[논문리뷰] Images Speak in Images: A Generalist Painter for In-Context Visual Learning (Painter)
CVPR 2023. [Paper] [Github]
Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, Tiejun Huang
Beijing Academy of Artificial Intelligence | Zhejiang University | Peking University
5 Dec 2022
Introduction
다양한 task를 동시에 실행할 수 있고, 주어진 프롬프트와 매우 적은 예를 통해 새로운 task를 수행할 수 있는 하나의 범용 모델을 학습하는 것은 인공 일반 지능에 한 걸음 더 다가가는 중요한 단계이다. NLP에서 in-context learning의 출현은 언어 시퀀스를 범용 인터페이스로 사용하고 모델이 소수의 프롬프트와 예제만으로 다양한 언어 중심 task에 빠르게 적응할 수 있도록 하는 이러한 방향의 새로운 경로를 제시한다.
지금까지 컴퓨터 비전에서는 in-context learning이 거의 탐구되지 않았으며 이를 달성하는 방법이 불분명한 상태로 남아 있다. 이는 두 가지 방식의 차이로 인해 발생할 수 있다. 한 가지 차이점은 NLP task는 주로 언어 이해와 생성으로 구성되므로 출력 공간이 이산 언어 토큰의 시퀀스로 통합될 수 있다는 것이다. 그러나 비전 task는 다양한 세분성과 각도에 대한 시각적 입력을 추상화한 것이다. 따라서 비전 task는 출력 표현이 크게 다르므로 다양한 task별 loss function과 아키텍처 디자인으로 이어진다. 두 번째 차이점은 NLP task의 출력 공간이 입력 공간과 동일하다는 것이다. 따라서 언어 토큰 시퀀스인 task 지침과 예제의 입력/출력은 입력 조건 (task 프롬프트)으로 직접 사용될 수 있으며, 이는 대규모 언어 모델에서 직접 처리될 수 있다. 그러나 비전에서는 비전 모델이 이해하고 도메인 외부 task로 전송할 수 있는 범용 task 프롬프트 또는 지침을 정의하는 방법이 불분명하다. 최근 몇 가지 시도는 NLP의 솔루션을 따라 이러한 문제를 해결한다. 비전 task의 연속 출력 공간을 이산화하고 task 프롬프트로 언어 또는 특별히 설계된 이산 토큰을 사용하여 비전 문제를 NLP 문제로 거의 변환한다.
그러나 저자들은 이미지가 이미지로 말한다고 믿는다. 즉, 이미지 자체는 범용 시각적 인식을 위한 자연스러운 인터페이스이다. 본 논문에서는 비전 중심 솔루션을 통해 위의 장애물을 해결한다. 핵심 관찰은 대부분의 dense prediction 비전 문제가 이미지 인페인팅으로 공식화될 수 있다는 것이다.
따라서 비전 task의 출력을 위해 “이미지”로 나타나는 3채널 텐서의 표현이 필요하고 한 쌍의 이미지를 사용하여 task 프롬프트를 지정한다. 여기에서는 깊이 추정, keypoint detection, semantic segmentation, instance segmentation, 이미지 denoising, 이미지 제거, 이미지 향상을 포함하여 학습을 위한 몇 가지 대표적인 비전 task를 보여주고 “출력 이미지”라고도 불리는 3채널 텐서를 사용하여 출력 공간을 통합한다. 본 논문은 instance mask, panoptic segmentation의 픽셀별 이산 레이블, 깊이 추정의 픽셀별 연속 값, 자세 추정의 고정밀 좌표 등 각 task에 대한 데이터 형식을 신중하게 설계한다. 모델 아키텍처나 loss function을 수정하지 않고 새로운 데이터 쌍을 구성하고 학습 세트에 추가하기만 하면 되므로 더 많은 task를 포함하는 것은 매우 간단하다.
이러한 통합을 기반으로 매우 간단한 학습 과정을 통해 범용 Painter 모델을 학습한다. 학습하는 동안 동일한 task의 두 이미지를 더 큰 이미지로 연결하고 해당 출력 이미지도 연결한다. 그런 다음 입력 이미지를 조건으로 하여 출력 이미지의 픽셀에 masked image modeling (MIM)을 적용한다. 이러한 학습 과정을 통해 모델이 보이는 이미지 패치에 따라 task을 수행할 수 있도록 한다. 즉, 시각적 신호를 컨텍스트로 사용하여 in-context 예측을 수행할 수 있다.
