[논문리뷰] Osprey: Pixel Understanding with Visual Instruction Tuning
CVPR 2024. [Paper] [Github]
Yuqian Yuan, Wentong Li, Jian Liu, Dongqi Tang, Xinjie Luo, Chi Qin, Lei Zhang, Jianke Zhu
Zhejiang University | Ant Group | Microsoft | The HongKong Polytechnical University
15 Dec 2023

Introduction
Large Multimodal Model (LMM)은 범용 어시스턴트의 핵심 구성 요소이다. 최근의 많은 LMM은 instruction-following 및 시각적 추론 능력에서 인상적인 결과를 보여주었지만 대부분 이미지-텍스트 쌍을 사용하여 image-level에서 비전-언어 정렬을 수행한다. Region-level 정렬이 부족하면 영역에 대한 분류, captioning, 추론과 같은 세밀한 이미지 이해가 어려워진다.
LMM에서 region-level 이해를 가능하게 하기 위해 일부 최근 연구에서는 bounding box 영역을 처리하고 object-level의 공간적 feature를 사용하여 visual instruction tuning을 활용하려고 시도했다. 그러나 sparse한 bounding box를 참조 입력 영역으로 직접 사용하면 관련 없는 배경이 포함될 수 있으며 LLM의 영역-텍스트 쌍 정렬이 부정확해질 수 있다. 추론 과정에서 box-level의 참조 입력은 물체를 정확하게 지시하지 못하여 semantic 편차가 발생할 수 있다. 게다가 이러한 모델들은 상대적으로 낮은 입력 이미지 해상도(224$\times$224)를 사용하기 때문에 dense한 영역의 디테일을 이해하는 데 어려움을 겪는다.
Bounding box 대신 세밀한 마스크를 참조 입력으로 사용하면 물체를 정확하게 표현할 수 있다. SAM은 간단한 bounding box 또는 점을 프롬프트로 사용하여 탁월한 zero-shot segmentation 품질을 보여주었다. 그러나 SAM은 자세한 semantic 속성과 캡션은 물론 기본 semantic 레이블도 제공할 수 없다. 결과적으로, 기존 방법으로는 세밀한 멀티모달 정보를 가지고 실제 장면을 이해하는 데 한계가 있다.
본 논문에서는 세밀한 픽셀 단위 이해를 위해 LMM의 능력을 확장하도록 설계된 Osprey를 제안하였다. 이를 위해 다양한 세분성으로 정확한 visual mask feature들을 캡처하는 mask-aware visual extractor를 제시하였다. 이러한 visual feature는 언어 명령과 함께 LLM에 대한 입력 시퀀스를 형성한다. 고해상도 입력의 사용을 용이하게 하기 위해 convolutional CLIP backbone을 비전 인코더로 사용한다. ViT 기반 모델과 비교하여 convolutional CLIP은 효율성과 robustness를 가지고 더 큰 입력 해상도로 잘 일반화된다. 이러한 디자인을 통해 Osprey는 part-level 및 object-level 영역에 대한 세밀한 semantic 이해를 달성하고 기본 물체 카테고리, 자세한 물체 속성, 보다 복잡한 장면 설명을 제공할 수 있다.
세밀한 pixel-level 비전-언어 정렬을 위해 저자들은 각 영역의 마스크와 텍스트 설명에 주의 깊게 주석이 달린 대규모 마스크 기반 영역 텍스트 데이터셋, 즉 Osprey-724K를 꼼꼼하게 선별하였다. 대부분의 데이터는 object-level 및 part-level 샘플을 포함하며, 명령을 따르도록 신중하게 설계된 프롬프트 템플릿을 사용하여 공개 데이터셋에서 제작된다. 상세한 설명과 대화뿐만 아니라 풍부한 속성 정보도 포함된다. 또한 네거티브 데이터 마이닝과 단답형 응답 명령을 도입하여 Osprey 응답의 robustness와 유연성을 더욱 향상시켰다.
Osprey는 기존의 box-level 및 image-level 이해를 뛰어넘는 새로운 능력을 제공한다. Osprey는 SAM의 마스크를 기반으로 세분화된 semantic을 생성할 수 있다.
