[논문리뷰] PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360°
CVPR 2023. [Paper] [Page] [Github]
Sizhe An, Hongyi Xu, Yichun Shi, Guoxian Song, Umit Ogras, Linjie Luo
ByteDance Inc. | University of Wisconsin-Madison
23 Mar 2023

Introduction
사실적인 인물 이미지 합성은 다양한 다운스트림 애플리케이션을 통해 컴퓨터 비전 및 그래픽 분야에서 지속적으로 초점을 맞춰왔다. GAN의 최근 발전으로 실제 사진과 구별할 수 없을 만큼 놀라울 정도로 높은 이미지 합성 품질이 입증되었다. 그러나 현대의 생성적 접근 방식은 기본 3D 장면을 모델링하지 않고 2D CNN에서 작동한다. 따라서 다양한 포즈의 머리 이미지를 합성할 때 3D 일관성을 엄격하게 적용할 수 없다.
다양한 모양과 외형을 가진 3D 머리를 생성하려면 기존 접근 방식에서는 대규모 3D 스캔 컬렉션에서 학습된 parametric textured mesh model이 필요하다. 그러나 렌더링된 이미지에는 미세한 디테일이 부족하고 품질과 표현력이 제한되어 있다. Differentiable rendering과 암시적 neural 표현의 출현으로 보다 사실적인 3D-aware 얼굴 이미지를 생성하기 위한 조건부 생성 모델이 개발되었다. 그러나 이러한 접근 방식에는 일반적으로 멀티뷰 이미지 또는 3D 스캔 supervision이 필요하다. 이는 일반적으로 통제된 환경에서 캡처되므로 획득하기 어렵고 외형 분포가 제한적이다.
3D-aware 생성 모델은 최근 3D 장면 모델링의 암시적 neural 표현과 이미지 합성을 위한 GAN의 통합에 힘입어 빠른 발전을 보였다. 그중에서도 중요한 3D GAN인 EG3D는 실제 단일 뷰 이미지 컬렉션에서만 학습된 일관된 뷰에 대한 이미지 합성에서 놀라운 품질을 보여주었다. 그러나 이러한 3D GAN 접근 방식은 여전히 정면 뷰에서의 합성으로 제한된다.
본 논문에서는 실제 비정형 이미지만으로 학습된 360도 고품질 full 3D 머리 합성을 위한 새로운 3D-aware GAN인 PanoHead를 제안한다. 본 논문의 모델은 모든 각도에서 볼 수 있는 일관된 3D 머리를 합성할 수 있으며 이는 많은 몰입형 상호 작용 시나리오에서 바람직하다. 본 논문의 방법은 360도에서 완전한 3D 머리 합성을 달성한 최초의 3D GAN 접근 방식이다.
EG3D와 같은 3D GAN 프레임워크를 전체 3D 머리 합성으로 확장하면 몇 가지 중요한 기술적 과제가 발생한다. 첫째, 많은 3D GAN은 전경과 배경을 분리할 수 없어 2.5D 머리 형상을 유도한다. 일반적으로 벽 구조로 구성된 배경은 생성된 머리와 3D로 얽혀 있어 큰 포즈에서 렌더링할 수 없다. 2차원 영상 분할에 대한 사전 지식을 추출하여 3차원 공간에서 전경 머리의 분해를 공동 학습하는 전경 인식 삼중 discriminator를 도입한다.
둘째, tri-plane과 같은 현재의 하이브리드 3D 장면 표현은 작고 효율적이면서도 360도 카메라 포즈에 대한 강력한 projection 모호성을 도입하여 뒷머리에 ‘반사된 얼굴’이 생성된다. 이 문제를 해결하기 위해 삼면 표현의 효율성을 유지하면서 정면 feature를 뒷머리와 분리하는 새로운 3D 삼중 그리드 볼륨 표현을 제시한다.