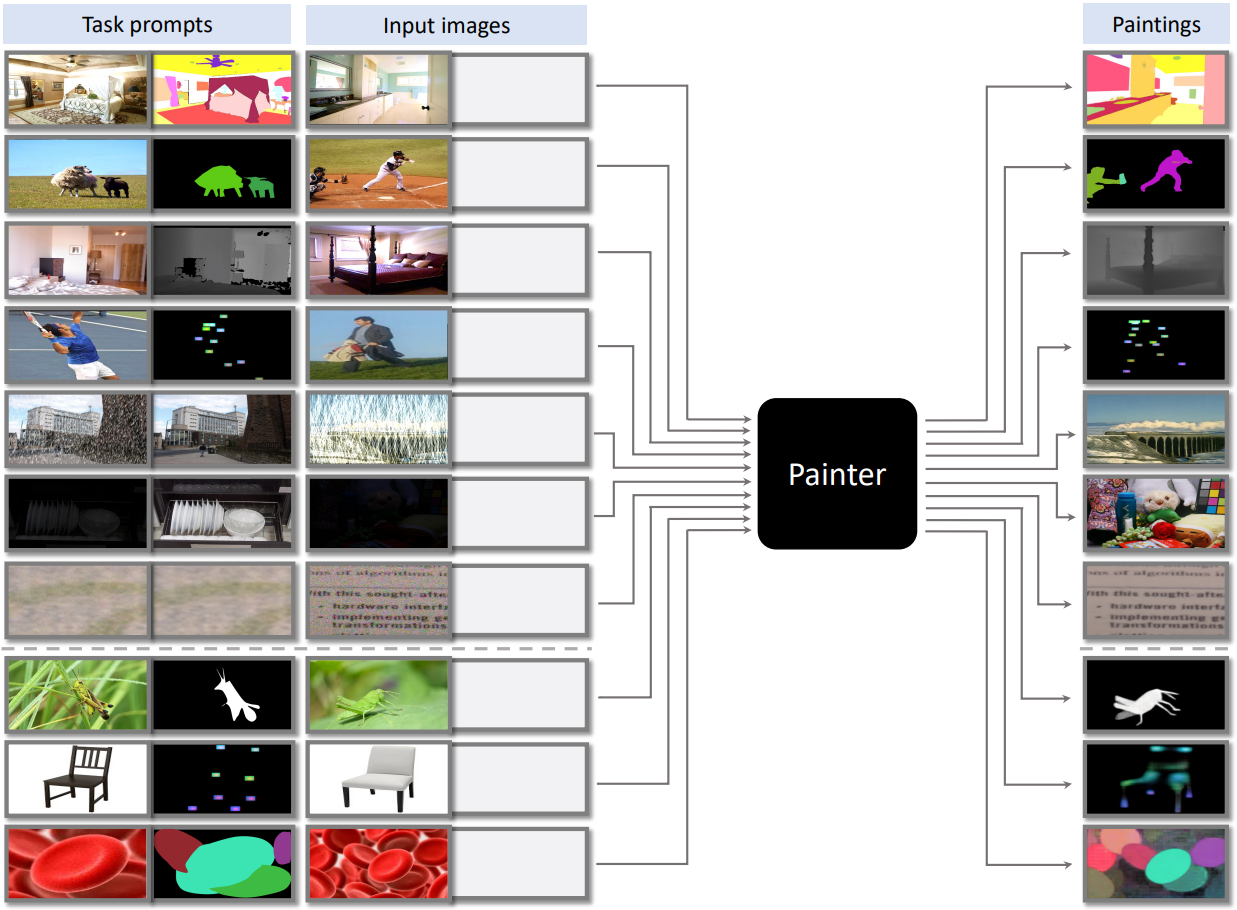
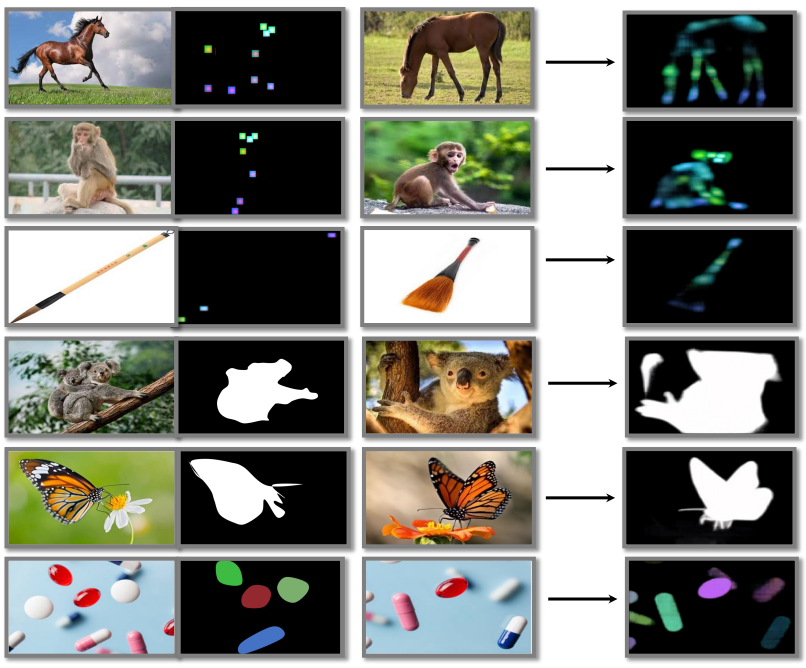
따라서 학습된 모델은 in-context inference가 가능하다. 즉, 입력 조건과 동일한 task의 입력/출력 쌍 이미지를 직접 사용하여 수행할 task를 나타낸다. In-context inference의 예는 위 그림에 나와 있으며, 7개의 도메인 내부 예시 (상단 7개 행)와 3개의 도메인 외부 예시 (하단 3개 행)로 구성되어 있다. 이러한 task 프롬프트 정의에는 거의 모든 이전 접근 방식의 필요에 따라 언어 지침에 대한 깊은 이해가 필요하지 않으며 도메인 내 및 도메인 외부 비전 task를 모두 수행하는 데 매우 유연하다.
Approach
프레임워크의 핵심 아이디어는 깊이 추정, semantic segmentation, instance segmentation, keypoint detection, 이미지 복원과 같은 대부분의 비전 task를 이미지 인페인팅 문제로 재구성하는 것이다. 이를 위해 해당 task의 출력 공간을 “이미지”로 재정의한다.
1. Redefining Output Spaces as “Images”
