[논문리뷰] Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models (ODISE)
CVPR 2023. [Paper] [Page] [Github]
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiaolong Wang, Shalini De Mello
UC San Diego | NVIDIA
8 Mar 2023
Introduction
인간은 세상을 바라보며 무한한 카테고리를 인식할 수 있다. 세밀하고 무한한 이해로 지능을 재현하기 위해 open-vocabulary 인식 문제가 최근 컴퓨터 비전 분야에서 많은 주목을 받고 있다. 그러나 모든 객체 인스턴스와 장면 semantic을 동시에 파싱하는 통합 프레임워크, 즉 panoptic segmentation을 제공할 수 있는 task는 거의 없다.
Open-vocabulary 인식을 위한 대부분의 최신 접근 방식은 인터넷 스케일 데이터로 학습된 텍스트-이미지 discriminative model의 뛰어난 일반화 능력에 의존하였다. 이러한 사전 학습된 모델은 개별 object proposal이나 픽셀을 분류하는 데는 좋지만 장면 수준의 구조적 이해를 수행하는 데 반드시 최적인 것은 아니다. 실제로 CLIP은 종종 객체 간의 공간 관계를 혼동하는 것으로 나타났다. 저자들은 텍스트-이미지 discriminative model이 공간적 이해와 관계적 이해가 부족하여 open-vocabulary panoptic segmentation의 병목 현상이 발생한다고 가정하였다.
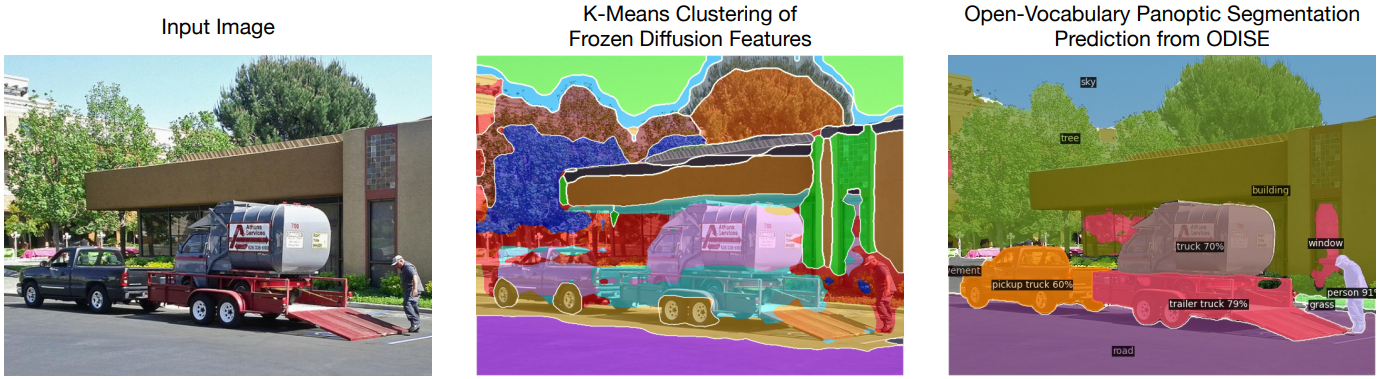
한편, 인터넷 스케일의 데이터에 대해 학습된 diffusion model을 사용한 text-to-image 생성은 최근 이미지 합성 분야에 혁명을 일으켰다. 입력 텍스트를 통해 전례 없는 이미지 품질, 일반화 가능성, 합성 가능성, semantic 제어 능력을 제공하였다. 흥미로운 관찰은 제공된 텍스트에 대한 이미지 생성 프로세스를 컨디셔닝하기 위해 diffusion model이 텍스트 임베딩과 내부 시각적 표현 간의 cross-attention을 계산한다는 것이다. 이 디자인은 diffusion model의 내부 표현이 언어로 설명될 수 있는 높은/중간 수준의 semantic 개념과 잘 구별되고 상호 연관되어 있다는 타당성을 의미한다. 이 발견에 동기를 부여하여 저자들은 인터넷 스케일의 text-to-image diffusion model을 활용하여 현실의 모든 개념에 대한 보편적인 open-vocabulary panoptic segmentation 모델을 만들 수 있는지 여부에 대해 질문하였다.
