[논문리뷰] No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images
ICLR 2025 (Oral). [Paper] [Page] [Github]
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, Songyou Peng
ETH Zurich | NVIDIA | Microsoft | UC Merced
31 Oct 2024

Introduction
본 논문은 feedforward network를 사용하여 포즈를 모르는 sparse-view 이미지(최소 2개)에서 3D Gaussian으로 표현된 3D 장면을 재구성하는 문제를 다룬다. Feedforward network를 사용하는 SOTA 방법들은 입력 뷰에 대한 정확한 카메라 포즈를 필요로 한다. 최근의 방법들은 포즈 추정과 3D 장면 재구성을 단일 파이프라인으로 통합하여 이러한 과제를 해결하고자 하였다. 그러나 이러한 방법의 새로운 뷰에 대한 렌더링 품질은 카메라 포즈에 의존하는 SOTA 방법보다 떨어진다. 성능 격차는 포즈 추정과 장면 재구성을 번갈아가는 순차적 프로세스에서 비롯된다. 포즈 추정의 오차는 재구성의 품질을 저하시키고, 이는 다시 포즈 추정의 부정확성을 더욱 높여 복합적인 효과를 낸다.
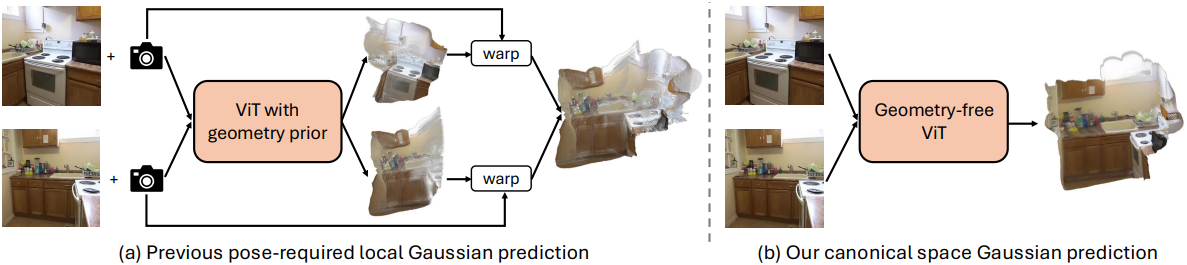
본 논문에서는 카메라 포즈에 의존하지 않고 장면을 완전히 재구성하는 것이 가능하다는 것을 보여 주며, 포즈 추정의 필요성을 없앴다. 저자들은 canonical space에서 장면 Gaussian을 직접 예측하여 이를 달성하였다. 또한 DUSt3R와 달리 GT 깊이 정보 없이 photometric loss로만 학습할 수 있으므로 더 널리 사용 가능한 동영상 데이터를 활용할 수 있다.
구체적으로, 첫 번째 뷰의 로컬 카메라 좌표를 canonical space로 고정하고 이 공간 내의 모든 입력 뷰에 대한 Gaussian들을 예측한다. 결과적으로, 출력 Gaussian은 이 canonical space에 맞춰진다. 이는 Gaussian들이 먼저 각 로컬 좌표계에서 예측된 다음 카메라 포즈를 사용하여 월드 좌표로 변환되고 융합되는 이전 방법과 대조된다. 변환 후 융합하는 기존 파이프라인과 비교할 때, 본 논문의 네트워크는 canonical space 내에서 직접 다른 뷰의 융합을 학습하도록 요구하여 명시적 변환으로 인해 발생한 정렬 오차를 제거한다.
제안된 파이프라인은 간단하고 유망하지만, 렌더링된 새로운 뷰에서 GT 타겟 뷰와 비교하여 상당한 스케일 불일치가 발생한다. 즉, 장면 스케일 모호성 문제가 발생한다. 저자들은 이미지 projection 프로세스를 분석한 결과, 카메라의 초점 거리가 이 스케일 모호성을 해결하는 데 중요하다는 것을 알게 되었다. 이는 모델이 초점 거리의 영향을 받는 이미지 외형에만 기반하여 장면을 재구성하기 때문이다. 이 정보를 통합하지 않으면 모델은 올바른 스케일에서 장면을 복구하는 데 어려움을 겪는다.
