[논문리뷰] Palette: Image-to-Image Diffusion Models
SIGGRAPH 2022. [Paper] [Page]
Chitwan Saharia, William Chan, Huiwen Chang, Chris A. Lee, Jonathan Ho, Tim Salimans, David J. Fleet, Mohammad Norouzi
Google Research, Brain Team
10 Nov 2021

Introduction
비전과 이미지 처리의 많은 문제는 image-to-image translation으로 공식화될 수 있다. 예를 들면 super-resolution, colorization, inpainting과 같은 복원 task와 instance segmentation과 깊이 추정과 같은 픽셀 레벨 이미지 이해 task가 있다. 많은 task는 여러 출력 이미지가 단일 입력과 일치하는 복잡한 inverse problem이다. Image-to-image translation에 대한 자연스러운 접근 방식은 이미지의 고차원 space에서 multi-modal 분포를 캡처할 수 있는 심층 생성 모델을 사용하여 입력이 주어진 출력 이미지의 조건부 분포를 학습하는 것이다.
GAN은 많은 image-to-image task를 위한 모델로 부상했다. 충실도 높은 출력을 생성할 수 있고 광범위하게 적용 가능하며 효율적인 샘플링을 지원한다. 그럼에도 불구하고 GAN은 학습하기 어려울 수 있으며 종종 출력 분포에서 모드를 모두 캡처하지 못한다. Autoregressive model, VAE, normalizing flows는 특정 애플리케이션에서 성공을 거두었지만 GAN과 동일한 수준의 품질과 일반성을 확립하지 못했다.
Diffusion 및 score 기반 모델은 최근 연속 데이터 모델링에서 몇 가지 주요 발전을 이루었다. 음성 합성에서 diffusion model은 SoTA autoregressive model과 동등한 점수를 달성했다. 클래스 조건부 ImageNet 생성 챌린지에서는 FID 점수 측면에서 강력한 GAN baseline을 능가했다. 이미지 super-resolution에서는 GAN을 능가하는 인상적인 결과를 제공했다. 이러한 결과에도 불구하고 diffusion modal이 이미지 조작을 위한 다재다능하고 일반적인 프레임워크를 제공하는 데 있어 GAN과 경쟁하는지 여부는 분명하지 않다.
본 논문에서는 colorization, inpainting, uncropping, JPEG 복원과 같은 고유하고 어려운 task들에 대한 image-to-image diffusion model을 구현한 Palette의 일반적인 적용 가능성을 조사한다. 본 논문은 Palette가 task별로 아키텍처, hyperparameter, loss에 대한 변경 없이 네 가지 task 모두에서 충실도 높은 출력을 제공한다는 것을 보여준다. 동일한 신경 아키텍처를 사용하여 task별 baseline과 강력한 regression baseline을 능가한다. Colorization, inpainting, JPEG 복원에 대해 학습된 단일 generalist Palette 모델이 task별 JPEG 모델을 능가하고 다른 task에서 경쟁력 있는 성능을 달성한다.
저자들은 denoising loss function과 신경망 아키텍처를 포함하여 Palette의 주요 구성 요소를 연구하였다. 목적 함수의 $L_2$ 및 $L_1$ loss는 유사한 샘플 품질 점수를 생성하는 반면 $L_2$는 모델 샘플의 다양성을 높이는 반면 $L_1$은 더 보수적인 출력을 생성한다. 또한 저자들은 Palette의 U-Net 아키텍처에서 self-attention 레이어를 제거하여 완전히 컨볼루션 모델을 구축하면 성능이 저하된다는 사실을 발견했다. 마지막으로 ImageNet 기반의 inpainting, uncropping, JPEG 복원을 위한 표준화된 평가 프로토콜을 옹호하고 여러 baseline에 대한 샘플 품질 점수를 측정하였다.
Palette
Diffusion model은 반복적인 denoising process를 통해 표준 가우시안 분포의 샘플을 경험적 데이터 분포의 샘플로 변환한다. 조건부 diffusion model은 denoising process를 입력 신호에 따라 조건부로 만든다. Image-to-image diffusion model은 $p (y \vert x)$ 형식의 조건부 diffusion model이다. 여기서 $x$와 $y$는 모두 이미지이다. 예를 들어 $x$는 grayscale 이미지이고 $y$는 컬러 이미지이다. 이 모델은 이미지 super-resolution에 적용되었다. 본 논문은 광범위한 task들에서 image-to-image diffusion model의 일반적인 적용 가능성을 연구하였다.
학습 출력 이미지 $y$가 주어지면 noisy한 버전 $\tilde{y}$를 생성하고 신경망 $f_\theta$를 학습시켜 주어진 $x$와 noise level indicator $\gamma$에 대하여 $\tilde{y}$를 denoise한다. Loss는 다음과 같다.