본 논문은 이를 위해 대규모 text-to-image diffusion model과 discriminative model을 모두 활용하여 현실의 모든 카테고리에 대해 최신 panoptic segmentation을 수행하는 모델인 ODISE: Open-vocabulary DIffusion-based panoptic SEgmentation을 제안하였다. 상위 수준에는 이미지와 캡션을 입력하고 diffusion model의 내부 feature를 추출하는 사전 학습된 고정된 text-to-image diffusion model이 포함되어 있다. 이러한 feature를 입력으로 사용하여 마스크 generator는 이미지에서 가능한 모든 개념의 panoptic mask를 생성한다. 학습 세트에서 사용할 수 있는 주석이 달린 마스크를 사용하여 마스크 generator를 학습시킨다. 그런 다음 마스크 분류 모듈은 예측된 각 마스크의 diffusion feature를 여러 객체 카테고리 이름의 텍스트 임베딩과 연결하여 각 마스크를 많은 open-vocabulary 카테고리 중 하나로 분류한다. 학습 데이터셋의 마스크 카테고리 레이블이나 이미지 수준 캡션을 사용하여 이 분류 모듈을 학습시킨다. 학습을 마치면 text-to-image diffusion model과 discriminative model을 모두 사용하여 open-vocabulary panoptic inference를 수행하여 예측된 마스크를 분류한다. 다양한 벤치마크 데이터셋과 여러 open-vocabulary 인식 task에서 ODISE는 기존 baseline을 훨씬 능가하는 SOTA 정확도를 달성하였다.
Method
1. Problem Definition
테스트 카테고리 $C_\textrm{test}$와 다를 수 있는 기본 학습 카테고리 세트 $C_\textrm{train}$를 사용하여 모델을 학습한다. 즉, $C_\textrm{train} \ne C_\textrm{test}$이다. $C_\textrm{test}$에는 학습 중에 표시되지 않는 새로운 카테고리가 포함될 수 있다. 학습 중에 이미지의 각 카테고리에 대한 이진 panoptic mask 주석이 제공된다고 가정한다. 또한 각 마스크의 카테고리 레이블이나 이미지의 텍스트 캡션을 사용할 수 있다고 가정한다. 테스트 중에는 어떤 이미지에도 카테고리 레이블이나 캡션을 사용할 수 없으며 테스트 카테고리 $C_\textrm{test}$의 이름만 제공된다.
2. Method Overview
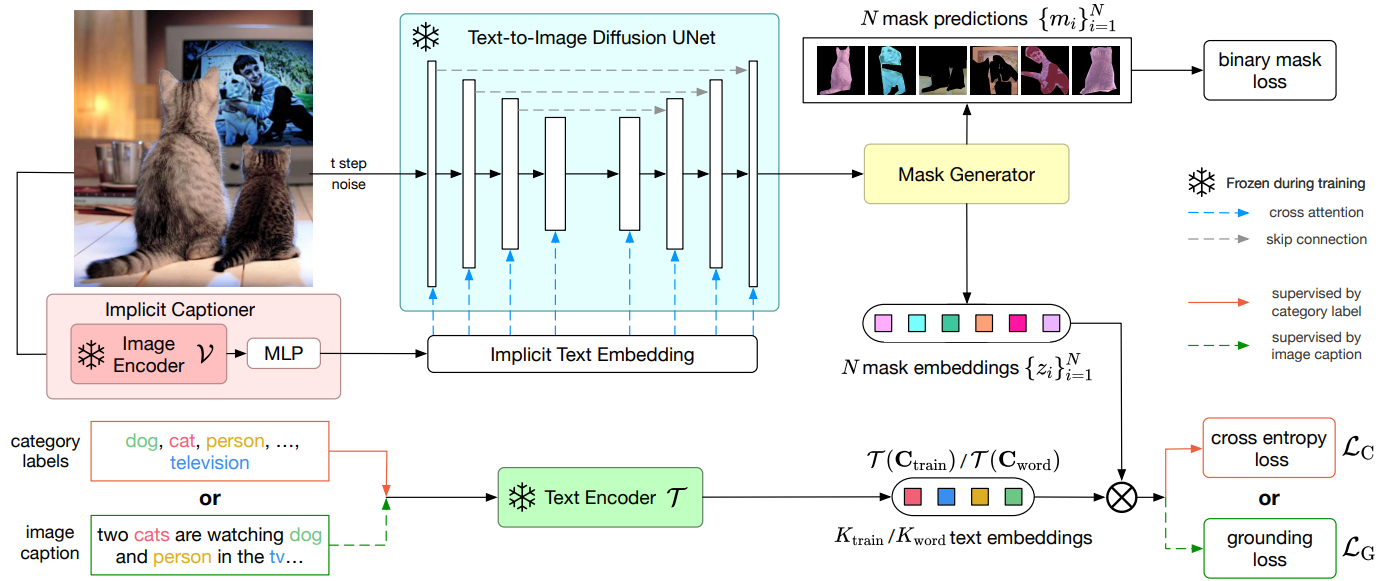
