[논문리뷰] OneFormer: One Transformer to Rule Universal Image Segmentation
CVPR 2023. [Paper] [Page] [Github]
Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shig
SHI Labs | IIT Roorkee | Picsart AI Research (PAIR)
10 Nov 2022
Introduction
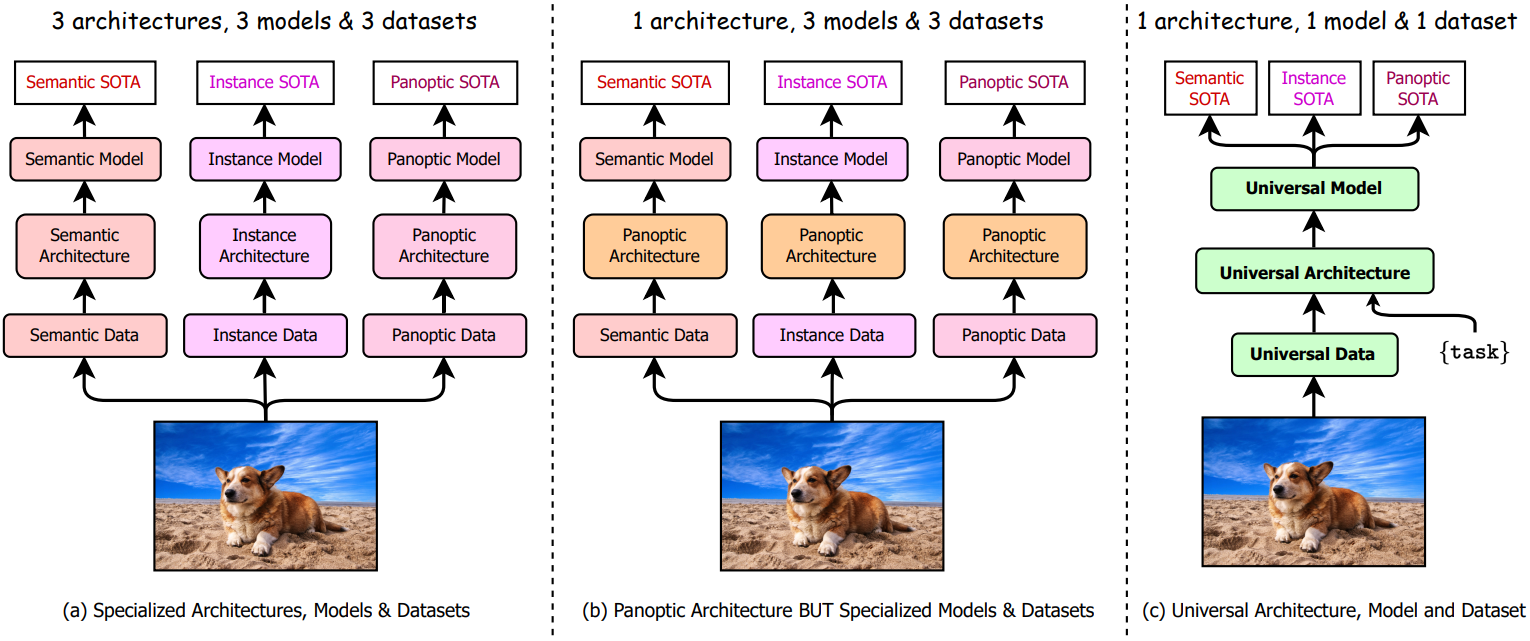
Image segmentation은 픽셀을 여러 세그먼트로 그룹화하는 task이다. 이러한 그룹화는 semantic 기반 (ex. 도로, 하늘, 건물) 또는 인스턴스 기반 (잘 정의된 경계가 있는 객체)일 수 있다. 이전의 segmentation 접근 방식은 전문화된 아키텍처를 사용하여 이러한 두 가지 segmentation task를 개별적으로 다루었으므로 각각에 대한 별도의 연구 노력이 필요했다. Semantic segmentation과 instance segmentation을 통합하려는 최근 연구에서는 픽셀을 비정형 배경 영역(“물건”으로 표시됨)에 대해 비정형 세그먼트로 그룹화하고 잘 정의된 모양 (“stuff”로 표시됨)을 가진 개체에 대해 개별 세그먼트로 그룹화하는 panoptic segmentation을 제안했다. 그러나 이러한 노력으로 인해 이전 task를 통합하는 대신 새로운 전문화된 panoptic 아키텍처가 탄생했다 (위 그림의 a 참조).
최근에는 K-net, MaskFormer, Mask2Former와 같은 새로운 panoptic 아키텍처를 사용하여 image segmentation을 통합하는 방향으로 연구 추세가 바뀌었다. 이러한 panoptic 아키텍처는 세 가지 task 모두에 대해 학습을 받을 수 있으며 아키텍처를 변경하지 않고도 고성능을 얻을 수 있다. 그러나 최고의 성능을 달성하려면 각 task에 대해 개별적으로 학습을 받아야 한다 (위 그림 b 참조). 개별 학습 정책에는 추가 학습 시간이 필요하며 각 task에 대해 서로 다른 모델 가중치 집합을 생성한다. 그런 점에서 보편적이지 않은 접근 방식으로만 간주될 수 있다. 예를 들어 Mask2Former는 각 task에 대한 최상의 성능을 얻기 위해 각 segmentation task에 대해 ADE20K에서 16만 iteration에 대해 학습되어 총 48만 iteration을 사용하고 inference를 위해 저장 및 호스팅할 3개 모델을 생성한다.
