[논문리뷰] Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces (Paella)
arXiv 2022. [Paper] [Github]
Dominic Rampas, Pablo Pernias, Elea Zhong, Marc Aubreville
Technische Hochschule Ingolstadt, Wand Technologies Inc.
14 Nov 2022

Introduction
Text-to-image 생성에 대한 최근 연구는 생성된 이미지의 다양성, 품질, 베리에이션 측면에서 놀라운 발전을 가져왔다. 그러나 이러한 모델의 인상적인 출력 품질은 많은 샘플링 step이 필요하여 일반 사용자가 사용하는 데 적합하지 않은 느린 inference 속도로 이어지는 단점이 있다. 대부분의 최신 연구들은 diffusion model에 의존하거나 Transformer 기반이다. Transformer는 일반적으로 학습 전에 저차원 공간에 대한 공간 압축을 사용하는데, 이는 latent space 차원의 제곱에 비례하여 커지는 self-attention mechanism으로 인해 필요하다. 또한 Transformer는 인코딩된 이미지 토큰을 flattening하여 이미지를 1차원 시퀀스로 취급한다. 이는 이미지의 부자연스러운 projection이며 이미지의 2D 구조에 대한 이해를 학습하기 위해 훨씬 더 높은 모델 복잡성이 필요하다. Transformer의 autoregressive한 특성은 각 토큰을 한 번에 하나씩 샘플링해야 하므로 샘플링 시간이 길어지고 계산 비용이 높아진다. 반면 diffusion model은 픽셀 수준에서 효과적으로 학습할 수 있지만 기본적으로 엄청난 수의 샘플링 step이 필요하다.
본 논문에서는 Transformer 기반도 diffusion 기반도 아니지만 fully convolutional neural network 아키텍처를 활용하는 텍스트 조건부 이미지 생성을 위한 새로운 기술을 제안한다. 본 논문의 모델은 8 step으로 이미지를 샘플링할 수 있으며 여전히 높은 fidelity의 결과를 얻을 수 있으므로 시간 지연, 메모리 및 계산 복잡성에 대한 제한이 적다. 본 논문의 모델은 양자화된 latent space에서 작동하며 적당한 압축률로 인코딩 및 디코딩 프로세스에 Vector-quantized Generative Adversarial Network (VQGAN)을 사용한다. 이론적으로 모델의 convolutional한 특성으로 인해 훨씬 더 낮은 압축률을 사용할 수 있으며, 이는 제곱에 비례하는 메모리 증가와 같은 일반적인 Transformer 제한에 의해 제한되지 않는다. 압축률이 낮으면 높은 압축률로 작업할 때 일반적으로 손실되는 미세한 디테일을 보존할 수 있다.
학습하는 동안 VQGAN을 사용하여 이미지를 양자화하고 이미지 토큰에 random noise를 적용한다. 모델은 noise가 있는 이미지 토큰과 조건부 레이블이 주어지면 이미지 토큰을 재구성해야 한다. 새 이미지 샘플링은 반복적인 방식으로 발생하며 MaskGIT에서 영감을 받았지만 중요한 변경 사항이 있다. 그런 다음 모델은 이미지의 모든 토큰을 동시에 반복적으로 예측하지만 모델이 가장 확신하는 특정 수의 토큰만 유지하고 나머지 토큰은 다시 마스킹된다. 저자들은 이 절차가 샘플링 중 초기 step에서 모델이 자체적으로 예측을 수정하는 것을 허용하지 않는다는 점에서 매우 제한적이라고 주장한다. 모델에 더 많은 유연성을 제공하기 위해 토큰을 마스킹하는 대신 랜덤하게 noise를 생성한다. 이를 통해 모델은 샘플링 과정에서 특정 토큰에 대한 예측을 구체화할 수 있다.
또한 unconditional한 학습을 랜덤하게 수행하는 Classifier-Free Guidance (CFG)를 사용하여 샘플링을 개선한다. 샘플링 프로세스를 개선하기 위해 Locally Typical Sampling (LTS)도 사용한다. 그리고 Contrastive Language-Image Pretraining (CLIP) 임베딩을 사용하여 텍스트 컨디셔닝을 가능하게 한다. 모델을 명시적인 prior에서 분리하고 계산 복잡성을 줄이는 텍스트 임베딩에 대해서만 학습한다.