Osprey-724K Dataset

저자들은 세부적인 pixel-level 이미지 이해를 위해 약 72.4만 개의 멀티모달 대화를 포함하는 마스크-텍스트 쌍이 있는 명령 데이터셋인 Osprey-724K를 제시하였다. Osprey-724K는 공개 데이터셋을 기반으로 생성된 object-level 및 part-level 마스크-텍스트 명령 데이터로 구성된다. Instruction-following 데이터를 만들기 위해 저자들은 GPT-4를 활용하여 신중하게 설계된 프롬프트 템플릿을 사용하여 고품질 마스크-텍스트 쌍을 생성하였다. 또한 응답의 robustness와 유연성을 향상시키기 위해 단답형 프롬프트를 사용하는 negative sample mining 방법을 도입하였다. Osprey-724K의 자세한 통계 및 분포는 아래에 나와 있다.

1. Object-level Instructions
$N$개의 물체 영역이 있는 이미지의 경우, COCO 및 RefCOCO/+/g와 같은 마스크 주석이 있는 공개 데이터셋을 기반으로 image-level 및 object-level 캡션을 최대한 활용하였다. 그러나 이러한 캡션들은 semantic 컨텍스트가 거의 없어 단순하고 짧으며 이는 LMM을 학습시키는 데 충분하지 않다.
저자들은 이 문제를 완화하기 위해 물체의 카테고리, 유형, 행동, 위치, 색상, 상태 등을 포함하여 세분화된 영역 기반 명령 데이터를 생성하는 데이터 처리 파이프라인을 만들었다. 먼저, COCO 이미지에 대한 image-level 설명으로 LLaVA-115K의 상세 설명을 사용한다. 그런 다음, GPT-4로 instruction-following 데이터를 생성하여 각 물체 영역의 다양성을 갖춘 시각적 콘텐츠를 생성한다. 특히 bounding box와 간략한 영역 캡션을 최대한 활용한다. 여기서 각 박스는 물체 개념과 장면에서의 공간적 위치를 인코딩한다. RefCOCO/+/g에서 수집된 짧은 캡션은 일반적으로 다양한 관점에서 특정 영역을 설명한다. 이러한 정보를 바탕으로 GPT-4를 사용하여 region-level의 ‘상세 설명’과 ‘대화’라는 두 가지 유형의 데이터를 생성하였다. 마지막으로 총 19.7만 개의 고유한 object-level instruction-following 샘플을 수집하였다.
2. Part-level Instructions
Part-level 지식을 포착하기 위해 저자들은 75개 물체 카테고리에 분산된 456개 물체별 파트 클래스를 포함하는 PACO-LVIS 데이터셋을 활용하였다. 구체적으로 PACO-LVIS는 29가지 색상, 10가지 패턴 및 마킹, 13가지 재료 및 3가지 반사율을 포함하여 55가지 속성으로 구성된다. 이러한 정보를 고려하여 GPT-4를 사용하여 QA 형식 대화를 통해 instruction-following 데이터를 구성하였다. 이러한 간단한 접근 방식은 파트 카테고리 및 속성의 다양성을 향상시킨다. 전체적으로 30.6만 개의 part-level instruction-following 샘플을 얻었다.
3. Robustness and Flexibility
Robustness. LMM은 hallucination 문제를 겪는다. 즉, 명령에 자주 나타나거나 다른 물체와 함께 나타나는 물체는 hallucination이 발생하기 쉽다. Robustness를 강화하기 위해 positive/negative 명령 샘플을 추가로 구성한다. 구체적으로, 특정 영역이 특정 카테고리에 속하는지 여부를 문의하고 “Yes/No”로 응답할 것으로 예상하는 쿼리를 사용한다. Positive/negative 샘플은 균형을 보장하기 위해 동일하게 고안되었다.
