[논문리뷰] NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models
CVPR 2024 (Oral). [Paper] [Page]
Yusuf Dalva, Pinar Yanardag
Virginia Tech
8 Dec 2023

Introduction
Diffusion model과 latent diffusion model (LDM)은 다양한 도메인서 고품질의 고해상도 이미지를 생성하는 능력으로 인해 상당한 주목을 받아 왔다. 특히 Stable Diffusion과 같은 text-to-image 모델을 사용하여 다양한 조건을 통해 이미지를 편집하도록 영감을 주었다.
생성 모델을 사용한 이미지 편집에서는 의도하지 않은 영역에 영향을 주지 않으면서 이미지의 특정 영역에 의미상 중요한 변경을 수행하는 semantic의 disentanglement가 중요하다. GAN은 구조화된 latent space로 인해 disentangle된 이미지 편집에 특히 효과적임이 입증되었다. 그러나 diffusion model에서 semantic direction을 찾는 것은 더 어렵다. 이러한 어려움은 입력과 독립적으로 forward noise를 추정하고 여러 timestep에 걸쳐 상당한 수의 latent 변수를 관리하는 diffusion model의 고유 설계에서 발생한다.
따라서 diffusion 기반 모델의 생성 프로세스에 대한 세밀한 제어를 제공하는 이전 연구들은 latent 벡터 혼합, 모델 fine-tuning, 임베딩 최적화와 같은 간단한 솔루션에 중점을 두었다. 그러나 이러한 방법들은 특정 semantic을 정확히 찾아내기 위해 사용자가 제공한 텍스트 프롬프트에 따라 달라진다. 이 접근 방식은 적절한 텍스트 프롬프트를 생성하기가 쉽지 않거나 광범위한 도메인 지식이 필요한 전문 분야에서는 제한적일 수 있다. 따라서 unsupervised 방식으로 latent space에서 방향을 발견하는 것이 중요하다.
Diffusion model 내의 latent direction을 체계적으로 조사하기 위해 다양한 전략이 도입되었다. 그러나 기존 연구들은 Stable Diffusion과 같은 대규모 모델에서의 한계를 인정하고 DDPM과 같은 단순한 diffusion model을 선택하였다. 따라서 상당한 발전에도 불구하고 Stable Diffusion과 같은 대규모 diffusion model에서 latent space를 철저히 탐색하는 것은 여전히 진행 중인 과제이다.
Diffusion model의 latent space에서 방향을 발견하는 것은 이미지 편집뿐만 아니라 광범위한 다른 응용 분야에서도 필수적이다.
- 이미지 생성 프로세스를 보다 정밀하게 제어할 수 있으므로 다양한 창의적이고 전문적인 영역에서 모델의 다양성과 적용 가능성이 크게 향상된다.
- 보다 투명하고 통찰력 있는 탐색을 촉진하여 latent space를 더 이해하기 쉽게 만든다.
- 이러한 통찰력은 모델의 신뢰도를 높이고 잠재적인 편견을 식별하고 완화하는 데 도움이 될 수 있다.
본 논문의 접근 방식은 다양한 도메인 내에서 여러 방향을 결합할 수 있는 정도로 disentangle하게 Stable Diffusion의 latent space에서 방향을 성공적으로 발견하는 최초의 unsupervised 방법이다.