모델은 fully convolutional이기 때문에 원칙적으로 모든 크기의 이미지를 생성할 수 있다. 이 속성은 한 번만 샘플링하면 되지만 이미지를 outpainting하는 데 사용할 수 있다. Transformer는 outpainting을 위해 더 큰 크기의 latent 해상도를 생성하기 위해 컨텍스트 창을 반복적으로 이동해야 하며, 이 경우 샘플링 시간이 제곱으로 증가한다. 이미지 outpainting 외에도 text-guided inpainting도 수행할 수 있다. 또한 이미지 임베딩에 대한 모델을 fine-tuning하여 다양한 이미지를 생성할 수 있으며, CLIP 임베딩을 사용하면 latent space interpolation을 할 수 있다.
Method
1. Token Predictor Optimization
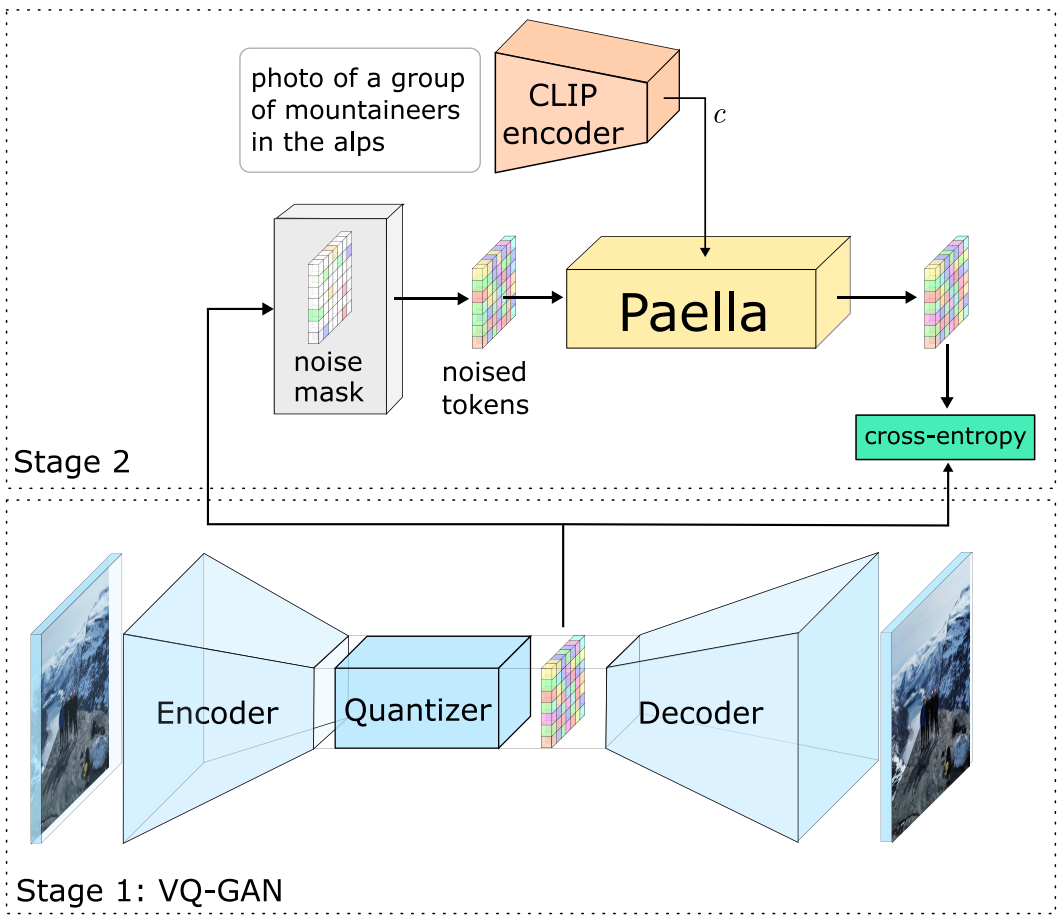
본 논문의 방법은 Taming Transformers for High-Resolution Image Synthesis 논문이 도입한 2단계 패러다임을 기반으로 한다. 위 그림과 같이 고차원 이미지를 저차원 latent space로 poject하기 위한 VQGAN으로 구성된다. 구체적으로 인코더는 $H \times W \times C$의 기본 해상도에서 이미지를 가져와 $h \times w \times z$의 해상도의 latent 표현 $u$에 매핑한다 ($h = H/f, w = W/f$). 여기서 f는 압축률이다. 그 다음에 양자화 단계가 이어지며 각 벡터를 크기 $N$의 학습된 codebook $Q \in \mathbb{R}^{N \times z}$에서 nearest neighbour로 대체한다. 그 후, 입력 이미지를 재구성하려고 시도하는 디코더에 양자화된 표현이 제공된다. 본 논문은 $f = 8$ 압축과 256$\times$256$\times$3의 기본 해상도로 사전 학습된 VQGAN을 사용하여 이미지를 32$\times$32$\times$256의 latent 해상도로 매핑핱다.
