[논문리뷰] NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration
ICRA 2024. [Paper] [Page] [Github]
Ajay Sridhar, Dhruv Shah, Catherine Glossop, Sergey Levine
UC Berkeley
11 Oct 2023
Introduction
본 논문은 로봇이 다양한 task를 수행할 수 있도록 multi-task policy를 학습하는 것에 대해 다루고 있다. Multi-task policy는 목표나 지시에 따라 다양한 행동을 수행할 수 있으며, 여러 task와 도메인에서 데이터를 활용해 더 성능이 뛰어나고 일반화된 policy를 획득할 수 있다. 그러나 실생활에서는 로봇이 환경이 낯설거나 탐색이 필요한 경우, 또는 사용자의 지시가 불완전한 경우 어떤 task를 수행해야 할지 모를 수 있다.
본 논문에서는 로봇 내비게이션 분야에서 이러한 문제를 탐구하였다. 여기서 사용자가 이미지로 목적지를 지정하면, 로봇은 환경을 탐색해 목적지를 찾아야 한다. 이러한 상황에서는 표준 multi-task policy만으로는 충분하지 않다. 로봇이 환경을 탐색하고 다양한 task를 시도한 후에야 관심 있는 대상을 찾는 task를 수행할 수 있기 때문이다. 이전 연구들은 높은 수준의 policy나 목표 제안 시스템을 따로 학습시켜 이러한 문제를 해결해 왔지만, 이는 복잡성을 증가시키고 task별 메커니즘을 필요로 했다. 대신 본 논문에서는 하나의 표현력 높은 policy를 학습시켜, task에 특화된 행동과 task에 구애받지 않는 탐색 행동을 모두 표현하고, 상황에 따라 탐색에서 task 수행으로 전환할 수 있는 방법을 제안하였다.
본 논문에서는 시각적 관찰의 고차원 스트림을 인코딩하기 위한 Transformer backbone과 미래 행동 시퀀스를 모델링하기 위한 diffusion model을 결합하여 이러한 policy에 대한 설계를 제시하였다. 주요 통찰력은 이러한 아키텍처가 높은 용량 (지각과 제어를 모델링하는 데 모두)과 복잡한 멀티모달 분포를 표현하는 능력을 제공하기 때문에 task별 경로와 task에 무관한 경로를 모델링하는 데 고유하게 적합하다는 것이다.
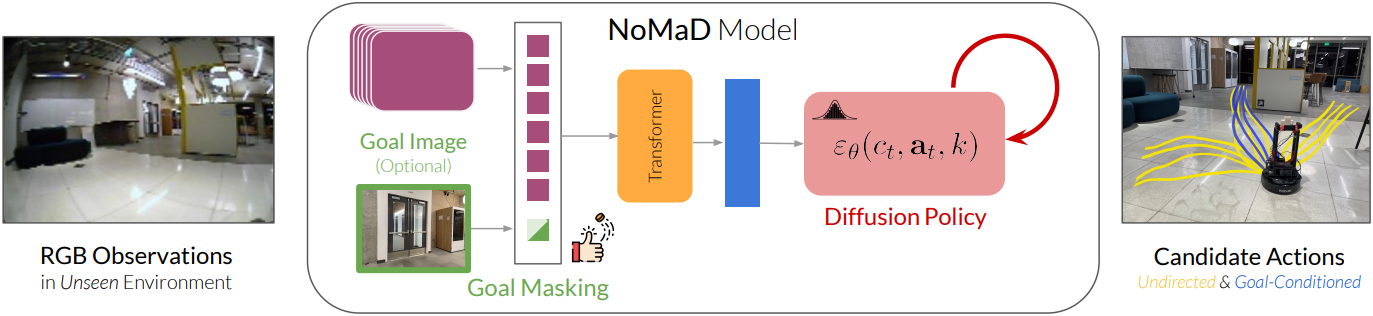
본 논문의 모델인 NoMaD (Navigation with Goal Masked Diffusion)는 이전에는 처음 보는 환경에서 로봇 내비게이션을 위한 새로운 아키텍처이다. 이 아키텍처는 통합된 diffusion policy를 사용하여 탐색 중심의 task에 무관한 행동과 목적지 지향적인 task에 특화된 행동을 공동으로 표현한다. 또한, 그래프 탐색, 경계 탐사(frontier exploration), 고도로 표현적인 policy들을 결합하는 프레임워크를 제공한다.
NoMaD는 까다로운 실내 및 실외 환경에서의 실험에서 목적지 유무에 상관없이 SOTA 기술보다 개선된 성능을 보였으며, 15배 더 높은 계산 효율성을 제공한다. NoMaD는 목적지 조건부 action diffusion model의 첫 번째 성공적인 인스턴스이며, task에 무관한 행동과 task에 특화된 행동에 대한 통합 모델이며, 실제 로봇에 배포되었다.