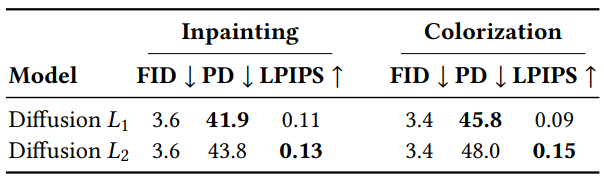
\[\begin{equation} \mathbb{E}_{(x, y)} \mathbb{E}_{\epsilon \sim \mathcal{N} (0,I)} \mathbb{E}_\gamma \bigg\| f_\theta (x, \tilde{y}, \gamma) - \epsilon \bigg\|_p^p \\ \textrm{where} \quad \tilde{y} = \sqrt{\gamma} y + \sqrt{1 - \gamma} \epsilon \end{equation}\]WaveGrad와 SR3는 $L_1$ norm을 사용한 반면, DDPM은 $L_2$ norm을 사용한다. 저자들은 조심스럽게 ablation을 수행하고 norm 선택의 영향을 분석하였다. 저자들은 $L_1$이 $L_2$에 비해 샘플 다양성이 상당히 낮다는 것을 발견했다. $L_1$이 유용할 수 있지만 일부 애플리케이션에서 잠재적인 환각을 줄이기 위해 Pallete는 $L_2$를 채택하여 출력 분포를 보다 충실하게 캡처한다.
Architecture
Palette는 ADM에서 영감을 얻은 몇 가지 수정 사항이 포함된 U-Net 아키텍처를 사용한다. 네트워크 아키텍처는 256$\times$256 클래스 조건부 U-Net 모델을 기반으로 한다. Palette의 아키텍처와 ADM의 아키텍처 사이의 두 가지 주요 차이점은 클래스 컨디셔닝의 부재와 SR3와 같은 concatenation을 통한 소스 이미지의 추가 컨디셔닝이다.
Evaluation Protocol
Image-to-image translation model을 평가하는 것은 어려운 일이다. Colorization에 대한 이전 연구들은 FID 점수와 모델 비교를 위한 사람의 평가에 의존했다. Inpainting과 uncropping과 같은 task는 종종 정성적 평가에 크게 의존했다. JPEG 복원과 같은 다른 task의 경우 PSNR과 SSIM과 같은 레퍼런스 기반 픽셀 레벨 유사성 점수를 사용하는 것이 일반적이었다. 또한 많은 task에는 평가를 위한 표준화된 데이터셋이 부족하다는 점도 주목할 만하다.
본 논문은 규모, 다양성, 공개 가용성으로 인해 ImageNet에서 inpainting, uncropping, JPEG 복원을 위한 통합 평가 프로토콜을 제안한다. Inpainting과 uncropping을 위해 기존 task는 평가를 위해 Places2 데이터셋에 의존했다. 따라서 이러한 task을 위해 Places2에서 표준 평가 설정도 사용한다. 특히 ImageNet에서 모든 image-to-image translation task를 벤치마킹하기 위한 표준 subset으로 제안된 ImageNet ctest10k split 사용을 지지한다. 또한 places10k라는 카테고리가 균형있는 Places2 validation set의 10,950개 이미지를 포함한 subset을 소개한다. 통제된 인간 평가 외에도 이미지 품질과 다양성을 모두 캡처하는 자동화된 측정 기준의 사용을 지지한다. PSNR과 SSIM과 같은 픽셀 레벨 metric의 경우 인간의 인식과 달리 흐릿한 regression 출력을 선호하는 경향을 보이며, hallucination(환각)이 필요한 어려운 task에 대한 신뢰할 수 있는 샘플 품질 측정이 아니기 때문에 피한다.
Image-to-image translation을 위해 샘플 품질에 대한 4가지 자동화된 정량 측정을 사용한다.
- Inception Score (IS)
- Fréchet Inception Distance (FID)
- 사전 학습된 ResNet-50 classifier의 Classification Accuracy (CA) (top-1)
- Perceptual Distance (PD) (Inception-v1 feature space의 유클리드 거리)
일부 task의 경우 여러 모델 출력 간의 쌍별 SSIM과 LPIPS 점수를 통해 샘플 다양성을 평가한다. 샘플 다양성은 도전적이며 기존의 많은 GAN 기반 방법의 주요 제한 사항이었다.
Image-to-image translation model의 궁극적인 평가는 사람의 평가이다. 즉, 인간이 실제 이미지와 모델의 출력을 구별할 수 있는지 여부이다. 이를 위해 저자들은 테스트 입력에서 얻은 실제 이미지에 대해 모델 출력의 지각 품질을 평가하기 위해 2-alternative forced choice (2AFC) 시험을 사용하였다. “어떤 이미지가 카메라로 찍은 것이라고 생각하십니까?”라는 질문을 받았을 때 실제 이미지보다 모델 출력을 선택한 인간 평가자의 비율인 fool rate로 결과를 요약한다.
Experiments
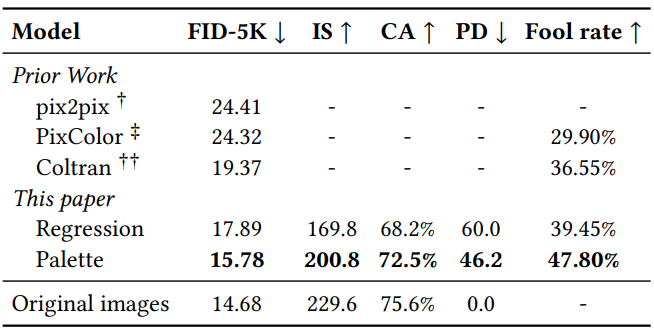
1. Colorization
Colorization은 ImageNet validation set에서 수행되었다.

