[논문리뷰] Paint by Example: Exemplar-based Image Editing with Diffusion Models
arXiv 2023. [Paper] [Github]
Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, Fang Wen
University of Science and Technology of China | Microsoft Research Asia
23 Nov 2022

Introduction
수많은 소셜 미디어 플랫폼의 발전으로 인해 사진을 창의적으로 편집하는 것은 어디에서나 필요한 일이 되었다. AI 기반 기술은 전통적으로 전문 소프트웨어와 노동 집약적인 수동 작업이 필요한 고급 이미지 편집의 장벽을 크게 낮춘다. 이제 심층 신경망은 풍부하게 사용 가능한 쌍 데이터로부터 학습하여 이미지 인페인팅, 합성, colorization, 미적 향상과 같은 다양한 낮은 수준의 이미지 편집 task에 대한 강력한 결과를 생성할 수 있다. 반면에 더 어려운 시나리오는 이미지 사실성을 유지하면서 이미지 콘텐츠의 높은 수준의 semantic을 조작하려는 semantic 이미지 편집이다. 이러한 방식으로 GAN과 같은 생성 모델의 semantic latet space에 주로 의존하는 엄청난 노력이 이루어졌지만 기존 연구들의 대부분은 특정 이미지 장르로 제한된다.
Autoregressive model 또는 diffusion model을 기반으로 하는 최근 대규모 언어-이미지 (LLI) 모델은 복잡한 이미지 모델링에서 전례 없는 생성 능력을 보여주었다. 이러한 모델을 사용하면 이전에는 불가능했던 다양한 이미지 조작 작업이 가능해지며 텍스트 프롬프트의 안내에 따라 일반 이미지에 대한 이미지 편집이 가능해진다. 그러나 상세한 텍스트 설명조차도 필연적으로 모호함을 초래하고 사용자가 원하는 효과를 정확하게 반영하지 못할 수 있다. 실제로, 많은 세밀한 객체 모양은 일반 언어로는 거의 지정될 수 없다. 따라서 세밀한 이미지 편집을 쉽게 할 수 있는 보다 직관적인 접근 방식을 개발하는 것이 중요하다.
본 연구에서는 사용자가 제공하거나 데이터베이스에서 검색한 예시 이미지에 따라 이미지 내용에 대한 정확한 semantic 조작을 허용하는 예시 기반 이미지 편집 접근 방식을 제안한다. 저자들은 이미지가 말보다 더 세부적인 방식으로 사용자가 원하는 이미지 맞춤화를 더 잘 전달한다고 믿는다. 이 task는 전경 객체를 합성할 때 색상 및 조명 보정에 주로 초점을 맞춘 image harmonization와 완전히 다른 반면, 본 논문은 훨씬 더 복잡한 task를 목표로 한다. 예를 들어 다양한 포즈, 변형 또는 시점을 생성하는 등 예시를 의미론적으로 변형하는 것이다. 편집된 콘텐츠는 이미지 상황에 따라 원활하게 삽입될 수 있다. 실제로 일관된 이미지 혼합을 위해 아티스트가 이미지 에셋에 대해 지루한 변형을 수행하는 전통적인 이미지 편집 task 흐름을 자동화한다.
목표를 달성하기 위해 예시 이미지를 기반으로 diffusion model을 학습시킨다. 텍스트 기반 모델과 달리 핵심 문제는 소스 이미지, 예시 및 해당 편집 ground-truth로 구성된 triplet 학습 쌍을 충분히 수집하는 것이 불가능하다는 것이다. 한 가지 해결 방법은 인페인팅 모델을 학습할 때 레퍼런스 역할을 하는 입력 이미지에서 개체를 무작위로 자르는 것이다. 그러나 이러한 self-reference 설정을 통해 학습된 모델은 실제 모형으로 일반화할 수 없다. 모델은 단순히 레퍼런스 객체를 복사하여 최종 출력에 붙여넣는 방법만 학습하기 때문이다.