이 문제를 해결하기 위해, 저자들은 카메라 intrinsic을 임베딩하기 위한 세 가지 다른 방법을 설계하였다. 세 방법을 비교한 결과, intrinsic 파라미터를 feature 토큰으로 변환하고 입력 이미지 토큰과 concat하기만 하면 네트워크가 더 합리적인 스케일의 장면을 예측하여 가장 좋은 성능을 낼 수 있음을 알게 되었다.
3D Gaussian이 canonical space에서 재구성되면, 이를 novel view synthesis (NVS)와 포즈 추정에 활용한다. 포즈 추정의 경우, 2단계 파이프라인을 도입한다. 먼저, Gaussian 중심에 PnP 알고리즘을 적용하여 초기 포즈를 얻는다. 그런 다음, 추정된 포즈에서 장면을 렌더링하고 photometric loss를 사용하여 입력 뷰와의 정렬을 최적화하여 초기 포즈를 조정한다.
본 논문의 방법인 NoPoSplat은 NVS와 포즈 추정 task에서 모두 인상적인 성과를 보였다. NVS의 경우, 포즈를 사용하는 방법보다 성능이 우수하였으며, 특히 두 입력 이미지 간의 중첩이 작을 때 그렇다. 포즈 추정의 경우, 여러 벤치마크에서 기존 SOTA보다 상당히 성능이 우수하다. 또한 NoPoSplat은 out-of-distribution 데이터에 잘 일반화된다.
Method
1. Pipeline
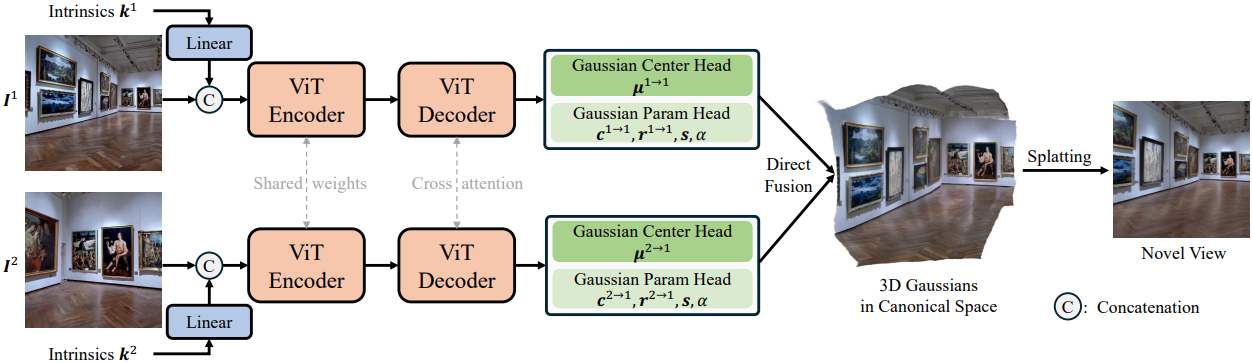
본 논문의 방법은 세 가지 주요 구성 요소로 구성된다.
- 인코더
- 디코더
- Gaussian 파라미터 예측 head
인코더와 디코더는 모두 ViT 구조를 활용하며, 기하학적 prior을 주입하지 않는다. 흥미롭게도, 이러한 간단한 ViT 네트워크가 이러한 기하학적 prior를 통합한 backbone보다 경쟁력 있거나 더 우수한 성능을 보인다. 특히 입력 뷰 간에 콘텐츠가 제한적으로 중복되는 시나리오에서 그렇다. 이러한 장점은 이러한 기하학적 prior가 효과적이려면 일반적으로 입력 카메라 간에 상당한 중복이 필요하다는 사실에서 비롯된다.
ViT 인코더 및 디코더
RGB 이미지는 patchify되고 이미지 토큰 시퀀스로 flatten된 다음, intrinsic 토큰과 concat된다. 각 뷰의 concat된 토큰은 ViT 인코더에 별도로 공급된다. 인코더는 다른 뷰에 대해 동일한 가중치를 공유한다. 다음으로, 인코더의 출력 feature는 ViT 디코더 모듈에 공급되고, 여기서 각 뷰의 feature는 각 attention 블록의 cross-attention layer를 통해 다른 모든 뷰의 feature와 상호 작용하여 멀티뷰 정보가 통합된다.
