 시각적 스타일 모두에 대한 구체적인 기반을 제공한다.
Planner Agent
Planner 에이전트는 시스템의 인지적 핵심 역할을 한다. 입력으로는 소스 컨텍스트 $S$, 사용자 의도 $C$, 그리고 검색된 예시 $\mathcal{E}$를 받는다. $\mathcal{E}$에 포함된 예시들을 통해 in-context learning을 수행함으로써, Planner는 $S$에 있는 비정형 또는 정형 데이터를 대상 예시에 대한 포괄적이고 상세한 텍스트 설명 $P$로 변환한다.
\[\begin{equation} P = \textrm{VLM}_\textrm{plan} (S, C, \{(S_i, C_i, I_i)\}_{E_i \in \mathcal{E}}) \end{equation}\]Stylist Agent
현대 학술 원고의 미적 기준을 준수하도록 하기 위해 Stylist 에이전트는 디자인 컨설턴트 역할을 수행한다. 주요 과제는 포괄적인 “학술 스타일”을 정의하는 것이다. 이를 해결하기 위해 스타일리스트는 전체 레퍼런스 모음 $\mathcal{R}$을 탐색하여 색상 팔레트, 도형 및 컨테이너, 선 및 화살표, 레이아웃 및 구성, 타이포그래피 및 아이콘과 같은 주요 요소를 포괄하는 미적 가이드라인 $\mathcal{G}$를 자동으로 생성한다. 이 가이드라인을 바탕으로 Stylist는 각 초기 설명 $P$을 스타일적으로 최적화된 버전 $P^\ast$로 다듬는다.
\[\begin{equation} P^\ast = \textrm{VLM}_\textrm{style} (P, \mathcal{G}) \end{equation}\]이를 통해 최종 일러스트레이션은 정확할 뿐만 아니라 시각적으로도 전문적인 모습을 갖추게 된다.
Visualizer Agent
Visualizer 에이전트는 $P^\ast$를 받아 Critic 에이전트와 협력하여 학술 일러스트레이션을 렌더링하고 그 품질을 반복적으로 개선한다. Visualizer 에이전트는 이미지 생성 모델을 활용하여 텍스트 설명을 시각적 출력으로 변환한다. 각 iteration $t$에서, 설명 $P_t$를 받으면 Visualizer는 이미지 $I_t$를 생성한다.
\[\begin{equation} I_t = \textrm{Image-Gen}(P_t), \quad \textrm{where} \quad P_0 = P^\ast \end{equation}\]Critic Agent
Critic 에이전트는 생성된 이미지 $I_t$를 면밀히 검토하고 정제된 설명 $P_{t+1}$을 Visualizer에 제공함으로써 Visualizer와 closed-loop 정제 메커니즘을 형성한다. Critic은 $t$번째 iteration에서 생성된 이미지 $I_t$를 받으면 원본 소스 컨텍스트 $(S, C)$와 비교하여 사실 불일치, 시각적 오류 또는 개선 영역을 식별한다. 그런 다음 식별된 문제를 해결하는 맞춤형 피드백을 제공하고 정제된 설명 $P_{t+1}$을 생성한다.
\[\begin{equation} P_{t+1} = \textrm{VLM}_\textrm{critic} (I_t, S, C, P_t) \end{equation}\]이렇게 수정된 설명은 Visualizer로 다시 전달되어 재생성된다. Visualizer-Critic 루프는 $T = 3$회 반복되며, 최종 출력은 $I = I_T$가 된다.
통계 plot으로의 확장
이 프레임워크는 Visualizer와 Critic 에이전트를 조정하여 통계 plot을 지원한다. 수치적 정확도를 위해 Visualizer는 설명 $P_t$를 실행 가능한 Python Matplotlib 코드로 변환한다.
\[\begin{equation} I_t = \textrm{VLM}_\textrm{code}(P_t) \end{equation}\]Critic은 렌더링된 plot을 평가하고 부정확하거나 불완전한 부분을 수정하여 정제된 설명 $P_{t+1}$을 생성한다. 동일하게 $T = 3$ 라운드의 반복적인 정제 과정이 적용된다. 정확도를 위해 코드 기반 접근 방식을 우선시한다.