본 논문은 이 문제를 회피하는 몇 가지 핵심 요소를 식별한다. 첫 번째는 생성적 prior를 활용하는 것이다. 특히 사전 학습된 text-to-image 모델은 원하는 고품질 결과를 생성할 수 있는 능력을 갖추고 있으므로 이를 초기화로 활용하여 복사하여 붙여넣는 자명한 솔루션에 빠지지 않도록 한다. 그러나 오랜 시간 동안 fine-tuning하면 모델이 사전 지식에서 벗어나 궁극적으로 다시 퇴화될 수 있다. 따라서 공간 토큰을 삭제하고 글로벌 이미지 임베딩만 조건으로 간주하는 self-reference 컨디셔닝에 대한 정보 bottleneck을 도입한다. 이러한 방식으로 네트워크가 예시 이미지의 높은 수준의 의미와 소스 이미지의 컨텍스트를 이해하도록 강제하여 self=supervised 학습 중에 자명한 결과를 방지한다. 또한 학습-테스트 격차를 효과적으로 줄일 수 있는 self-reference 이미지에 공격적인 augmentation을 적용한다.
본 논문은 두 가지 측면에서 접근 방식의 편집 가능성을 더욱 향상시킨다.
- 실제 편집에 사용되는 일반적인 브러시를 모방하기 위해 학습이 불규칙한 랜덤 마스크를 사용한다
- classifier-free guidance를 사용하여 이미지 품질과 레퍼런스에 대한 스타일 유사성을 모두 높인다.
Method
병합된 이미지가 그럴듯하고 사실적으로 보이도록 레퍼런스 이미지를 원본 이미지에 자동으로 병합하는 예시 기반 이미지 편집을 목표로 한다. 최근 텍스트 기반 이미지 편집의 눈부신 성공에도 불구하고, 복잡하고 다양한 생각을 표현하기 위해 단순한 언어적 설명을 사용하는 것은 여전히 어렵다. 반면에 이미지는 사람들의 의도를 전달하는 데 더 나은 대안이 될 수 있다.
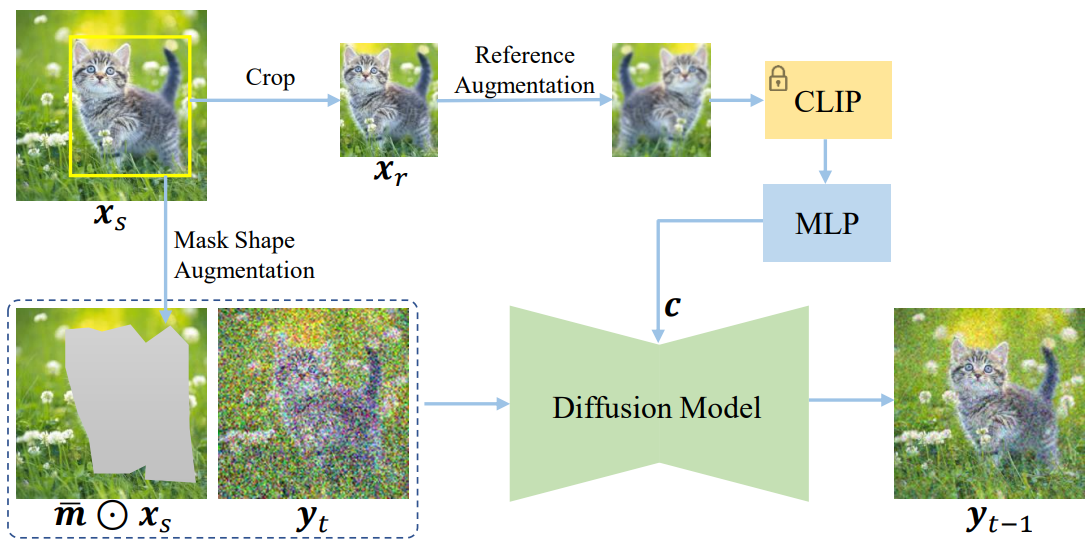
소스 이미지를 $x_s \in \mathbb{R}^{H \times W \times 3}$으로 표시하자. 여기서 $H$와 $W$는 각각 너비와 높이이다. 편집 영역은 직사각형 또는 불규칙한 모양일 수 있으며 이진 마스크 \(m \in \{0, 1\}^{H \times W}\)로 표시되며, 값 1은 $x_s$에서 편집 가능한 위치를 지정한다. 원하는 객체를 포함하는 레퍼런스 이미지 $x_r \in \mathbb{R}^{H’ \times W’ \times 3}$이 주어질 때, 본 논문의 목표는 \(\{x_s, x_r, m\}\)에서 이미지 $y$를 합성하여 $m = 0$인 영역은 소스 이미지 $x_s$에 최대한 동일하게 유지되도록 하면서 $m = 1$인 영역은 객체를 레퍼런스 이미지 $x_r$과 유사하게 묘사하고 조화롭게 맞추는 것이다.
