[논문리뷰] OctGPT: Octree-based Multiscale Autoregressive Models for 3D Shape Generation
SIGGRAPH 2025. [Paper] [Github]
Si-Tong Wei, Rui-Huan Wang, Chuan-Zhi Zhou, Baoquan Chen, Peng-Shuai Wang
Peking University
14 Apr 2025

Introduction
본 논문에서는 새로운 serialized octree 표현을 활용한 효율적이고 scalable한 3D shape 생성 autoregressive model을 제시하였으며, SOTA diffusion model보다 우수한 품질과 scalability를 달성하였다. 핵심적인 관찰은 octree가 3D shape의 계층적 구조를 본질적으로 포착하는 동시에 autoregressive 예측에 적합한 locality 보존 순서를 제공한다는 점이다. 이는 각 깊이의 octree 노드가 z축 방향으로 정렬되기 때문이다. 입력 shape을 지정된 깊이 또는 해상도로 노드를 재귀적으로 분할하여 octree로 변환한다. 노드 분할 상태를 0/1 바이너리 신호로 간주하고, 이러한 신호를 각 octree 깊이에 걸쳐 coarse-to-fine으로 concat하여 1D 시퀀스를 생성한다.
Octree 구조는 coarse geometry를 효과적으로 포착하지만, 세밀한 디테일은 표현하지 못한다. 본 논문에서는 octree 기반 신경망을 기반으로 구축된 VQVAE를 사용하여 가장 fine한 octree 노드에 정의된 추가적인 바이너리 토큰을 octree에 추가한다. 이 바이너리 토큰들은 바이너리 분할 신호와 concat되어 autoregressive model의 최종 입력 시퀀스를 형성한다. Autoregressive model은 일련의 binary classification task를 통해 바이너리 시퀀스를 예측하도록 학습된다. Inference 과정에서, 예측 결과는 가장 fine한 octree 노드의 바이너리 토큰과 함께, coarse-to-fine으로 octree 구조를 재구성하는 데 사용된다. 이 바이너리 토큰들은 VQVAE의 디코더에 의해 continuous SDF로 디코딩된다. 최종 출력으로, SDF는 marching cubes 알고리즘을 사용하여 메쉬로 변환된다.
기존의 autoregressive model들이 3D 좌표를 직접 예측하는 방식과 달리, 본 논문에서는 생성 작업을 일련의 간단한 binary classification task로 분해하였다. 이러한 방법론은 LLM의 chain-of-thought 패러다임에서 영감을 받았다. 이 접근 방식을 통해 직접적인 좌표 예측 방식보다 훨씬 빠른 수렴 속도와 높은 생성 품질을 달성했다.
Serialized octree 표현의 토큰 길이는 5만 개를 초과할 수 있어, 시간 복잡도가 2차 함수인 단순 autoregressive model 어려움을 초래한다. 이러한 문제를 해결하기 위해, 시간 복잡도를 선형으로 낮추는 여러 개선 사항을 적용한 octree 기반 transformer를 사용하여 13배의 속도 향상을 달성했다. 결과적으로, 본 모델은 NVIDIA 4090 GPU 4개에서 학습될 수 있다. 또한, 제안된 병렬 토큰 예측 방식을 통합하여 생성 프로세스를 69배 가속화하고, 단일 NVIDIA 4090 GPU에서 30초 이내에 $1024^3$ 해상도의 고해상도 3D shape을 생성할 수 있다. 더불어, RoPE를 3D로 확장하고 각 토큰에 대한 스케일별 위치 인코딩을 도입하여 serialized octree 표현에서 멀티스케일 바이너리 신호를 구별하는 모델의 능력을 향상시켰다.
Method

1. Serialized Octree Representation
Octree는 shape의 대략적인 geometry를 포착하는 반면, octree 기반 VQVAE는 세밀한 디테일을 인코딩하고 continuous SDF를 재구성하는 역할을 한다. Octree 구조와 quantize된 코드는 모두 바이너리 시퀀스로 serialize되어 autoregressive model의 입력으로 사용된다.
