[논문리뷰] Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP (OVSeg)
CVPR 2023. [Paper] [Page] [Github]
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiaolong Wang, Shalini De Mello
The University of Texas at Austin | Meta Reality Labs | Cruise
9 Oct 2022
Introduction
Semantic segmentation은 픽셀을 해당 semantic 카테고리에 따라 의미 있는 영역으로 그룹화하는 것을 목표로 한다. 눈에 띄는 발전이 있었음에도 불구하고 현대의 semantic segmentation 모델은 주로 미리 정의된 카테고리를 사용하여 학습되므로 처음 보는 클래스로 일반화하는 데 실패한다. 반대로 인간은 일반적으로 수천 개의 카테고리로 구성된 open-vocabulary 방식으로 장면을 이해한다. 인간 수준의 인식에 접근하기 위해 본 논문에서는 모델이 텍스트로 설명되는 임의의 카테고리로 이미지를 분할하는 open-vocabulary semantic segmentation을 연구하였다.
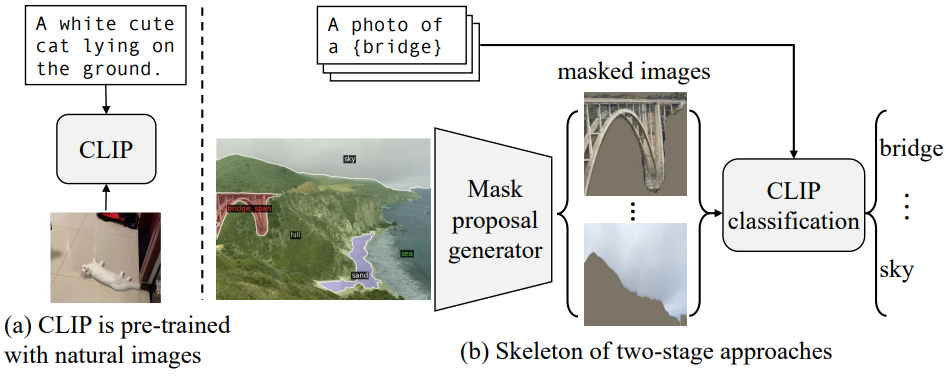
CLIP과 같은 비전-언어 모델은 수십억 규모의 이미지-텍스트 쌍에서 풍부한 멀티모달 feature를 학습한다. 뛰어난 open-vocabulary 분류 능력을 목격한 이전 연구에서는 open-vocabulary segmentation을 위해 사전 학습된 비전-언어 모델을 사용할 것을 제안했다. 그 중 2단계 접근 방식은 큰 잠재력을 보여주었다. 먼저 클래스에 구애받지 않는 마스크 proposal을 생성한 다음 사전 학습된 CLIP을 활용하여 open-vocabulary 분류를 수행한다. 이 접근 방식의 성공은 두 가지 가정에 달려 있다.
- 모델은 클래스에 구애받지 않는 마스크 proposal을 생성할 수 있다.
- 사전 학습된 CLIP은 분류 성능을 마스크된 이미지 proposal으로 전송할 수 있다.
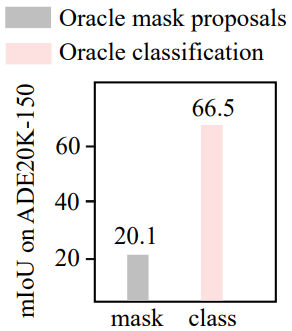
저자들은 이 두 가지 가정을 조사하기 위해 다음 분석을 수행하였다. 먼저 “oracle” 마스크 generator와 일반적인 CLIP classifier라고 가정한다. 실제 마스크를 영역 proposal로 사용하고 분류를 위해 사전 학습된 CLIP에 마스킹된 이미지를 공급한다. 이 모델은 ADE20K-150 데이터셋에서 20.1%의 mIoU에만 도달한다. 다음으로, “oracle” classifier와 일반적인 마스크 proposal generator라고 가정한다. 먼저 마스킹된 영역 proposal을 추출한 다음 각 영역을 실제 객체 마스크와 비교하고 가장 많이 겹치는 객체를 찾은 다음 추출된 영역에 객체 레이블을 할당한다. 불완전한 영역 proposal에도 불구하고 이 모델은 66.5%라는 상당히 높은 mIoU에 도달한다.