이 task는 암시적으로 여러 가지 중요한 절차를 포함하기 때문에 매우 어렵고 복잡하다.
- 모델은 레퍼런스 이미지의 객체를 이해하고 배경의 잡음을 무시하면서 모양과 질감을 모두 캡처해야 한다.
- 소스 이미지에 잘 맞는 객체의 변환된 view (다른 포즈, 다른 크기, 다른 조명 등)를 합성하는 것이 중요하다.
- 모델은 병합 경계에서 부드러운 전환을 보여주는 사실적인 사진을 생성하기 위해 객체 주변 영역을 인페인팅해야 한다.
- 레퍼런스 이미지의 해상도가 편집 영역보다 낮을 수 있다. 모델은 super-resolution을 포함해야 한다.
1. Preliminaries
Self-supervised training
예시 기반 이미지 편집 학습을 위해 쌍을 이루는 데이터 (ex. \(\{(x_s, x_r, m), y\}\))를 수집하고 주석을 추가하는 것은 불가능하다. 합리적인 출력을 수동으로 작성하려면 막대한 비용과 노동력이 필요할 수 있다. 따라서 self-supervised 학습을 수행한다. 구체적으로, 이미지와 이미지에 있는 객체의 bounding box가 주어지면 학습 데이터를 시뮬레이션하기 위해 객체의 bounding box를 이진 마스크 $m$으로 사용한다. 소스 이미지의 bounding box에 있는 이미지 패치를 레퍼런스 이미지 $x_r = m \odot x_s$로 직접 간주한다. 당연히 이미지 편집 결과는 원본 소스 이미지 $x_s$여야 한다. 따라서 학습 데이터는
\[\begin{equation} \{(\bar{m} \odot x_s, x_r, m), x_s\}, \quad \textrm{where} \quad \bar{m} = \unicode{x1D7D9} - m \end{equation}\]로 구성된다.
A naive solution
Diffusion model은 전례 없는 이미지 품질을 합성하는 데 있어 눈에 띄는 진전을 이루었으며 많은 텍스트 기반 이미지 편집 task에 성공적으로 적용되었다. 예시 기반 이미지 편집 task의 경우 순진한 해결책은 텍스트 조건을 레퍼런스 이미지 조건으로 직접 바꾸는 것이다.