마지막으로, 3D GAN 학습을 위해 뒷머리 이미지의 잘 추정된 카메라 외부 요소를 얻는 것은 매우 어렵다. 더욱이, 이러한 이미지와 감지 가능한 얼굴 랜드마크가 있는 정면 이미지 사이에는 이미지 정렬 차이가 존재한다. 정렬 차이로 인해 외형에 잡음이 많고 머리 형상이 매력적이지 않다. 따라서 본 논문은 모든 뷰의 이미지를 일관되게 견고하게 정렬하는 새로운 2단계 정렬 방식을 제안하였다. 이 단계는 3D GAN의 학습 난이도를 크게 줄인다. 특히, 뒷머리 이미지의 정렬 드리프트를 수용하기 위해 렌더링 카메라의 위치를 동적으로 조정하는 카메라 자체 적응 모듈을 제안하였다.
본 논문의 프레임워크는 임의의 뷰에서 실제 전체 머리 이미지에 적응할 수 있는 3D GAN의 능력을 크게 향상시킨다. 본 논문의 3D GAN은 충실도가 높은 360도 RGB 이미지와 형상을 생성할 뿐만 아니라 SOTA 방법보다 더 나은 정량적 메트릭을 달성하였다. PanoHead는 단일 단안 이미지에서 강력한 3D 전체 머리 재구성을 선보이며, 쉽게 액세스할 수 있는 3D 인물 사진 생성이 가능하다.
Methodology
1. PanoHead Overview
본 논문은 현실적이고 일관된 뷰의 전체 머리 이미지를 합성하기 위해 효율성과 합성 품질로 인해 SOTA 3D-aware GAN, 즉 EG3D를 기반으로 PanoHead를 구축했다. 특히 EG3D는 StyleGAN2 backbone을 활용하여 3개의 2D feature 평면이 있는 3D 장면을 나타내는 tri-plane 표현을 출력한다. 원하는 카메라 포즈 $c_\textrm{cam}$이 주어지면 tri-plane이 MLP 네트워크로 디코딩되고 볼륨이 feature 이미지로 렌더링된 다음 super-resolution 모듈을 통해 더 높은 해상도의 RGB 이미지 $I^{+}$를 합성한다. 저해상도 이미지와 고해상도 이미지는 모두 이중 discriminator $D$에 의해 공동으로 최적화된다.
EG3D의 정면 얼굴 생성의 성공에도 불구하고 다음과 같은 이유로 360도 실제 전체 머리 이미지에 적응하는 것이 훨씬 더 어렵다.
- 전경-배경 얽힘으로 인해 큰 포즈 렌더링이 금지된다.
- Tri-plane 표현의 강한 inductive bias로 인해 뒷머리에 얼굴 아티팩트가 미러링된다.
- 잡음이 많은 카메라 레이블과 뒷머리 이미지의 일관되지 않은 cropping이 발생한다.
이러한 문제를 해결하기 위해 전경과 배경을 분리하기 위한 배경 generator와 삼중 discriminator, StyleGAN backbone과 여전히 호환되면서 효율적이면서도 표현력이 풍부한 삼중 그리드 표현, 학습 중에 렌더링 카메라를 동적으로 조정하는 자체 적응 모듈을 갖춘 2단계 이미지 정렬 방식을 도입한다. 모델의 전체 파이프라인은 아래 그림에 나와 있다.