Serialized Octree
3D shape이 주어지면 먼저 단위 정육면체 안에 맞도록 크기를 조정하고, 지정된 깊이에 도달할 때까지 비어 있지 않은 voxel들을 재귀적으로 세분화하여 octree를 구성한다. 또한, octree의 처음 세 레벨은 전체 부피를 완전히 채우도록 한다. Octree 구조는 각 노드의 분할 상태에 따라 결정되며, 노드들은 무작위로 섞인 키에 따라 z축 방향으로 정렬된다. 특히, z축 정렬 덕분에 공간적 locality가 octree에서 잘 보존된다. 즉, 공간적으로 가까운 octree 노드들은 z축 정렬 곡선에서 인접할 가능성이 높다.
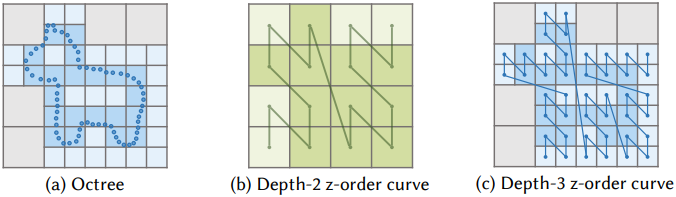
Octree의 최대 깊이를 $D$로, 깊이 $d$에서의 노드 분할 상태를 \(o_i^d \in \{0,1\}\)로 나타내자. 여기서 $𝑖$는 z-order curve에서의 노드 인덱스이며, 0과 1은 각각 분할 없음과 분할됨을 나타낸다. 깊이 $d$에서의 octree 노드들은 바이너리 시퀀스 $O^d = (o_1^d, \ldots, o_{n_d}^d)$로 concat된다. 여기서 $n_d$는 깊이 $d$에서의 노드 개수이다. 깊이 3에서 octree는 완전히 채워져 총 512개의 노드가 된다. 깊이 3부터 시작하여 깊이 $(D - 1)$까지 각 레벨의 바이너리 시퀀스를 concat하여 멀티스케일 바이너리 시퀀스 $\textbf{O} = (O^3, \ldots, O^{D-1})$을 생성한다. 역으로, 이 시퀀스 $\textbf{O}$를 사용하여 octree 구조를 재구성할 수 있으며, 3D shape의 대략적인 geometry를 효과적으로 포착할 수 있다.
Octree 기반 VQVAE
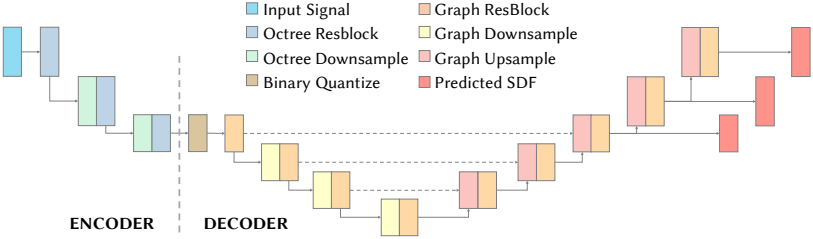
본 논문에서는 octree를 보완하여 3D shape의 SDF와 geometry 디테일을 효율적으로 tokenize하고 재구성하기 위한 octree 기반 VQVAE를 도입하였다. VQVAE는 octree의 가장 fine한 레벨에서 quantize된 바이너리 코드를 생성한다. VQVAE 모델은 비대칭 인코더-디코더 아키텍처를 채택하고 있으며, 특히 디코더의 표면 재구성 정확도를 향상시키는 데 중점을 두었다.
인코더는 octree 기반 CNN (O-CNN)을 기반으로 한다. 3D 메쉬 또는 포인트 클라우드에서 구성된 octree를 시작으로, 인코더는 입력 octree를 leaf node의 feature 표현으로 효율적으로 압축하여 octree의 깊이를 2배로 줄인다. 이러한 feature는 Binary Spherical Quantization (BSQ) 방식을 사용하여 바이너리 토큰으로 quantize된다. 구체적으로, $i$번째 leaf node의 feature 벡터 $z_i \in d$는 다음과 같이 바이너리 토큰 $q_i$로 quantize된다.
\[\begin{equation} q_i = \textrm{sign} \left( \frac{z_i}{\| z_i \|} \right) \end{equation}\]BSQ는 기존 VQ-VAE에서 필요한 codebook을 없애 구현을 단순화하면서도 유사한 재구성 품질을 유지한다. BSQ를 따라 바이너리 토큰이 균일하게 분포되도록 하기 위해 loss function \(\mathcal{L}_\textrm{vq}\)를 사용한다.