Negative sample mining은 공간 인식 및 클래스 인식 negative sample을 찾는 것을 목표로 한다. 전자의 경우, 모델이 주어진 물체에 공간적으로 가장 가까운 물체별 카테고리를 식별할 수 있다. 후자의 경우, 대상 클래스 이름과의 높은 semantic 유사도를 기반으로 negative 카테고리가 선택되며, SentenceBert로 semantic 유사도를 계산하는 데 사용된다. Negative 카테고리의 다양성을 높이기 위해 의미상 유사한 상위 8개 후보 중에서 하나의 카테고리를 무작위로 선택한다. 저자들은 마스크 주석이 있는 약 1,200개의 물체 카테고리를 포함하는 대규모 vocabulary 데이터셋인 LVIS에 이 방식을 적용했다.
Flexibility. 응답의 유연성을 향상시키기 위해 특정 물체 영역의 카테고리, 색상, 유형, 위치, 수량을 다루는 짧은 형식의 응답 명령을 추가한다. 저자들은 GPT-4를 사용하여 공개 데이터셋을 사용하여 명령 샘플을 생성하였으며, GPT-4가 하나의 단어나 구문으로 구성된 간결한 응답을 생성할 수 있을 것으로 기대하였다. 그러나 기존의 대화 기반 프롬프트는 원하는 출력 형식을 명시적으로 나타내지 않아 LLM이 짧은 형식의 답변에 overfitting될 가능성이 있다. 이 문제를 해결하기 위해 간단한 답변을 요청할 때 질문 끝에 명시적으로 짧은 형식의 응답 프롬프트를 추가하도록 한다.
Method of Osprey
1. Model Architecture
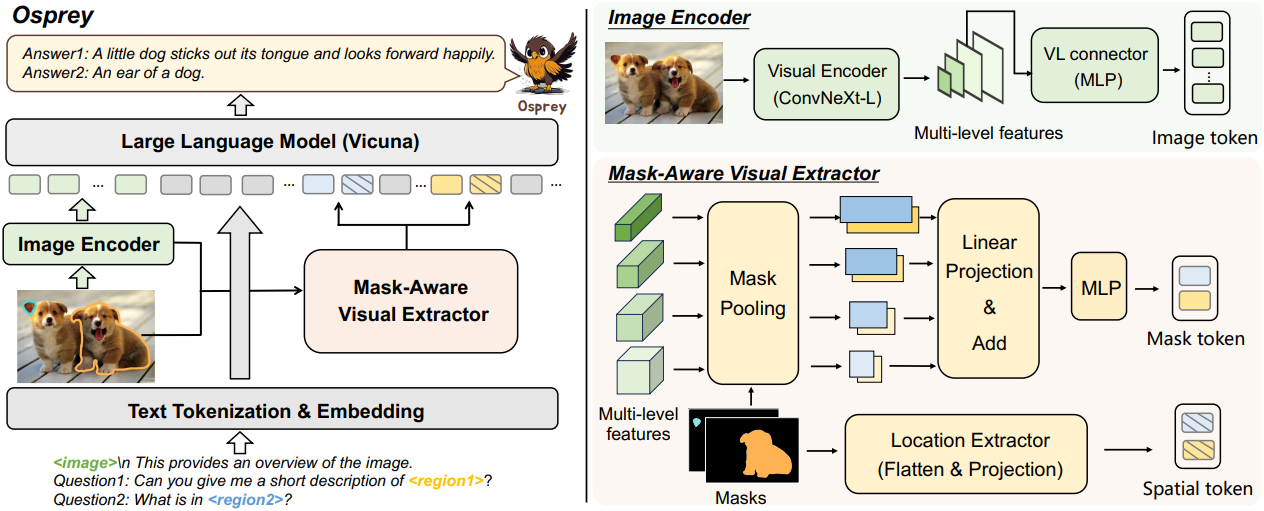
Osprey는 image-level vision encoder, pixel-level mask-aware visual extractor, LLM으로 구성된다. 이미지, 참조 마스크 영역, 입력 언어가 주어지면 tokenization 및 변환을 수행하여 임베딩을 얻는다. 그런 다음 인터리빙된 마스크 feature들과 언어 임베딩 시퀀스들이 LLM으로 전송되어 세밀한 semantic 이해를 얻는다.
