[논문리뷰] Paying More Attention to Image: A Training-Free Method for Alleviating Hallucination in LMMs
ECCV 2024. [Paper] [Page] [Github]
Shi Liu, Kecheng Zheng, Wei Chen
Zhejiang University
31 Jul 2024

Introduction
최근 Large Multimodal Model (LMM)은 상당한 진전을 이루었으며 다양한 task에서 인상적인 역량을 보여주었지만, 여전히 hallucination 현상에 어려움을 겪는다. 구체적으로, 모델에서 생성된 텍스트 콘텐츠와 실제로 입력받는 시각적 입력 사이에 종종 불일치가 있다.
LMM의 hallucination은 종종 modality 정렬 문제로 인해 발생하며, 일반적으로 정렬 학습을 통해 hallucination을 완화하게 된다. 그러나 이미지 입력을 제거하고 hallucination 대상 단어 앞에 생성된 텍스트만 유지하더라도 LMM은 동일한 hallucination 설명을 계속 생성한다.
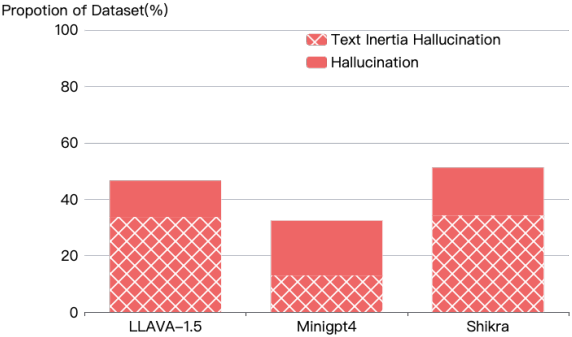
저자들은 COCO 데이터셋에서 이미지 설명 task에 대한 세 개의 LMM에 대한 테스트를 수행했다. 위 그래프에서 볼 수 있듯이 엄격한 설정을 적용하더라도 이러한 현상이 여전히 상당한 비율을 차지한다.
이 현상을 Text Inertia라고 부른다. 저자들은 text inertia가 이미지 표현을 텍스트 토큰으로 텍스트 표현 공간에 매핑하는 현재의 생성 패러다임으로 인해 발생한다고 가설을 세웠다. 이 메커니즘에서 LLM이 지배적이게 되고 inference 프로세스는 이미지 토큰을 추가로 처리하지 않아 생성 프로세스 중에 무시된다.
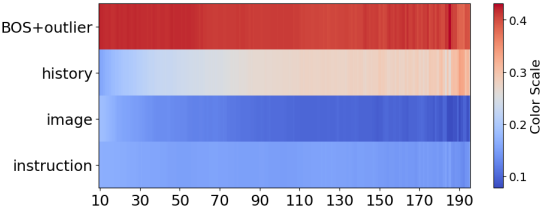
이 가설을 검증하기 위해 저자들은 inference 프로세스 동안 LLaVA 모델의 attention 값 비율을 분석했다. 이미지 토큰이 상당한 비율을 차지함에도 불구하고 현재 메커니즘에서는 상당한 attention을 받지 못한다. 이 멀티모달 채팅은 이미지에 대한 연속적인 attention보다는 맥락에 기반한 자동 완성과 더 유사하다.
이러한 격차를 메우기 위해 본 논문은 Pay Attention to Image (PAI)라고 하는 방법을 도입하였다. 높은 수준에서, PAI는 inference에 개입하여 원래 이미지 인식 방향을 따라 더 이미지 중심적으로 만든다. 저자들은 LMM의 디코더 레이어에 있는 self-attention head에 초점을 맞추었다. Inference 중에 원래 방향에서 이미지 토큰에 대한 attention 가중치를 향상시킨다. 이를 통해 업데이트된 attention 행렬을 사용하여 생성된 토큰에 대한 hidden state를 계산할 수 있으므로 생성 프로세스에서 이미지 표현에 대한 고려 사항을 더 많이 통합할 수 있다.