현실의 모든 카테고리에 대한 open-vocabulary panoptic segmentation을 위한 ODISE 방법의 개요는 위 그림에 나와 있다. 상위 수준에는 이미지를 입력하는 text-to-image diffusion model이 포함되어 있으며, 캡션을 작성하고 diffusion model의 내부 feature를 추출한다. 이렇게 추출된 feature를 입력으로 사용하고 제공된 학습 마스크 주석을 사용하여 이미지에서 가능한 모든 카테고리의 panoptic mask를 생성하도록 마스크 generator를 학습시킨다. 제공된 학습 이미지의 카테고리 레이블 또는 텍스트 캡션을 사용하여 open-vocabulary 마스크 분류 모듈도 학습시킨다. 각 예측 마스크의 diffusion feature와 텍스트 인코더의 학습 카테고리 이름 임베딩을 사용하여 마스크를 분류한다. 학습을 마치면 text-to-image diffusion model과 discriminative model을 모두 사용하여 open-vocabulary panoptic inference를 수행한다.
3. Text-to-Image Diffusion Model
Background
Text-to-image diffusion model은 제공된 입력 텍스트 프롬프트에서 고품질 이미지를 생성할 수 있다. 인터넷에서 크롤링된 수백만 개의 이미지-텍스트 쌍으로 학습되었다. 텍스트는 사전 학습된 텍스트 인코더 (ex. T5 또는 CLIP)를 사용하여 텍스트 임베딩으로 인코딩된다. Diffusion model에 입력되기 전에 이미지에 일정 수준의 Gaussian noise를 추가하여 이미지가 왜곡된다. Diffusion model은 noisy한 입력과 쌍을 이루는 텍스트 임베딩을 고려하여 왜곡을 없애도록 학습되었다. Inference 중에 모델은 이미지 형태의 순수 Gaussian noise와 사용자가 제공한 설명의 텍스트 임베딩을 입력으로 받고, 여러 번의 inference 반복을 통해 점진적으로 현실적인 이미지로 denoise한다.
Visual Representation Extraction
널리 사용되는 diffusion 기반 text-to-image 생성 모델은 일반적으로 UNet 아키텍처를 사용하여 denoising process를 학습시킨다. 위 그림의 파란색 블록에 표시된 것처럼 UNet은 convolution block, 업샘플링 블록, 다운샘플링 블록, skip connection, attention block으로 구성되어 텍스트 임베딩과 UNet feature 간에 cross-attention을 수행한다. Denoising process의 모든 단계에서 diffusion model은 텍스트 입력을 사용하여 noisy한 입력 이미지의 denoising 방향을 추론한다. 텍스트는 cross-attention layer를 통해 모델에 주입되므로 시각적 feature가 의미상으로 유의미한 풍부한 텍스트 설명과 연관되도록 장려한다. 따라서 UNet 블록에 의해 출력된 feature map은 panoptic segmentation을 위한 풍부하고 dense한 feature로 간주될 수 있다.