이 분석은 사전 학습된 CLIP이 마스킹된 이미지에 대해 만족스러운 분류를 수행할 수 없으며 이는 2단계 open-vocabulary segmentation 모델의 성능 병목 현상임을 분명히 보여준다. 저자들은 이것이 마스킹된 이미지와 CLIP의 학습 이미지 사이의 상당한 도메인 차이로 인해 발생한다고 가정하였다. CLIP은 최소한의 data augmentation으로 자연 이미지에 대해 사전 학습되었다. 반면에 마스크 proposal은 원본 이미지에서 잘리고 크기 조정되며 잡음이 있는 분할 마스크로 인해 더욱 손상된다.
본 논문은 이 문제를 해결하기 위해 마스킹된 이미지와 해당 텍스트 레이블을 fine-tuning하여 CLIP을 적용할 것을 제안한다. 한 가지 직접적인 해결책은 예를 들어 COCO-Stuff 데이터셋의 분할 레이블을 사용하는 것이다. 그러나 이는 처음 보는 클래스에 대한 잘못된 일반화로 이어진다. 이러한 수동으로 주석이 달린 마스크는 정확하지만 클래스는 닫힌 집합으로 제한된다. 저자들은 텍스트 다양성의 부족으로 인해 fine-tuning된 CLIP이 open-vocabulary 개념을 일반화 능력을 상실하게 된다고 가정하였다. 대신 기존 이미지 캡션 데이터셋을 마이닝하여 학습 데이터를 수집한다. 이미지-캡션 쌍이 주어지면 먼저 캡션에서 명사를 추출하고 사전 학습된 분할 모델을 사용하여 클래스에 구애받지 않는 마스크 영역 proposal을 생성한다. 그런 다음 사전 학습된 CLIP 모델을 사용하여 추출된 각 명사에 가장 일치하는 proposal을 할당한다. 마스킹된 이미지와 새로운 카테고리 사이의 weak supervision 정렬을 통해 학습함으로써 적응된 CLIP은 open-vocabulary segmentation에 대한 일반화 능력을 더 잘 유지한다.
다음 질문은 CLIP을 효과적으로 fine-tuning하는 방법이다. 마스킹된 이미지와 자연 이미지의 가장 눈에 띄는 차이점은 마스킹된 이미지의 배경 픽셀이 마스킹되어 많은 공백 영역이 생기고 CLIP transformer에 공급할 때 “zero token”으로 변환된다는 것이다. 이러한 토큰은 유용한 정보를 포함하지 않을 뿐만 아니라 모델에 도메인 분포 이동을 가져오고 (이러한 토큰은 자연 이미지에 존재하지 않기 때문에) 성능 저하를 유발한다. 본 논문은 이를 완화하기 위해 마스크 프롬프트 튜닝을 제안한다. 마스킹된 이미지를 토큰화할 때 “zero token”을 학습 가능한 프롬프트 토큰으로 대체한다. Fine-tuning하는 동안 프롬프트만 학습하고 CLIP의 가중치를 고정하거나 둘 다 학습한다. 마스크 프롬프트 튜닝만으로도 마스킹된 이미지에 대한 CLIP의 성능이 크게 향상되는 것으로 나타났다. 이는 다른 task와 공유되므로 CLIP의 가중치를 변경할 수 없는 multi-task 시나리오에 중요한 속성이다. 전체 모델 fine-tuning과 결합하면 마스크 프롬프트 튜닝이 적지 않은 차이로 성능을 더욱 향상시킬 수 있다.