이어서 디코더는 dual octree graph network를 사용하여 바이너리 토큰 $q_i$를 로컬 SDF로 디코딩하고, 이를 multi-level Partition-of-Unity 방식을 사용하여 글로벌 SDF로 통합한다. 이 과정을 통해 원본 shape을 일관되고 상세하게 재구성할 수 있다. SDF reconstruction loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{sdf} = \frac{1}{N_\mathcal{P}} \sum_{x \in \mathcal{P}} \left( \lambda \| S(x) - D(x) \|_2^2 + \| \nabla S(x) - \nabla D(x) \|_2^2 \right) \end{equation}\]($S(x)$는 예측된 SDF, $D(x)$는 GT SDF, $\mathcal{P}$는 샘플링된 점들의 집합, \(N_\mathcal{P}\)는 샘플링된 점들의 개수)
이 loss function은 디코더가 연속적인 SDF를 정확하게 재구성하도록 유도한다. 인코더가 octree의 깊이를 줄이기 때문에, 디코더는 octree splitting loss를 사용하여 원래 octree의 깊이를 복원하도록 설계되었다.
VQVAE의 총 loss는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{vq} + \mathcal{L}_\textrm{sdf} + \mathcal{L}_\textrm{octree} \end{equation}\]인코더에서 생성된 바이너리 토큰 $q_i$는 z-order curve에 따라 시퀀스 $\textbf{Q}$를 형성하고, 이 시퀀스는 $\textbf{O}$와 concat되어 최종 serialized octree 표현을 생성한다.
본 논문에서 제시하는 serialized octree 표현은 전체가 바이너리 토큰으로 구성되어 있어 autoregressive model에 의해 쉽게 처리되고 예측될 수 있다. 또한, 이 표현은 3D shape의 멀티스케일 정보를 포착하고 octree 노드의 공간적 locality를 보존한다. 이러한 특성 덕분에 serialized octree 표현은 rasterization 순서보다 autoregressive한 예측에 더욱 적합하다.
2. Multiscale Autoregressive Models
본 논문에서는 serialized octree 표현을 사용하여 autoregressive model을 학습시켜 이를 예측하고, coarse-to-fine으로 점진적으로 3D shape을 생성할 수 있도록 한다. 표준 autoregressive model을 이 표현에 직접 적용하는 것도 가능하지만, 계산 효율이 낮고 최적의 성능을 얻기 어려운 경우가 많다. 이러한 문제점을 해결하기 위해, 저자들은 효율적인 transformer 아키텍처, 맞춤형 위치 인코딩, 다중 토큰 생성 전략을 도입하여 학습 및 생성 효율을 크게 향상시켰다.
효율적인 Transformer 아키텍처
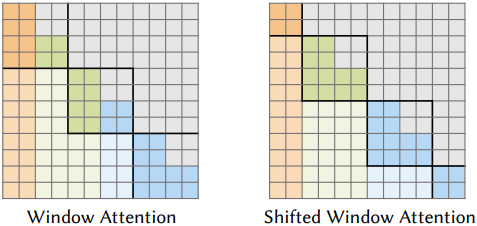
본 논문에서 제시하는 transformer 아키텍처는 multi-head self-attention 모듈과 feed-forward network를 포함하는 attention block들의 stack으로 구성된다. 토큰 시퀀스의 길이가 5만 개를 초과할 수 있다는 점을 고려할 때, 모든 토큰에 대한 self-attention을 계산하는 것은 계산적으로 매우 비효율적이다. 이러한 문제를 해결하기 위해, 토큰을 고정 크기의 window로 나누어 효율적인 self-attention 계산을 가능하게 하는 octree 기반 attention (OctFormer)을 사용한다. 또한, 확장된 octree attention과 shifted window attention을 번갈아 사용하여 서로 다른 window 간의 상호작용을 가능하게 한다. 토큰을 단일 octree 깊이로 제한하는 OctFormer와 달리, 본 논문에서 제시하는 디자인은 다양한 깊이에 있는 노드의 토큰을 수용하여 모든 토큰 간의 포괄적인 상호작용을 가능하게 한다. 이러한 접근 방식은 로컬 dependency와 글로벌 dependency를 모두 포착하여 모델의 3D shape 표현 능력을 향상시킨다.
