[논문리뷰] Navigation World Models
CVPR 2025. [Paper] [Page]
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, Yann LeCun
FAIR at Meta, New York University, Berkeley AI Research
4 Dec 2024

Introduction
본 논문에서는 과거 프레임 표현과 action을 기반으로 동영상 프레임의 미래 표현을 예측하도록 학습된 Navigation World Model (NWM)을 제안하였다. NWM은 다양한 로봇 에이전트에서 수집한 동영상과 내비게이션 action에 대해 학습된다. 학습 후, NWM은 잠재적인 내비게이션 policy를 시뮬레이션하고 목표에 도달하는지 확인하여 새로운 궤적을 계획하는 데 사용된다.
저자들은 NWM의 내비게이션 기술을 평가하기 위해 알려진 환경에서 테스트를 진행하였며, 새로운 경로를 독립적으로 계획(planning)하거나 외부 내비게이션 policy의 순위를 매겨 (ranking) 선택하는 능력을 살펴보았다. Planning 셋업의 경우, NWM을 model predictive control (MPC) 프레임워크에서 사용하여 목표 지점에 도달할 수 있는 action 시퀀스를 최적화한다. Ranking 셋업의 경우, NoMaD와 같은 기존 내비게이션 policy에 접근할 수 있다고 가정하고, NWM을 사용해 경로를 샘플링하고 시뮬레이션한 후 최적의 경로를 선택한다. NWM은 독립적인 성능에서도 경쟁력을 갖추고 있으며, 기존 방법과 결합했을 때 SOTA를 달성하였다.
NWM은 RL을 위한 diffusion 기반 world model과 개념적으로 유사하지만, 이런 방법들과 달리 로봇 및 인간 에이전트의 다양한 탐색 데이터를 활용하여 광범위한 환경 및 구현에서 학습된다. 이를 통해 여러 환경에 적응하기 위해 모델 크기와 데이터에 따라 효과적으로 스케일링할 수 있는 대규모 diffusion transformer 모델을 학습시킬 수 있다. 또한 NWM은 novel view synthesis (NVS) 방법에서 영감을 얻었지만, NVS와 달리 다양한 환경에서 탐색을 위한 하나의 모델을 학습하고 3D prior에 의존하지 않고 일반 동영상에서 시간적 역학을 모델링하는 것이 목표이다.
NWM을 학습하기 위해, 저자들은 과거 이미지 state와 action을 컨텍스트로 주어 다음 이미지 state를 예측하도록 학습된 새로운 Conditional Diffusion Transformer (CDiT)를 제안하였다. DiT와 달리 CDiT의 계산 복잡도는 컨텍스트 프레임 수에 대해 선형적이며 다양한 환경과 구현에서 최대 1B 모델로 스케일링되어 표준 DiT에 비해 4배 적은 연산량으로 더 나은 미래 예측 결과를 달성하였다.
NWM은 알려지지 않은 환경의 action 및 reward가 없는 동영상 데이터로 학습하는 데 도움이 된다는 것을 보여준다. 또한, 단일 이미지에서 향상된 동영상 예측 및 생성 성능을 보이며, 레이블이 없는 추가 데이터를 사용하면 더 정확한 예측을 생성한다.
Method
1. Formulation
NWM은 world의 현재 state (ex. 이미지 observation)와 내비게이션 action을 입력받고 world의 다음 state를 생성한다. 구체적으로, egocentric한 동영상 데이터셋과 에이전트의 내비게이션 action \(D = \{(x_0, a_0, \ldots, x_T, a_T)\}_{i=1}^n\)이 주어진다. 여기서 $x_i \in \mathbb{R}^{H \times W \times 3}$은 이미지이고, $a_i = (u, \phi)$는 앞뒤 및 좌우 동작을 제어하는 translation 파라미터 $u \in \mathbb{R}^2$와 yaw rotation angle $\phi \in \mathbb{R}$로 주어진 내비게이션 명령이다.
내비게이션 action $a_i$는 fully observed이다. 예를 들어, 벽을 향해 앞으로 이동하면 물리학에 기반한 환경의 반응이 트리거되어 에이전트가 그 자리에 머무르게 되며, 다른 환경에서는 에이전트의 위치 변경에 따라 내비게이션 action을 계산한다.