Method
1. Two-stage models for open-vocabulary semantic segmentation
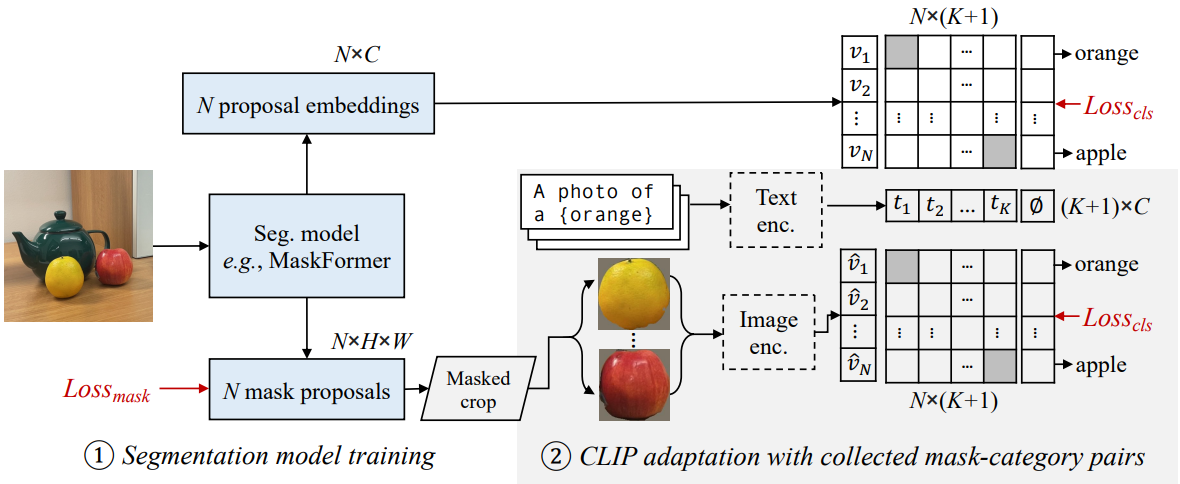
본 논문의 2단계 open-vocabulary semantic segmentation 모델은 위 그림에 나와 있다. 이는 마스크 proposal을 생성하는 분할 모델과 open-vocabulary 분류 모델로 구성된다.
저자들은 분할 모델로 MaskFormer를 선택하였다. 픽셀별 분할 모델과 달리 MaskFormer는 $N$개의 마스크 proposal 집합과 해당 클래스 예측을 예측한다. 각 proposal은 대상 객체의 위치를 나타내는 $H \times W$ 이진 마스크로 표시된다. 클래스 예측은 $C$차원 분포이며, 여기서 $C$는 학습 세트의 클래스 수이다. 다음으로 각 마스크에 대해 $C$차원 proposal 임베딩을 생성하도록 MaskFormer를 수정한다. 여기서 $C$는 CLIP 모델의 임베딩 차원 (ViT-B/16의 경우 512, ViT-L/14의 경우 768)이다. 이 변경을 통해 MaskFormer는 open-vocabulary segmentation을 수행할 수 있다.
구체적으로 마스크를 $K$개의 카테고리로 분류하고 싶다고 가정하면 먼저 CLIP 모델의 텍스트 인코더를 사용하여 각 클래스에 대한 $K$개의 텍스트 임베딩을 \(\{t_k \vert t_k \in \mathbb{R}^C\}_{k=1,\ldots,K}\)로 생성할 수 있다. 다음으로 각 마스크 임베딩 $v_i$를 텍스트 임베딩과 비교하고 클래스 $k$의 확률을
\[\begin{equation} p_{i,k} = \exp(\sigma(v_i, t_k) / \tau) / \sum_k (\exp(\sigma(v_i, t_k) / \tau)) \end{equation}\]로 예측한다. 여기서 $\sigma(\cdot,\cdot)$는 두 임베딩 벡터 간의 코사인 유사도이며, $\tau$는 temperature 계수이다. 저자들은 171개의 클래스가 있는 COCO-Stuff 데이터셋에서 수정된 MaskFormer를 학습시켰다. CLIP의 텍스트 인코더를 사용하여 클래스 이름을 처리하여 텍스트 임베딩을 생성한다. 또한 “객체 없음” 카테고리를 나타내기 위해 학습 가능한 임베딩 $\varnothing$을 추가한다. 다른 학습 설정의 경우 원래 MaskFormer를 따른다.