2. Inpainting
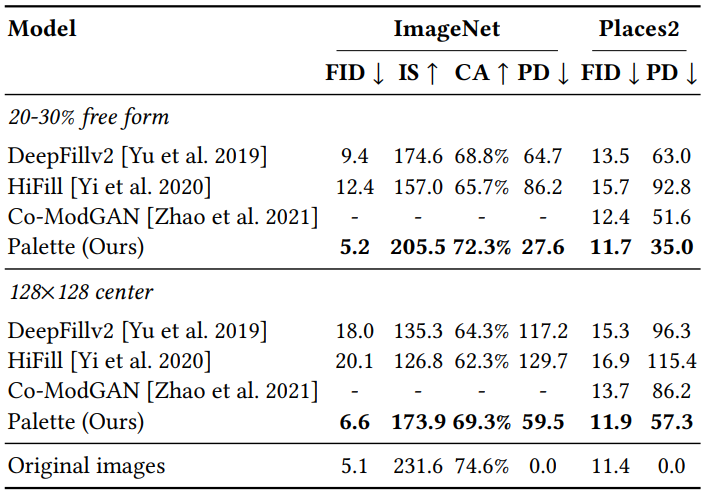

3. Uncropping
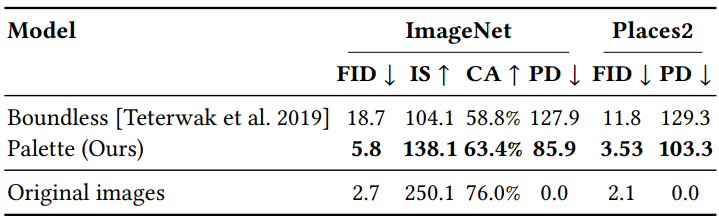

다음은 주어진 256$\times$256 이미지의 좌우에 uncropping을 여러 번 적용하여 만든 256$\times$2304 파노라마이다.