본 논문의 방법은 전체 다단계 생성 diffusion process를 거치는 것과는 달리 시각적 표현을 추출하기 위해 diffusion model을 통해 입력 이미지의 단일 forward pass만 필요하다. 입력 이미지-텍스트 쌍 $(x, s)$가 주어지면 먼저 timestep $t$에서 noisy한 이미지 $x_t$를 다음과 같이 샘플링한다.
\[\begin{equation} x_t = \sqrt{\vphantom{1} \bar{\alpha}_t} x + \sqrt{1 - \bar{\alpha}_t} \epsilon \\ \epsilon \sim \mathcal{N}(0, I), \quad \bar{\alpha}_t = \prod_{k=1}^t \alpha_k \end{equation}\]사전 학습된 텍스트 인코더 $\mathcal{T}$로 캡션 $s$를 인코딩하고 이를 UNet에 공급하여 쌍에 대한 text-to-image diffusion UNet의 내부 feature $f$를 추출한다.
\[\begin{equation} f = \textrm{UNet} (x_t, \mathcal{T} (s)) \end{equation}\]$x$에 대한 diffusion model의 시각적 표현 $f$는 쌍을 이루는 캡션 $s$에 따라 달라진다는 점은 주목할 가치가 있다. 예를 들어 text-to-image diffusion model을 사전 학습하는 동안 이미지-텍스트 쌍 데이터를 사용할 수 있는 경우 올바르게 추출할 수 있다. 그러나 일반적인 사용 사례인 쌍 캡션 없이 이미지의 시각적 표현을 추출하려는 경우 문제가 된다. 캡션이 없는 이미지의 경우 빈 텍스트를 캡션 입력으로 사용할 수 있지만 이는 확실히 최선이 아니다. 본 논문은 명시적으로 캡션이 포함된 이미지 데이터의 필요성을 극복하기 위해 새로운 Implicit Captioner를 설계하였다.
Implicit Captioner
캡션을 생성하기 위해 기성 캡션 네트워크를 사용하는 대신 입력 이미지 자체에서 암시적 텍스트 임베딩을 생성하도록 네트워크를 학습한다. 그런 다음 이 텍스트 임베딩을 diffusion model에 직접 입력한다. 이 모듈을 implicit captioner라고 부른다. 이미지에 대한 암시적 텍스트 임베딩을 파생시키기 위해 예를 들어 CLIP에서 사전 학습된 고정 이미지 인코더 $\mathcal{V}$를 활용하여 입력 이미지 $x$를 임베딩 공간에 인코딩한다. 또한 학습된 MLP를 사용하여 이미지 임베딩을 암시적 텍스트 임베딩에 project하고 이를 text-to-image diffusion UNet에 입력한다. Open-vocabulary panoptic segmentation 학습 중에 이미지 인코더와 UNet의 파라미터는 변경되지 않으며 MLP의 파라미터만 fine-tuning한다.
마지막으로 text-to-image diffusion model의 UNet은 implicit captioner와 함께 입력 이미지 $x$에 대한 시각적 표현 $f$를 계산하는 ODISE의 feature extractor를 형성한다. 시각적 표현 $f$를 다음과 같이 계산한다.
\[\begin{aligned} f = \textrm{UNet} (x_t, \textrm{ImplicitCaptioner} (x)) = \textrm{UNet} (x_t, \textrm{MLP} \circ \mathcal{V} (x)) \end{aligned}\]4. Mask Generator
마스크 generator는 시각적 표현 $f$를 입력으로 취하고 $N$개의 클래스 독립적인 이진 마스크 \(\{m_i\}_{i=1}^N\)과 대응되는 $N$개의 마스크 임베딩 feature \(\{z_i\}_{i=1}^N\)을 출력한다. 마스크 generator는의 아키텍처는 특정 아키텍처로 제한되지 않는다. 이는 전체 이미지의 마스크 예측을 생성할 수 있는 모든 panoptic segmentation 네트워크일 수 있다. Bounding box 기반 방법과 segmentation mask 기반 방법을 모두 사용하여 방법을 인스턴스화할 수 있다. Bounding box 기반 방법을 사용하는 경우, 예측된 각 마스크 영역의 ROI-Aligned feature들을 모아 마스크 임베딩 feature를 계산할 수 있다. Segmentation mask 기반 방법의 경우, 최종 feature map에서 masked pooling을 직접 수행하여 마스크 임베딩 feature를 계산할 수 있다. 표현은 픽셀별 예측에 초점을 맞추기 때문에 직접 segmentation 기반 아키텍처를 사용한다. 다음으로, 픽셀별 binary cross entropy loss를 통해 예측된 클래스 독립적인 이진 마스크를 대응되는 ground truth 마스크와 함께 supervise한다.