Benchmark Construction
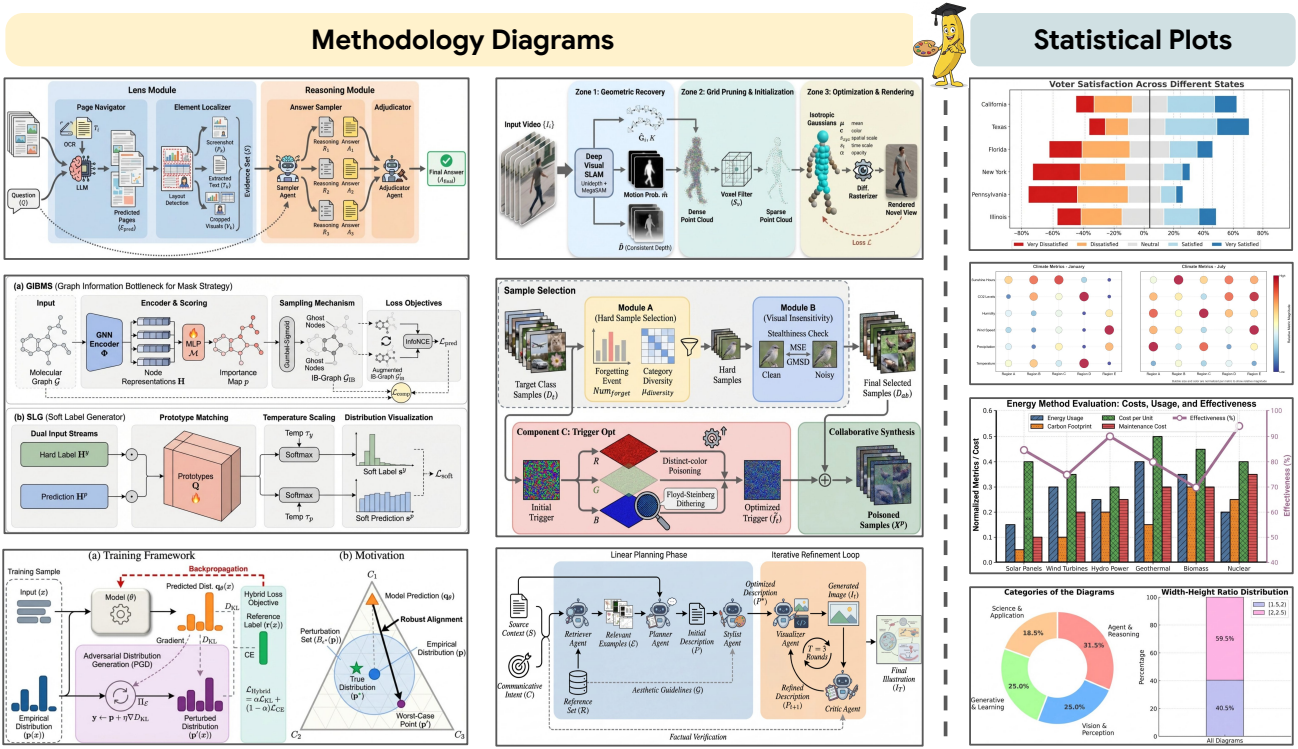
벤치마크 부족으로 인해 자동화된 다이어그램 생성에 대한 엄밀한 평가가 어렵다. 본 논문에서는 NeurIPS 2025의 methodology 다이어그램을 기반으로 구축된 전용 벤치마크인 PaperBananaBench를 통해 이러한 문제를 해결하고자 하였다. PaperBananaBench는 현대 AI 논문의 정교한 미적 감각과 다양한 논리적 구성을 반영한다.
데이터 큐레이션
- NeurIPS 2025에서 랜덤하게 2,000개의 논문을 샘플링 후 PDF 파일들을 검색
- MinerU 툴킷으로 methodology 섹션의 텍스트와 다이어그램 및 캡션을 추출
- 부적절한 논문 필터링
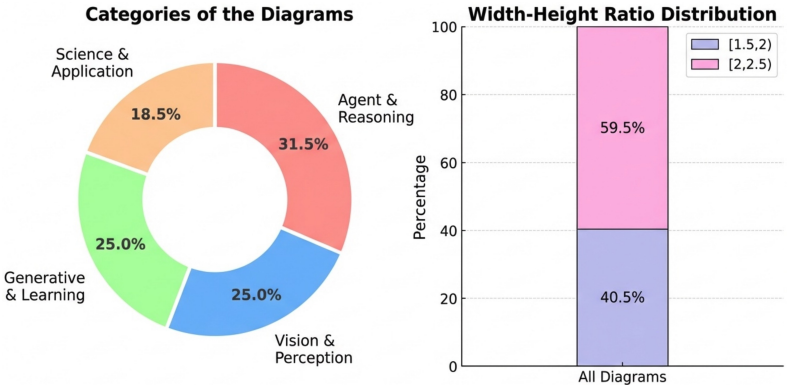
- Methodology 다이어그램이 없는 논문 필터링 (2,000 $\rightarrow$ 1,359)
- 다이어그램의 종횡비 $w:h$가 $[1.5, 2.5]$을 벗어나는 논문 필터링 (1,359 $\rightarrow$ 610)
- Gemini-3-Pro를 사용하여 다이어그램을 4 종류의 카테고리로 분류
- Agent & Reasoning
- Vision & Perception
- Generative & Learning
- Science & Applications
- 인간이 직접 검토 (610 $\rightarrow$ 584)
- 292개는 평가용, 292개는 레퍼런스 집합 (in-context learning)
평가 프로토콜
본 논문에서는 VLM-as-a-Judge를 활용하여 방법론 다이어그램과 통계 그래프의 품질을 평가하였다. 시각적 디자인 평가에 내재된 주관성을 고려하여, 모델이 생성한 다이어그램과 사람이 직접 그린 다이어그램을 비교하는 참조 비교 방식을 채택하여 각 평가 기준을 더 잘 충족하는 다이어그램을 결정한다.