4. JPEG restoration
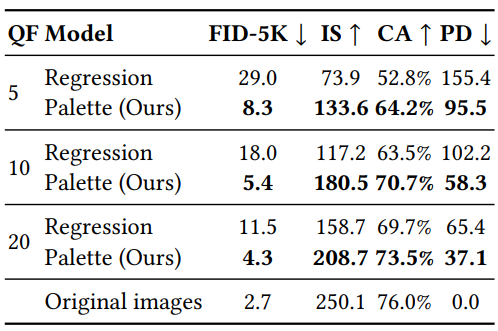

5. Self-attention in diffusion model architectures
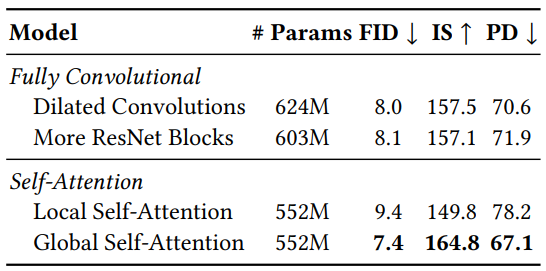
저자들은 self-attention layer가 어려운 task중 하나인 inpainting의 샘플 품질에 미치는 영향을 분석하였다. 4개의 설정으로 실험을 진행하였다.
- Global Self-Attention
- Local Self-Attention: feature map을 4개의 겹치지 않는 query block으로 나누어 사용
- More ResNet Blocks w/o Self-Attention: 2$\times$residual block 사용
- Dilated Convolutions w/o Self-Attention: More ResNet Blocks에서 dilation rates를 증가
각 설정은 32$\times$32, 16$\times$16, 8$\times$8 해상도에 적용하였다. 결과는 아래 표와 같다.
6. Sample diversity
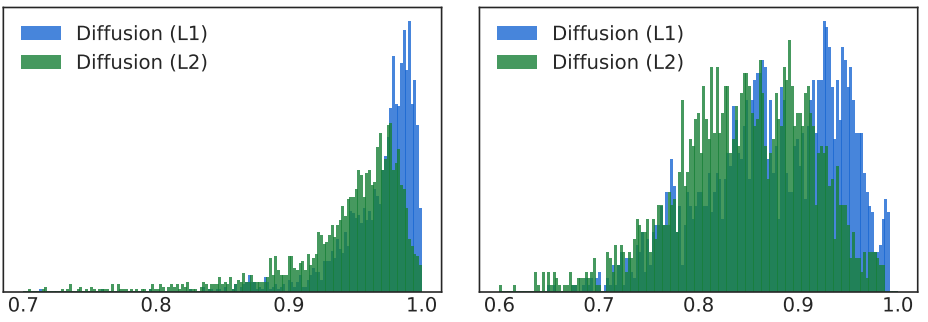
다음은 여러 입력 이미지에 대한 출력 이미지들의 SSIM을 colorization(왼쪽)과 inpainting(오른쪽)에 대하여 측정한 히스토그램이다.
다음은 목적 함수의 norm 선택이 샘플 다양성에 미치는 영향을 나타낸 표이다.
다음은 inpainting, colorization, uncropping에 대한 Palette의 다양성을 보여주는 예시이다.

7. Multi-task learning
Multi-task 학습은 여러 image-to-image task, 즉 블라인드 이미지 향상을 위해 하나의 모델을 학습하는 자연스러운 접근 방식중 하나이다. 다른 접근 방식 중 하나는 imputation이 있는 조건부 task에 unconditional model을 적용하는 것이다. 예를 들어 Score-Based Generative Modeling through Stochastic Differential Equations 논문은 inpainting을 위해 이를 수행하였다. 각 step에서 이전 단계의 noisy한 이미지를 denoise하고 추정 이미지 $y$의 픽셀을 관찰된 이미지 영역의 픽셀로 대체한 다음 noise를 추가하고 다음 denoising iteration으로 진행한다.

위 그림은 이 방법을 네 가지 task 모두에 대해 학습된 multi-task Palette와 inpainting에만 학습된 Palette를 비교한다. 모든 모델은 동일한 아키텍처, 학습 데이터, 학습 단계 수를 사용한다. 위 그림의 결과는 일반적이다. 목적이 변경된 unconditional model은 잘 수행되지 않는데, 부분적으로는 ImageNet과 같은 다양한 데이터셋에서 좋은 unconditional model을 학습하기 어렵고 반복 정제 중에 관찰된 픽셀을 포함한 모든 픽셀에 noise가 추가되기 때문이다. 대조적으로 Pallete는 모든 step에 대한 noise가 없는 관찰에 직접적으로 영향을 받는다.
다음 JPEG 복원, inpainting, colorization에 대해 동시에 학습된 하나의 multi-task Palette와 task별로 학습된 task-specific Pallete 간의 정량적 비교 결과를 나타낸 표이다.
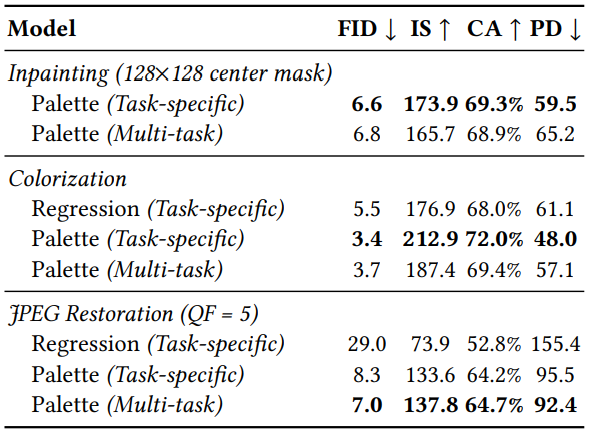
Multi-task Pallete가 task-specific JPEG 복원 모델보다 성능이 우수하지만 inpainting 및 colorization에서는 task-specific Palette 모델보다 약간 성능이 낮은 것을 볼 수 있다.