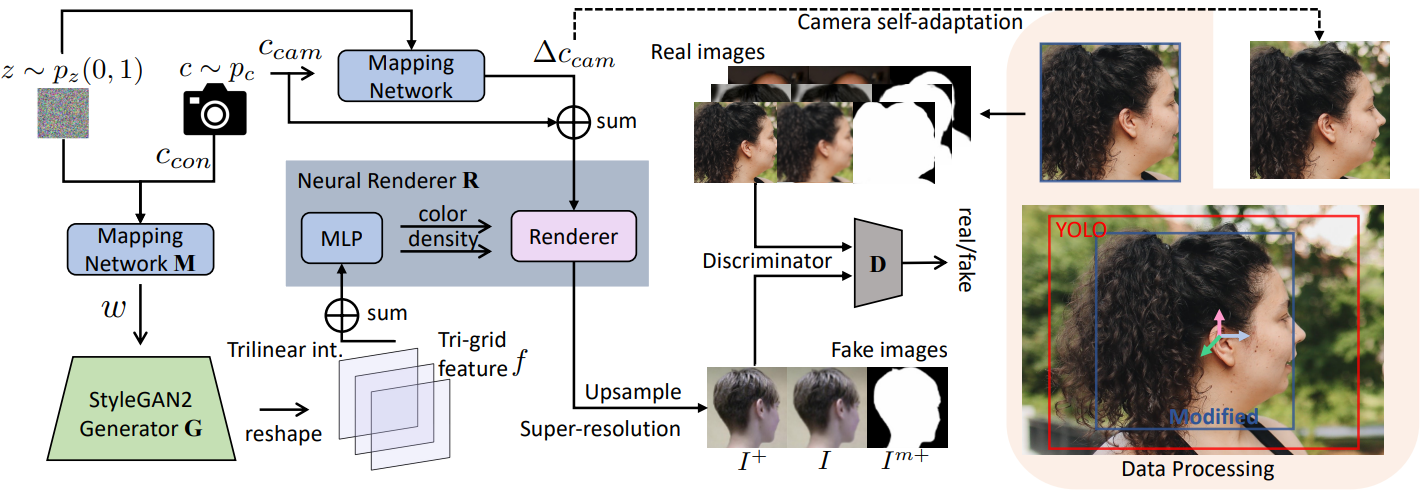
2. Foreground-Aware Tri-Discrimination

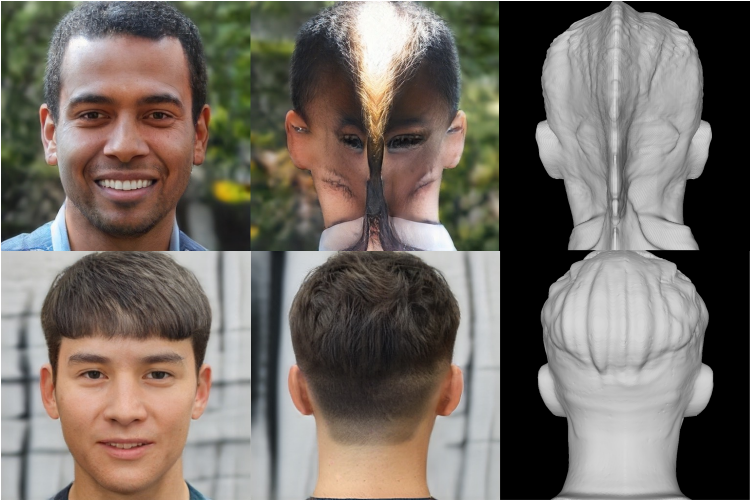
EG3D와 같은 SOTA 3D-aware GAN의 일반적인 문제점은 합성 이미지의 배경과 전경이 얽혀 있다는 것이다. 매우 상세한 형상 재구성에 관계없이 FFHQ와 같은 실제 RGB 이미지 컬렉션에서 3D GAN을 직접 학습하면 위 그림과 같이 2.5D 얼굴이 생성된다. 머리 측면과 후면의 이미지 supervision을 강화하면 합리적인 뒷머리 모양으로 전체 머리 형상을 구축하는 데 도움이 된다. 그러나 tri-plane 표현 자체가 전경과 배경이 분리되어 표현되도록 설계되지 않았기 때문에 문제가 해결되지 않는다.
전경과 배경을 분리하기 위해 먼저 추가 StyleGAN2 네트워크를 도입하여 feature 이미지 $I^r$과 동일한 해상도로 2D 배경을 생성한다. 볼륨 렌더링 중에 전경 마스크 $I^m$은 다음을 통해 얻을 수 있다.
\[\begin{equation} I^r (r) = \int_0^\infty w(t) f(r(t)) dt, \quad I^m (r) = \int_0^\infty w(t) dt \\ w(t) = \exp (-\int_0^t \sigma (r(s)) ds) \sigma (r(t)) \end{equation}\]여기서 $r(t)$는 렌더링 카메라 중심에서 방출되는 광선을 나타낸다. 그런 다음 전경 마스크는 새로운 저해상도 이미지 $I^\textrm{gen}$을 구성하는 데 사용된다.
\[\begin{equation} I^\textrm{gen} = (1 - I^m) I^\textrm{bg} + I^r \end{equation}\]$I^\textrm{gen}$은 super-resolution 모듈에 입력된다. 배경 generator의 출력은 tri-plane generator와 super-resolution 모듈보다 훨씬 낮은 해상도를 갖기 때문에 계산 비용은 중요하지 않다.