구체적으로 diffusion model은 Markov forward process를 점진적으로 reverse하여 이미지 $y$를 생성한다. $y_0 = x_s$에서 시작하여 forward process는 noise가 증가하는 이미지 시퀀스 \(\{y_t \vert t \in [1, T]\}\)를 생성한다. 여기서 $y_t = \alpha_t y_0 + (1 − \alpha_t) \epsilon$이고 $\epsilon$는 Gaussian noise이고 $\alpha_t$는 timestep $t$에 따라 감소한다. 생성 프로세스의 경우 diffusion model은 다음 loss function을 최소화하여 조건 $c$가 주어지면 마지막 step에서 이미지를 점진적으로 denoise한다.
\[\begin{equation} \mathcal{L} = \mathbb{E}_{t, y_0, \epsilon} [\| \epsilon_\theta (y_t, \bar{m} \odot x_s, c, t) - \epsilon \|_2^2] \end{equation}\]텍스트 기반 인페인팅 모델의 경우 조건 $c$는 주어진 텍스트이며 일반적으로 사전 학습된 CLIP 텍스트 인코더에 의해 처리되어 77개의 토큰을 출력한다. 마찬가지로 순진한 해결책은 이를 CLIP 이미지 임베딩으로 직접 대체하는 것이다. \(c = \textrm{CLIP}_\textrm{all} (x_r)\)로 표시되는 1개의 클래스 토큰과 256개의 패치 토큰을 포함하여 257개의 토큰을 출력하는 사전 학습된 CLIP 이미지 인코더를 활용한다.

이 순진한 솔루션은 학습 세트에 잘 수렴된다. 그러나 테스트 이미지에 적용해 보면 생성된 결과가 만족스럽지 못하다. 위 그림에서 볼 수 있듯이 편집 영역에는 명백한 복사 붙여넣기 아티팩트가 존재하여 생성된 이미지를 매우 부자연스럽게 만든다. 이는 순진한 학습 방식에서 모델이 자명한 매핑 함수 $\bar{m} \odot x_s + x_r = x_s$를 학습하기 때문이다. 이는 네트워크가 레퍼런스 이미지의 내용과 소스 이미지에 대한 연결을 이해하는 것을 방해하여 레퍼런스 이미지가 임의로 제공되지만 원본 이미지의 패치는 제공되지 않는 일반화 실패로 이어진다.
Our motivation
모델이 이러한 자명한 매핑 함수를 학습하는 것을 어떻게 방지하고, self-supervised 학습 방식으로 모델 이해를 촉진할 수 있는지는 어려운 문제이다. 본 논문에서는 세 가지 원칙을 제안한다.
- 네트워크가 단순히 복사하는 대신 레퍼런스 이미지의 내용을 이해하고 재생성하도록 강제하기 위해 정보 bottleneck을 도입한다.
- 학습-테스트 불일치 문제를 완화하기 위해 강력한 augmentation을 채택한다. 이는 네트워크가 예시 객체뿐만 아니라 배경에서도 변환을 학습하는 데 도움이 된다.
- 예시 기반 이미지 편집의 또 다른 중요한 기능은 제어 가능성이다. 편집 영역의 모양과 편집 영역과 레퍼런스 이미지 간의 유사도를 제어할 수 있다.
2. Information Bottleneck
Compressed representation
저자들은 텍스트 상태와 이미지 상태의 차이를 재분석하였다. 텍스트 조건의 경우 텍스트는 본질적으로 semantic 신호이므로 모델은 자연스럽게 semantic을 학습해야 한다. 이미지 상태에 관해서는 맥락 정보를 이해하고 내용을 복사하는 것보다 기억하기가 매우 쉬워서 자명한 솔루션에 도달한다. 이를 방지하기 위해 레퍼런스 이미지의 정보를 압축하여 마스크 영역을 재구성하는 난이도를 높인다. 특히 예시 이미지에서 사전 학습된 CLIP 이미지 인코더의 클래스 토큰만 조건으로 활용한다. 레퍼런스 이미지를 공간 크기 224$\times$224$\times$3에서 차원 1024의 1차원 벡터로 압축한다.
이렇게 고도로 압축된 표현은 semantic 정보를 유지하면서 고주파수 디테일을 무시하는 경향이 있다. 이는 네트워크가 레퍼런스 콘텐츠를 이해하도록 하고 generator가 학습에서 최적의 결과에 도달하기 위해 직접 복사하여 붙여넣는 것을 방지한다. 표현력을 고려하여 여러 추가적인 fully-connected (FC) layer를 추가하여 feature를 디코딩하고 cross attention을 통해 diffusion process에 주입한다.