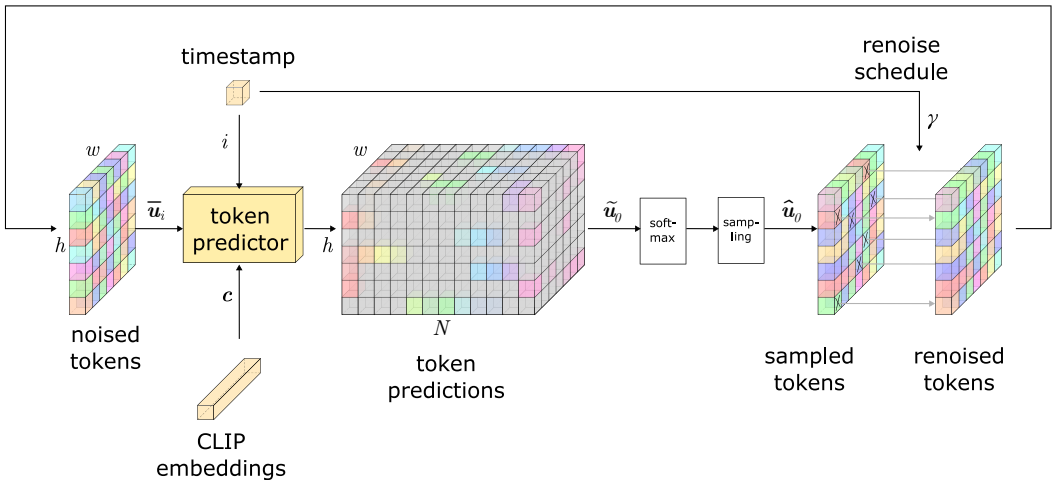
두 번째 단계는 저차원 latent space에서 이미지의 토큰 분포를 학습한다. 학습 중에 위 그림과 같이 토큰의 일부를 codebook에서 임의로 선택한 다른 토큰으로 랜덤하게 교체하여 인코딩되고 양자화된 이미지의 latent 토큰에 noise를 발생시킨다. Noise가 있는 토큰의 정확한 양은 scheduling function $\gamma$에 의해 MaskGIT과 같이 결정된다. MaskGIT처럼 cosine schedule $s(t) \in (0, 1]$도 사용한다. 학습에서 각 이미지에 대해 랜덤한 $t ∼ \mathcal{U}(0, 1)$를 샘플링하고 noise가 발생할 토큰의 백분율을 반환하는 스케줄 $s(t)$을 얻는다. 그런 다음 마스크의 각 위치에 대한 확률이 $s(t)$인 베르누이 분포를 사용하여 $m_{x,y}$ 요소로 이루어진 binary noise mask $m$을 샘플링한다. 좌표 $(x, y)$에서 토큰 \(\bar{u}_{x,y}\)는 균일 분포 $n_{x,y} \sim \mathcal{U} (0, N − 1)$에서 다음과 같이 샘플링된다.