본 논문은 하나의 panoptic 데이터셋에 대해 단 한 번의 학습으로 세 가지 image segmentation task 모두에서 기존의 SOTA 성능을 능가하는 multi-task 범용 image segmentation 프레임워크인 OneFormer를 제안한다 (위 그림 c 참조). 본 논문은 다음과 같은 질문들에 답하는 것을 목표로 한다.
기존의 panoptic 아키텍처가 세 가지 task를 모두 처리하는 하나의 학습 프로세스나 모델로 성공하지 못하는 이유는 무엇인가?
저자들은 기존 방법이 아키텍처에 task guidance가 없기 때문에 각 segmentation task에 대해 개별적으로 학습해야 하므로 공동으로 학습하거나 하나의 모델을 사용하여 학습할 때 task 간 도메인 차이를 학습하는 것이 어렵다고 가정하였다. 이 과제를 해결하기 위해 본 논문은 “the task is {task}”라는 텍스트 형식의 task 입력 토큰을 도입하여 원하는 task에 따라 모델을 컨디셔닝한다. 이를 통해 학습 시에는 아키텍처를 task-guided로 만들고 inference 시에는 아키텍처를 task에 동적으로 만들며, 모두 하나의 모델로 가능하다.
저자들은 모델이 task 측면에서 편견이 없는지 확인하기 위해 공동 학습 프로세스 중에 {panoptic, instance, semantic}에서 {task}와 해당 ground truth를 균일하게 샘플링한다. Semantic 정보와 instance 정보를 모두 캡처하는 panoptic 데이터의 능력에 힘입어 학습 중에 해당 panoptic 주석에서 semantic 레이블과 instance 레이블을 파생한다. 결과적으로 학습 중에는 panoptic 데이터만 필요하다. 또한 공동 학습 시간, 모델 파라미터, FLOPs는 기존 방법과 유사하여 학습 시간과 스토리지 요구 사항을 최대 3배까지 줄여 image segmentation에 리소스를 덜 사용하고 접근성을 높인다.
하나의 공동 학습 과정에서 multi-task 모델이 task 간 및 클래스 간 차이를 더 잘 학습할 수 있는 방법은 무엇인가?
최근 컴퓨터 비전에서 transformer 프레임워크의 성공에 따라 query 토큰을 사용하여 가이드할 수 있는 transformer 기반 접근 방식으로 프레임워크를 공식화한다. 모델에 task별 컨텍스트를 추가하기 위해 task 토큰의 반복으로 query를 초기화하고 샘플링된 task에 대한 해당 ground truth 레이블에서 파생된 텍스트를 사용하여 query-text contrastive loss를 계산한다. 저자들은 query의 contrastive loss가 모델이 보다 task에 민감하도록 가이드하는 데 도움이 된다고 가정하였다. 또한 카테고리 예측 오차를 어느 정도 줄이는 데도 도움이 된다.
Method