Image prior
레퍼런스 이미지를 직접 기억하는 자명한 솔루션을 더 피하기 위해 잘 학습된 diffusion model을 활용하여 강력한 이미지 prior로 초기화한다. 구체적으로 두 가지 주요 이유를 고려하여 text-to-image 생성 모델인 Stable Diffusion을 채택한다.
- Latent space에 있는 모든 벡터가 그럴듯한 이미지로 연결된다는 특성 덕분에 고품질의 이미지를 생성하는 강력한 능력이 있다.
- 사전 학습된 CLIP 모델을 사용하여 언어 정보를 추출한다. 이는 CLIP 이미지 임베딩과 유사한 표현을 공유하므로 좋은 초기화가 된다.
3. Strong Augmentation
Self-supervised 학습의 또 다른 잠재적인 문제는 학습과 테스트 간의 도메인 차이다. 이러한 학습-테스트 불일치는 두 가지 측면에서 발생한다.
Reference image augmentation
첫 번째 불일치는 레퍼런스 이미지 $x_r$이 학습 중에 소스 이미지 $x_s$에서 파생된다는 것인데, 이는 테스트 시에는 거의 발생하지 않는다. 차이를 줄이기 위해 레퍼런스 이미지에 여러 가지 data augmentation 기술 (뒤집기, 회전, 흐림, 탄성 변환 등)을 채택하여 원본 이미지와의 연결을 끊는다. 이러한 data augmentation 을 $\mathcal{A}$로 표시한다. Diffusion model에 제공되는 조건은 다음과 같이 표시된다.
\[\begin{equation} c = \textrm{MLP} (\textrm{CLIP} (\mathcal{A} (x_r))) \end{equation}\]Mask shape augmentation
반면 bounding box의 마스크 영역 $m$은 레퍼런스 이미지에 전체 객체가 포함되어 있음을 보장한다. 결과적으로 generator는 객체를 최대한 완벽하게 채우는 방법을 학습한다. 그러나 이는 실제 시나리오에서는 적용되지 않을 수 있다. 이 문제를 해결하기 위해 bounding box를 기반으로 임의 모양의 마스크를 생성하고 이를 학습에 사용한다. 구체적으로, bounding box의 각 가장자리에 대해 먼저 Bessel curve를 만들어 이를 맞춘 다음 이 곡선에서 20개의 점을 균일하게 샘플링하고 해당 좌표에 1~5개의 픽셀 오프셋을 무작위로 추가한다. 마지막으로 이 점들을 직선으로 순차적으로 연결하여 임의의 모양의 마스크를 형성한다. 마스크 $m$의 랜덤 왜곡 $\mathcal{D}$는 inductive bias를 깨뜨려 학습과 테스트 사이의 격차를 줄인다.
\[\begin{equation} \bar{m} = \unicode{x1D7D9} - \mathcal{D} (m) \end{equation}\]이 두 가지 augmentation은 서로 다른 레퍼런스 guidance에 직면할 때 견고성을 크게 향상시킬 수 있다.
4. Control the mask shape
마스크 모양 augmentation의 또 다른 이점은 inference 단계에서 마스크 모양에 대한 제어력이 향상된다는 것이다. 실제 적용 시나리오에서 직사각형 마스크는 일반적으로 마스크 영역을 정확하게 표현할 수 없다. 어떤 경우 사람들은 다른 영역을 최대한 유지하면서 특정 영역을 편집하고 싶어하므로 불규칙한 마스크 모양을 처리해야 하는 요구가 발생한다. 이러한 불규칙한 마스크를 학습에 포함시킴으로써 모델은 다양한 모양의 마스크가 주어지면 사실적인 결과를 생성할 수 있다.