5. Mask Classification
각각의 예측된 이진 마스크에 open-vocabulary의 카테고리 레이블을 할당하기 위해 텍스트-이미지 discriminative model을 사용한다. 인터넷 스케일의 이미지-텍스트 쌍에 대해 학습된 이러한 모델은 강력한 open-vocabulary 분류 능력을 보여주었다. 이는 이미지 인코더 $\mathcal{V}$와 텍스트 인코더 $\mathcal{T}$로 구성된다. Open-Vocabulary Image Segmentation 논문과 Language-driven Semantic Segmentation 논문을 따라 학습하는 동안 일반적으로 사용되는 두 가지 supervision 신호를 사용하여 각 예측 마스크의 카테고리 레이블을 예측하는 방법을 학습한다.
Category Label Supervision
여기서는 학습 중에 각 마스크의 ground truth 카테고리 레이블에 접근할 수 있다고 가정한다. 따라서 학습 절차는 전통적인 closed-vocabulary 학습의 절차와 유사하다. 학습 세트에 $K_\textrm{train} = \vert C_\textrm{train} \vert$개의 카테고리가 있다고 가정하자. 각 마스크 임베딩 feature $z_i$에 대해 대응되는 알려진 ground truth 카테고리를 $y_i \in C_\textrm{train}$로 부른다. 고정된 텍스트 인코더 $\mathcal{T}$를 사용하여 $C_\textrm{train}$의 모든 카테고리 이름을 인코딩하고 모든 학습 카테고리 이름의 임베딩 세트를 다음과 같이 정의한다.
\[\begin{equation} \mathcal{T} (C_\textrm{train}) = [\mathcal{T} (c_1), \mathcal{T} (c_2), \ldots, \mathcal{T} (c_{K_\textrm{train}})] \end{equation}\]여기서 카테고리 이름은 $c_k \in C_\textrm{train}$이다. 그런 다음 classification loss를 통해 $K_\textrm{train}$개의 클래스 중 하나에 속하는 마스크 임베딩 feature $z_i$의 확률을 다음과 같이 계산한다.
\[\begin{equation} \mathcal{L}_C = \frac{1}{N} \sum_i^N \textrm{CrossEntropy} (p(z_i, C_\textrm{train}), y_i) \\ p(z_i, C_\textrm{train}) = \textrm{Softmax} (z_i \cdot \mathcal{T} (C_\textrm{train}) / \tau) \end{equation}\]여기서 $\tau$는 학습 가능한 temperature 파라미터이다.
Image Caption Supervision
여기서는 학습 중에 주석이 달린 각 마스크와 관련된 카테고리 레이블이 없다고 가정한다. 대신, 각 이미지에 대한 자연어 캡션에 접근할 수 있으며, 모델은 이미지 캡션만 사용하여 예측된 마스크 임베딩 feature를 분류하는 방법을 학습한다. 이를 위해 각 캡션에서 명사들을 추출하고 이를 해당 쌍을 이루는 이미지에 대한 grounding 카테고리 레이블로 처리한다. 이전 연구들을 따라 마스크의 카테고리 레이블 예측을 supervise하기 위해 grounding loss를 사용한다. 구체적으로, 이미지-캡션 쌍 $(x^{(m)}, s^{(m)})$이 주어지면 $s^{(m)}$에서 추출된 $K_\textrm{word}$개의 명사들이 있고 \(C_\textrm{word} = \{w_k\}_{k=1}^{K_\textrm{word}}\)로 표시된고 가정한다. 배치를 형성하기 위해 $B$개의 이미지-캡션 쌍 \(\{(x^{(m)}, s^{(m)})\}_{m=1}^B\)을 샘플링한다고 가정하자. Grounding loss을 계산하기 위해 각 이미지-캡션 쌍 간의 유사성을 다음과 같이 계산한다.