객체의 정의가 학습 세트의 클래스 정의에 의해 결정되기 때문에 이러한 방식으로 학습된 마스크 proposal generator는 엄격하게 “클래스 독립적”이 아니다. 예를 들어 학습 세트에 클래스로 “사람”만 포함된 경우 모델이 사람을 “얼굴”, “손”, “신체” 또는 더 미세한 신체 부위로 자동으로 분할할 가능성은 없다. 마스크 proposal을 생성하기 위해 일반 모델과 클래스 독립적인 모델을 학습하는 방법은 중요한 주제이지만 본 논문의 범위를 벗어난다.
MaskFormer의 예측 외에도 CLIP을 사용하여 병렬 예측 분기를 추가한다. MaskFormer는 마스크 proposal \(\{M_i \vert M_i \in \{0, 1\}^{H \times W}\}_{i=1,··· ,N}\)을 생성한다. 여기서 1과 0은 전경과 배경을 나타낸다. 각 마스크에 대해 모든 전경 픽셀을 포함하는 타이트한 bounding box를 선택하고, 이미지를 자르고, 배경을 마스크 처리하고, CLIP 해상도에 맞게 크기 조정한다. 마스크 proposal $i$를 CLIP에 공급하고 클래스 $k$의 확률을 \(\hat{p}_{i,k}\)로 계산한다. 두 가지 예측을 모두 앙상블하여 최종 예측을
\[\begin{equation} p_{i,k}^{(1 − \lambda)} \cdot \hat{p}_{i,k}^\lambda, \quad \textrm{where} \; \lambda \in [0, 1] \end{equation}\]로 계산한다. MaskFormer의 융합 모듈을 사용하여 마스크별 예측을 semantic segmentation에 융합한다.
CLIP은 이러한 마스킹된 이미지에서는 제대로 작동하지 않는 것으로 나타났다. 특히 CLIP은 data augmentation이 거의 없는 자연 이미지에 대해 학습된다. 그러나 마스킹된 이미지에는 “빈 영역”이 많이 포함되어 있다. 이러한 상당한 도메인 격차로 인해 CLIP이 분류 성능을 이전하기가 어렵다. 또한 저자들은 배경 픽셀을 가리지 않고 proposal을 잘라내는 시도도 했지만 성능이 더 나빴다. 배경 픽셀을 유지하면 CLIP이 전경을 올바르게 분류하는 것이 더 혼란스러워질 것이라고 추측할 수 있다.
2. Collecting diverse mask-category pairs from captions
본 논문은 마스킹된 이미지를 더 잘 처리하도록 CLIP을 적용하기 위해 마스킹된 이미지와 텍스트 쌍으로 구성된 데이터셋에서 CLIP을 fine-tuning할 것을 제안하였다. 한 가지 직접적인 해결책은 COCO-Stuff 등에서 수동으로 주석이 달린 분할 레이블을 활용하는 것이다. 이러한 레이블은 정확하지만 닫힌 카테고리 집합을 가지고 있다. 저자들은 이 솔루션을 시도하고 COCO-Stuff에서 171개 클래스에 걸쳐 96.5만 개의 마스크-카테고리 쌍을 수집하였다. 그런 다음 텍스트 인코더를 고정하면서 CLIP의 이미지 인코더를 fine-tuning하였다. 그러나 처음 보는 클래스가 더 많으면 성능이 떨어지기 때문에 이러한 순진한 접근 방식이 CLIP의 일반화 능력을 제한한다. 저자들은 제한된 텍스트 vocabulary로 인해 fine-tuning된 CLIP이 171개 클래스에 overfitting되어 처음 보는 카테고리로 일반화하는 능력을 상실한다고 가정하였다.