5. Control the similarity degree
Classifier 없는 샘플링 전략은 편집된 영역과 레퍼런스 이미지 간의 유사도를 제어하기 위한 강력한 도구이다. Classifier-free guidance는 실제로 prior 제약과 posterior 제약의 조합이다.
\[\begin{equation} \log p (y_t \vert c) + (s-1) \log p (c \vert y_t) \propto \log p(y_t) + s (\log p(y_t \vert c) - \log p(y_t)) \end{equation}\]여기서 $s$는 classifier-free guidance scale을 나타낸다. 생성된 이미지와 레퍼런스 이미지의 유사성을 제어하는 척도라고도 볼 수 있다. 더 큰 $s$는 융합 결과가 조건부 레퍼런스 입력에 더 많이 의존한다는 것을 나타낸다. 실험에서는 Improved VQ-Diffusion의 설정을 따른다. 학습 중에 20% 레퍼런스조 조건을 학습 가능한 벡터 $v$로 대체한다. 이 항은 고정된 조건 입력 $p(y_t \vert v)$를 사용하여 $p(y_t)$를 모델링하는 것을 목표로 한다. Inference 단계에서 각 denoising step은 수정된 예측을 사용한다.
\[\begin{equation} \tilde{\epsilon}_\theta (y_t, c) + s (\epsilon_\theta (y_t, c) - \epsilon_\theta (y_t, v)) \end{equation}\]여기서는 간결함을 위해 $t$와 $\bar{m} \odot x_s$를 생략했다. 전체 프레임워크는 아래 그림에 나와 있다.
Experiments
- 데이터셋: OpenImages
- 구현 디테일
- Stable Diffusion의 가중치로 초기화
- 이미지 해상도: 512$\times$512
- epoch: 40
- 학습은 NVIDIA V100 GPU 64개에서 7일 소요
1. Comparisons
다음 그림은 다른 접근 방법들과 정성적으로 비교한 것이다.

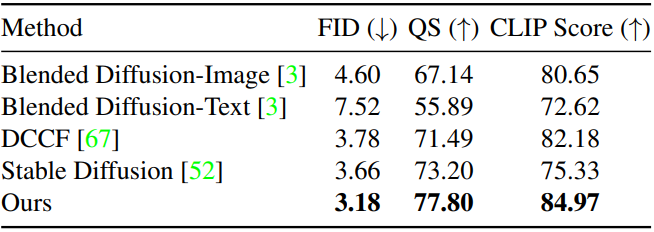
다음은 다른 방법들과 정량적으로 비교한 표이다.
다음은 이미지 품질과 semantic 일관성에 대한 user study 결과로, 평균 순위 점수를 비교한 표이다. (1 ~ 5)

2. Ablation Study
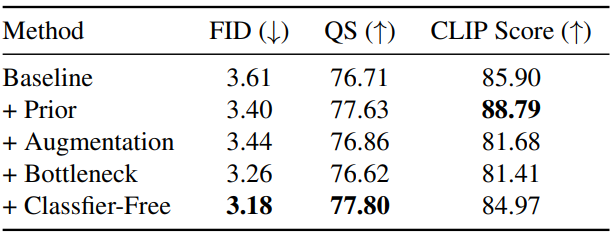
다음은 각 구성요소에 대한 ablation study 결과이다.

다음은 classifier-free guidance scale $\lambda$에 따른 결과를 비교한 것이다.

3. From Language to Image Condition
다음은 점점 더 정확해지는 텍스트 설명과 이미지를 guidance로 사용할 때의 결과를 비교한 것이다. 이미지를 조건으로 사용할 때 디테일이 더 우수하다.

4. In-the-wild Image Editing
다음은 실제 예시 기반 이미지 편집 결과들이다.

다음은 동일한 원본 이미지와 예시 이미지로부터 함성한 현실적이고 다양한 결과들이다.

5. More Visual Results