Generator가 배경의 전경 콘텐츠를 합성하는 경향이 있으므로 단순히 배경 generator를 추가해도 전경에서 완전히 분리되지 않는다. 따라서 본 논문은 RGB 이미지와 함께 렌더링된 전경 마스크를 supervise하기 위한 새로운 전경 인식 삼중 discriminator를 제안한다. 구체적으로, 삼중 discriminator의 입력은 bilinear하게 업샘플링된 RGB 이미지 $I$, super-resolution RGB 이미지 $I^{+}$, 단일 채널의 업샘플링된 전경 마스크 $I^{m+}$로 구성된 7개 채널을 갖는다.

추가 마스크 채널을 사용하면 2D 분할 사전 지식을 neural radiance field의 밀도 분포로 역전파할 수 있다. 본 논문의 접근 방식은 구조화되지 않은 2D 이미지에서 3D 전체 머리 형상을 형성하는 데 있어 학습 어려움을 줄여 실제 형상과 다양한 배경으로 구성 가능한 전체 머리의 외관 합성을 가능하게 한다 (위 그림 참조).
3. Feature Disentanglement in Tri-Grid
EG3D에서 제안된 tri-plane 표현은 3D 생성을 위한 효율적인 표현을 제공한다. Neural radiance density와 볼륨 포인트의 모양은 3개의 축으로 된 직교 평면에 3D 좌표를 project하고 작은 MLP를 사용하여 bilinear하게 보간된 3개의 feature의 합을 디코딩하여 얻는다. 그러나 360도에서 전체 머리를 합성할 때 tri-plane의 표현력이 제한되고 mirroring-face 아티팩트가 발생한다. 문제는 학습 이미지의 카메라 분포가 불균형한 경우에도 나타난다.
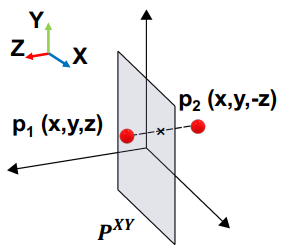
근본 원인은 2D 평면의 한 점이 다른 3D 점의 feature를 나타내야 하는 tri-plane projection에서 발생하는 inductive bias이다. 예를 들어, 위 그림에 표시된 것처럼 앞면의 점과 뒷머리의 점이 $XY$ 평면 $P^{XY}$ ($Z$ 축에 직교)의 동일한 점에 project된다. 다른 두 평면은 이론적으로 이러한 projection 모호성을 완화하기 위해 보완적인 정보를 제공해야 하지만 뒤에서 시각적 supervision이 적거나 뒷머리의 구조를 배우기 어려운 경우에는 그렇지 않다. Tri-plane은 여기서 mirroring-face 아티팩트라고 하는 후면 머리를 합성하기 위해 전면의 feature를 빌려오는 경향이 있다.
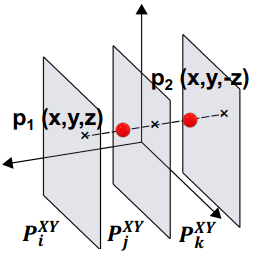
Tri-plane의 inductive bias를 줄이기 위해 tri-plane을 추가 깊이 차원으로 강화하여 더 높은 차원으로 끌어올린다. 이 강화된 버전을 tri-grid라고 부른다. $H \times W \times C$ 형태의 3개 평면을 갖는 대신, 각 tri-grid는 $D \times H \times W \times C$ 형태를 갖는다. 여깃 $D$는 깊이를 나타낸다. 예를 들어, $XY$ 평면에 공간 feature를 나타내기 위해 tri-grid는 $Z$축을 따라 균일하게 분포된 feature 평면 $P_i^{XY}, i = 1, \ldots, D$를 갖는다. 해당 좌표를 각 tri-grid에 project하고 tri-linear interpolation을 통해 해당 feature 벡터를 검색하여 3D 공간 지점을 쿼리한다. 따라서 깊이가 다른 두 점의 경우 동일한 projection 좌표를 공유하지만 해당 feature는 공유되지 않은 평면에서 보간될 가능성이 높다. Tri-grid는 앞면과 뒷면 머리의 feature 표현을 분리하여 mirroring-face 아티팩트를 크게 완화한다. 아래 그림은 tri-plane과 tri-grid ($D = 3$)의 이미지 합성 결과이다.