(NoMaD가 학습한 두 목적지 이미지를 위한 경로 (초록, 파랑)와 task에 무관한 경로 (노랑))
Method

목적지 조건부 탐색과 개방형 탐색에 대해 별도의 policy를 사용하는 이전 연구들과 달리, 저자들은 두 가지 동작에 대해 하나의 모델을 학습하는 것이 더 효율적이고 일반화 가능하다고 가정하였다. 두 가지 동작에 대해 공유된 policy를 학습하면, 모델이 action \(\textbf{a}_t\)에 대한 보다 표현력 있는 prior를 학습할 수 있다.
NoMaD 아키텍처에는 두 가지 핵심 구성 요소가 있다.
- Attention 기반 목적지 마스킹: 선택적으로 목적지 이미지 $o_g$에 policy를 컨디셔닝 또는 마스킹하기 위한 유연한 메커니즘을 제공
- Diffusion policy: 로봇이 취할 수 있는 충돌 없는 action에 대해 표현력 있는 prior를 제공
1. Goal Masking
목적지 도달과 무방향 탐색을 위한 공유 policy를 학습시키기 위해, ViNT 아키텍처를 수정하여 바이너리 “목적지 마스크” $m$을 도입한다.
\[\begin{equation} c_t = f(\psi (o_i), \phi (o_t, o_g), m) \end{equation}\]$m$은 목적지 토큰 $\phi (o_t, o_g)$를 마스크하는 데 사용할 수 있으므로 policy의 목적지 조건부 경로를 차단할 수 있다.
- $m = 1$: masked attention을 구현하여 $c_t$의 다운스트림 계산이 목적지 토큰에 attention하지 않도록 한다.
- $m = 0$: 목적지 토큰이 $c_t$의 다운스트림 계산에서 observation 토큰과 함께 사용된다. (unmasked attention)
학습하는 동안 목적지 마스크 $m$은 확률 $p_m = 0.5$의 베르누이 분포에서 샘플링된다. 즉, 목적지 도달 탐색과 무방향 탐색에 동일한 수의 학습 샘플을 사용한다. 테스트 시에는 무방향 탐색의 경우 $m = 1$, 사용자가 지정한 목적지 이미지에 도달하는 경우 $m = 0$으로 설정한다. 이 간단한 마스킹 전략은 목적지 도달 및 무방향 탐색 모두에 대한 하나의 policy를 학습시키는 데 매우 효과적이다.
2. Diffusion Policy
목적지 마스킹은 목적지 이미지에 대하여 policy를 컨디셔닝하는 편리한 방법을 제공하지만, 특히 목적지가 제공되지 않을 때 이로 인해 발생하는 action에 대한 분포는 매우 복잡할 수 있다. 예를 들어 교차로에서 policy는 좌회전과 우회전에 높은 확률을 할당해야 하지만 충돌로 이어질 수 있는 모든 action에는 낮은 확률을 할당해야 할 수 있다.
Action 시퀀스에 대한 이러한 복잡한 멀티모달 분포를 모델링하기 위해 하나의 policy를 학습하는 것은 어렵다. 이러한 복잡한 분포를 효과적으로 모델링하기 위해 diffusion model을 사용하여 조건부 분포 \(p(\textbf{a}_t \vert c_t)\)를 근사화한다. 여기서 $c_t$는 목적지 마스킹 후 얻은 observation context이다.
Gaussian 분포에서 미래의 액션 시퀀스 \(\textbf{a}_t^K\)를 샘플링하고, denoising을 $K$번 수행하여 noise level이 감소하는 일련의 중간 액션 시퀀스 \(\{\textbf{a}_t^K, \ldots, \textbf{a}_0^t\}\)를 생성하여 \(\textbf{a}_0^K\)가 형성될 때까지 계속한다. 반복적인 denoising process는 다음 방정식을 따른다.
\[\begin{equation} \textbf{a}_t^{k-1} = \alpha \cdot (\textbf{a}_t^k - \gamma \epsilon_\theta (c_t, \textbf{a}_t^k, k) + \mathcal{N} (0, \sigma^2 I)) \end{equation}\]($k$는 denoising step, \(\epsilon_\theta\)는 noise 예측 네트워크)
\(\epsilon_\theta\)는 마스크 $m$에 의해 결정되는 목적지 정보를 포함할 수도 있고 포함하지 않을 수도 있는 observation context $c_t$로 컨디셔닝된다. Denoising process의 출력에서 $c_t$를 제외하여 조건부 action 분포를 모델링하며, 이를 통해 diffusion process와 비전 인코더의 실시간 제어와 end-to-end 학습이 가능하다. 학습하는 동안 GT action 시퀀스에 noise를 추가하여 \(\epsilon_\theta\)를 학습시킨다. 예측된 noise는 MSE loss를 통해 실제 noise와 비교된다.