Convolutional CLIP Vision Encoder
기존 LMM의 비전 인코더는 대부분 224$\times$224 또는 336$\times$336의 이미지 해상도를 채택하는 ViT 기반 CLIP 모델을 사용한다. 그러나 이러한 해상도는 특히 작은 영역에서 픽셀 레벨 표현으로 세밀한 이미지 이해를 달성하기 어렵게 만든다. 입력 이미지 해상도를 높이는 것은 ViT 아키텍처의 글로벌 attention과 관련된 계산 부담을 발생시킨다.
위의 문제를 완화하기 위해 ResNet이나 ConvNeXt와 같은 convolutional CLIP 모델을 비전 인코더로 도입한다. CNN 기반 convolutional CLIP은 ViT 기반 CLIP 모델과 비교하여 다양한 입력 해상도에 걸쳐 유망한 일반화 능력이 입증되었다. Convolutional CLIP를 사용하여 성능 저하 없이 효율적인 학습과 빠른 추론이 가능하다. 또한 CNN 기반 CLIP 비전 인코더로 생성된 멀티스케일 feature map은 각 물체 영역의 후속 feature 추출에 직접 활용될 수 있다.
저자들은 ConvNeXtLarge CLIP 모델을 비전 인코더로 선택하고 “res4” 단계의 출력을 image-level feature로 채택하였다.
Mask-Aware Visual Extractor
Osprey는 상세한 마스크 영역을 사용하여 세분화된 표현을 채택한다. 각 물체 영역의 pixel-level feature를 캡처하기 위해 mask-level visual feature를 인코딩할 뿐만 아니라 각 영역 \(\textbf{R}_i\)의 공간적 위치 정보를 수집하는 mask-aware visual extractor를 제안하였다.
먼저 비전 인코더 $\textbf{Z}$의 출력에서 얻은 multi-level 이미지 feature $\textbf{Z}(x)$를 기반으로 하는 마스크 풀링 연산 $\mathcal{MP}$를 채택한다. 각 레벨의 feature \(\textbf{Z}(x)_j\)에 대해 모든 feature를 풀링한다. 이는 다음과 같이 마스크 영역 \(\textbf{R}_i\) 내부에 해당한다.
\[\begin{equation} V_{ij} = \mathcal{MP} (\textbf{R}_i, \textbf{Z} (x)_j) \end{equation}\]그런 다음 여러 레벨에 걸쳐 feature를 인코딩하기 위해 linear projection layer \(\textbf{P}_j\)에 각 feature $V_{ij}$를 전달하여 동일한 차원의 region-level 임베딩을 생성하고 더해 multi-level feature를 융합한다. 다음과 같이 MLP 레이어 $\sigma$를 추가로 사용하여 visual mask token $t_i$를 생성한다.
\[\begin{equation} t_i = \sigma (\sum_{j=1}^4 \textbf{P}_j (V_{ij})) \end{equation}\]물체 영역의 공간적 형상을 보존하기 위해 각 물체 영역에 대해 바이너리 마스크 \(\textbf{M}^{H \times W} \in \{0, 1\}\)을 활용하여 pixel-level 위치 관계를 인코딩한다. 먼저 각 \(\textbf{M}_i\)를 224$\times$224로 resize한 다음 flatten하고 projection하여 spatial token $s_i$를 생성한다. 마지막으로 visual mask token $t_i$와 해당 spatial token $s_i$를 각 마스크 영역의 임베딩으로 통합한다.
LLM 모델을 위한 Tokenization
Image-level 임베딩을 추출하기 위해 사전 학습된 비전 인코더인 ConvNeXt-Large CLIP 모델에 이미지를 공급한다. 텍스트 정보의 경우 사전 학습된 LLM의 tokenizer를 사용하여 텍스트 시퀀스를 tokenize하고 이를 텍스트 임베딩에 projection한다. 마스크 기반 영역의 경우 특수 토큰을 placeholder <region>으로 정의한다. 이는 <mask> <position>으로 표시되는 spatial token $s$와 함께 mask token $t$로 대체된다. 텍스트 입력에서 물체 영역을 참조할 경우 "region1" 또는 "region2"와 같이 해당 영역 이름 뒤에 <region>이 추가된다. 이런 방식으로 마스크 영역은 텍스트와 잘 혼합되어 동일한 tokenization space를 가진 완전한 문장을 형성할 수 있다.