입력 이미지를 $H \times W \times 3$ 크기의 $x$로 표시하고 task ground truth의 표준 정의를 다양한 task $t$에 대해 다양한 크기를 갖는 $y^t$로 표시하며 이러한 task 출력을 이미지 공간에 재정의하여 $H \times W \times 3$ 크기의 \(\hat{y}^t\)로 표시한다. 본 논문의 철학은 픽셀 간의 공간적 관계를 그대로 유지하는 것이며, 출력 이미지의 각 픽셀은 여전히 해당 입력 이미지 픽셀의 이 task에 대한 출력을 나타내지만 RGB에서는 공간. 즉, 3차원의 \(\hat{y}_{i,j}^t\)는 입력 픽셀 $x_{i,j}$의 해당 ground truth를 나타낸다. 저자들은 깊이 추정, semantic segmentation, keypoint detection, panoptic segmentation 등 다양한 유형의 출력을 갖춘 7가지 대표적인 비전 task를 선택하였다. 본 논문은 RGB 공간과 유사한 3채널 텐서로 각 task에 대한 픽셀당 ground truth를 재정의하며, 이론적으로는 고정된 수의 출력 채널이 본 논문의 목적을 달성할 수 있다. 저자들은 이미지를 만들기 위해 3개의 채널을 선택하였다.