Text inertia를 더욱 완화하기 위해, 명령 토큰과 과거 응답 토큰을 사용하여 입력을 구성하고, 이 입력의 모델 logit을 이미지 토큰 입력이 있는 원래 모델의 logit에서 뺀다. 이 전략은 생성 프로세스에서 언어 prior의 영향을 줄이는 데 도움이 된다. 추가 학습이나 외부 도구가 필요한 이전 hallucination 완화 방법과 달리 PAI는 학습이 필요 없다.
Method
PAI의 핵심은 근본적으로 상호 연결되어 있는 이미지 무시와 text inertia에 대한 해결책이다. 본질적으로 이미지에 더 많은 주의를 기울일수록 언어 prior에 대한 의존도가 감소한다. 이미지를 중심으로 한 대화에서 모델은 이미지에 더 많은 주의를 기울여야 하므로 응답에 상당한 영향을 미칠 수 있다. 따라서 토큰 수준의 생성에서 self-attention map을 식별하고 원래 방향으로 이미지 attention을 증가시킨다. 이 전략은 이미지 중심의 latent 표현을 촉진시킨다. 또한 text inertia의 영향을 더욱 완화하기 위해 순수 텍스트 입력의 logit 분포를 모델의 출력으로 나눈다.
1. Pay More Attention to Image
Self-attention 행렬 추출
LMM의 응답 프로세스는 기본적으로 토큰별로 생성된다. 각 토큰은 입력 이미지, 명령어, 이전에 생성된 응답을 기반으로 생성되며, multi-layer attention 디코더 아키텍처를 기반으로 한다. 본 논문의 목표는 이미지에 대한 attention을 향상시키는 것이므로, inference 중 각 콘텐츠의 영향을 나타내는 모든 레이어의 각 attention head의 attention 행렬을 추출해야 한다.
시퀀스에서 $k$번째 토큰을 생성할 때, attention head에 대한 입력 표현에는 명령 표현 \(\textbf{X}_I = [\textbf{x}_{i_1}, \ldots, \textbf{x}_{i_{n_I}}]\), 이미지 표현 \(\textbf{X}_V = [\textbf{x}_{v_1}, \ldots, \textbf{x}_{v_{n_V}}]\), 이전에 생성된 응답의 표현 \(\textbf{X}_H = [\textbf{x}_{h_1}, \ldots, \textbf{x}_{h_{n_H}}]\)가 포함된다. 여기서 \(\textbf{X}_V\)는 projector에 의해 처리된 것이다. 기본적으로, 각 입력 레이어의 hidden state는
\[\begin{equation} X = \textrm{concat}(\textbf{X}_I [1:m], \textbf{X}_V, \textbf{X}_I [m+1:n_I], \textbf{X}_H) \end{equation}\]이다. 각 attention head는 각 요소에 다른 정도의 attention을 할당한다. 이미지에 대한 attention을 향상시키기 위해 현재 생성된 토큰에 대한 이미지 토큰과 관련된 attention 가중치 값을 추출하고 intervention 후, softmax를 통해 각 요소의 attention 값을 재분배한다.
신뢰할 수 있는 방향으로 모델을 자극

일부 LLM 연구에서는 intervention을 통해 LLM에서 생성된 답변을 더 신뢰할 수 있도록 만들려는 시도들이 있었다. 기존 방법들은 더 신뢰할 수 있는 방향을 정의하는 것과 관련하여 일반적으로 이 신뢰할 수 있는 방향을 조사하기 위해 추가적인 projection과 학습이 필요하다. 본 논문의 경우 이미지 기반인 응답이 더 신뢰할 수 있는 것으로 간주된다. LMM은 정렬 학습을 거쳤으므로 원래의 attention 값은 이미지 콘텐츠에 따라 방향을 제공한다. 위 그림에서 볼 수 있듯이 원래의 attention 값을 기반으로 이미지 토큰의 attention 값을 증폭함으로써 결과의 신뢰성을 높일 수 있다.