\[\begin{equation} g (x^{(m)}, s^{(m)}) = \frac{1}{K} \sum_{k=1}^K \sum_{i=1}^N p (z_i, C_\textrm{word})_k \cdot \langle z_i, \mathcal{T} (w_k) \rangle \end{equation}\]여기서 $z_i$와 $\mathcal{T}(w_k)$는 동일한 차원의 벡터이고 \(p(z_i, C_\textrm{word})_k\)는 \(p(z_i, C_\textrm{word})\)의 $k$번째 요소이다. 이 유사도 함수는 각 명사가 이미지의 하나 또는 몇 개의 마스크 영역에 기반을 두도록 장려하고 어떤 단어에도 전혀 기반을 두지 않는 영역에 불이익을 주는 것을 방지한다. Grounding loss는 이미지-텍스트 contrastive loss와 비슷하게 다음과 같이 정의된다.
\[\begin{aligned} \mathcal{L}_G =\; &- \frac{1}{B} \sum_{m=1}^B \log \frac{\exp (g (x^{(m)}, s^{(m)}) / \tau)}{\sum_{n=1}^B \exp (g (x^{(m)}, s^{(n)}) / \tau)} \\ &- \frac{1}{B} \sum_{m=1}^B \log \frac{\exp (g (x^{(m)}, s^{(m)}) / \tau)}{\sum_{n=1}^B \exp (g (x^{(n)}, s^{(m)}) / \tau)} \end{aligned}\]여기서 $\tau$는 학습 가능한 temperature 파라미터이다. 클래스 독립적인 이진 마스크 loss와 함께 \(\mathcal{L}_C\) 또는 \(\mathcal{L}_G\)를 사용하여 전체 ODISE 모델을 학습한다.
6. Open-Vocabulary Inference
Inference 중에 테스트 카테고리 $C_\textrm{test}$의 이름 세트를 사용할 수 있다. 테스트 카테고리는 학습 카테고리와 다를 수 있다. 또한 테스트 이미지에는 캡션/레이블을 사용할 수 없다. 따라서 암시적 캡션을 얻기 위해 implicit captioner를 통해 이를 전달한다. UNet의 feature를 얻기 위해 두 가지를 diffusion model에 한다. 마스크 generator를 사용하여 이미지의 semantic 카테고리의 가능한 모든 이진 마스크를 예측한다. 각 예측 마스크 $m_i4를 테스트 카테고리 중 하나로 분류하기 위해 ODISE를 사용하여 $p(z_i, C_\textrm{test})$를 계산하고 최종적으로 최대 확률로 카테고리를 예측한다.
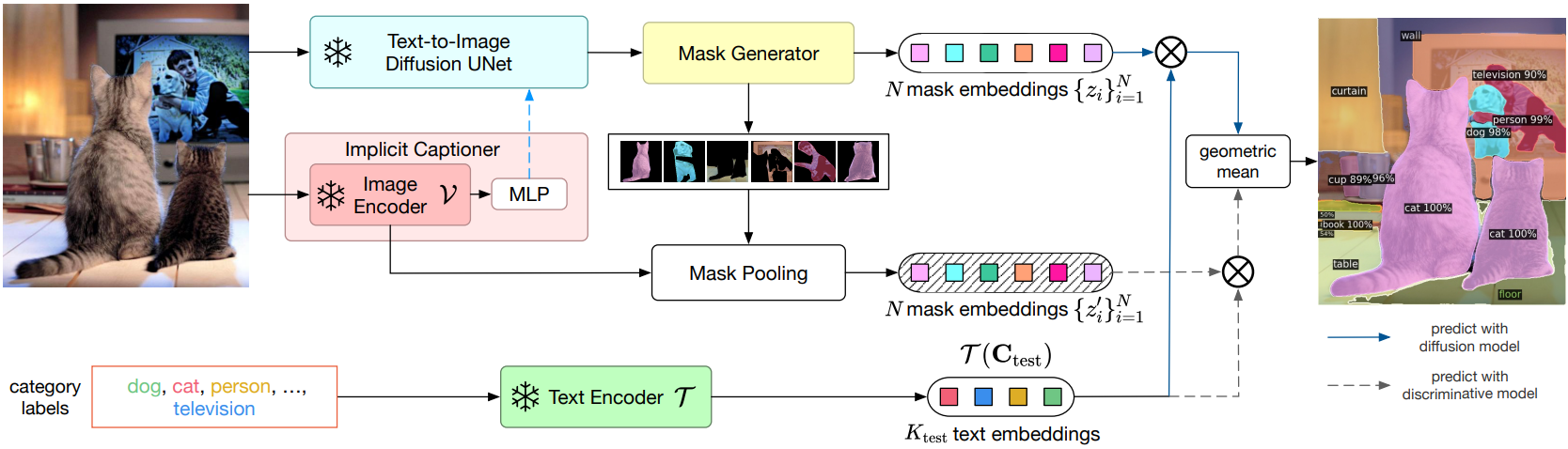