Monocular depth estimation
단안 깊이 추정은 입력 RGB 이미지에 대해 픽셀당 깊이 값 (카메라에 대한 상대적인 거리)을 추정하기 위한 약한 semantic을 사용하는 dense prediction task이다. NYUv2의 경우 픽셀당 ground truth 깊이 $y_{i,j}^t$는 $[0, 10]$ 미터 범위의 실수 값이다. 여기서는 실수 범위의 ground truth 값을 $[0, 255]$ 범위인 정수 공간에 매핑한다.
\[\begin{equation} \hat{y}_{i,j,0}^t = \lfloor y_{i,j}^t \times \frac{255}{10} \rfloor \end{equation}\]세 채널 \(\hat{y}_{i,j,0}^t\), \(\hat{y}_{i,j,0}^t\), \(\hat{y}_{i,j,0}^t\)를 동일한 ground truth로 둔다. Inference에서는 세 채널의 출력을 직접 평균한 다음 학습의 역선형 변환을 수행하여 범위의 깊이 추정치를 얻는다.
Semantic segmentation
Semantic segmentation은 입력 이미지가 주어지면 픽셀당 semantic 레이블을 예측하기 위해 강력한 semantic을 사용하는 dense prediction task이다. $L$개의 카테고리가 있는 semantic segmentation task가 주어지면 RGB 공간이 각 공간에서 동일한 margin을 사용하여 이러한 $L$개의 카테고리를 나타내도록 한다. $L$은 $b$진법 시스템을 사용하는 3자리 숫자로 나타낸다. 여기서 $b = \lceil L^{\frac{1}{3}} \rceil$이고 \(\hat{y}_{i,j,0}^t\), \(\hat{y}_{i,j,0}^t\), \(\hat{y}_{i,j,0}^t\)는 백의 자리, 십의 자리, 일의 자리를 나타낸다. $m = \lfloor \frac{256}{b} \rfloor$로 정의된 margin을 사용하여 한 자리씩 배치한다. 예를 들어, ADE-20K에는 하나의 배경 클래스가 있는 150개의 semantic 카테고리가 있으므로 $b = 6$으로 설정하고 margin을 $m = 42$로 설정한다. 출력 채널은
\[\begin{equation} \hat{y}_{i,j,0}^t = \lfloor \frac{l}{b^2} \rfloor \times m \\ \hat{y}_{i,j,1}^t = \lfloor \frac{l}{b} \rfloor \textrm{ mod } b \times m \\ \hat{y}_{i,j,2}^t = \lfloor l \rfloor \textrm{ mod } b \times m \end{equation}\]로 정의된다. 여기서 $l$은 해당 카테고리를 나타내고 $[0, L)$ 범위의 정수 값이다. Inference를 통해 각 픽셀의 출력을 margin $m$으로 이산화하고 해당 카테고리를 얻는다.
Keypoint detection
Keypoint detection은 객체를 감지하는 동시에 세부적인 키포인트를 위치화하는 세분화된 위치 파악 task이다. 본 논문은 최근 히트맵 기반 하향식 파이프라인을 따르므로 키포인트 분류와 \(\hat{y}_{i,j,0}^t\)의 다른 채널을 사용하는 클래스 독립적인 키포인트 localization의 결합으로 분리한다. 17개 카테고리 분류 task의 경우 각 키포인트를 9$\times$9 픽셀 정사각형으로 정의하고 semantic segmentation 방식을 사용하여 각 정사각형의 색상을 정의한다. 클래스와 무관한 지점 위치 파악 task를 위해 17개의 사각형을 정의한다. 각 사각형은 가장 큰 값이 255이고 중앙 픽셀이 실제 키포인트의 위치인 가우스 분포를 갖는 17$\times$17 히트맵이다. Inference에서는 3채널 출력 이미지의 최종 결과로 각 키포인트의 카테고리와 위치를 얻는다.
Panoptic segmentation
Panoptic segmentation은 semantic segmentation task와 instance segmentation task의 결합이다. 따라서 출력 공간의 재정의와 최적화를 용이하게 하기 위해 이 두 가지 task를 개별적으로 수행한 다음 그 결과를 결합하여 panoptic segmentation에 대한 결과를 얻는다.