Gaussian 파라미터 예측 head
Gaussian 파라미터를 예측하기 위해 DPT 아키텍처를 기반으로 하는 두 개의 예측 head를 사용한다. 첫 번째 head는 Gaussian 중심 위치를 예측하는 데 중점을 두고 transformer 디코더에서만 추출한 feature를 활용한다. 두 번째 head는 나머지 Gaussian 파라미터를 예측하고 ViT 디코더 feature 외에도 RGB 이미지를 입력으로 사용한다. RGB 이미지 shortcut은 3D 재구성에서 미세한 텍스처 디테일을 캡처하는 데 중요한 텍스처 정보의 직접적인 흐름을 보장한다. 이 접근 방식은 자세한 구조 정보가 부족한 ViT 디코더에서 출력된 상위 수준 feature를 16배 다운샘플링하여 보상한다.
2. Analysis of the Output Gaussian Space
이전 방법들은 먼저 각 픽셀의 해당 깊이를 예측한 다음, 예측된 Gaussian 파라미터를 예측된 깊이와 카메라 intrinsic을 사용하여 각 프레임의 로컬 좌표계에서 Gaussian을 얻는다. 그런 다음, 이러한 로컬 Gaussian은 각 입력 뷰에 대해 제공된 카메라 포즈를 사용하여 월드 좌표계로 변환된다. 마지막으로, 모든 변환된 Gaussian은 하나의 장면을 나타내기 위해 융합된다.
대조적으로, canonical 좌표계에서 다른 뷰의 Gaussian을 직접 출력한다. 구체적으로, 첫 번째 입력 뷰를 글로벌 레퍼런스 좌표계로 고정한다. 네트워크는 모든 입력 뷰에 대해 이 canonical space 아래에서 Gaussian을 출력한다. 즉, 각 입력 뷰 $v$에 대해 \(\{\mu_j^{v \rightarrow 1}, r_j^{v \rightarrow 1}, c_j^{v \rightarrow 1}, \alpha_j, s_j\}\)를 예측한다.
Canonical space에서 직접 예측하는 것은 여러 가지 이점을 제공한다.
- 네트워크는 canonical space 내에서 직접 다른 뷰를 융합하는 법을 배우므로 카메라 포즈가 필요 없다.
- 글로벌 좌표계로 변환 후 융합하는 단계를 우회하면 응집력 있는 글로벌 표현이 생성되어 입력된 뷰에 대한 포즈 추정 적용이 더욱 용이해진다.
3. Camera Intrinsics Embedding
네트워크 입력에는 각 입력 뷰의 카메라 intrinsic $k$도 포함된다. 이는 스케일 오정렬을 해결하고 3D 재구성 품질을 개선하는 필수적인 기하학적 정보를 제공하는 데 필요하다. 저자들은 카메라 intrinsic을 모델에 주입하기 위한 세 가지 다른 인코딩 전략을 도입하였다.
- Global Intrinsic Embedding - Addition: 카메라 intrinsic $k = [f_x, f_y, c_x, c_y]$를 linear layer에 넣어 글로벌 feature를 얻는다. 이 feature는 ViT의 패치 임베딩 레이어 뒤에 있는 RGB 이미지 feature에 더해진다.
- Global Intrinsic Embedding - Concat: 글로벌 feature를 얻은 후에는 이를 추가적인 intrinsic 토큰으로 취급하고 모든 이미지 토큰과 concat한다.
- Dense Intrinsic Embedding: 입력 뷰의 각 픽셀 $p_j$에 대해 카메라 광선 방향을 $K^{−1} p_j$로 얻고, 픽셀별 카메라 광선을 spherical harmonics를 사용하여 더 높은 차원 feature로 변환 후 네트워크 입력인 RGB 이미지와 concat한다.
기본적으로 저자들은 가장 좋은 성능을 보이는 intrinsic 토큰 옵션을 활용하였다.
4. Training and Inference
학습
예측된 3D Gaussian들은 새로운 뷰에서의 이미지를 렌더링하는 데에 사용된다. 본 논문의 네트워크는 GT RGB 이미지를 사용하여 end-to-end로 학습된다. MVSplat를 따라 MSE와 LPIPS의 선형 결합을 loss로 사용한다. 각 loss에 대한 가중치는 각각 1과 0.05이다.
상대적 포즈 추정
3D Gaussian은 canonical space에 있으므로 상대적 포즈 추정에 직접 사용될 수 있다. 효율적인 포즈 추정을 위해, 저자들은 2단계 접근법을 제안하였다.
- 출력 Gaussian의 중심이 월드 좌표계로 주어졌을 때, PnP 알고리즘과 RANSAC을 사용하여 입력된 두 뷰의 초기 관련 카메라 포즈를 추정한다. 이 단계는 매우 효율적이고 밀리초 단위로 수행된다.
