[논문리뷰] Null-text Inversion for Editing Real Images using Guided Diffusion Models
CVPR 2023. [Paper] [Page] [Github]
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, Daniel Cohen-Or
Google Research | Tel Aviv University
17 Nov 2022

Introduction
Text-guided diffusion model을 사용한 이미지 합성의 발전은 뛰어난 사실성과 다양성으로 인해 많은 관심을 끌었다. 대규모 모델은 수많은 사용자의 상상력에 불을 붙여 전례 없는 창의적 자유로 이미지 생성을 가능하게 했다. 당연히 이미지 편집을 위해 이러한 강력한 모델을 활용하는 방법을 조사하는 지속적인 연구 노력이 있었다. 가장 최근에는 합성 이미지에 대한 직관적인 텍스트 기반 편집이 시연되어 사용자가 텍스트만으로 이미지를 쉽게 조작할 수 있다.
그러나 이러한 SOTA 도구를 사용하여 실제 이미지를 텍스트 가이드로 편집하려면 주어진 이미지와 텍스트 프롬프트를 반전(invert)해야 한다. 즉, 모델의 편집 능력을 유지하면서 diffusion process에 프롬프트와 함께 공급될 때 입력 이미지를 생성하는 초기 noise 벡터를 찾는 것이다. Inversion process는 최근 GAN에 대해 상당한 관심을 끌었지만 text-guided diffusion model에 대해서는 아직 완전히 다루지 않았다. Unconditional diffusion model에 대해서는 효과적인 DDIM inversion 기법이 제안되었지만, 의미 있는 편집에 필요한 classifier-free guidance를 적용할 때 text-guided diffusion model에는 부족한 것으로 나타났다.
본 논문에서는 원래 모델의 풍부한 텍스트 기반 편집 능력을 유지하면서 거의 완벽에 가까운 재구성을 달성하는 효과적인 inversion 체계를 소개한다. 본 논문의 접근 방식은 guided diffusion model의 두 가지 주요 측면인 classifier-free guidance와 DDIM inversion에 대한 분석을 기반으로 한다.
널리 사용되는 classifier-free guidance에서는 각 diffusion step에서 예측이 두 번 수행된다. 한 번은 unconditional하게, 한 번은 텍스트 조건부로 수행된다. 그런 다음 이러한 예측은 텍스트 guidance의 효과를 증폭하기 위해 외삽(interpolate)된다. 모든 연구들이 조건부 예측에 집중되어 있지만 저자들은 unconditional한 부분에서 가이드되는 실질적인 효과를 인식하였다. 따라서 입력 이미지와 프롬프트를 반전시키기 위해 unconditional한 부분에 사용된 임베딩을 최적화한다. 빈 텍스트 문자열의 임베딩을 최적화된 임베딩으로 대체하므로 이를 null-text optimization이라고 한다.
DDIM inversion은 DDIM 샘플링을 역순으로 수행하는 것으로 구성된다. 각 step에서 약간의 오차가 발생하지만 이것은 unconditional한 경우에 잘 작동한다. 그러나 실제로는 classifier-free guidance가 누적된 오차를 확대하기 때문에 텍스트 기반 합성에 적합하지 않다. 저자들은 그것이 inversion을 위한 유망한 출발점을 여전히 제공할 수 있음을 관찰하였다. GAN 논문에서 영감을 받아 초기 DDIM inversion에서 얻은 noised latent code를 피벗으로 사용한다. 그런 다음 이 피벗을 중심으로 최적화를 수행하여 개선되고 더 정확한 inversion을 생성한다. 가능한 모든 noise 벡터를 단일 이미지에 매핑하는 것을 목표로 하는 기존 연구들과 대조되는 이 매우 효율적인 최적화를 Diffusion Pivotal Inversion이라고 한다.
본 논문의 접근 방식은 실제 이미지에서 Prompt-to-Prompt의 텍스트 편집 기술을 활성화하는 첫 번째 방법이다. 또한 최근 접근 방식과 달리 모델 가중치를 조정하지 않으므로 학습된 모델의 prior 손상을 방지하고 각 이미지에 대해 전체 모델을 복제한다.