그런 다음 noise가 있는 이미지 표현 $\bar{u}$는 timestep $t$와 조건 $c$와 함께 토큰 예측 모델 $f_\theta$에 공급된다. 저자들은 diffusion model에서와 같이 이미지에 noise가 얼마나 존재하고 얼마나 제거될 것으로 예상되는지에 대한 명확한 정보 소스를 모델에 제공하기 위해 모델의 입력에 현재 timestep을 포함하기로 결정했다. 또한 linear projection을 통해 모든 layer에 포함하는 이 추가 정보에 대해 모델을 조정한다. 클래스 레이블 또는 semantic segmentation map과 같은 모든 조건이 포함될 수 있지만 CLIP 임베딩에서 모델을 컨디셔닝하기로 결정했다. 노이즈 인덱스, timestep 임베딩, CLIP 임베딩은 noise 없는 토큰을 예측하는 token predictor 모델에 대한 입력으로 제공되어 예측 $\tilde{u} \in \mathbb{R}^{h \times w \times N}$를 생성한다.
\[\begin{equation} \tilde{u} = f_\theta (\bar{u}, c, t) \end{equation}\]Token predictor는 label smoothing을 사용한 cross-entropy로 최적화된다.
2. Sampling
단일 step의 샘플링이 기술적으로 가능하지만 이 절차는 목적 함수와 적절하게 일치하지 않는다. 따라서 저자들은 샘플링에 반복적인 접근 방식을 사용하기로 결정했다. $u_T \in \mathbb{N}_0^{h \times w}$를 각 값이 codebook의 랜덤 토큰인 latent image라고 한다. 또한, $t = [t_T, \cdots, t_1]$를 $t_T = 1$ (완전히 noise가 있음)과 $t_1 = 1/T$ (거의 noise가 없음)에서 시작하는 timestep의 시퀀스라고 하고, $T$는 샘플링 step의 수라 한다. 또한, $c \in \mathbb{R}^d$는 CLIP 임베딩을 나타낸다. 샘플링은 반복적인 방식으로 수행되며 각 iteration에서 다음 step이 실행된다.
- 현재 timestep $i \in t$, 입력 $u_i$의 latent space 표현, 임베딩 $c$가 denoising model에 입력으로 주어지면 모든 토큰을 동시에 예측하여 전체 latent image에 대한 각 codebook index에 대한 점수를 생성한다. 구체적으로, 입력 $u_i$를 입력하면 출력 $\tilde{u}_0$는 $h \times w \times N$의 모양을 갖는다. 여기서 $N$은 codebook의 item 수이다.
- 그런 다음 softmax 함수를 적용하여 모든 점수를 latent image의 각 토큰에 대한 확률 분포로 변환한다. 그런 다음 확률에 따라 multinomial sampling을 사용하여 각 분포에서 하나의 토큰을 샘플링한다. 결과 $\hat{u}_0$의 모양은 $h \times w$이다.
- 샘플링된 모든 토큰의 일정 비율을 랜덤하게 초기 noise codebook 값 $u_T$로 되돌린다. 이 비율은 현재 timestep $i$에 의해 결정된다.
랜덤하게 noise를 재조정하지 않고 처음에 샘플링된 원래 noise token을 사용한다. 저자들은 이것이 더 강력한 출력으로 이어지는 것을 발견했다. 또한 신뢰도가 가장 낮은 토큰을 renoise하지 않고 가장 높은 점수를 가진 토큰을 유지한다. 이것이 모델의 성능을 향상시키는 것으로 밝혀지지 않았기 때문이다. 대신 단순성을 위해 랜덤하게 토큰을 renoise한다.