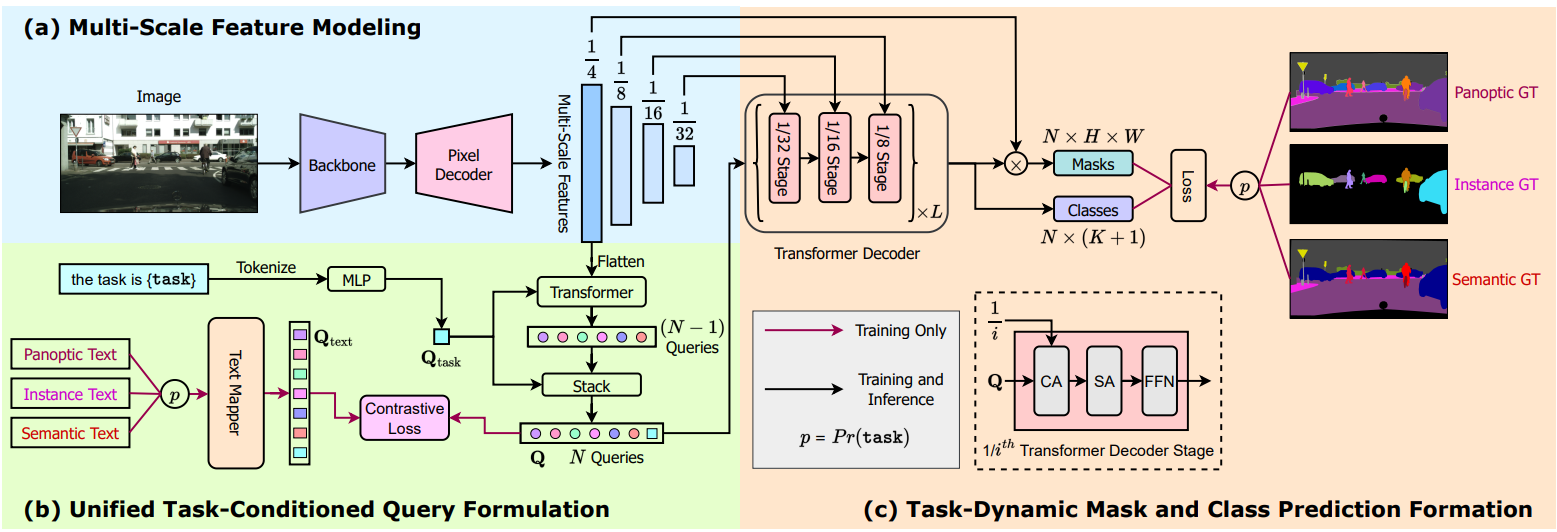
본 논문은 panoptic, semantic, instance segmentation에 대해 공동으로 학습되고 개별적으로 학습된 모델보다 성능이 뛰어난 범용 image segmentation 프레임워크인 OneFormer를 소개한다. 위 그림은 OneFormer의 개요를 제공한다. OneFormer는 샘플 이미지와 “the task is {task}” 형식의 task 입력이라는 두 가지 입력을 사용한다. 하나의 공동 학습 과정에서 task는 각 이미지에 대하여 {panoptic, instance, semantic}에서 균일하게 샘플링된다. 먼저 backbone과 픽셀 디코더를 사용하여 입력 이미지에서 멀티스케일 feature를 추출한다. Task 입력을 토큰화하여 object query를 컨디셔닝하는 데 사용되는 1D task 토큰을 얻고 결과적으로 각 입력에 대한 task에 대한 모델을 얻는다. 또한 ground truth 레이블에 있는 각 클래스의 이진 마스크 수를 나타내는 텍스트 목록을 생성하고 이를 text query 표현에 매핑한다. 텍스트 목록은 입력 이미지와 {task}에 따라 달라진다. 모델의 task에 동적인 예측을 supervise하기 위해 panoptic 주석에서 해당 ground truth 정보를 도출한다. Ground truth는 task에 따라 달라지므로 object query에 task 구분이 있는지 확인하기 위해 객체와 text query 간의 query-text contrastive loss를 계산한다. Object query와 멀티스케일 feature는 transformer 디코더에 입력되어 최종 예측을 생성한다.
1. Task Conditioned Joint Training
Image segmentation을 위한 기존 semi-universal 아키텍처는 세 가지 segmentation task 모두에 대해 공동으로 학습할 때 성능이 크게 저하된다. 저자들은 multi-task 문제를 해결하지 못한 이유를 아키텍처에 task 컨디셔닝이 없기 때문이라고 생각하였다.
Task로 컨디셔닝된 공동 학습 전략을 사용하여 image segmentation을 위한 multi-task train-once 문제를 해결한다. 특히, 먼저 ground truth 레이블에 대한 {panoptic, semantic, instance}에서 task를 균일하게 샘플링한다. Panoptic 주석에서 task별 레이블을 파생하여 하나의 주석 세트만 사용하여 panoptic 주석의 통합 가능성을 실현한다.
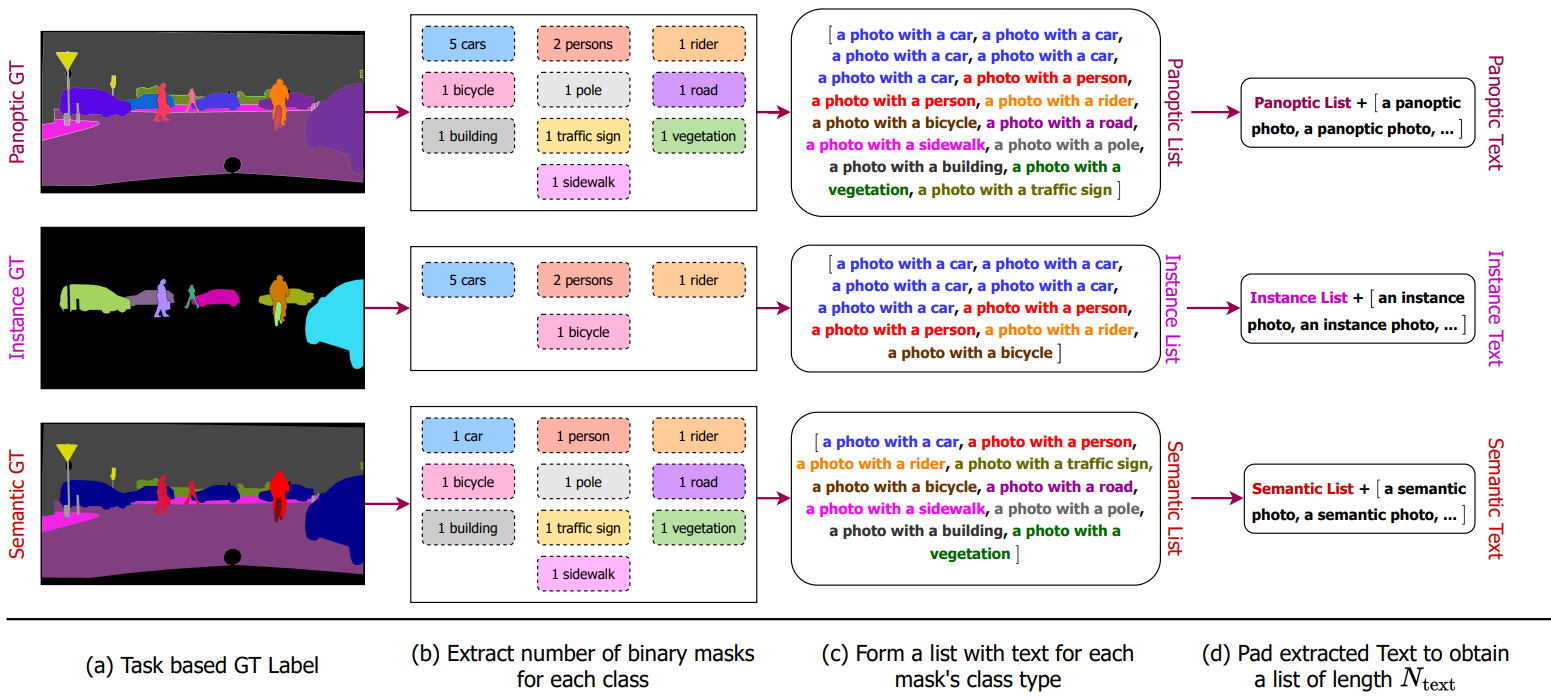