또 다른 방법은 attention head를 선택하지 않는 것이다. Inference-Time Intervention (ITI)에서는 모든 레이어에서 각 head의 순위를 매기고 intervention을 위한 상위 $k$개의 head를 선택하기 위해 신뢰할 수 있는 점수를 도입하였다. 본 논문의 경우 attention 값이 낮은 덜 신뢰할 수 있는 head는 intervention을 덜 받는다. 먼저 softmax 연산 전에 attention 가중치 \(\tilde{\textbf{A}}\)에서 현재 생성된 토큰에 대한 이미지 토큰의 attention 가중치를 추출한다. 그런 다음 hyper-parameter $\alpha$를 사용하여 intervention을 위한 step size를 제어한다. 단일 attention head 관점에서 볼 때 다음과 같이 표현할 수 있다.
\[\begin{equation} \tilde{\textbf{A}}_{n,j} = \tilde{\textbf{A}}_{n,j} + \alpha \cdot \vert \tilde{\textbf{A}}_{n,j} \vert \quad \textrm{for} \; m + 1 \le j \le m + n_V \end{equation}\]모델의 최종 vocabulary 확률 분포는 시퀀스의 마지막 토큰의 hidden state의 projection에서 파생된다. 따라서 \(\tilde{\textbf{A}}_{n,j}\)를 인덱싱하여 이미지 토큰의 마지막 토큰 $n$의 attention 가중치를 추출한다. Intervention 후, 인코딩된 hidden state를 재할당할 때 softmax 함수를 사용하여 각 토큰의 attention 값을 재분배한다. 이 절차는 autoregressive하게 후속 토큰 예측마다 반복된다.
Attention mode prior로 더욱 정확하게 자극
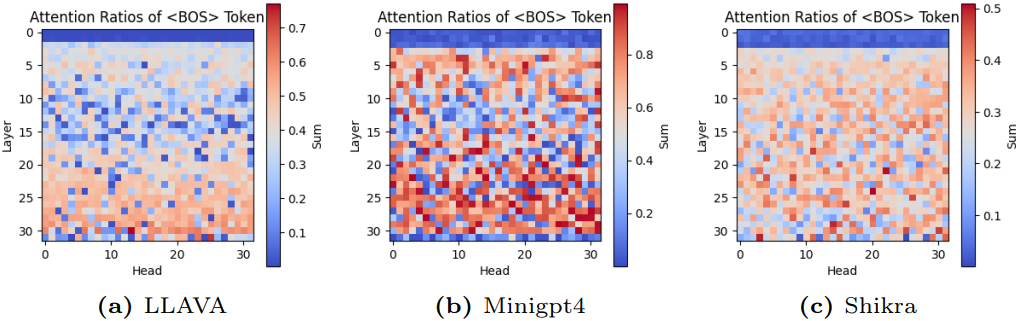
BOS (beginning of sentence) 토큰이 문장에 존재하면 attention 계산 과정에서 attention 값이 높아지는 attention sink pattern이 생기는데, 이는 직관적이지 않다. BOS 토큰은 일반적으로 의미적 내용이 크지 않다. 그러나 토큰 생성은 이 BOS 토큰의 영향을 크게 받는데, 이는 비전 모델에서도 유사하게 나타나는 현상이다. Attention sink pattern은 중복된 attention 값이 존재할 때 나타난다.
Attention sink pattern이 나타나면 이미지 토큰을 자극한다고 추론할 수 있다. 위 그림에 나와 있듯이 이 현상을 더 조사해 보면 이 현상이 얕은 레이어에서는 나타나지 않는다는 것을 알 수 있다. 이는 얕은 레이어가 의미가 풍부한 정보를 인코딩하는 데 더 집중하는 경향이 있기 때문이다. 의미가 풍부한 토큰의 인코딩이 안정화되면 attention sink 현상이 발생한다. 따라서 hidden state의 유사성을 계산하여 intervention 타이밍을 판단한다.