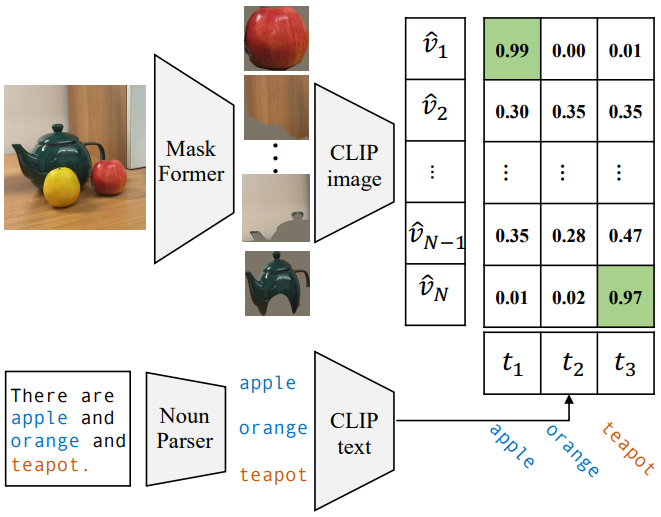
분할 레이블과 비교하여 이미지 캡션에는 이미지에 대한 훨씬 더 풍부한 정보가 포함되어 있으며 훨씬 더 많은 vocabulary가 포함된다. 예를 들어, 위 그림에서 이미지 캡션은 “There are apple and orange
and teapot.”이다. “apple”과 “orange”는 COCO-Stuff에서 유효한 클래스이지만 “teapot”은 유효한 클래스가 아니므로 무시된다.
이 관찰을 바탕으로 저자들은 마스크-카테고리 쌍을 추출하는 자체 레이블링 전략을 설계했다. 위 그림에서와 같이 이미지가 주어지면 먼저 사전 학습된 MaskFormer를 사용하여 마스킹된 proposal을 추출한다. 한편, 해당 이미지 캡션에서 기성 언어 파서를 사용하여 모든 명사를 추출하고 이를 잠재적 클래스로 처리한다. 그런 다음 CLIP을 사용하여 가장 일치하는 마스크 proposal을 각 클래스에 연결한다. COCO-Captions에서 이미지당 5개의 캡션을 사용하여 2.7만 개의 고유 명사와 함께 130만 개의 마스크-카테고리 쌍을 수집하거나 이미지당 1개의 캡션을 사용하여 1.2만 개의 명사와 44만 개의 쌍을 수집한다. 실험에 따르면 이 다양한 마스크-카테고리 데이터셋이 수동 분할 레이블보다 훨씬 더 나은 성능을 제공하는 것으로 나타났다.
3. Mask prompt tuning
데이터셋을 수집한 후, CLIP을 효과적으로 fine-tuning하는 방법에 대한 자연스러운 질문이 발생한다. 마스킹된 이미지와 자연 이미지의 가장 눈에 띄는 차이점은 마스킹된 이미지의 배경 픽셀이 0으로 설정되어 “빈 영역”이 많이 발생한다는 것이다. 마스킹된 이미지를 CLIP에 공급하면 이미지가 겹치지 않는 패치로 분할된 후 토큰화된다. 그러면 해당 빈 영역은 zero token이 된다. 이러한 토큰은 유용한 정보를 포함하지 않을 뿐만 아니라 모델에 도메인 분포 이동을 가져오고 (이러한 토큰은 자연 이미지에 존재하지 않기 때문에) 성능 저하를 유발한다.