다음으로, task별 ground truth 레이블에서 이미지에 있는 각 카테고리에 대한 이진 마스크 집합을 추출한다. 즉, semantic task는 이미지에 있는 각 클래스에 대해 단 하나의 비정형 이진 마스크만 보장하는 반면, instance task는 겹치지 않음을 나타낸다. “stuff” 클래스에만 이진 마스크를 적용하고 “thing” 영역은 무시한다. Panoptic task는 위 그림과 같이 “stuff” 클래스에 대한 하나의 비정형 마스크와 “thing” 클래스에 대한 겹치지 않는 마스크를 나타낸다. 이어서 마스크 집합을 반복하여 “a photo with a {CLS}” 템플릿으로 구성된 텍스트 목록 $T_\textrm{list}$을 생성한다. 여기서 CLS는 해당 이진 마스크의 클래스 이름이다. 샘플당 이진 마스크 수는 데이터셋에 따라 다르다. 따라서 일정한 길이 $N_\textrm{text}$의 패딩된 목록 $T_\textrm{pad}$를 얻기 위해 “a/an {task} photo” 엔트리로 $T_\textrm{list}$를 패딩한다. Query-text contrastive loss를 계산하기 위해 $T_\textrm{pad}$를 사용한다.
본 논문은 토큰화되고 task 토큰 $Q_\textrm{task}$에 매핑되는 “the task is {task}” 템플릿으로 구성된 task 입력 $I_\textrm{task}$을 사용하여 task에 대한 아키텍처를 컨디셔닝한다. $Q_\textrm{task}$를 사용하여 task에 대해 OneFormer를 컨디셔닝한다.
2. Query Representations
학습 중에 아키텍처에서는 text query $Q_\textrm{text}$와 object query $Q$라는 두 가지 query 집합을 사용한다. $Q_\textrm{text}$는 이미지의 세그먼트에 대한 텍스트 기반 표현인 반면 $Q$는 이미지 기반 표현이다.
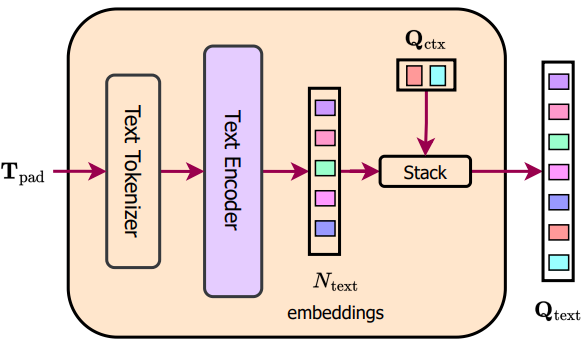
$Q_\textrm{text}$를 얻기 위해 먼저 텍스트 엔트리 $T_\textrm{pad}$를 토큰화하고 6-layer transformer인 텍스트 인코더를 통해 토큰화된 표현을 전달한다. 인코딩된 $N_\textrm{text}$개의 텍스트 임베딩은 입력 이미지의 이진 마스크 수와 해당 클래스를 나타낸다. 위 그림 (text mapper)과 같이 $N_\textrm{ctx}$개의 학습 가능한 텍스트 컨텍스트 임베딩 $Q_\textrm{ctx}$의 집합을 인코딩된 텍스트 임베딩에 concat하여 최종 $N$개의 text query $Q_\textrm{text}$를 얻는다. $Q_\textrm{ctx}$를 사용하는 동기는 샘플 이미지에 대하여 통합된 텍스트 컨텍스트를 학습하는 것이다. 학습 중에만 text query를 사용하며, inference 중에 text mapper 모듈을 삭제하여 모델 크기를 줄일 수 있다.