평가 항목은 다음과 같다.
- 충실도 (Faithfulness): 소스 컨텍스트 $S$ 및 사용자 의도 $C$와의 정렬도
- 간결성 (Conciseness): 시각적 혼란 없이 핵심 정보에 집중했나를 평가
- 가독성 (Readability): 레이아웃이 이해하기 쉬운가, 텍스트가 읽기 쉬운가, 과도한 줄바꿈은 없는가 등을 평가
- 미적 요소 (Aesthetics): 학술 원고의 스타일 규범 준수 여부를 평가
참조 기반 점수 산정 방식
각 평가 항목에 대해 VLM은 주어진 컨텍스트와 캡션을 바탕으로 모델이 생성한 다이어그램을 사람이 작성한 레퍼런스 이미지와 비교한다. 상대적인 품질을 기준으로 모델 승, 사람 승, 무승부를 판정하고, 각각 100점, 0점, 50점의 점수로 환산한다. 점수를 종합하여 전체 지표를 산출하기 위해, 정보 시각화의 핵심 원칙인 “show the truth”를 따른다. 핵심 평가 항목으로 충실도와 가독성을, 부차 평가 항목으로 간결성과 미적 요소를 사용한다. 심 평가 항목에서 확실한 승자가 나올 경우 (둘 모두 승 or 하나는 승, 하나는 무승부), 해당 차원의 승자가 최종 승자가 된다. 무승부일 경우 (ex. 하나씩 승자 or 둘 모두 무승부), 부차 평가 항목에도 동일한 규칙을 적용한다. 이러한 계층적 접근 방식을 통해 콘텐츠 충실도와 명확성이 부차 평가 항목보다 우선시되도록 한다.
Experiments
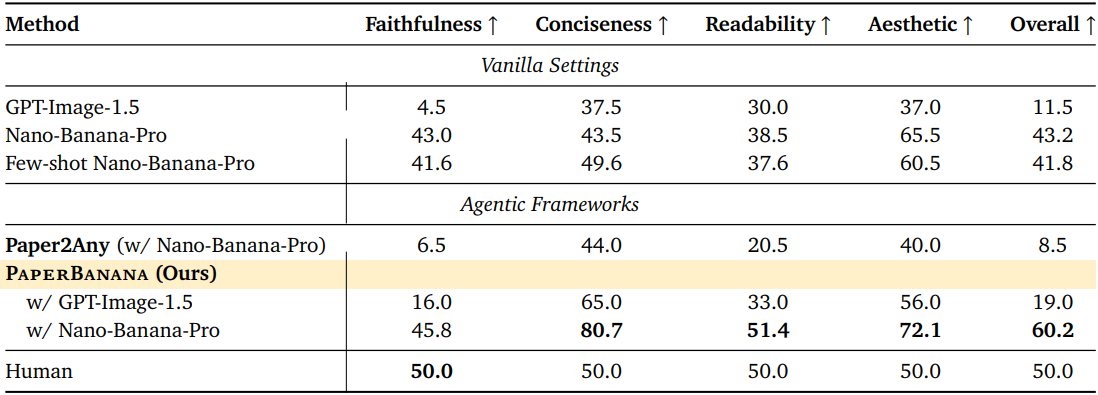
1. Main Results
다음은 PaperBananaBench에서의 주요 결과이다.