Method
$\mathcal{I}$를 실제 이미지라고 하자. 본 논문의 목표는 텍스트 guidance만 사용하여 $\mathcal{I}$를 편집하여 편집된 이미지 $\mathcal{I}^\ast$를 얻는 것이다. Prompt-to-Prompt에 의해 정의된 설정을 사용한다. 여기서 편집은 소스 프롬프트 $\mathcal{P}$와 편집된 프롬프트 $\mathcal{P}^\ast$에 의해 가이드된다. 이렇게 하려면 사용자가 소스 프롬프트를 제공해야 한다. 그러나 저자들은 기존 캡션 모델을 사용하여 소스 프롬프트를 자동으로 생성하는 것이 잘 작동한다는 것을 발견했다. 예를 들어, 이미지와 소스 프롬프트 “A baby wearing…“가 주어지면 편집된 프롬프트 “A robot wearing…“를 제공하여 아기를 로봇으로 대체한다.
이러한 편집 연산은 먼저 $\mathcal{I}$를 모델의 출력 도메인으로 반전시켜야 한다. 즉, 주요 과제는 직관적인 텍스트 기반 편집 능력을 유지하면서 소스 프롬프트 $\mathcal{P}$를 모델에 공급하여 충실하게 $\mathcal{I}$를 재구성하는 것이다.
본 논문의 접근 방식은 두 가지 주요 관찰을 기반으로 한다.
- DDIM inversion은 classifier-free guidance가 적용될 때 만족스럽지 못한 재구성을 생성하지만 최적화를 위한 좋은 출발점을 제공하여 고충실도 inversion을 효율적으로 달성할 수 있다.
- Classifier-free guidance에서 사용되는 unconditional null embedding을 최적화하면 모델의 튜닝과 조건부 임베딩을 피하면서 정확한 재구성이 가능하다. 따라서 원하는 편집 능력을 유지한다.
전체 개요는 아래와 같다.
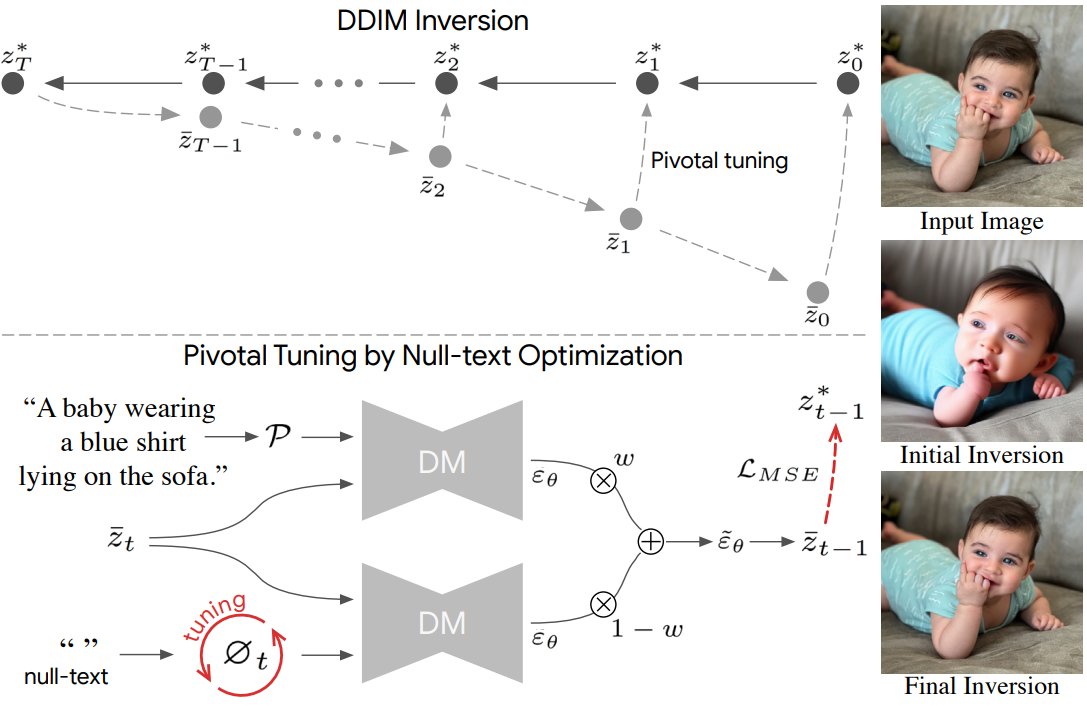
1. Background and Preliminaries
Text-guided diffusion model은 랜덤 noise 벡터 $z_t$와 텍스트 조건 $\mathcal{P}$를 주어진 조건 프롬프트에 해당하는 출력 이미지 $z_0$에 매핑하는 것을 목표로 한다. 순차적인 denoising을 수행하기 위해 네트워크 $\epsilon_\theta$는 다음 목적 함수에 따라 인공 noise를 예측하도록 학습된다.