이를 완화하기 위해 본 논문은 마스크 프롬프트 튜닝이라는 기술을 제안한다. 구체적으로 CLIP에 입력할 때 마스킹된 이미지는 텐서 $T \in \mathbb{R}^{N_p \times E}$로 토큰화된다. 여기서 $N_p$는 패치 수이고 $E$는 토큰 차원이다. 마스킹된 이미지에는 압축된 이진 마스크 \(M_p \in \{0, 1\}^{N_p}\)도 함께 제공된다. 여기서 각 요소는 주어진 패치가 유지되는지 또는 마스크 해제되는지 여부를 나타낸다. 패치 내의 모든 픽셀이 완전히 마스킹된 경우에만 패치가 마스킹된 토큰으로 처리된다. 일반적으로 부분적으로 마스킹된 패치에 존재하는 경계 픽셀이 영역 분류에 중요하다는 것이 직관이다. 프롬프트 토큰을 나타내는 학습 가능한 텐서를 $P \in \mathbb{R}^{N_p \times E}$로 할당한다. 마지막으로 transformer에 대한 최종 입력은 $T \otimes M_p + P \otimes (1 − M_p)$로 계산된다. 여기서 $\otimes$는 element-wise 곱셈을 나타낸다. Visual prompt tuning의 “deep prompt”를 따라 transformer의 더 깊은 레이어에 이러한 프롬프트 토큰을 추가할 수 있다.
전체 모델을 완전히 fine-tuning하는 것과 비교하여 마스크 프롬프트 튜닝에는 몇 가지 장점이 있다.
- 입력 이미지의 일부가 마스킹되는 segmentation task를 위해 특별히 설계되었다.
- 마스크 프롬프트 튜닝의 학습 가능한 파라미터의 양이 훨씬 작아서 학습 효율성이 훨씬 향상된다.
- Foundational model로서 CLIP은 여러 task에 동시에 사용될 수 있으며 CLIP의 가중치를 튜닝하는 것이 허용되지 않을 수도 있다. 마스크 프롬프트 튜닝에는 CLIP의 가중치 변경이 필요하지 않으므로 이러한 multi-task 시나리오에 적합하다.
- 마스크 프롬프트 튜닝만으로도 상당한 개선이 가능하다. 그리고 전체 모델 fine-tuning과 함께 적용하면 open-vocabulary segmentation 성능을 더욱 향상시킬 수 있다.
Experiments
- 학습 데이터셋: COCO
- 구현 디테일
- 분할 모델
- backbone: Swin-Base (또는 ResNet-101c)
- backbone 가중치는 ImageNet-21K에서 사전 학습된 모델에서 초기화)
- optimizer: AdamW
- learning rate: $6 \times 10^{-5}$, poly scheduler