또한 샘플링 프로세스를 개선하기 위해 두 가지 테크닉을 더 사용한다. 첫 번째는 classifier-free guidance(CFG)이다. CFG의 경우 학습에 null label을 도입한다. 샘플링하는 동안 null label로 한 번, CLIP 임베딩을 조건으로 한 번 샘플링한다. 그런 다음 두 임베딩을 다음과 같이 선형 결합한다.
\[\begin{equation} u_t = u_{t, \emptyset} + w \cdot (u_{t,c} - u_{t, \emptyset}) \end{equation}\]여기서 $w$는 조건부 샘플로 끌어당기는 정도를 결정하는 classifier weight이다. 두 번째 개선점은 자연어 처리에서 매우 성공적인 것으로 나타난 LTS이다. 주요 아이디어는 정보 이론에서 영감을 얻었으며 높은 확률의 이벤트가 높은 정보 콘텐츠를 유도하지 않는다고 말한다. 대신 정보 콘텐츠가 조건부 엔트로피에 가까운 확률 분포 영역에서 샘플링하는 것을 제안한다.
3. Token Predictor Architecture
MaskGIT은 이미지 합성 task에 양방향 Transformer를 사용한다. 저자들은 여기에 두 가지 주요 제한 요소가 있다고 주장한다.
- Transformer를 사용하려면 이미지를 평평한 1D 시퀀스로 처리해야 한다. 이는 이미지의 부자연스러운 projection이며 2D 구조는 먼저 positional embedding을 통해 학습해야 하기 때문에 학습 중에 근본적인 단점을 부여할 수 있다.
- 제곱으로 증가하는 메모리는 Transformer를 작은 latent space 해상도로 제한하므로 높은 압축률이 필요하다. 또한 autoregressive model은 최적으로 작동하고 큰 context window를 갖기 위해 Transformer 아키텍처에 의존하지만 학습 및 샘플링 설정에는 더 이상 Transformer가 필요하지 않으며 convolutional model로 대체할 수 있다.
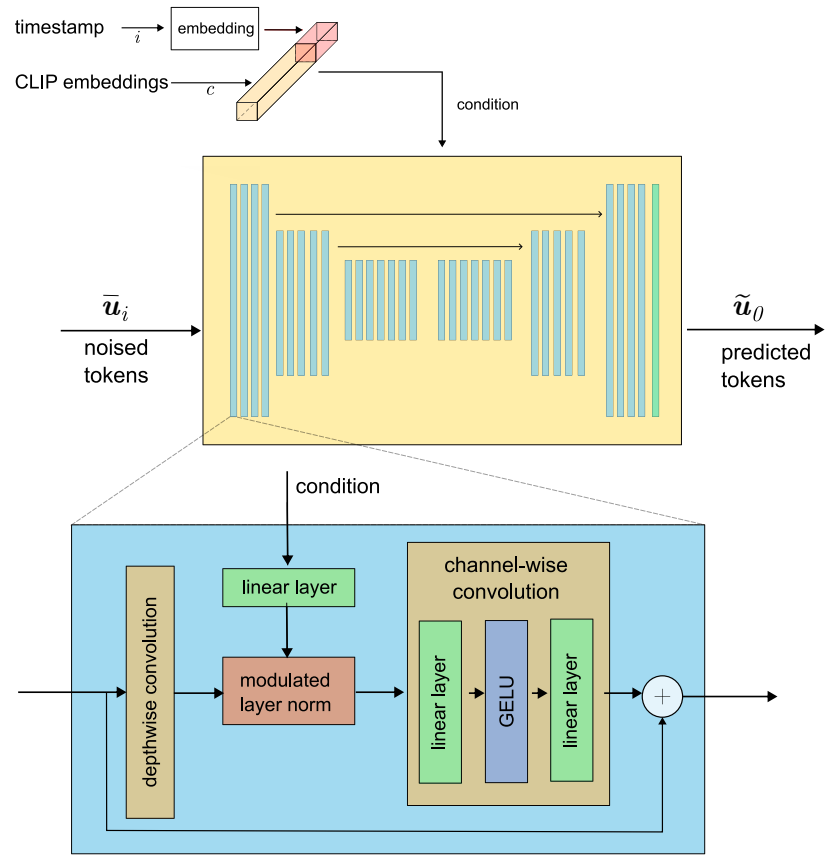
본 논문의 아키텍처는 fully convolutional이며 residual block을 활용하는 U-Net 스타일 인코더-디코더 구조로 구성된다. Latent image 옆에 있는 모든 block은 CLIP embedding과 timestep embedding을 받는다. 표준 2D convolution을 사용하는 대신 훨씬 빠르고 훨씬 적은 메모리를 사용하는 depthwise convolution을 사용한다. 또한 각 block에는 두 조건부 embedding을 latent 차원에 매핑하는 linear projection도 포함되어 있다. 그런 다음 조건부 정보를 주입하고 modulate하는 게이트웨이 역할을 하는 modulate된 LayerNorm을 사용한다. 그 다음에는 GELU activation을 통해 결합된 두 개의 fully connected layer로 구성된 channelwise convolution이 이어진다. 마지막으로 학습된 상수로 activation을 확장하고 residual connection을 추가한다. 위 그림은 아키텍처를 시각적으로 보여준다. 아키텍처는 attention을 사용하지도 않고 광범위한 정규화를 적용하지도 않아 모델을 빠르고 메모리 효율적으로 만든다.