\[\begin{equation} \min_\theta \mathbb{E}_{z_0, \epsilon \sim \mathcal{N}(0,I), t \sim \textrm{Uniform} (1,T)} \| \epsilon - \epsilon_\theta (z_t, t, \mathcal{C}) \|_2^2 \end{equation}\]$\mathcal{C} = \psi (\mathcal{P})$는 텍스트 조건의 임베딩이고 $z_t$는 timestep $t$에 따라 샘플링된 데이터 $z_0$에 noise가 추가된 noisy한 샘플이다. Inference에서 noise 벡터 $z_T$가 주어지면 $T$ step에 대해 학습된 네트워크를 사용하여 noise는 순차적으로 예측되어 점진적으로 제거된다.
주어진 실제 이미지를 정확하게 재구성하는 것을 목표로 하기 때문에 deterministic DDIM sampling을 사용한다.
\[\begin{equation} z_{t-1} = \sqrt{\frac{\alpha_{t-1}}{\alpha_t}} z_t + \bigg( \sqrt{\frac{1}{\alpha_{t-1}} - 1} - \sqrt{\frac{1}{\alpha_t} - 1} \bigg) \cdot \epsilon_\theta (z_t, t, \mathcal{C}) \end{equation}\]Diffusion model은 종종 $z_0$가 실제 이미지의 샘플인 이미지 픽셀 space에서 작동한다. 본 논문의 경우, latent 이미지 인코딩 $z_0 = E (x_0)$에 forward process가 적용되고 reverse process의 끝에 이미지 디코더가 사용되는 ($x_0 = D (z_0)$) Stable Diffusion 모델을 사용한다.
Classifier-free guidance
텍스트 기반 생성의 주요 과제 중 하나는 조건부 텍스트에 의해 가이드된 효과의 증폭이다. 이를 위해 예측도 unconditional하게 수행한 다음 조건부 예측으로 외삽하는 classifier-free guidance 기법이 제시되었다.
$\varnothing = \psi(“”)$가 null-text의 임베딩이고 $w$가 guidance scale 파라미터라고 하면 classifier-free guidance는 다음과 같이 정의된다.
\[\begin{equation} \tilde{\epsilon}_\theta (z_t, t, \mathcal{C}, \varnothing) = w \cdot \epsilon_\theta (z_t, t, \mathcal{C}) + (1-w) \cdot \epsilon_\theta (z_t, t, \varnothing) \end{equation}\]Stable Diffusion의 경우 $w = 7.5$가 기본 파라미터이다.
DDIM inversion
ODE 프로세스가 작은 step의 극한에서 reverse될 수 있다는 가정을 기반으로 DDIM 샘플링에 대해 간단한 inversion 기술이 제안되었다.
\[\begin{equation} z_{t+1} = \sqrt{\frac{\alpha_{t+1}}{\alpha_t}} z_t + \bigg( \sqrt{\frac{1}{\alpha_{t+1}} - 1} - \sqrt{\frac{1}{\alpha_t} - 1} \bigg) \cdot \epsilon_\theta (z_t, t, \mathcal{C}) \end{equation}\]즉 $z_T \rightarrow z_0$가 아닌 $z_0 \rightarrow z_T$의 방향으로 diffusion process가 수행되며, 여기서 $z_0$은 주어진 실제 이미지의 인코딩이다.
2. Pivotal Inversion
최근 inversion 연구들은 모든 noise 벡터를 단일 이미지에 매핑하는 것을 목표로 최적화의 각 iteration에 대해 임의의 noise 벡터를 사용한다. Inference에는 단일 noise 벡터만 필요하므로 이것이 비효율적이다. 대신, GAN 논문에서 영감을 얻어 이상적으로는 단일 noise 벡터만 사용하여 보다 로컬한 최적화를 수행한다. 특히, 좋은 근사값인 pivotal noise vector를 중심으로 최적화를 수행하여 보다 효율적인 inversion을 허용하는 것을 목표로 한다.