사용자 명령 외에도 "<image>\n This provides an overview of the picture."라는 접두사 프롬프트가 포함되어 있다. <image>는 비전 인코더의 image-level 임베딩으로 대체되는 placeholder 역할을 하는 특수 토큰이다. Image-level 및 region-level visual token과 텍스트 토큰은 함께 LLM에 공급되어 다양한 물체 영역의 이미지와 사용자 명령을 이해한다. 저자들은 LLM으로 Vicuna를 사용하였다.
2. Training
Osprey의 학습 과정은 세 단계로 구성되며, 모두 next-token prediction loss를 최소화하여 학습된다.
1단계: 이미지-텍스트 정렬 사전 학습. 먼저 convolutional CLIP 비전 인코더를 사용하여 이미지-텍스트 feature 정렬을 위해 image-level feature와 language connector를 학습시킨다. 이 단계에서 Osprey에는 사전 학습된 비전 인코더, 사전 학습된 LLM, image-level projector가 포함되어 있다. LLaVA-1.5를 따라 모델의 멀티모달 feature를 향상시키기 위해 connector로 MLP를 채택했다. LLaVA에 도입된 CC3M 데이터가 학습 데이터로 사용된다. 이 단계에서는 image-level projector만 학습되며, 비전 인코더와 LLM이 고정된다.
2단계: 마스크-텍스트 정렬 사전 학습. 1단계에서 학습된 가중치를 로드하고 Mask-Aware Visual Extractor를 추가하여 pixel-level region feature를 캡처한다. 이 단계에서는 마스크 기반 region feature를 언어 임베딩과 정렬하기 위해 Mask-Aware Visual Extractor만 학습된다. Object-level 데이터셋인 COCO, RefCOCO, RefCOCO+와 part-level 데이터셋인 Pascal Part, Part Imagenet에서 짧은 텍스트와 pixel-level 마스크 쌍을 수집한 다음 이를 instruction-following 데이터로 변환하여 모델을 학습시킨다.
3단계: End-to-End Fine-tuning. 이 단계에서는 비전 인코더의 가중치를 고정하고 image-level projector, 마스크 기반 region feature extractor, LLM 모델을 fine-tuning한다. 이 단계에서는 Osprey-724K 데이터셋을 활용한다. 또한, Visual Genome (VG)과 Visual Commonsense Reasoning (VCR) 데이터셋을 사용하여 더 많은 다중 영역 이해 데이터를 추가한다. VG 데이터셋에서 bounding box 주석은 사용할 수 있지만 마스크 기반 주석은 사용할 수 없다. 따라서 HQ-SAM을 사용하여 VG 데이터셋에 대한 고품질 마스크를 생성한다.
Experiments
- 구현 디테일
- 입력 이미지 크기: 512$\times$512
- optimizer: AdamW
- 1단계: batch size = 128, learning rate = $1 \times 10^{-3}$, epoch = 1
- 2단계: batch size = 4, learning rate = $2 \times 10^{-5}$, epoch = 2
- 3단계: batch size = 4, learning rate = $1 \times 10^{-5}$, epoch = 2
- LLM 최대 길이: 2,048
- GPU: NVIDIA A100 4개
- 학습 시간: 각 단계마다 7, 15, 48시간
1. Experimental Results
다음은 입력 마스크 기반 참조 영역에 대한 결과이다.

다음은 SAM에서 얻은 마스크를 기반으로 한 시각적 결과이다.