클래스와 무관한 instance segmentation의 출력 공간을 재정의한다. 이 task에서는 이미지의 각 instance mask 색상을 동일한 색상으로 직접 변경하므로 인스턴스마다 서로 다른 색상을 사용한다. 이론적으로는 서로 다른 인스턴스에 대해 색상을 랜덤하게 선택할 수 있지만 이 설정으로 인해 모델을 최적화하기가 어려워진다. 이 최적화 문제를 해결하기 위해 SOLO를 따라 이미지 중심의 절대 위치에 따라 각 instance mask의 색상을 할당한다. 개념적으로 이미지를 각각 3개의 채널에 해당하는 16$\times$20$\times$20 블록으로 나눈다. 각 블록에 고정된 색상을 할당한 다음 마스크의 중심이 해당 블록에 위치하면 그에 따라 마스크 색상을 지정한다. Inference에서는 각 색상을 커널로 채택하여 이미지의 각 픽셀과의 거리를 계산한 다음 임계값을 설정하여 최종 마스크를 얻는다. 각 instance mask에 대한 카테고리를 얻으려면 각 instance mask 내의 semantic segmentation 결과에서 다수 카테고리를 해당 카테고리로 직접 할당한다.
Image restoration
이미지 복원은 손상된 이미지를 입력으로 사용하고 해당하는 깨끗한 이미지를 출력한다. 본 논문에서는 이미지 denoising, 이미지 제거, 저조도 이미지 향상을 포함한 세 가지 대표적인 이미지 복원 task를 조사하였다. 입력과 출력 모두 본질적으로 RGB 공간에 정의되어 있으므로 이러한 task는 변환 없이 Painter 모델에서 원활하게 통합될 수 있다.
2. A Masked Image Modeling Framewor
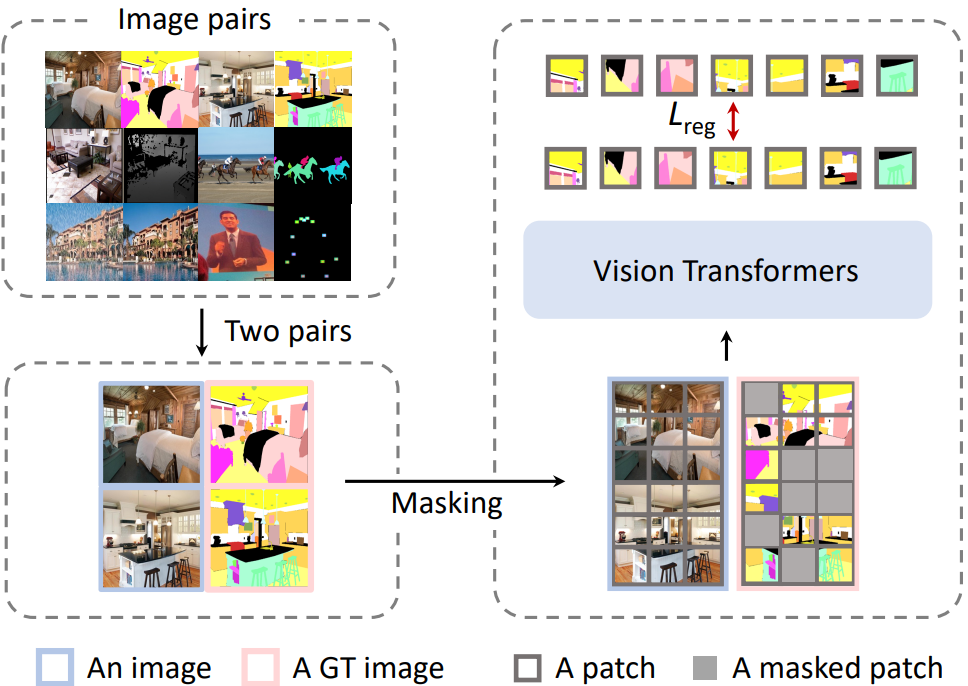
위의 대표적인 비전 task의 출력 공간을 재정의한 결과, 이러한 task의 입력과 출력은 모두 이미지이다. 따라서 위 그림에 설명된 표준 masked image modeling (MIM) 파이프라인을 학습에 직접 적용한다. 이 프레임워크는 입력 형식, 아키텍처, loss function의 세 가지 주요 구성 요소로 구성된다.