목표는 이전 latent observation \(\textbf{s}_\tau\)와 action $a_\tau$에서 미래 latent state 표현 \(s_{\tau+1}\)로의 확률적 매핑인 world model $F$를 학습하는 것이다.
\[\begin{equation} s_i = \textrm{enc}_\theta (x_i), \quad s_{\tau+1} \sim F_\theta (s_{\tau+1} \vert \textbf{s}_\tau, a_\tau) \end{equation}\]여기서 \(\textbf{s}_\tau = (s_\tau, \ldots, s_{\tau−m})\)은 사전 학습된 VAE를 통해 인코딩된 과거 $m$개의 visual observation이다. VAE를 사용하면 압축된 latent 데이터를 사용하여 예측을 픽셀 공간으로 디코딩할 수 있다는 이점이 있다.
이 공식의 단순성으로 인해 자연스럽게 여러 환경에서 공유될 수 있으며 로봇 팔을 제어하는 것과 같이 더 복잡한 action space로 쉽게 확장될 수 있다. 기존 방법들과 달리, NWM은 task나 action 임베딩들을 사용하지 않고 여러 환경들에 대한 하나의 world model을 학습시키는 것을 목표로 하였다.
위 공식은 action을 모델링하지만 시간적 역학에 대한 제어를 허용하지 않는다. 이 공식을 time shift 입력 \(k \in [T_\textrm{min}, T_\textrm{max}]\)로 확장하여 \(a_\tau = (u, \phi, k)\)로 설정하면, $a_\tau$는 모델이 미래 또는 과거로 이동해야 하는 step 수를 결정하는 데 사용되는 시간 변화 $k$를 지정한다. 따라서 현재 state $s_\tau$가 주어지면 무작위로 $k$를 선택하고, 해당 동영상 프레임을 tokenize한 다음 $s_{\tau+1}$을 해당 토큰 집합으로 설정할 수 있다. 이 경우 내비게이션 action을 시간 $\tau$에서 $\tau + k$까지의 합으로 근사할 수 있다.
\[\begin{equation} u_{\tau \rightarrow \tau + k} = \sum_{t=\tau}^{\tau+k} u_t, \quad \phi_{\tau \rightarrow \tau+k} = \sum_{t=\tau}^{\tau+k} \phi_t \textrm{ mod } 2\pi \end{equation}\]이 공식은 내비게이션 action과 환경 시간 역학을 모두 학습할 수 있게 해준다. 실제로는 최대 ±16초의 time shift을 허용한다.
발생할 수 있는 한 가지 문제는 action과 시간의 얽힘(entanglement)이다. 예를 들어, 특정 위치에 도달하는 것이 항상 특정 시간에 발생하는 경우, 모델은 시간에만 의존하고 이후의 action을 무시하거나 그 반대로 학습할 수 있다. 실제로 데이터에는 동일한 지역에 다른 시간에 도달할 수 있다. 이를 장려하기 위해 학습 중에 각 stae에 대해 여러 목적지를 샘플링한다.
2. Diffusion Transformer as World Model
\(F_\theta\)를 확률적 매핑으로 설계하여 확률적인 환경을 시뮬레이션할 수 있다. 이를 위해 Conditional Diffusion Transformer (CDiT) 모델를 사용한다.
CDiT 아키텍처
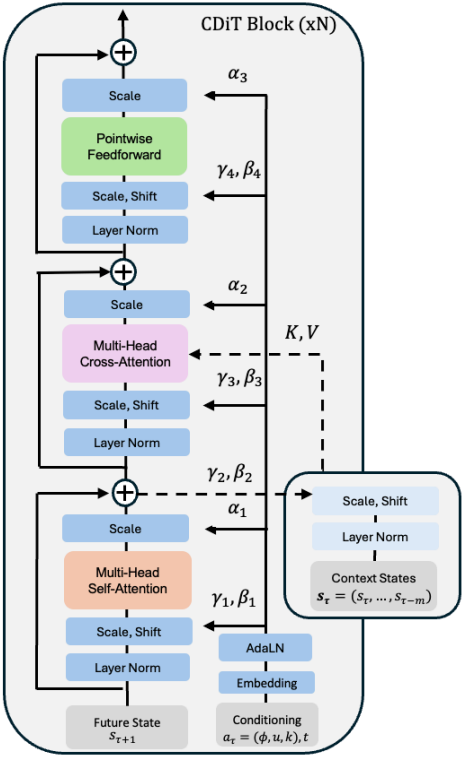
사용하는 아키텍처는 효율적인 CDiT block을 활용하는 시간적으로 autoregressive한 transformer 모델로, 입력 action 컨디셔닝을 통해 입력 시퀀스의 latent들에 $N$번 적용된다.