저자들은 실험에서 diffusion model의 내부 표현이 공간적으로 잘 차별화되어 객체 인스턴스에 대해 그럴듯한 마스크를 많이 생성한다는 것을 발견했다. 그러나 객체 분류 능력은 특히 open-vocabulary의 경우 CLIP과 같은 텍스트-이미지 discriminative model과 다시 한 번 결합하여 더욱 향상될 수 있다. 이를 위해 텍스트-이미지 discriminative model의 이미지 인코더 $\mathcal{V}$를 활용하여 원본 입력 이미지의 예측된 각 마스크 영역을 테스트 카테고리 중 하나로 추가로 분류한다. 구체적으로 위 그림에서 볼 수 있듯이 입력 이미지 $x$가 주어지면 먼저 이를 $\mathcal{V}$를 사용하여 feature map으로 인코딩한다. 그런 다음 ODISE가 이미지 $x$에 대해 예측한 마스크 $m_i$에 대하여, $\mathcal{V}(x)$에서 $m_i$ 내부에 속하는 모든 feature를 풀링하여 그에 대한 마스크 풀링된 이미지 feature를 계산한다.
텍스트-이미지 discriminative model로부터 최종 분류 확률을 계산하기 위해 \(p(z_i^{\prime M}, C_\textrm{test})\)를 사용한다. 마지막으로 diffusion model과 discriminative model의 카테고리 예측의 기하 평균을 최종 분류 예측으로 사용한다.
\[\begin{equation} p_\textrm{final} (z_i, C_\textrm{test}) \propto p (z_i, C_\textrm{test})^\lambda p_\textrm{final} (z_i^\prime, C_\textrm{test})^{(1-\lambda)} \end{equation}\]여기서 $\lambda \in [0,1]$는 고정된 balancing factor이다. 마스킹된 feature를 풀링하는 것은 원본 이미지에서 $N$개의 예측된 마스킹된 영역의 bounding box를 각각 잘라내고 이미지 인코더 $\mathcal{V}$를 사용하여 별도로 인코딩하는 접근 방식만큼 효율적이면서도 효과적이다.
Experiments
- 데이터셋: COCO
- 구현 디테일
- 아키텍처
- Diffusion model: stable diffusion (LAION에서 사전학습)
- 텍스트-이미지 discriminative model: CLIP
- 마스크 generator: Mask2Former ($N = 100$)
- 학습 디테일
- iteration: 9만
- 이미지 크기: 1024$\times$1024
- batch size: 64
- $K_\textrm{word} = 8$
- optimizer: AdamW
- learning rate: 0.0001
- weight decay: 0.05
- 아키텍처
1. Comparison with State of the Art
Open-Vocabulary Panoptic Segmentation
다음은 open-vocabulary panoptic segmentation 성능을 비교한 표이다.

다음은 COCO (상단, 중단)와 ADE20K (하단)에 대한 결과를 정성적으로 시각화한 것이다.