위치 인코딩
Transformer는 순열 불변성을 가지므로 위치 정보를 모델에 통합해야 한다. 시퀀스의 각 토큰은 단위 정육면체 내의 3D 위치와 관련 깊이를 갖는 octree 노드에 해당한다. 저자들은 위치 정보를 인코딩하기 위해, RoPE2D 디자인을 기반으로 rotary positional encoding (RoPE)을 3D로 확장한 RoPE3D를 제안하였다. 또한, 서로 다른 octree 깊이에 있는 토큰을 구별하기 위해 학습 가능한 스케일 임베딩을 도입한다. 3D 위치 인코딩과 스케일 임베딩을 통합함으로써, transformer는 토큰의 공간적 위치와 깊이를 기반으로 토큰을 효과적으로 구별할 수 있으며, 이는 autoregressive한 3D shape의 정확한 예측에 매우 중요하다.
다중 토큰 생성
표준 autoregressive model은 한 번에 하나의 토큰만 예측하므로, 처리해야 할 토큰 수가 많은 3D shape 생성에는 비효율적일 수 있다. 이러한 한계를 극복하기 위해, 본 논문에서는 masked autoregressive models (MAR)에서 제안된 다중 토큰 생성 전략을 채택하여 여러 토큰을 병렬로 예측할 수 있도록 했다. 이 접근 방식은 3D shape 생성에 필요한 forward pass 횟수를 크게 줄여 효율성을 향상시킨다.
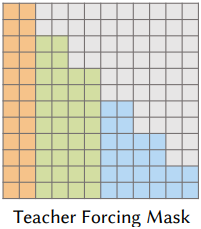
MAR은 시퀀스의 토큰의 순서를 바꾸고 일부를 마스킹한 다음, 모델이 autoregressive 방식으로 예측하는 방식으로 작동한다. 그러나 시퀀스가 여러 octree 깊이의 토큰으로 구성되어 있고, 더 깊은 octree 레이어의 토큰이 더 얕은 레이어의 토큰에 의존하는 경우, MAR을 시퀀스에 직접 적용하면 dependency 문제가 발생할 수 있다. 이러한 문제를 해결하기 위해, 저자들은 깊이별 teacher forcing 마스크를 도입했다. 시퀀스 전체의 순서를 바꾸는 대신, 각 깊이 레벨 내에서 토큰의 순서를 바꿔 더 높은 깊이의 토큰이 더 낮은 깊이의 토큰으로부터 정보를 얻을 수 있도록 하면서 더 높은 깊이의 토큰에서 정보가 유출되는 것을 방지한다. 이를 통해 시퀀스의 계층적 의존성을 유지할 수 있다.
Inference에서 토큰 예측은 깊이 3에서 시작하여 최대 octree 깊이 $D$까지 순차적으로 진행된다. 깊이 3부터 $(D-1)$까지의 토큰은 분할 신호로 해석되어 점진적으로 coarse voxel grid를 생성하고 이를 더 깊은 octree로 정제한다. 깊이 $D$의 토큰은 quantize된 바이너리 코드로 디코딩되어 3D shape의 미세한 디테일을 포착한다. 분할 신호와 quantize된 코드 모두 바이너리 토큰이며, transformer에 연결된 binary classifier를 사용하여 예측된다. 예측된 시퀀스는 VQVAE 디코더에 입력되어 최종 3D shape을 재구성한다.
Experiments
1. 3D Shape Generation
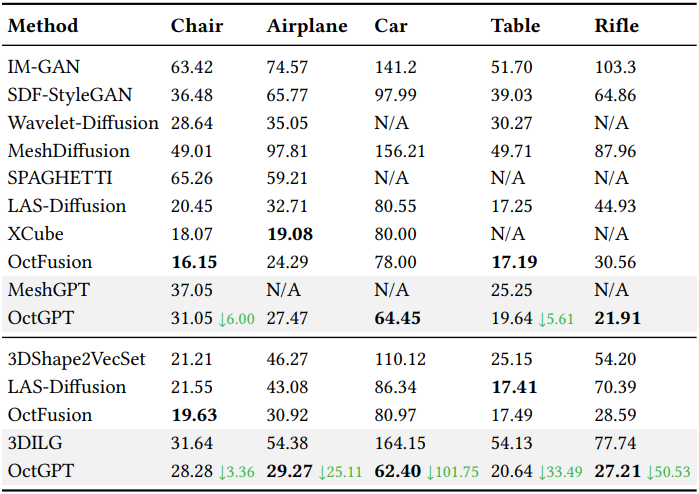
다음은 다른 방법들과의 비교 결과이다.