$Q$를 얻기 위해 먼저 task 토큰 $Q_\textrm{task}$의 $N -1$번 반복으로 object query $Q^\prime$을 초기화한다. 그런 다음 2-layer transformer 내부의 flatten된 1/4 스케일 feature의 guidance에 따라 $Q^\prime$을 업데이트한다. Transformer에서 업데이트된 $Q^\prime$은 $Q_\textrm{task}$와 concat되어 $N$개의 query들의 task로 컨디셔닝된 표현인 $Q$를 얻는다. 바닐라 all-zeros 또는 랜덤 초기화와 달리 task 기반 query 초기화와 $Q_\textrm{task}$와의 concatenation은 모델이 여러 segmentation task를 학습하는 데 중요하다.
3. Task Guided Contrastive Queries
세 가지 segmentation task 모두에 대한 하나의 모델을 개발하는 것은 세 가지 task 간의 본질적인 차이로 인해 어렵다. Object query $Q$의 semantic은 task에 따라 다르다. Instance segmentation의 경우 query는 “thing” 클래스만 집중해야 하고, semantic segmentation의 경우 query는 하나의 비정형 객체만 예측해야 하고, panoptic segmentation의 경우 두 가지의 혼합을 예측해야 한다. 기존 query 기반 아키텍처는 이러한 차이점을 고려하지 않으므로 세 가지 task 모두에서 하나의 모델을 효과적으로 학습하는 데 실패한다.
이를 위해 $Q$와 $Q_\textrm{text}$를 사용하여 query-text contrastive loss을 계산한다. $T_\textrm{pad}$를 사용하여 text query 표현인 $Q_\textrm{text}$를 얻는다. 여기서 $T_\textrm{pad}$는 주어진 이미지에서 감지될 각 마스크에 대한 텍스트 표현 목록이며, 객체 없음을 나타내는 “a/an {task} photo”가 포함된다. 따라서 text query는 이미지에 존재하는 객체/세그먼트를 나타내는 object query의 목적과 일치한다. 따라서 ground truth에서 파생된 text query와 object query 간의 contrastive loss를 사용하여 query 표현의 task 간 구별을 성공적으로 학습할 수 있다. 또한 query에 대한 contrastive learning을 통해 클래스 간 차이에 주의를 기울이고 카테고리 오분류를 줄일 수 있다.
\[\begin{aligned} \mathcal{L}_{Q \rightarrow Q_\textrm{text}} &= - \frac{1}{B} \sum_{i=1}^B \log \frac{\exp (q_i^\textrm{obj} \odot q_i^\textrm{txt} / \tau)}{\sum_{j=1}^B \exp (q_i^\textrm{obj} \odot q_j^\textrm{txt} / \tau)} \\ \mathcal{L}_{Q_\textrm{text} \rightarrow Q} &= - \frac{1}{B} \sum_{i=1}^B \log \frac{\exp (q_i^\textrm{txt} \odot q_i^\textrm{obj} / \tau)}{\sum_{j=1}^B \exp (q_i^\textrm{txt} \odot q_j^\textrm{obj} / \tau)} \\ \mathcal{L}_{Q \leftrightarrow Q_\textrm{text}} &= \mathcal{L}_{Q \rightarrow Q_\textrm{text}} + \mathcal{L}_{Q_\textrm{text} \rightarrow Q} \end{aligned}\]$B$개의 object-text query 쌍의 배치 \(\{(q_i^\textrm{obj}, x_i^\textrm{txt})\}_{i=1}^B\)가 있다고 가정하자. 여기서 \(q_i^\textrm{obj}\)와 \(q_i^\textrm{txt}\)는 각각 $i$번째 쌍의 object query와 text query이다. Query 간의 유사도를 내적을 계산하여 측정한다. 전체 contrastive loss는 두 가지 loss로 구성된다.
- object-to-text contrastive loss \(\mathcal{L}_{Q \rightarrow Q_\textrm{text}}\)
- text-to-object contrastive loss \(\mathcal{L}_{Q_\textrm{text} \rightarrow Q}\)
$\tau$는 contrastive logit의 크기를 조정하기 위한 학습 가능한 temperature 파라미터이다.
4. Other Architecture Components
Backbone and Pixel Decoder
널리 사용되는 ImageNet으로 사전 학습된 backbone을 사용하여 입력 이미지에서 멀티스케일 feature는 표현을 추출한다. 픽셀 디코더는 backbone feature를 점진적으로 업샘플링하여 feature는 모델링을 지원한다. 최근 multi-scale deformable attention의 성공에 힘입어 픽셀 디코더에 동일한 Multi-Scale Deformable Transformer (MSDeformAttn) 기반 아키텍처를 사용한다.
Transformer Decoder
Transformer 디코더 내부의 고해상도 맵을 활용하기 위해 멀티스케일 전략을 사용한다. 구체적으로, object query $Q$와 픽셀 디코더의 멀티스케일 출력 $F_i$, \(i \in \{1/4, 1/8, 1/16, 1/32\}\)을 입력으로 제공한다. 원래 이미지의 1/8, 1/16, 1/32 해상도의 feature를 사용하여 masked cross-Attention (CA) 연산과 이어지는 self-attention (SA), feed-forward network (FFN)로 $Q$를 업데이트한다. Transformer 디코더 내에서 이러한 연산을 $L$번 수행한다.