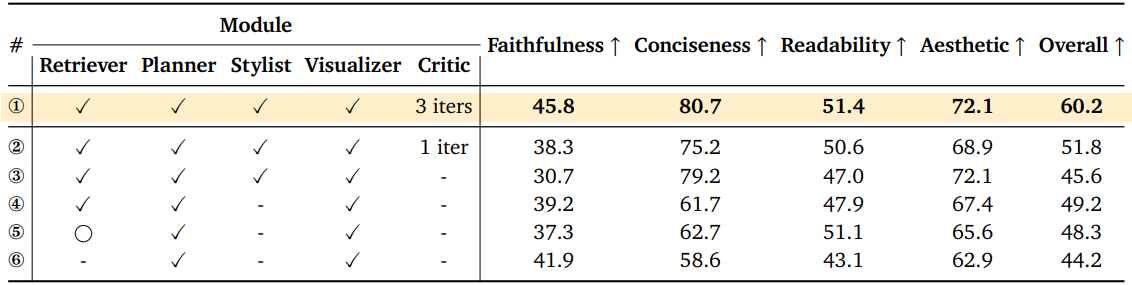
2. Ablation Study
다음은 ablation study 결과이다.
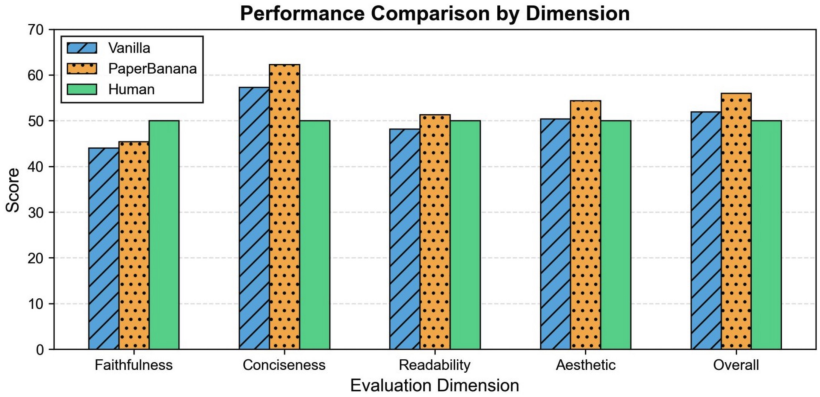
3. PaperBanana for Statistical Plots Generation
다음은 통계 plot 생성에 대하여 Gemini-3-Pro와 비교한 결과이다.
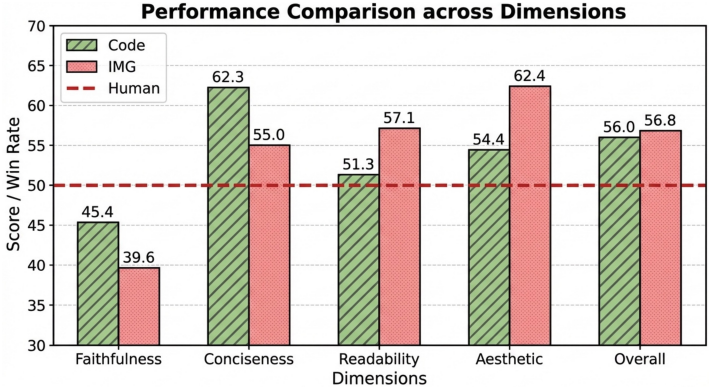
4. Discussion
다음은 통계 plot에 대하여 코드 기반 방법과 이미지 기반 방법을 비교한 결과이다.
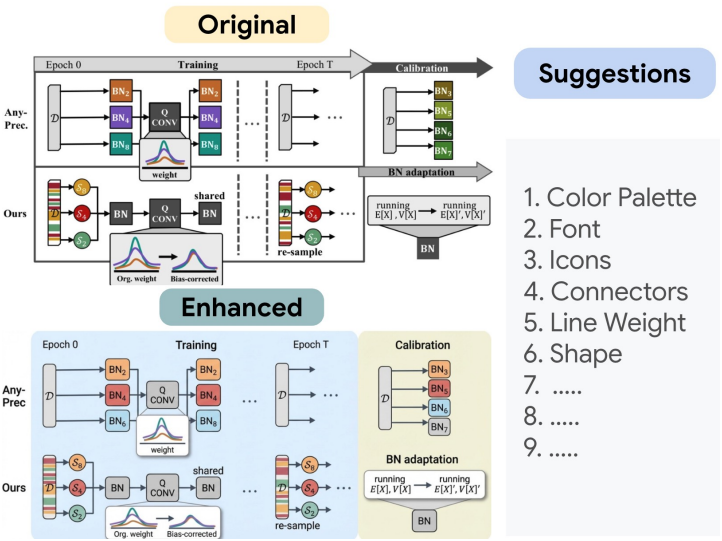
다음은 사람이 그린 다이어그램을 PaperBanana로 향상시킨 예시이다.