Input Format
학습 중에 각 입력 샘플은 이미 data augmentation이 별도로 적용된 동일한 task의 두 쌍의 이미지를 연결한 것이다. 각 이미지 쌍은 하나의 이미지와 해당 task 출력으로 구성되며, 이미지로도 재정의된다. Task 출력 이미지를 랜덤하게 마스킹하고 모델을 학습하여 누락된 픽셀을 재구성한다. 마스킹된 영역의 경우 NLP와 이전 연구들을 따라 학습 가능한 토큰 벡터를 사용하여 각 마스킹된 패치를 대체한다. 본 논문은 블록 방식 마스킹 전략을 채택하고 75%의 마스킹 비율이 잘 작동함을 확인했다.
Architecture
적층된 Transformer으로 구성된 바닐라 ViT를 인코더로 채택한다. 이러한 블록에서 고르게 샘플링된 4개의 feature map을 concat하고 간단한 3개 layer head를 사용하여 각 패치의 feature를 원래 해상도로 매핑한다. 특히 head는 linear layer (1$\times$1 convolution), 3$\times$3 convolution layer, 또 다른 linear layer가 있다.
각 입력 샘플에는 입력 이미지와 출력 이미지가 모두 포함되어 있으므로 입력 해상도는 기존 학습 프로세스보다 클 수 있으며 계산 비용도 커질 수 있다. 이 문제를 해결하기 위해 입력 이미지와 출력 이미지의 초기 feature를 병합하여 계산 비용을 줄이는 방법을 제안한다. 구체적으로, 입력 이미지와 출력 이미지를 모델에 병렬로 공급한 다음 몇 블록 (기본적으로 3블록) 뒤에 패치별로 feature를 더한다. 이 디자인은 계산 비용의 거의 절반을 절약하지만 성능 저하가 발견되지 않았다.
Loss Function
Painter를 학습시키기 위해 마스킹된 픽셀에 대한 smooth-$\ell_1$ loss가 계산된다.
3. In-Context Inference
맨 처음 저자들은 도메인 내부 및 도메인 외부 비전 task를 모두 수행하는 데 매우 유연한 in-context inference를 디자인했다. 비전 task의 입력/출력 공간이 이미지로 통합되었으므로 입력 조건 (task 프롬프트)과 동일한 task의 입력/출력 쌍 이미지를 직접 사용하여 수행할 task를 표시하고, 해당 task를 완료하기 위한 이미지 및 마스킹된 이미지와 concat할 수 있다. Task 프롬프트의 이러한 정의는 이전 접근 방식과 같이 언어 지침에 대한 깊은 이해가 필요하지 않지만 시각적 신호를 비전 모델에서 이해할 수 있고 비전 도메인의 특성과 잘 일치하는 컨텍스트로 사용한다.
또한 task 프롬프트가 다르면 결과도 달라진다. 따라서 보다 적합한 task 프롬프트를 선택하거나 생성하는 방법은 탐색할 새로운 방향이 될 수 있다. 본 논문은 두 가지 간단한 baseline을 제시하고 더 많은 탐구를 향후 연구로 남겨두었다. 첫 번째 baseline은 선택을 통해 더 나은 프롬프트를 얻는 것이다. 즉, 휴리스틱 방식으로 전체 학습 세트를 탐색하고 각 task에 대해 가장 성능이 좋은 예제 쌍을 선택한다. 두 번째 baseline은 task 프롬프트를 생성하는 것이다. Task 프롬프트를 학습 가능한 텐서로 정의하고 전체 모델을 동결한 다음 학습 loss를 사용하여 task 프롬프트를 최적화한다.