Experiments
저자들은 최종 모델을 학습시키기 전에 몇 가지 소규모 실험을 수행했다. 적합하고 효율적인 아키텍처를 찾기 위해 더 작은 latent space 크기, 더 적은 모델 파라미터, 더 작은 데이터셋에 대해 학습시켰다. 이러한 초기 실험 후 Paella라고 하는 전체 모델을 학습시켰다. 저자들은 ablation study를 통해 모든 디자인 선택을 경험적으로 근거를 두고 텍스트 조건부 이미지 합성을 수행한다.
1. Architectural Search
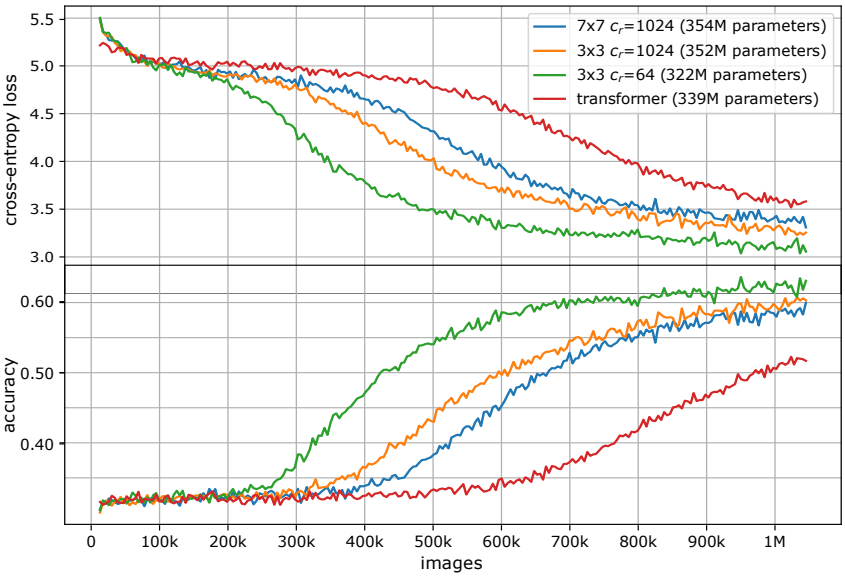
다음은 다양한 convolutional kernel configuration과 Transformer를 token predictor로 사용할 때의 정확도와 loss를 나타낸 그래프이다.
2. Text-Conditional Image Synthesis
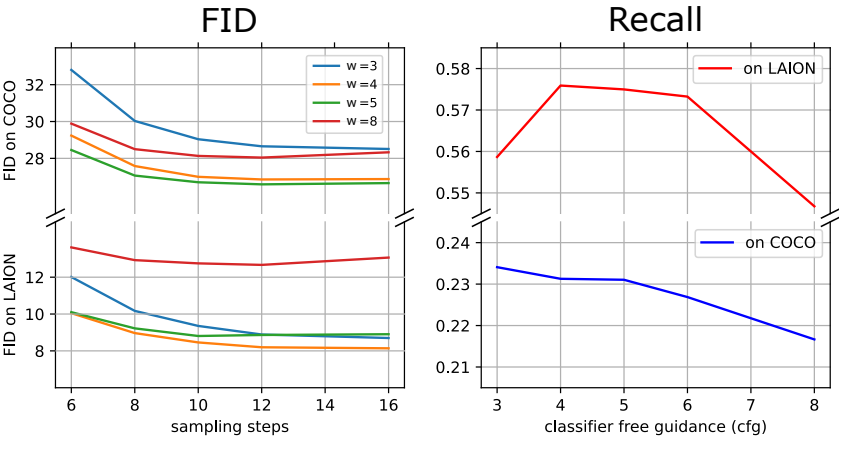
다음은 zero-shot FID와 classifier-free guidance weight $w$ (왼쪽), recall (오른쪽)을 각각 비교한 그래프이다.