저자들은 DDIM inversion을 연구하는 것으로 시작하였다. 실제로는 모든 step에 약간의 오차가 포함된다. Unconditional diffusion model의 경우 누적 오차는 무시할 수 있으며 DDIM inversion이 성공한다. 그러나 Stable Diffusion 모델을 사용하는 의미 있는 편집에는 큰 guidance scale $w > 1$로 classifier-free guidance를 적용해야 한다. 이러한 guidance scale은 누적 오차를 증폭시킨다. 따라서 classifier-free guidance로 DDIM inversion 절차를 수행하면 시각적 아티팩트가 발생할 뿐만 아니라 획득한 noise 벡터가 가우시안 분포를 벗어날 수 있다. 이는 편집 가능성, 즉 특정 noise 벡터를 사용하여 편집하는 능력을 감소시킨다.
Guidance scale $w = 1$로 DDIM inversion을 사용하면 편집 가능성은 높지만 정확하지는 않은 원본 이미지의 대략적인 근사치를 제공한다. 보다 구체적으로, 반전된 DDIM은 이미지 인코딩 $z_0$에서 Gaussian noise 벡터 $z_T^\ast$ 사이의 $T$ step 궤적을 생성한다. 편집에는 큰 guidance scale이 필수적이다. 따라서 classifier-free guidance ($w > 1$)를 사용하여 $z_T^\ast$를 diffusion process에 공급하는 데 중점을 둔다. 이로 인해 중간 latent code가 궤적에서 벗어나기 때문에 편집 가능성은 높지만 재구성이 부정확하다.
높은 편집 가능성에 동기를 부여하여 $w = 1$인 이 초기 DDIM inversion을 피벗 궤적으로 참조하고 표준 guidance scale인 $w > 1$을 사용하여 최적화를 수행한다. 즉, 최적화는 원본 이미지와의 유사성을 최대화하면서 의미 있는 편집을 수행할 수 있는 능력을 유지한다. 실제로, 초기 궤적 $z_T^\ast \rightarrow z_0^\ast$에 가능한 한 가까워지는 다음과 같은 목적 함수를 $t = T \rightarrow t = 1$의 순서로 사용하여 각 $t$에 대해 별도의 최적화를 실행한다.
\[\begin{equation} \min \| z_{t-1}^\ast - z_{t-1} \|_2^2 \end{equation}\]여기서 $z_{t−1}$은 최적화의 중간 결과이다. Pivotal DDIM inversion이 다소 좋은 출발점을 제공하므로 이 최적화는 랜덤 noise 벡터를 사용하는 것과 비교할 때 매우 효율적이다.
모든 $t < T$에 대해 최적화는 이전 step $t + 1$ 최적화의 끝점에서 시작해야 한다. 그렇지 않으면 최적화된 궤적이 inference에서 유지되지 않는다. 따라서 step $t$의 최적화 후 현재 noisy latent \(\bar{z̅}_t\)를 계산하고 이를 다음 step의 최적화에 사용하여 새로운 궤적이 $z_0$ 근처에서 끝나도록 한다.
3. Null-text optimization
실제 이미지를 모델의 도메인으로 성공적으로 변환하기 위해 최근 연구들은 텍스트 인코딩, 네트워크 가중치 또는 둘 다를 최적화한다. 각 이미지에 대한 모델의 가중치를 fine-tuning하려면 전체 모델을 복제해야 하므로 메모리 소비 측면에서 매우 비효율적이다. 게다가 각각의 모든 편집에 대해 fine-tuning이 적용되지 않는 한, 모델의 학습된 prior와 편집의 semantic을 손상시킬 수밖에 없다. 텍스트 임베딩을 직접 최적화하면 최적화된 토큰이 기존 단어와 반드시 일치하지는 않기 때문에 해석할 수 없는 표현이 된다. 따라서 직관적인 프롬프트 간 편집이 더욱 어려워진다.
대신 classifier-free guidance의 핵심 특성, 결과가 unconditional한 예측의 영향을 많이 받는다는 점을 활용한다. 따라서 기본 null-text 임베딩을 null-text optimization이라고 하는 최적화된 것으로 바꾼다. 즉, 각 입력 이미지에 대해 null-text 임베딩으로 초기화된 unconditional embedding $\varnothing$만 최적화한다. 모델과 조건부 텍스트 임베딩은 변경되지 않고 유지된다.