EG3D의 tri-plane과 유사하게 StyleGAN2 generator를 사용하여 tri-grid를 $3 \times D$ feature 평면으로 합성할 수 있다. 즉, EG3D backbone의 출력 채널 수를 $D$배 늘린다. 따라서 tri-plane은 $D = 1$인 tri-grid 표현으로 간주될 수 있다. Tri-grid의 깊이 $D$는 조정 가능하며 더 큰 $D$는 추가 계산 오버헤드를 희생하면서 더 많은 표현 능력을 제공한다. 경험적으로 저자들은 $D$의 작은 값 (ex. $D = 3$)이 3D 장면 표현으로서의 효율성을 유지하면서 feature 분리에 충분하다는 것을 발견했다.
4. Self-Adaptive Camera Alignment
360도에서 머리 전체를 적대적으로 학습하려면 훨씬 더 넓은 범위의 카메라 분포에서 나온 실제 이미지 표본이 필요하다. 본 논문의 3D-aware GAN은 널리 접근 가능한 2D 이미지로만 학습되지만 최고 품질의 학습의 핵심은 잘 추정된 카메라 파라미터로 레이블이 지정된 이미지 전반에 걸쳐 시각적 관찰을 정확하게 정렬하는 것이다. 얼굴 랜드마크를 기반으로 정면 얼굴 이미지 cropping과 정렬에 대해서는 모범 사례가 확립되었지만 GAN 학습을 위한 대형 이미지 전처리에 대해서는 연구된 적이 없다. 측면과 후면에서 촬영한 이미지에 대한 robust한 얼굴 랜드마크 감지 능력이 부족하기 때문에 카메라 추정과 이미지 cropping 모두 더 이상 간단하지 않다.
이 문제를 해결하기 위해 본 논문은 새로운 2단계 처리를 제안하였다. 첫 번째 단계에서는 감지 가능한 얼굴 랜드마크가 있는 이미지의 경우 SOTA face pose estimator 3DDFA를 사용하여 얼굴을 비슷한 크기로 조정하고 머리 중앙에 정렬하는 표준 처리를 계속 채택한다. 큰 카메라 포즈가 포함된 나머지 이미지의 경우 대략 추정된 카메라 포즈를 제공하는 head pose estimator WHENet과 감지된 머리를 중심으로 bounding box가 있는 human detector YOLO를 사용한다. 일관된 머리 크기와 중심으로 이미지를 자르기 위해 전면 이미지 batch에 YOLO와 3DDFA를 모두 적용하고, 여기서 상수 오프셋을 사용하여 YOLO 머리 중심의 스케일과와 평행 이동을 조정한다. 이 접근 방식을 사용하면 레이블이 지정된 카메라 파라미터를 사용하여 모든 머리 이미지를 대체로 일관된 정렬로 전처리할 수 있다.

다양한 헤어스타일이 존재하기 때문에 뒷머리 이미지 정렬에 여전히 불일치가 있어 네트워크가 전체 머리 형상과 외형를 해석하는 데 상당한 학습 어려움을 초래한다 (위 그림 참조). 따라서 각 학습 이미지에 대한 volume
rendering frustum의 변환을 fine-tuning하기 위한 자체 적응형 카메라 정렬 방식을 제안한다. 특히, 3D-aware GAN은 각 이미지를 형상 및 외관의 3D 장면 정보를 포함하는 latent code $z$와 연결하며, 이는 $c_\textrm{cam}$의 뷰에서 합성될 수 있다. $c_\textrm{cam}$은 학습 이미지의 이미지 콘텐츠와 잘 맞지 않을 수 있다. 그러므로 3D GAN이 합리적인 전체 머리 형상을 파악하기가 어렵다.