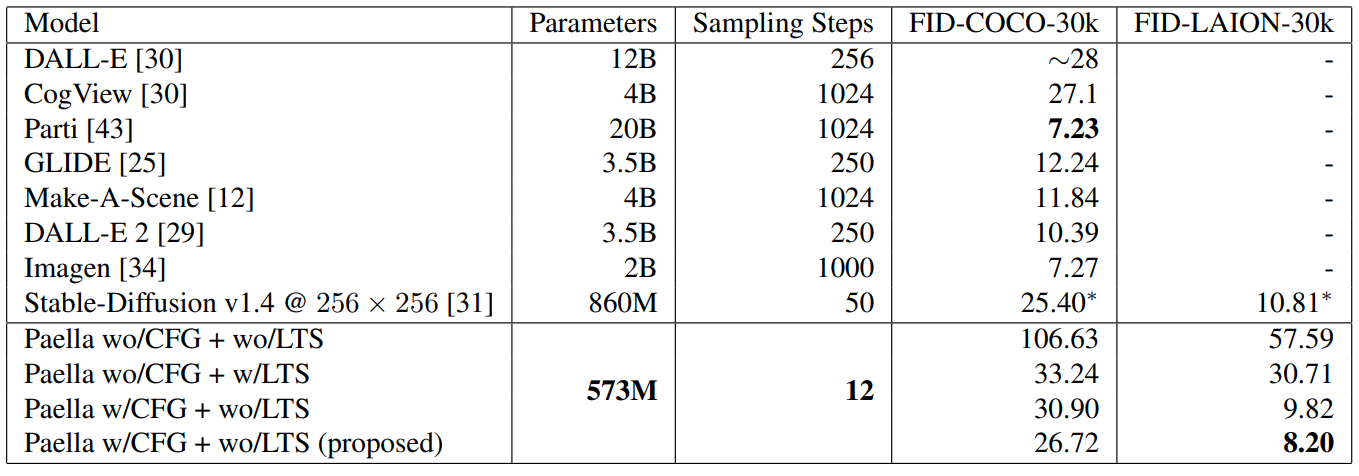
다음은 다른 state-of-the-art text-to-image 방법과 Paella의 ablation study를 함께 비교한 것이다.
CFG와 LTS를 사용하는 것이 굉장히 가치있으며 상당한 성능 개선을 가져오는 것을 볼 수 있다.
다음은 Paella의 inference 시간과 batch size에 대한 그래프이다.

3. Image Manipulations
Image Variations
다음은 Paella를 이미지 임베딩으로 fine-tuning한 결과이다. 가장 왼쪽의 이미지가 ground-truth이고 인접한 이미지들이 생성된 베리에이션이다.

Image Inpainting & Outpainting
다음은 outpainting 이미지의 샘플들이다.

다음은 inpainting된 예시 이미지이다. 텍스트 프롬프트를 조건으로 점선 사각형이 새로 채워진다.

Latent Space Interpolation
다음은 CLIP embedding space에서 서로 다른 캡션 간의 linear interpolation 결과이다.

Structural Editing
Structural Editing은 전체 색상과 모양을 유지하면서 이미지 내용을 의미론적으로 변경하는 것을 말한다. 다음은 structural editing의 예시들이다.

Multi-Conditioning
다음은 단일 sampling cycle에서 다양한 텍스트 프롬프트에 대한 컨디셔닝 생성이다. 점선은 서로 다른 텍스트 조건을 구분한다.