따라서 최적화된 unconditional embedding을 사용하여 Prompt-to-Prompt로 직관적인 편집이 가능하면서도 고품질 재구성이 가능하다. 또한 단일 inversion 프로세스 후에 동일한 unconditional embedding을 입력 이미지에 대한 여러 편집 작업에 사용할 수 있다. Null-text optimization은 전체 모델을 fine-tuning하는 것보다 표현력이 떨어지기 때문에 보다 효율적인 pivotal inversion 체계가 필요하다.
단일 unconditional embedding $\varnothing$의 최적화를 global null-text optimization라고 한다. 저자들은 각 timestep $t$에 대해 서로 다른 unconditional embedding $\varnothing_t$를 최적화하면 재구성 품질이 크게 향상되며 이것이 pivotal inversion에 매우 적합하다는 것을 관찰했다. 따라서 timestep별 unconditional embedding \(\{\varnothing_t\}_{t=1}^T\)을 사용하고 이전 step의 임베딩 $\varnothing_{t+1}$으로 $\varnothing_t$를 초기화한다.

두 구성 요소를 함께 넣은 전체 알고리즘은 Algorithm 1과 같다. $w = 1$인 DDIM inversion은 noisy latent code $z_T^\ast, \cdots, z_0^\ast$의 시퀀스를 출력한다. 여기서 $z_0^\ast = z_0$이다. \(\bar{z}_T = z_t\)로 초기화하고 timestep $t = T, \cdots, 1$과 각 iteration에 대해 기본 guidance scale $w = 7.5$로 다음과 같은 최적화를 수행한다.
단순화를 위해 \(z_{t-1} (\bar{z}_t, \varnothing_t, \mathcal{C})\)는 \(\bar{z}_t\), unconditional embedding $\varnothing_t$, 조건부 임베딩 $\mathcal{C}$를 사용하여 DDIM 샘플링 step을 적용하는 것을 나타낸다. 각 step의 끝에서 업데이트한다.
\[\begin{equation} \bar{z}_{t-1} = z_{t-1} (\bar{z}_t, \varnothing_t, \mathcal{C}) \end{equation}\]마지막으로 noise \(\bar{z}_T = z_T^\ast\)와 최적화된 unconditional embedding \(\{\varnothing_t\}_{t=1}^T\)을 사용하여 실제 입력 이미지를 편집할 수 있다.
Ablation Study
다음은 전체 알고리즘(녹색 선)의 성능을 다양한 변형과 비교하고 PSNR 점수를 최적화 iteration 수에 따라 측정하여 재구성 품질을 평가한 그래프이다.
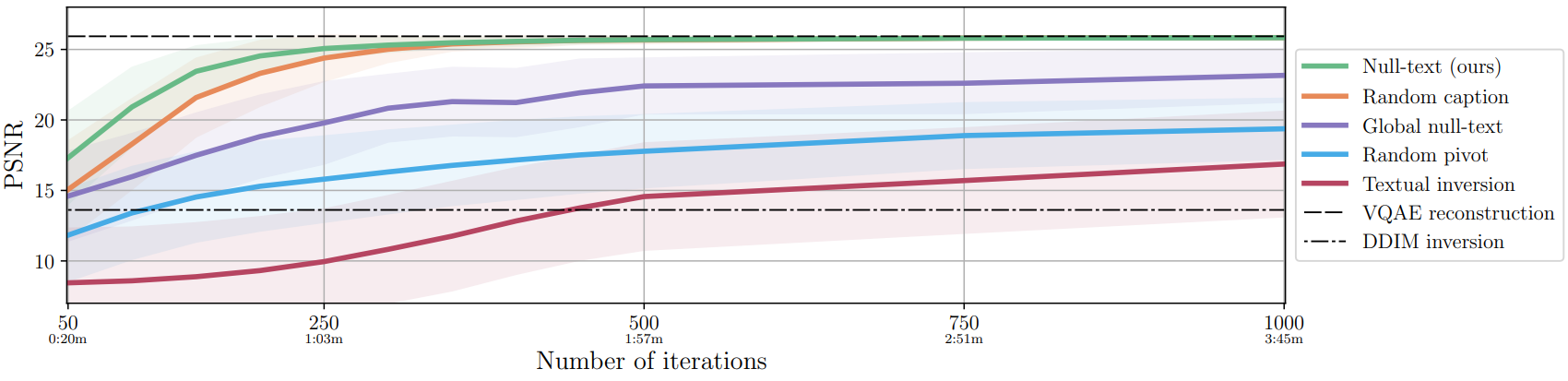
다음은 200 iteration 후의 inversion 결과를 비교한 것이다.