2. Image-Centric Logit Refine
LMM의 입력에서 이미지를 제거하더라도 동일한 hallucination 텍스트를 계속 생성하는 특이한 현상을 관찰된다. 이 관찰은 자연스럽게 출력 분포 (입력에 이미지가 없는 경우)를 초기 예측 분포에 페널티를 부과하는 기준으로 사용하는 개념으로 이어진다. 따라서 생성된 토큰의 분포를 다음과 같이 업데이트한다.
\[\begin{aligned} p_\textrm{model} = \; & \gamma \cdot p_\textrm{model} (\textbf{y} \vert \textbf{X}_V, \textbf{X}_I, \textbf{X}_H) \\ & - (\gamma - 1) \cdot p_\textrm{model} (\textbf{y} \vert \textbf{X}_I, \textbf{X}_H) \end{aligned}\]이 방정식은 텍스트만으로 예측된 확률을 효과적으로 줄인다. 가중치 $\gamma$는 초기 예측 분포에 적용되는 페널티의 정도를 제어하는 데 사용된다.
이 연산은 개념적으로 LLM-CFG와 유사하다. 이미지 콘텐츠에 기반한 출력과 언어 논리에 기반한 출력 사이에서 정보에 입각한 선택을 할 수 있도록 하는 가이드를 모델에 제공한다. 이런 방식으로 모델은 출력에서 시각적 정보와 텍스트 정보의 영향을 더 잘 균형 있게 조정하여 맥락적으로 더 정확하고 관련성 있는 결과를 얻을 수 있다.
Experiments
- 구현 디테일
1. Results
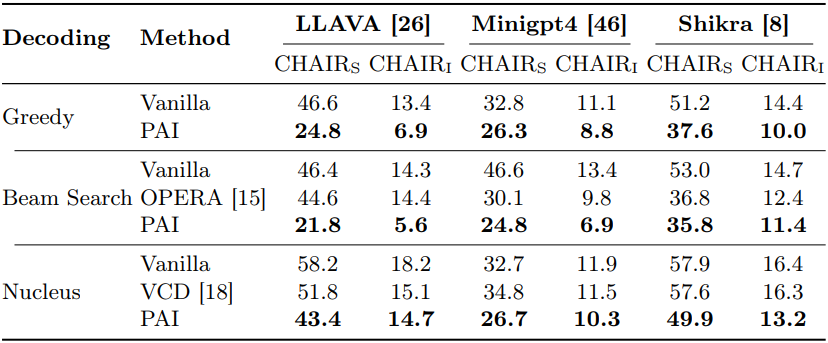
다음은 CHAIR로 hallucination을 평가한 결과이다.
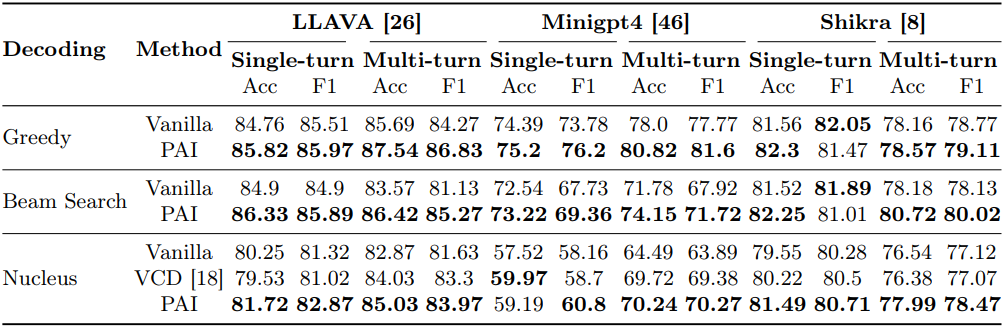
다음은 POPE로 hallucination을 평가한 결과이다.