따라서 적대적 학습과 함께 $(z, c_\textrm{cam})$에서 매핑된 잔여 카메라 변환 $\Delta c_\textrm{cam}$을 공동 학습한다. $\Delta c_\textrm{cam}$의 크기는 L2-norm으로 정규화된다. 기본적으로 네트워크는 다양한 시각적 관찰에 걸쳐 세련된 대응을 통해 이미지 정렬을 동적으로 자체 조정한다. 이는 다양한 카메라에서 뷰 일관성이 있는 이미지를 합성할 수 있는 3D-aware GAN의 특성 덕분에 가능하다. 2단계 정렬을 통해 실제 모양과 외형을 갖춘 360도의 뷰 일관성이 있는 머리 합성이 가능하며, 널리 분산된 카메라 포즈, 스타일, 구조가 포함된 다양한 머리 이미지로부터 학습할 수 있다.
Experiments
- 데이터셋: FFHQ-F (FFHQ + K-hairstyle + 자체 large-pose 머리 이미지 컬렉션)
1. Qualitative Comparisons
다음은 다른 baseline들과 정성적으로 비교한 것이다.

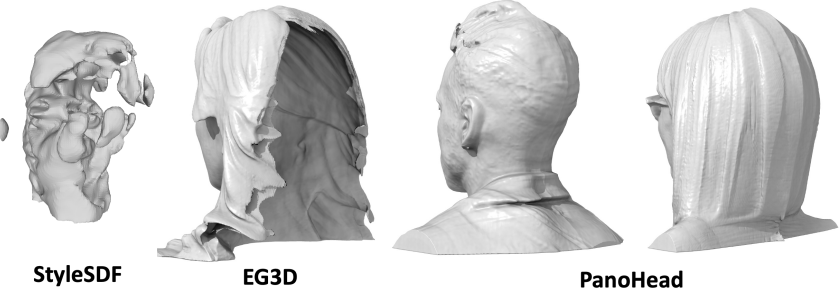
다음은 생성된 머리 형상을 비교한 것이다.
2. Quantitative Results
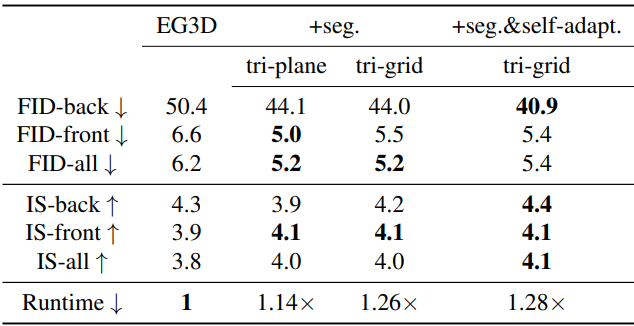
다음은 모든 baseline들과 정량적으로 비교한 표이다.

다음은 여러 구성 요소에 대한 ablation 결과이다. +seg는 전경 인식 삼중 discrimination을 의미하며, +self-adapt는 카메라 자체 적응 방식을 의미한다.
3. Single-view GAN Inversion
다음은 여러 카메라 포즈에 대한 단일 뷰 복원 결과이다. 왼쪽부터 타겟 이미지, GAN inversion으로 project한 RGB 이미지와 재구성된 3D 형상, 랜덤 카메라 포즈에서 렌더링된 이미지들이다.

Limitations
- 여전히 치아 부분에 사소한 아티팩트가 포함되어 있다.
- EG3D와 마찬가지로 깜박이는 텍스처 문제가 존재한다. Backbone을 StyleGAN3로 전환하면 고주파수 디테일을 보존하는 데 도움이 된다.
- 더 세밀한 고주파 기하학적 디테일이 부족하다. (ex. 머리카락 끝)
- 여전히 어느 정도 데이터 편향이 발생한다.