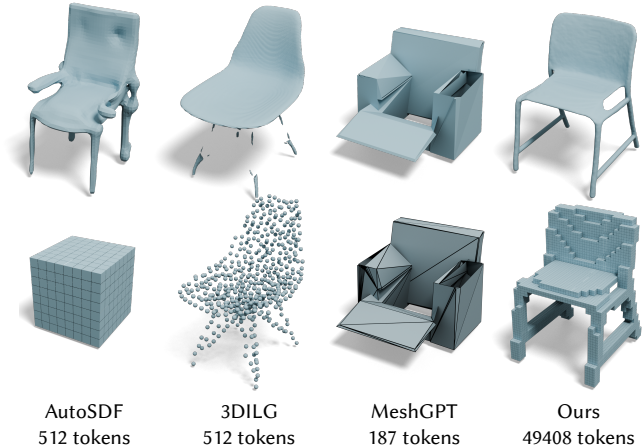

다음은 (왼쪽) ShapeNet 데이터셋과 (오른쪽) Objaverse 데이터셋에 대한 생성 결과이다.

2. Ablation Study and Discussions
다음은 3D causal autoregressive model과의 비교 결과이다.

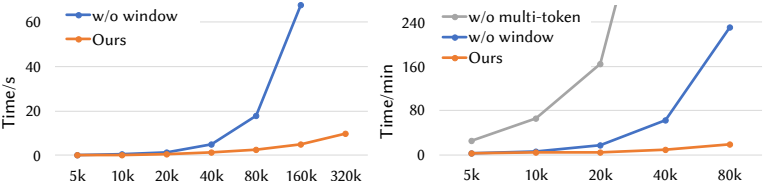
다음은 효율셩에 대한 ablation study 결과이다.
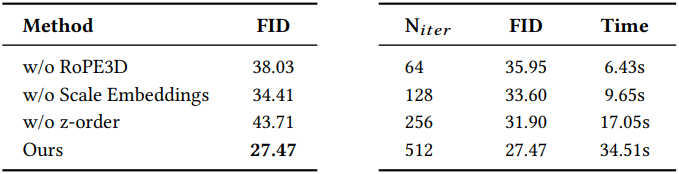
다음은 (왼쪽) 위치 인코딩, z-order와 (오른쪽) 생성 iteration 수에 대한 ablation study 결과이다.
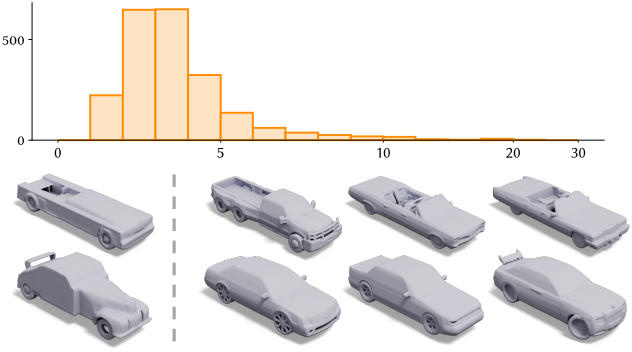
다음은 (위) 생성된 shape들과 학습 데이터 사이의 Chamfer distance (CD) 분포와 (아래) 학습 데이터와 가장 가까운 3개의 생성된 메쉬들이다.
3. Applications
다음은 텍스트 조건부 생성 결과를 비교한 것이다. (위: Objaverse, 아래, ShapeNet)


다음은 스케치 조건부 생성 결과를 비교한 것이다. (ShapeNet)

다음은 이미지 조건부 생성 결과들이다. (ShapeNet)

다음은 장면 수준의 생성 결과이다. (Synthetic Room)