다음은 MMHal-Bench에서의 정량적 평가 결과이다.
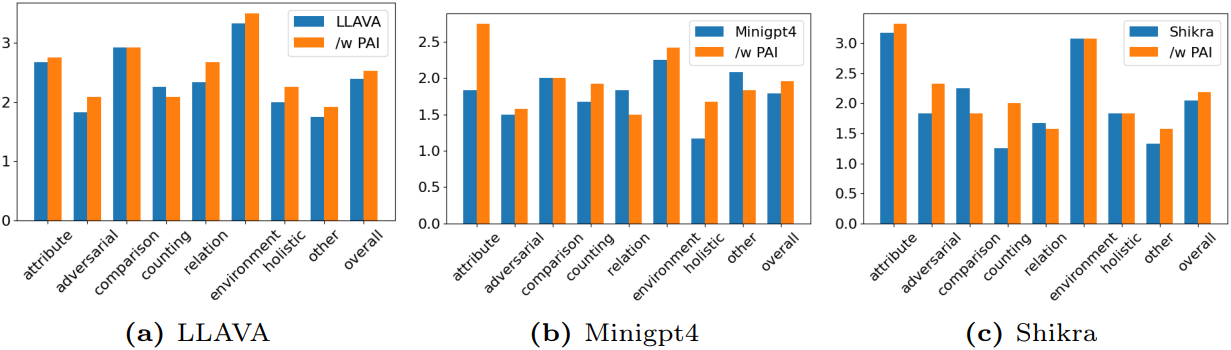
다음은 GPT-4V로 평가한 결과이다.

2. Ablation Study
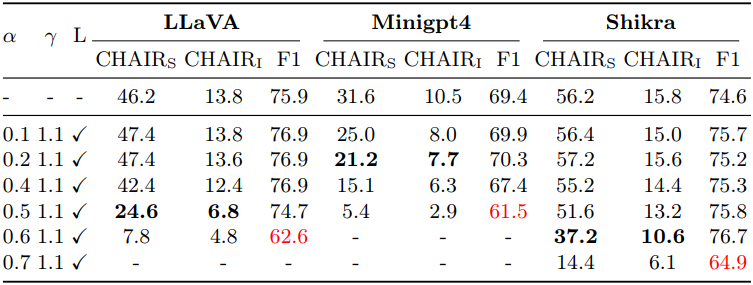
다음은 $\alpha$에 대한 ablation 결과이다. Layer prior $L$은 intervention을 위한 attention layer를 결정하는 데 사용된다.
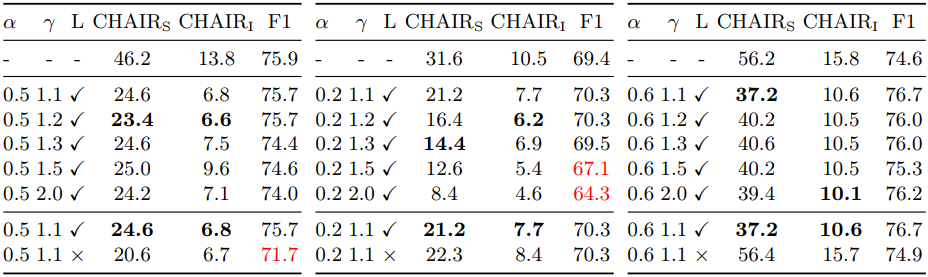
다음은 $\gamma$와 layer prior $L$에 대한 ablation 결과이다.
Limitation
- 기존 오픈소스 LMM의 언어 디코더는 주로 LLaMA 계열의 모델이다. LLaMA가 이미지 무시와 text inertia 문제를 도입하는지 여부는 확인되지 않았다.
- PAI는 inference 중에 이미지 무시 문제를 완화한다. 그 상한은 잘 학습된 모델의 역량에 따라 달라진다.