Transformer 디코더의 최종 query 출력은 클래스 예측을 위해 $K + 1$ 차원 공간에 매핑된다. 여기서 $K$는 클래스 수를 나타내고 추가 +1은 객체 없음 예측을 나타낸다. 최종 마스크를 얻기 위해 $Q$와 $F_{1/4}$ 사이의 einsum 연산을 사용하여 원본 이미지의 1/4 해상도에서 $F_{1/4}$을 디코딩한다. inference 중에는 최종 panoptic, semantic, instance segmentation 예측을 얻기 위해 Mask2Former와 동일한 후처리 기술을 따른다. ADE20K, Cityscapes, COCO 데이터셋에 대한 panoptic segmentation을 위한 후처리 중에 임계값 0.5, 0.8, 0.8을 초과하는 점수로만 예측을 유지한다.
5. Losses
Query에 대한 contrastive loss 외에도 클래스 예측에 대한 표준 분류 CE-loss \(\mathcal{L}_\textrm{cls}\)를 계산한다. 다음에서는 마스크 예측에 대해 이진 cross-entropy loss \(\mathcal{L}_\textrm{bce}\)와 dice loss \(\mathcal{L}_\textrm{dice}\)의 결합을 사용한다. 따라서 최종 loss function은 4개 loss의 가중 합이다. 저자들은 경험적으로 \(\lambda_{Q \leftrightarrow Q_\textrm{text}} = 0.5\), \(\lambda_\textrm{cls} = 2\), \(\lambda_\textrm{bce} = 5\), \(\lambda_\textrm{dice} = 5\)로 설정했다. 최소 비용 할당을 찾기 위해 예측 집합과 ground truth 간의 이분 매칭을 사용한다. 객체 없음 예측의 경우 \(\lambda_\textrm{cls}\)를 0.1로 설정했다.
\[\begin{aligned} \mathcal{L}_\textrm{final} &= \lambda_{Q \leftrightarrow Q_\textrm{text}} \mathcal{L}_{Q \leftrightarrow Q_\textrm{text}} + \lambda_\textrm{cls} \mathcal{L}_\textrm{cls} \\ &+ \lambda_\textrm{bce} \mathcal{L}_\textrm{bce} + \lambda_\textrm{dice} \mathcal{L}_\textrm{dice} \end{aligned}\]Experiments
- 데이터셋: Cityscapes, ADE20K, COCO
1. Main Results
ADE20K
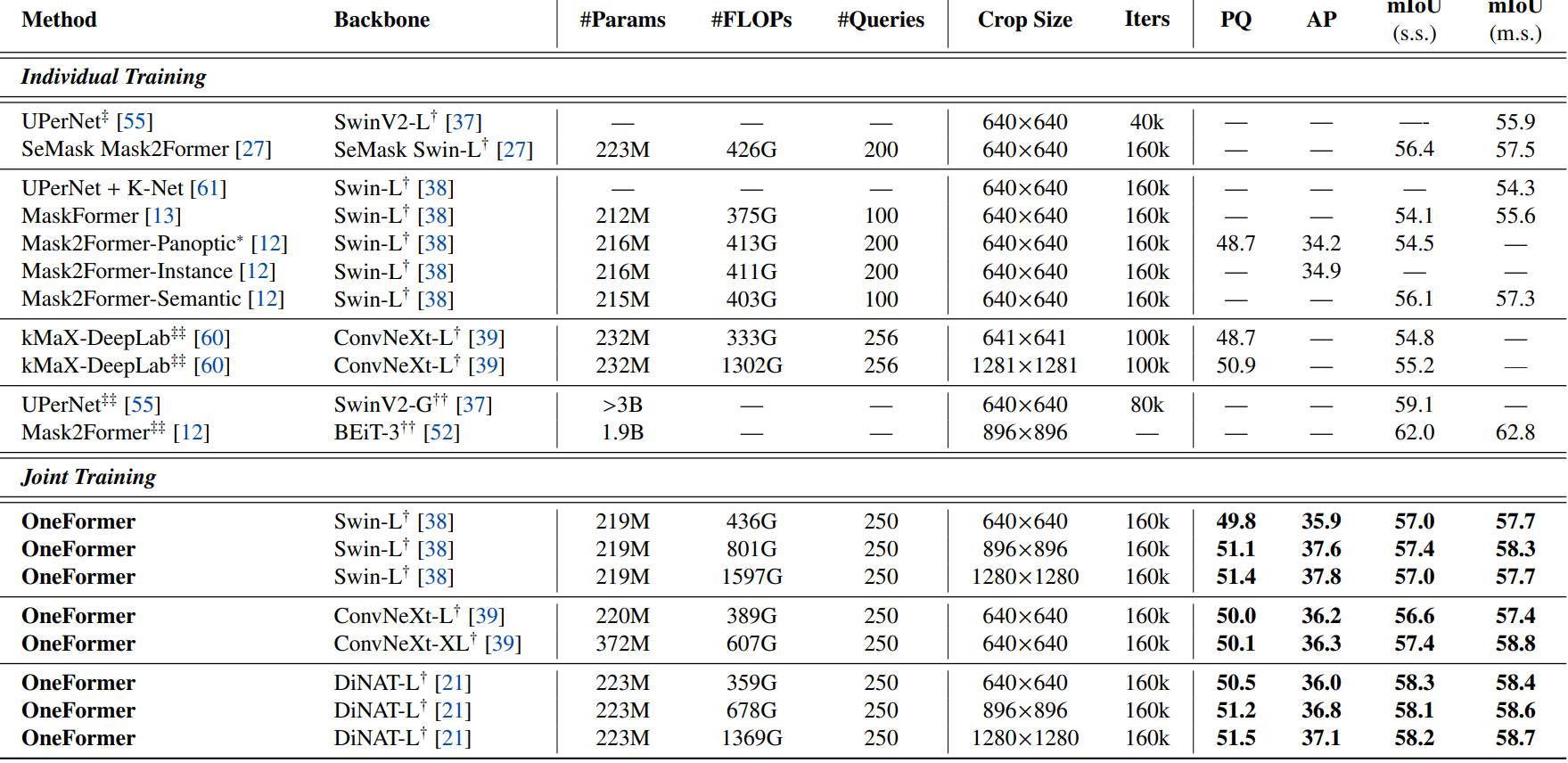
다음은 ADE20K val set에서 SOTA와 비교한 표이다.