- weight decay: 0.01
- batch size: 32
- crop size: 640$\times$640
- iteration: 12만
- CLIP 모델: ViT-L/14 (또는 ViT-B/16)
- Open-CLIP 구현을 활용
- 세 가지 방법을 사용: 마스크 프롬프트 튜닝 (MPT)만, 전체 모델 fine-tuning (FT)만, 공동 MPT + FT
- MPT
- CLIP 모델을 초기화하고 학습 가능한 토큰을 무작위로 초기화
- [Visual prompt tuning]에서 제안한 대로 “deep prompt”를 사용 (프롬프트 깊이는 3)
- optimizer: AdamW
- learning rate: $2 \times 10^{-2}$, cosine annealing scheduler
- weight decay: 0
- 입력 크기 = 224$\times$224, epoch = 5, batch size = 256
- FT
- 비슷한 학습 절차를 유지
- learning rate: $5 \times 10^{-6}$, cosine annealing scheduler
- weight decay: 0.2
- MPT + FT
- 먼저 완전히 fine-tuning된 모델로 CLIP을 초기화한 다음 그 위에 마스크 프롬프트 튜닝을 적용
- 다른 모든 hyperparameter는 MPT에서만 동일
- CLIP의 텍스트 인코더는 모든 실험에서 고정
- 분할 모델
1. Main results on open vocabulary semantic segmentation
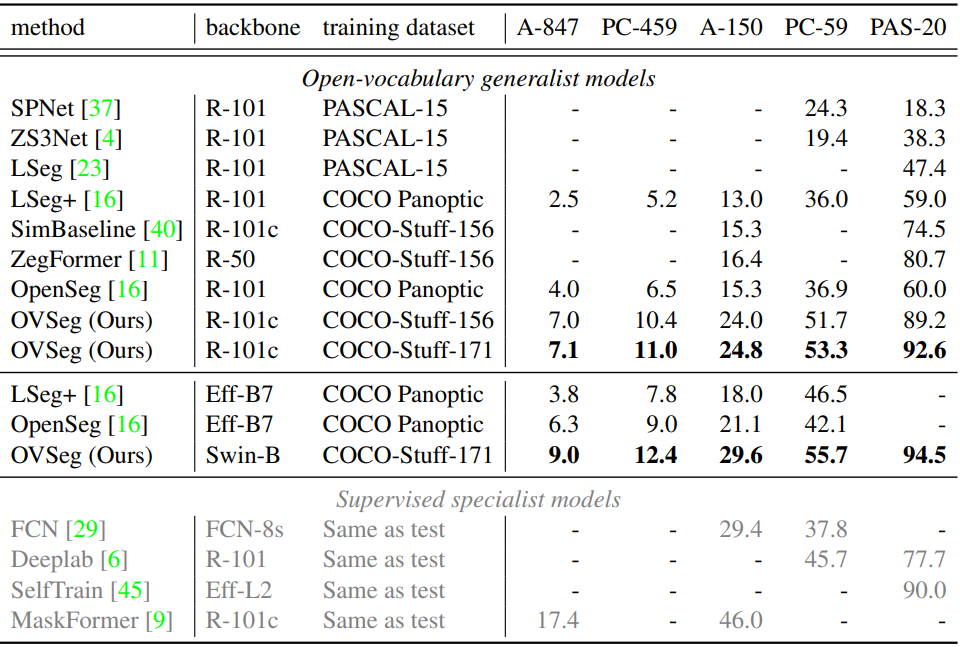
다음은 open-vocabulary 일반화 모델과 supervised 전문가 모델의 mIoU를 비교한 표이다.
2. Ablation study
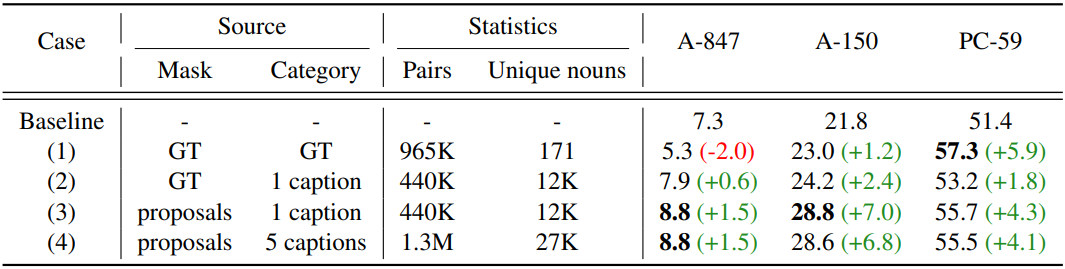
다음은 마스크-카테고리 쌍에 대한 ablation 결과이다.
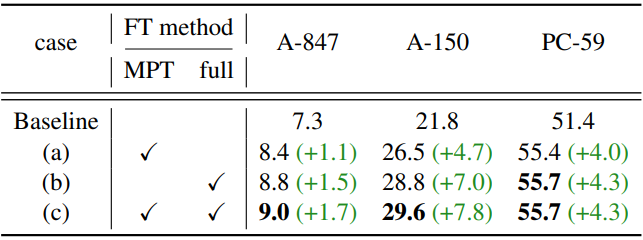
다음은 mask prompt tuning (MPT)과 전체 모델 튜닝에 대한 ablation 결과이다.
3. Discussions
다음은 사용자가 정의한 query에 대한 open-vocabulary segmentation 결과이다.

다음은 A-150 데이터셋의 일부 “실패” 예측 예시이다. Open vocabulary segmentation 평가에서 클래스 정의가 모호하다.