- Gaussian 파라미터를 고정한 채로, SSIM loss와 photometric loss를 함께 최적화하여 첫 번째 단계의 초기 포즈를 세부적으로 조정한다.
Experiments
- 데이터셋: RealEstate10k (RE10K), ACID, DL3DV
- 구현 디테일
- 인코더: ViT-large
- 디코더: ViT-base
- 인코더, 디코더, Gaussian center head는 MASt3R의 가중치로 초기화. 나머지 레이어는 랜덤 초기화
- 해상도: 256$\times$256, 512$\times$512
1. Experimental Results
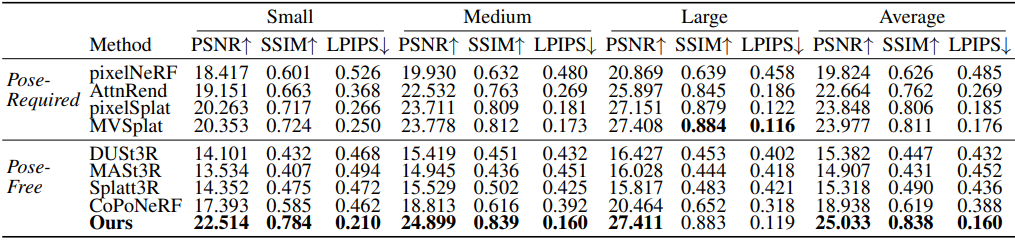
다음은 RealEstate10k에서의 NVS 결과이다.

다음은 ACID에서의 NVS 결과이다.

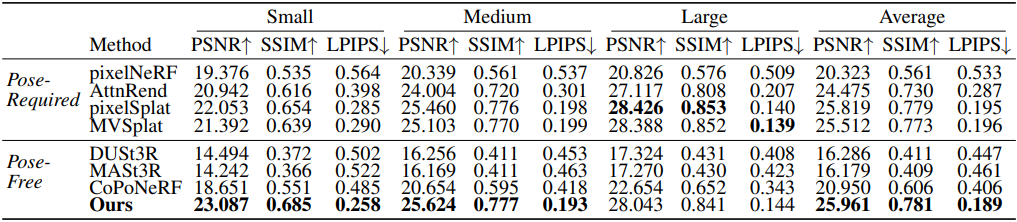
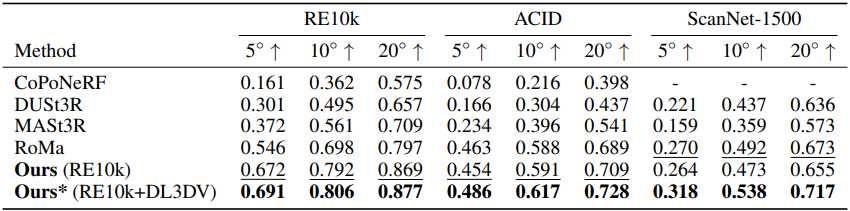
다음은 포즈 추정 결과를 비교한 표이다. (AUC로 비교)
다음은 3D Gaussian과 렌더링 결과를 비교한 것이다.

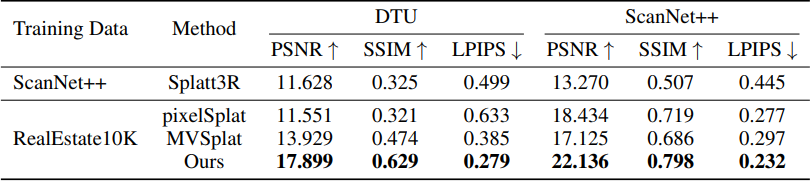
다음은 RealEstate10k에서 학습시킨 모델을 DTU와 ScanNet++에서 테스트한 결과이다.

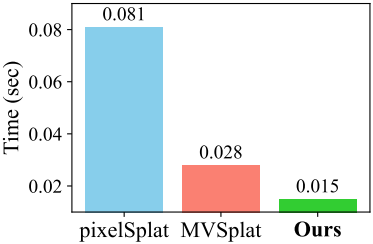
다음은 두 개의 256$\times$256 이미지에 대한 inference 시간을 RTX 4090 GPU에서 비교한 결과이다.
다음은 in-the-wild 이미지들에 대한 결과이다.

2. Ablation Studies
다음은 ablation 결과이다.