Cityscapes
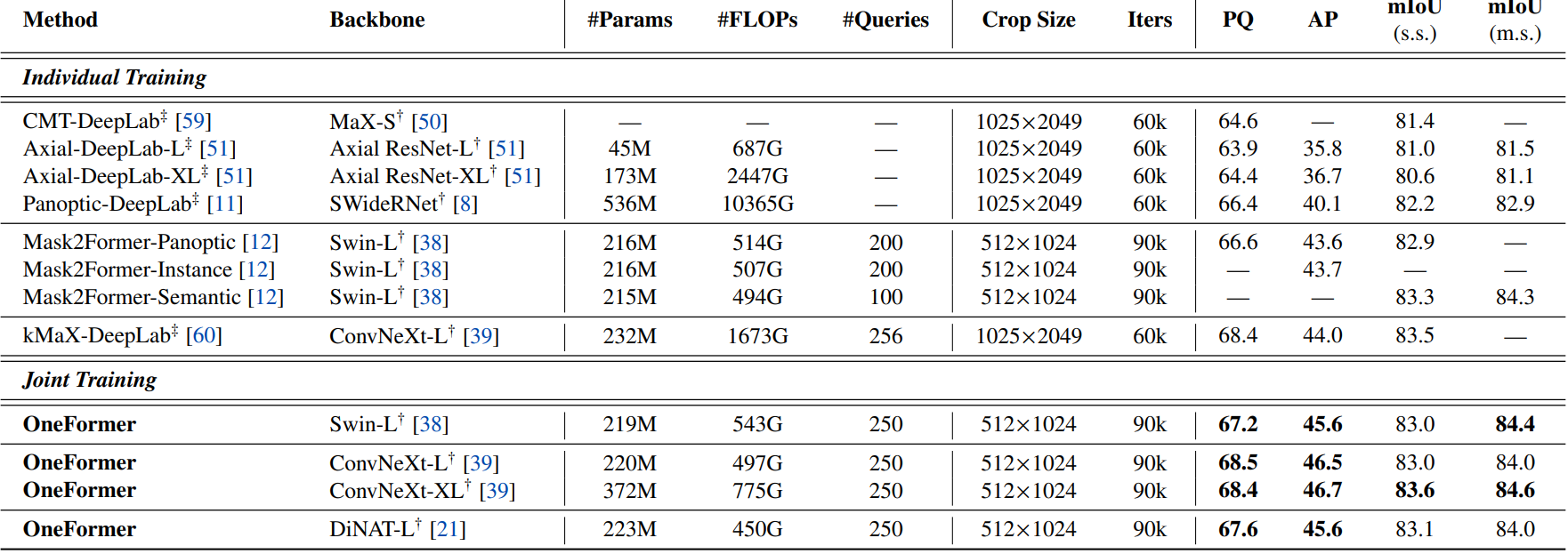
다음은 Cityscapes val set에서 SOTA와 비교한 표이다.
COCO
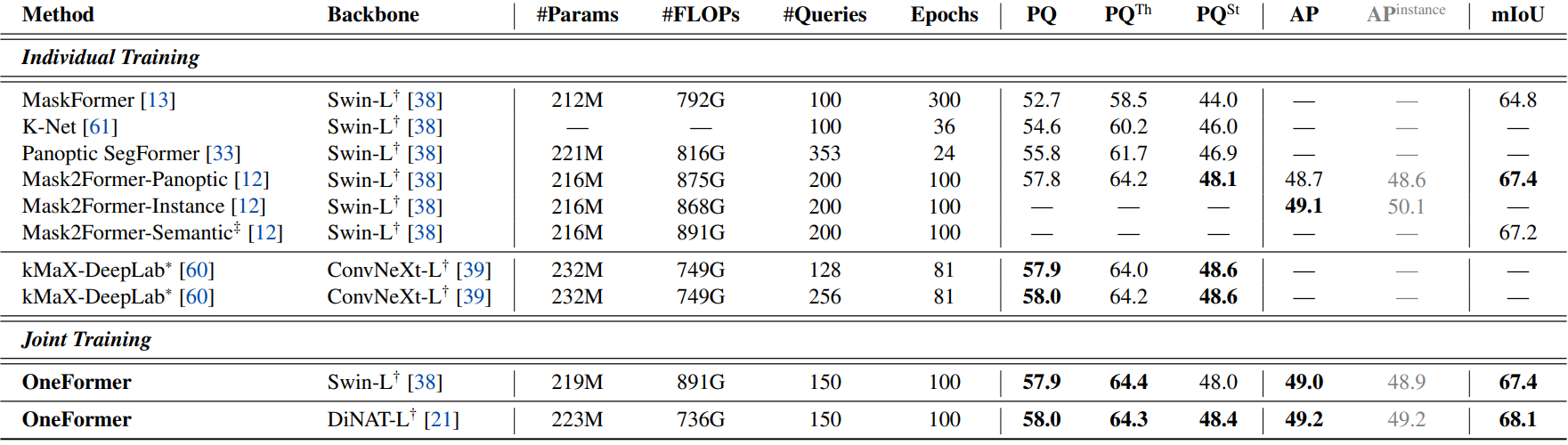
다음은 COCO val2017 set에서 SOTA와 비교한 표이다.