CDiT는 첫 번째 attention block의 attention을 denoise되는 타겟 프레임의 토큰으로만 제한하여 시간 효율적인 autoregressive한 모델링을 가능하게 한다. 과거 프레임의 토큰으로 컨디셔닝 하기 위해, cross-attention layer를 통합하여 현재 타겟의 모든 query 토큰이 key와 value로 사용되는 과거 프레임의 토큰에 attention하도록 한다. 그런 다음, cross-attention은 skip connection layer를 사용하여 표현을 컨텍스트화한다.
이동 $u$, 회전 $\phi$, time shift $k$와 같은 연속적인 action과 diffusion timestep $t$를 조건으로 하기 위해 각 scaler를 사인-코사인 feature에 매핑한 다음, 2-layer MLP \(G : \mathbb{R} \rightarrow \mathbb{R}^d\)를 적용한다. 마지막으로 모든 임베딩을 하나의 벡터로 합산한다.
\[\begin{equation} \xi = G_u (\psi (u)) + G_\theta (\psi (\theta)) + G_k (\psi (k)) + G_t (\psi (t)) \end{equation}\]그런 다음 $\xi$는 AdaLN block에 공급되어 Layer Normalization의 출력과 attention layer들의 출력을 조절하는 scale 및 shift 계수를 생성한다. 레이블이 없는 데이터에서 학습하기 위해, $\xi$를 계산할 때 명시적인 내비게이션 action을 생략한다.
전체 입력에 DiT를 적용하는 것은 계산적으로 비용이 많이 든다. 프레임당 입력 토큰 수를 $n$, 프레임 수를 $m$, 토큰 차원을 $d$라 하면, multi-head attention layer 복잡도는 컨텍스트 길이의 제곱에 비례하는 attention의 복잡도 $O(m^2 \cdot n^2 \cdot d)$에 의해 지배된다. 반면에 CDiT block은 컨텍스트에 대해 선형적인 cross-attention layer의 복잡도 $O(m \cdot n^2 \cdot d)$에 의해 지배되므로 더 긴 컨텍스트 크기를 사용할 수 있다. CDiT는 컨텍스트 토큰에 비용이 많이 드는 self-attention을 적용하지 않는다.
Diffusion 학습
Forward process에서는 무작위로 선택된 timestep \(t \in \{1, \ldots, T\}\)에 따라 타겟 state \(s_{\tau+1}\)에 noise가 추가된다. Noise가 추가된 state $s_{\tau+1}^{(t)}$는 다음과 같이 정의할 수 있다.
\[\begin{equation} s_{\tau+1}^{(t)} = \sqrt{\alpha_t} s_{\tau+1} + \sqrt{1 - \alpha_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0,I) \end{equation}\]\(\{\alpha_t\}\)는 분산을 제어하는 noise schedule이며, $t$가 증가함에 따라 $s_{\tau+1}^{(t)}$는 순수한 noise로 수렴한다.
Reverse process는 컨텍스트 \(\textbf{s}_\tau\), 현재 action $a_\tau$, diffusion timestep $t$를 조건으로 $s_{\tau+1}^{(t)}$에서 원래 state 표현 $s_{\tau+1}$을 복구하려고 시도한다.
목적 함수
$F_\theta$를 각 step에서 추가되는 noise를 예측하는 신경망으로 정의하면, 모델은 타겟 state $s_{\tau+1}$과 예측된 타겟 state \(F_\theta (s_{\tau+1}^{(t)} \vert \textbf{s}_\tau , a_\tau, t)\) 사이의 MSE를 최소화하도록 학습된다.
\[\begin{equation} \mathcal{L}_\theta = \mathbb{E}_{s_{\tau+1}, a_\tau, \textbf{s}_\tau, \epsilon, t} [\| s_{\tau+1} - F_\theta (s_{\tau+1}^{(t)} \vert \textbf{s}_\tau, a_\tau, t) \|^2] \end{equation}\]$t$는 무작위로 샘플링되어 모델이 모든 수준의 손상에서 프레임의 noise를 제거하는 방법을 학습한다. 이 loss를 최소화함으로써 모델은 컨텍스트 \(\textbf{s}_\tau\)와 action $a_\tau$에 따라 $s_{\tau+1}^{(t)}$에서 $s_{\tau+1}$을 재구성하는 방법을 학습하여 현실적인 미래 프레임을 생성한다.