Experiments
- 데이터셋
- 단안 깊이 추정: NYUv2
- Semantic segmentation: ADE20K
- Panoptic segmentation: MS-COCO
- Keypoint detection: COCO에 Simple Baseline 적용
- 이미지 denoising: SIDD
- 저조도 이미지 향상: LoL
- 학습 디테일
- optimizer: AdamW ($\beta_1$ = 0.9, $\beta_2$ = 0.999)
- learning rate: $10^{-3}$, cosine scheduler
- iteration: 54,000
- weight decay: 0.05
- drop path ratio: 0.1
- warm-up: 5,400 iteration
- data augmentation
- random flipping
- random resize cropping: 스케일 = [0.3, 1], 종횡비 = [3/4, 4/3]
- 입력 이미지 크기: 448$\times$448
- 각 task의 샘플링 가중치
- NYUv2 깊이 추정: 0.1
- ADE20K semantic segmentation: 0.2
- COCO instance segmentation: 0.15
- COCO semantic segmentation: 0.25
- COCO human keypoint detection: 0.2
- 이미지 denoising: 0.15
- 이미지 deraining: 0.05
- 저조도 이미지 향상: 0.05
1. Results
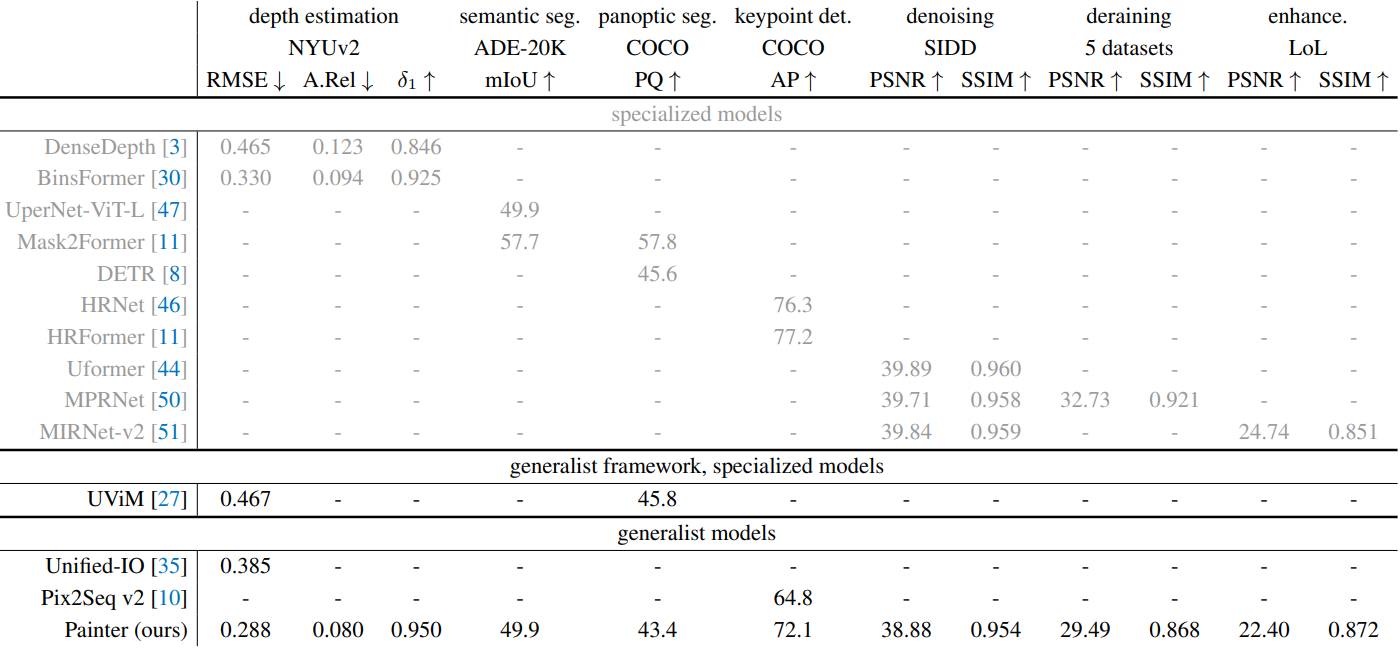
System-level comparison
다음은 여러 비전 범용 모델들과 성능을 비교한 표이다.
Joint training vs. separate training
다음은 7가지 대표 task에서 공동 학습과 개별 학습의 성능을 비교한 표이다.