2. Ablation Studies
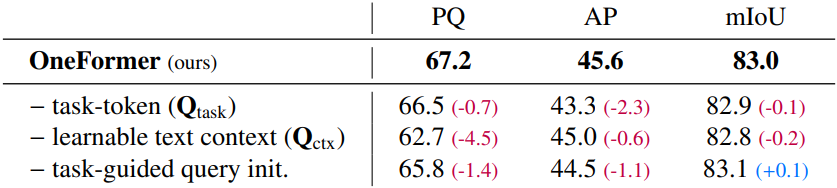
Task-Conditioned Architecture
다음은 구성 요소에 대한 ablation 결과이다.
Contrastive Query Loss
다음은 loss에 대한 ablation 결과이다.

Input Text Template
다음은 입력 텍스트 템플릿에 대한 ablation 결과이다.

Task Conditioned Joint Training
다음은 공동 학습에 대한 ablation 결과이다. (Swin-L backbone, ADE20K)

Task Token Input
다음은 task 토큰 입력에 대한 ablation 결과이다. (Swin-L backbone, ADE20K)

Reduced Category Misclassifications
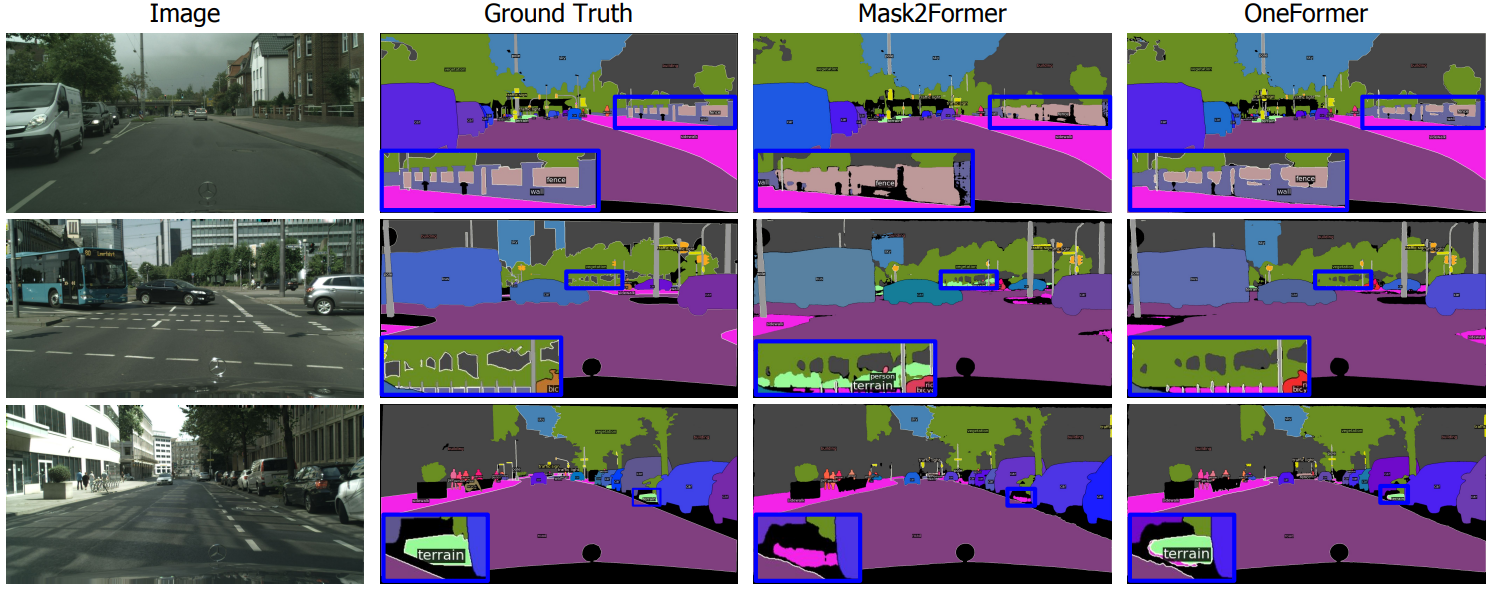
다음은 비슷한 클래스들이 있는 영역에 대한 분할 결과를 Mask2Former와 비교한 것이다.