3. Navigation Planning with World Models
학습된 NWM이 환경에 익숙하다면, 그것을 사용하여 내비게이션 궤적들을 시뮬레이션하고 그 중에서 목적지에 도달하는 것을 선택할 수 있다. 알려지지 않은 분포가 없는 환경의 경우, 장기적인 planning은 상상력에 의존할 수 있다.
Latent 인코딩 $s_0$와 내비게이션 목적지 $s^\ast$가 주어졌을 때, $s^\ast$에 도달할 likelihood를 최대화하는 일련의 action $(a_0, \ldots, a_T)$를 찾아야 한다. 이를 위해, 에너지 함수 $\mathcal{E} (s_0, a_0, \ldots, a_T, s_T)$를 정의한다.
\[\begin{equation} \mathcal{E} (s_0, a_0, \ldots, a_T, s_T) = - \mathcal{S} (s_T, s^\ast) + \sum_{\tau=0}^T \mathbb{I} (a_\tau \notin \mathcal{A}_\textrm{valid}) + \sum_{\tau=0}^T \mathbb{I} (s_\tau \notin \mathcal{S}_\textrm{safe}) \end{equation}\]($\mathbb{I}(\cdot)$는 indicator function)
$\mathcal{S}(s_T, s^\ast)$는 NWM에 의해 autoregressive하게 전개되어 얻어진 $s_T$로부터 $s^\ast$에 도달하기 위한 정규화되지 않은 점수이며, 사전 학습된 VAE 디코더를 사용하여 $s^\ast$와 $s_T$를 픽셀로 디코딩한 다음 perceptual similarity를 측정하여 계산한다. “절대 왼쪽으로 갔다가 다시 오른쪽으로 가지 않는다”와 같은 제약은 $a_\tau$를 유효한 action 집합 \(\mathcal{A}_\textrm{valid}\)에 제한함으로써 표현할 수 있고, “절벽 가장자리를 탐험하지 않는다”와 같은 제약은 해당 state $s_\tau$가 안전한 state 집합 \(\mathcal{S}_\textrm{sate}\)에 속하도록 보장함으로써 표현할 수 있다.
즉, 에너지를 최소화하는 것은 perceptual similarity 점수를 최대화하고 state와 action에 대한 잠재적 제약을 따르는 것과 같다.
그러면 문제는 이 에너지 함수를 최소화하는 action들을 찾는 것으로 축소된다.
\[\begin{equation} a_0, \ldots, a_T = \underset{a_0, \ldots, a_T}{\arg \min} \; \mathbb{E}_{\textbf{s}} [\mathcal{E} (s_0, a_0, \ldots, a_T, s_T)] \end{equation}\]이 목표는 model predictive control (MPC) 문제로 재구성할 수 있으며, 이를 최적화하기 위해 최근 world model을 사용한 planning에서 활용된 단순하고 미분에 의존하지 않는 집단 기반 최적화 방법인 Cross-Entropy Method를 사용한다.
Ranking Navigation Trajectories
기존 navigation policy $\Pi (\textbf{a} \vert s_0, s^\ast)$가 있다고 가정하면 NWM을 사용하여 샘플링된 궤적들의 순위를 매길 수 있다. 저자들은 로봇 내비게이션을 위한 SOTA 내비게이션 policy인 NoMaD를 사용하였다. 궤적의 순위를 매기기 위해 $\Pi$에서 여러 샘플을 추출하여 에너지가 가장 낮은 샘플을 선택한다.
Experiments
- 구현 디테일
- VAE: Stable Diffusion의 VAE
- 컨텍스트 길이: 4 프레임
- batch size: 1024
- optimizer: AdamW (learning rate = $8 \times 10^{-5}$)
- GPU: NVIDIA H100 64개
1. Ablations
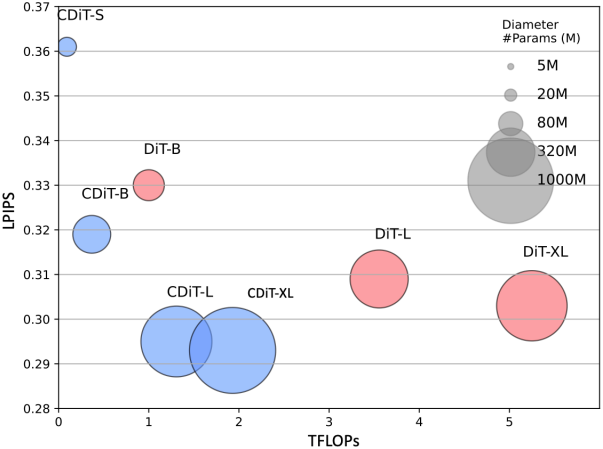
다음은 DiT와 CDiT의 예측 성능과 연산량을 비교한 그래프이다.