Results
다음은 실제 이미지 편집 결과이다.

다음은 attention re-weighting을 사용한 세밀한 제어 편집 예시이다.

1. Comparisons
다음은 기존 방법들과 비교한 결과이다.

다음은 마스크 기반 방법들과 비교한 결과이다.

다음은 user study 결과이다.
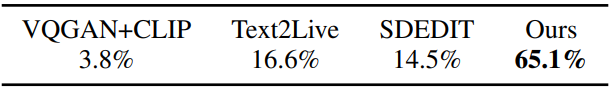
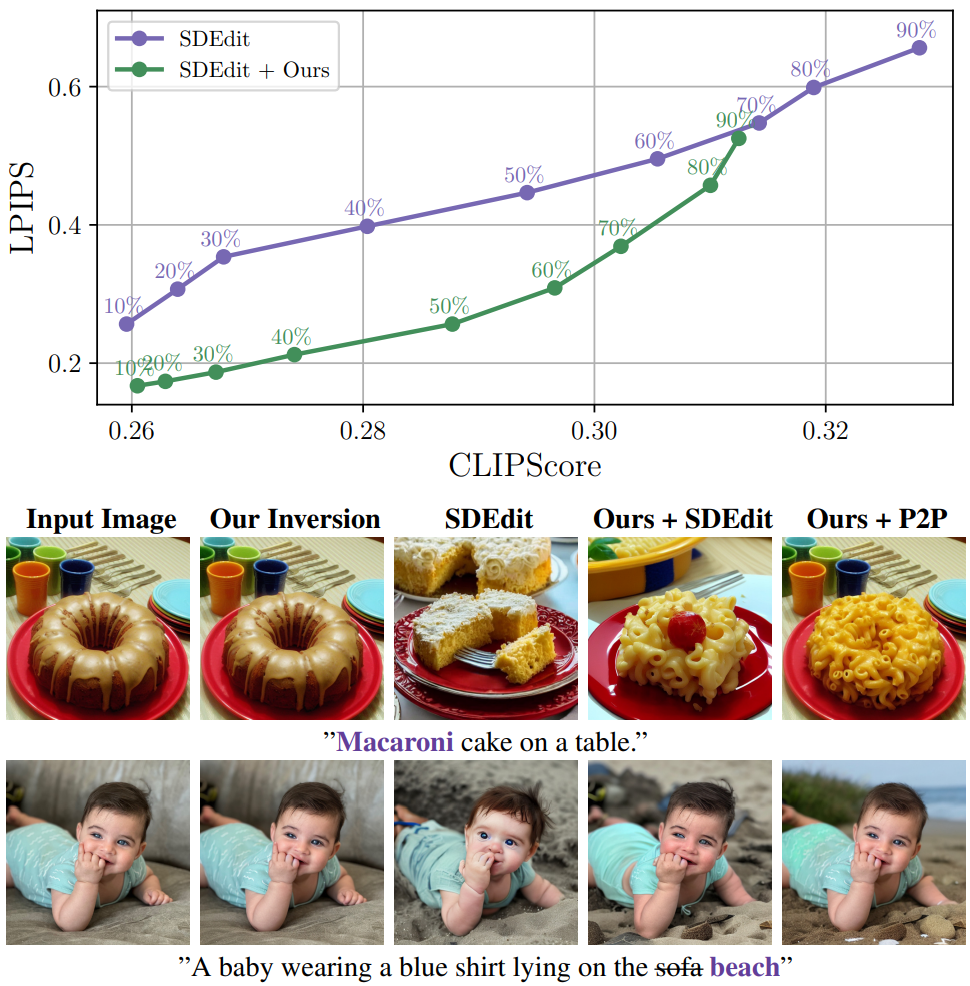
2. Evaluating Additional Editing Technique
다음은 SDEdit 결과를 개선한 결과이다.