Open-Vocabulary Semantic Segmentation
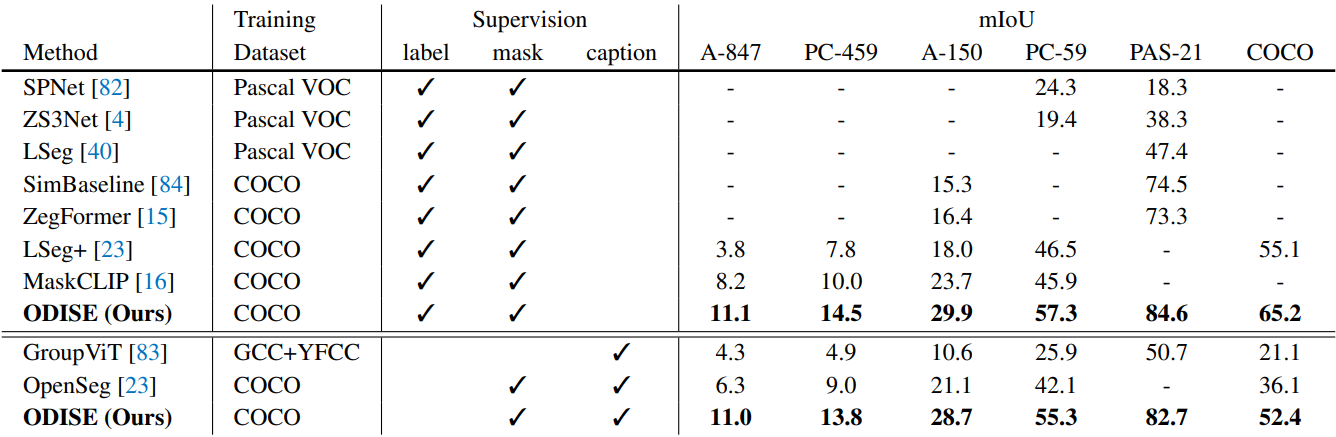
다음은 open-vocabulary semantic segmentation 성능을 비교한 표이다.
2. Ablation Study
Visual Representations
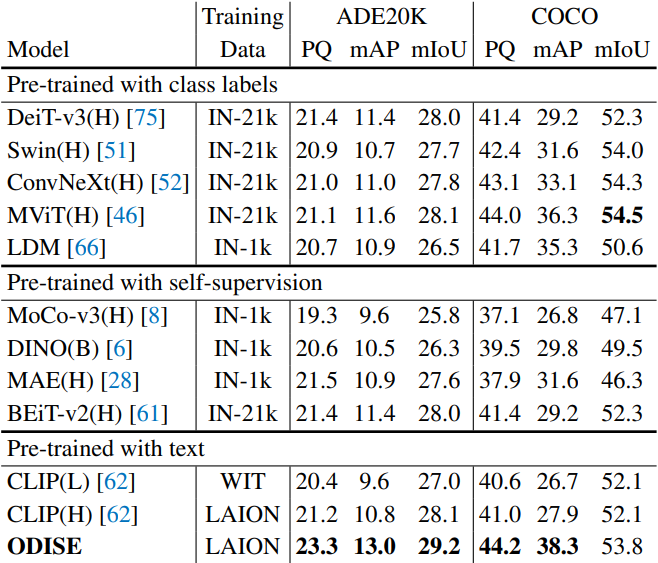
다음은 SOTA 시각적 표현들과 비교한 표이다.
Captioning Generators
다음은 여러 캡션 generator에 대한 ablation 결과이다.

Diffusion Time Steps
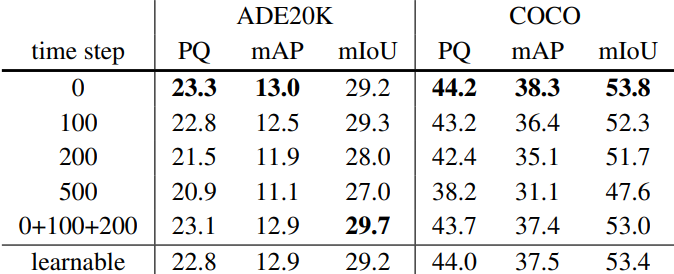
다음은 여러 diffusion timestep에 대한 ablation 결과이다.
Mask Classifiers
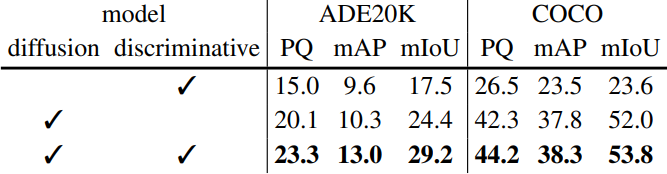
다음은 diffusion model과 discriminative model의 클래스 예측을 융합하는 것에 대한 ablation 결과이다.