Open-Vocabulary Segmentation
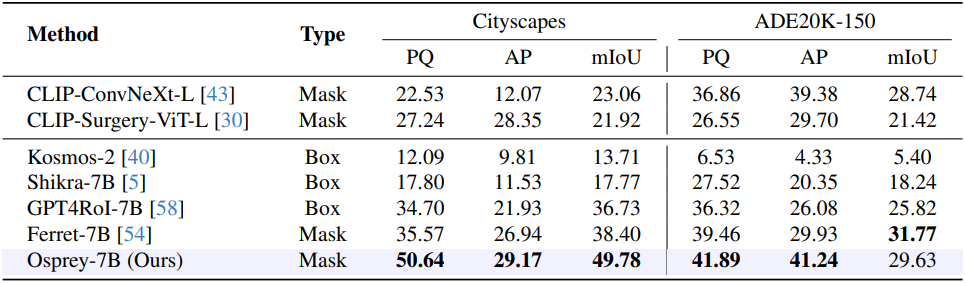
다음은 Cityscapes와 ADE20K에서 open-vocabulary panoptic segmentation (PQ), open-vocabulary instance segmentation (AP), open-vocabulary semantic segmentation (mIoU) 성능을 비교한 표이다.
Referring Object Classification
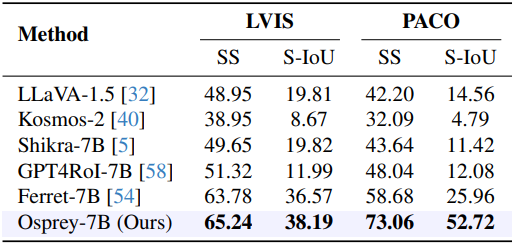
다음은 LVIS (object-level)와 PACO (part-level)에서 referring object classification 성능을 semantic similarity (SS)와 semantic IoU (S-IoU)로 비교한 표이다.
Referring Description and Reasoning
다음은 (왼쪽) RefCOCO에 대하여 GPT4가 평가한 상세한 영역 설명 성능과 (오른쪽) Ferret-Bench 결과이다.


Object Hallucination
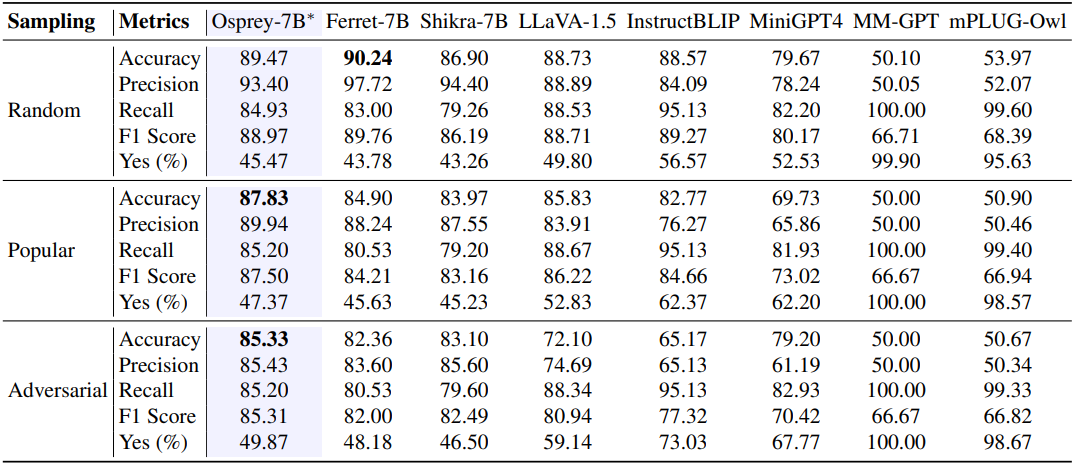
다음은 POPE 벤치마크에서의 object hallucination을 비교한 표이다.
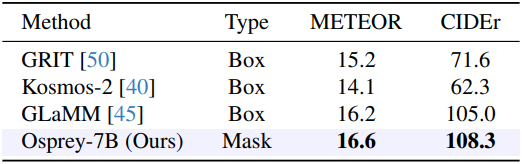
Region Level Captioning
다음은 RefCOCOg에서 region captioning 성능을 비교한 표이다.
2. Ablation Study
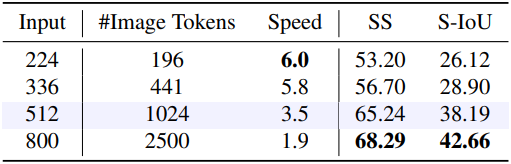
다음은 (왼쪽) 비전 인코더와 (오른쪽) 입력 이미지 크기에 대한 ablation 결과이다.