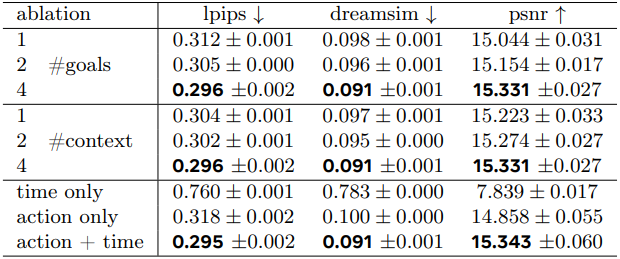
다음은 샘플 수, 컨텍스트 크기, 컨디셔닝에 대한 ablation 결과이다.
2. Video Prediction and Synthesis
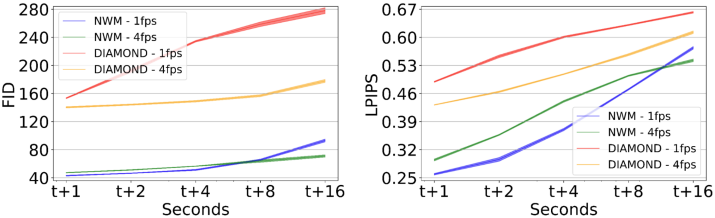
다음은 동영상 생성 정확도와 품질을 비교한 그래프이다.
다음은 동영상 합성 품질을 비교한 표이다.

3. Planning Using a Navigation World Model
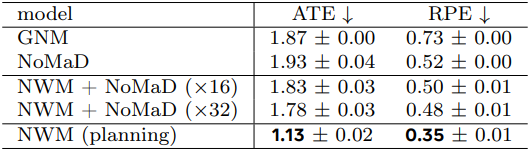
다음은 목적지를 조건으로 주었을 때의 내비게이션 결과를 비교한 표이다.
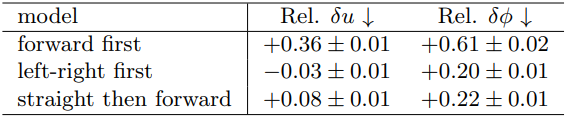
다음은 제약 조건을 주었을 때의 planning 결과이다.

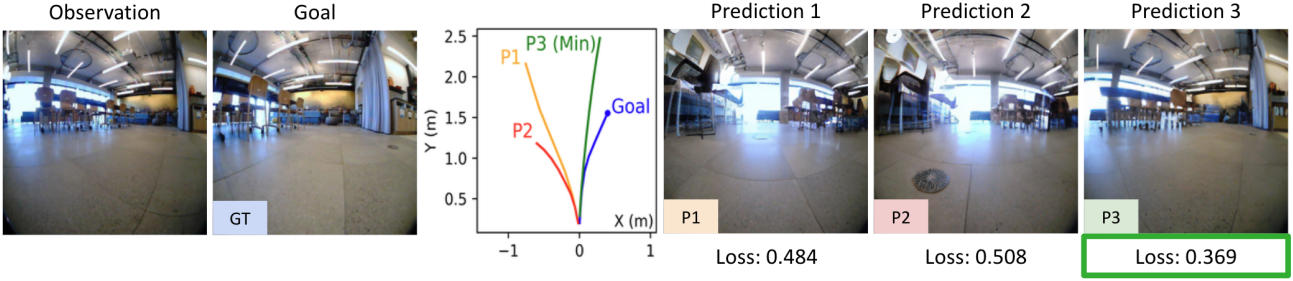
다음은 NoMaD로 샘플링한 궤적들의 순위를 매긴 예시이다.
4. Generalization to Unknown Environments
다음은 레이블이 없는 데이터로 추가로 학습시켰을 때의 결과로, 처음 보는 환경에 대한 성능이 향상되었다.

Limitations

- Out of distribution 데이터에 적용했을 때, 모델은 천천히 컨텍스트를 잃고 학습 데이터와 유사한 다음 state를 생성하는 경향이 있다.
- 모델은 planning할 수 있지만 보행자의 움직임과 같은 시간적 역학을 시뮬레이션하는 데 어려움을 겪는다.