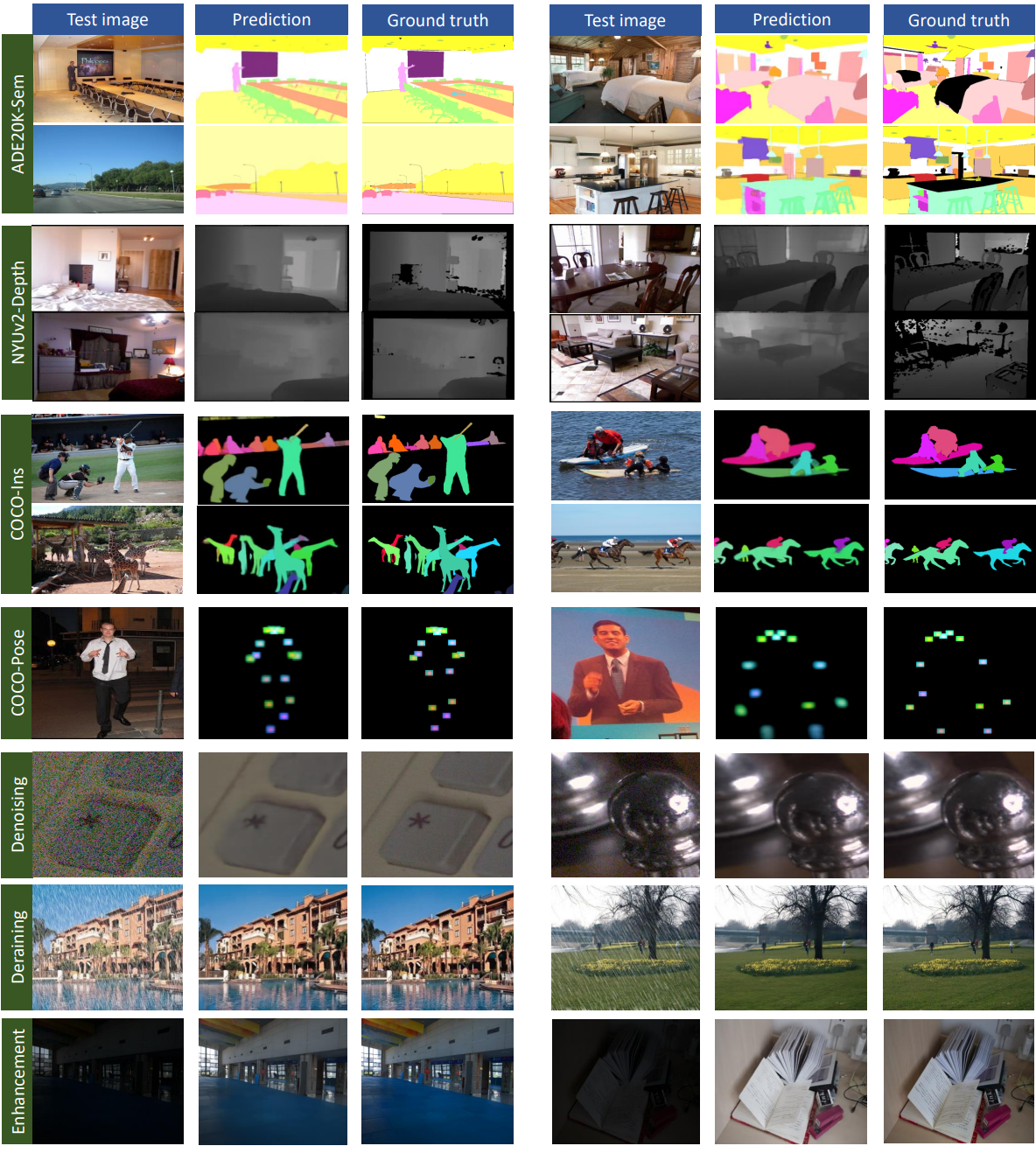
Qualitative results
다음은 여러 task에서의 예시와 Painter의 예측을 시각화한 것이다.
2. Prompt Tuning
다음은 프롬프트 종류에 따른 모델의 성능을 비교한 표이다 .

3. Generalization
다음은 예시와 Painter의 예측을 시각화한 것이다.
다음은 open-vocabulary FSS-1000에서의 정량적 결과이다.