3. Training Details
NoMaD는 다음과 같은 loss function을 사용하여 supervised learning으로 end-to-end로 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{NoMaD} (\phi, \psi, f, \theta, f_d) = \textrm{MSE} (\epsilon^k, \epsilon_\theta (c_t, \textbf{a}_t^0 + \epsilon^k, k)) + \lambda \cdot \textrm{MSE} (d (\textbf{o}_t, o_g), f_d (c_t)) \end{equation}\]($\psi$와 $\phi$는 각각 관찰 이미지와 목적지 이미지의 비전 인코더, $f$는 Transformer 레이어, $\theta$는 diffusion process의 파라미터, $f_d$는 temporal distance predictor)
- Diffusion policy
- noise scheduler: square cosine noise scheduler
- denoising step $K = 10$
- $\epsilon_\theta$: 15개의 convolutional layer가 있는 1D conditional U-Net
- ViNT observation encoder
- EfficientNet-B0를 사용하여 관찰 이미지와 목적지 이미지를 256차원 임베딩으로 토큰화
- 그런 다음 4개의 레이어와 4개의 head가 있는 Transformer 디코더를 사용
- 학습 디테일
- optimizer: AdamW
- learning rate: $10^{-4}$
- batch size: 256
- epoch: 30
- cosine scheduling과 warmup으로 학습 안정화
Experiments
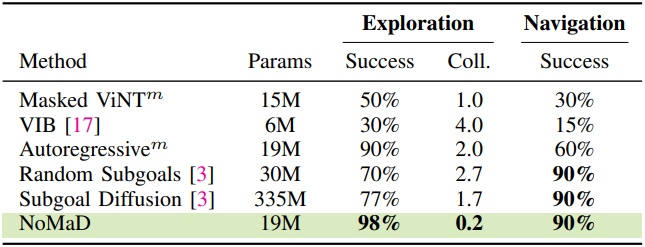
1. Benchmarking Performance
- VIB: Observation으로 컨디셔닝된 action 분포를 모델링하기 위해 variational information bottleneck (VIB)을 사용하는 탐색을 위한 latent goal model
- Masked ViNT: 목적지 마스킹을 ViNT policy와 통합하여 observation context $c_t$에 유연하게 조건을 부여하는 시스템. 분포를 모델링하는 것이 아니라 $c_t$로 컨디셔닝된 미래 action들의 점 추정치를 예측한다.
- Autoregressive: Discretize된 action 공간에 대한 autoregressive한 예측을 사용하여 멀티모달 action 분포를 표현하는 시스템. 목적지 마스킹과 동일한 비전 인코더 디자인을 사용한다.
- Subgoal Diffusion: Goal-conditioned policy와 이미지 diffusion model을 페어링하여 후보 목적지 이미지를 생성하는 ViNT 시스템. NoMaD보다 15배 큰 모델을 사용한다.
- Random Subgoals: 후보 목적지에 대한 학습 데이터를 무작위로 샘플링하여 Subgoal Diffusion을 대체하고, 이를 goal-conditioned policy에 전달하여 action을 예측하는 시스템. 이미지 diffusion model을 사용하지 않으며 NoMaD와 비슷한 파라미터 수를 갖는다.
다음은 LoCoBot 플랫폼에서의 탐색 예시이다. (초록, 파랑: 목적지 탐색, 노랑: 무방향 탐색)

다음은 처음 보는 환경에서의 탐색 성능 및 알고 있는 환경에서의 내비게이션 성능을 비교한 표이다.
다음은 action 예측 결과를 시각화하여 비교한 것이다.

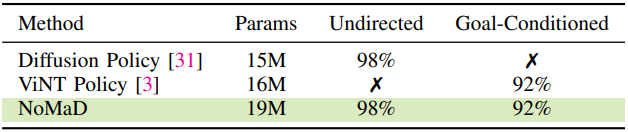
2. Unified vs. Dedicated Policies
다음은 policy에 따른 성능을 비교한 표이다.
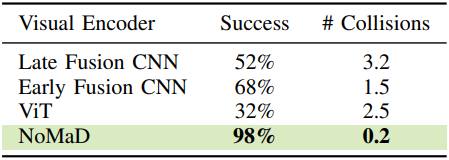
3. Visual Encoder and Goal Masking
다음은 비전 인코더와 목적지 마스킹에 따른 성능을 비교한 표이다.