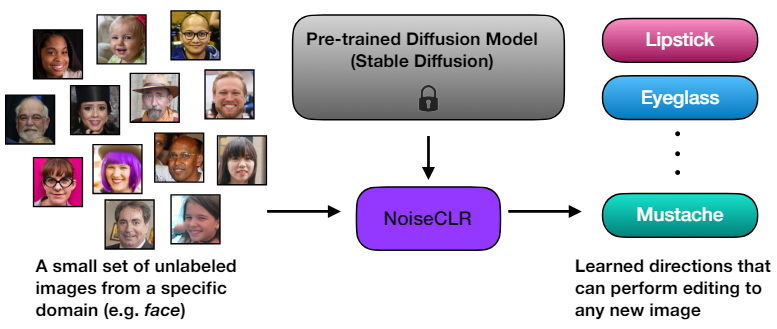
Method
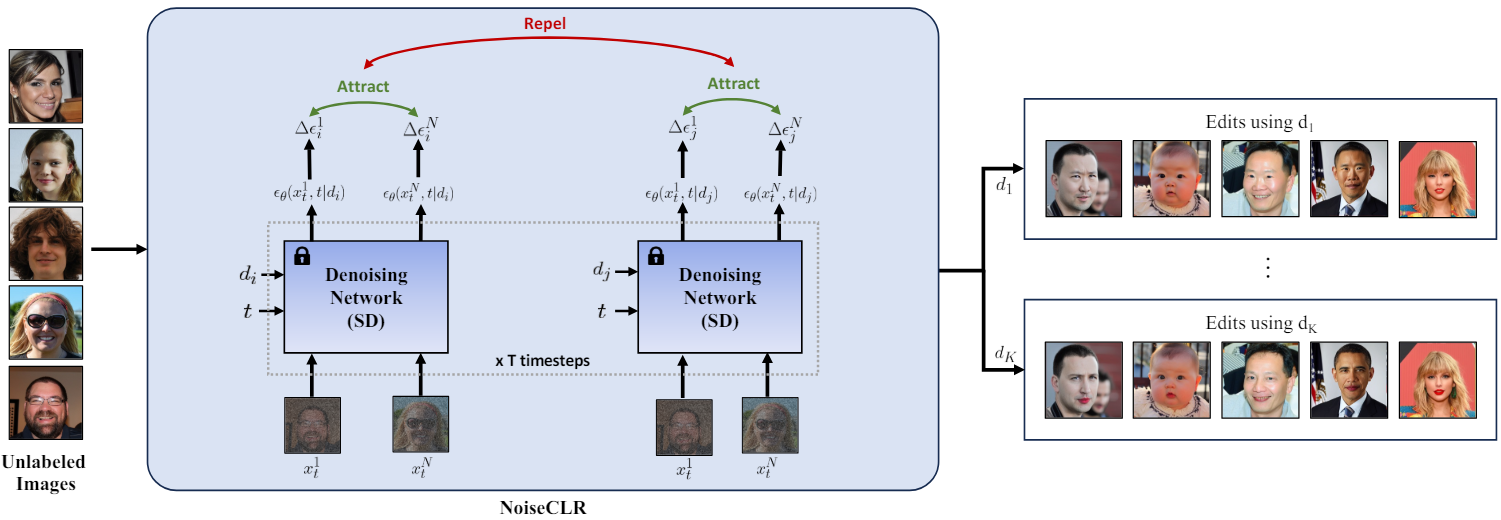
Contrastive Learning Objective
NoiseCLR의 주요 목표는 $N$개 이미지의 작은 집합이 주어지면 \(X = \{x_1, \ldots, x_N\}\)이 주어지면 $K$개의 semantic direction \(D = \{d_1, \ldots, d_K\}\)을 unsupervised 방식으로 학습하는 것이다. NoiseCLR은 임의의 방향으로 수행된 편집의 유사성을 장려하는 동시에 다른 방향으로 수행된 편집의 유사성을 억제하는 목적 함수를 사용한다. 즉, contrastive learning의 핵심 원리에 따라 동일한 방향으로 수행된 편집은 서로 끌어당기고, 서로 다른 방향으로 수행된 편집은 서로 밀어내기를 원한다. 이러한 목적 함수를 만들기 위해 먼저 임의의 데이터 샘플 $x_n$에서 임의의 방향 $d_k$로 인해 발생하는 feature divergence $\Delta \epsilon_k^n$을 다음과 같이 정의한다.
\[\begin{equation} \Delta \epsilon_k^n = \epsilon_\theta (x_t^n, d_k) - \epsilon_\theta (x_t^n, \varnothing) \end{equation}\]$d_j$와 데이터 샘플의 집합 $X^\prime \subset X$에서 얻은 feature divergence를 positive sample로 정의하고, $X^\prime$과 latent direction 집합 $D^\prime \subset D − d_j$에 대한 feature divergence은 negative sample로 정의한다. Contrastive learning 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{L} = - \log \frac{\sum_{a=1}^{\vert X^\prime \vert} \sum_{b=1}^{\vert X^\prime \vert} \unicode{x1D7D9}_{[a \ne b]} \exp (\textrm{sim} (\Delta \epsilon_j^a, \Delta \epsilon_j^b) / \tau)}{\sum_{a=1}^{\vert X^\prime \vert} \sum_{i=1}^{\vert D^\prime \vert} \unicode{x1D7D9}_{[i \ne j]} \exp (\textrm{sim} (\Delta \epsilon_j^a, \Delta \epsilon_i^a) / \tau)} \end{equation}\]여기서 $\textrm{sim}$은 cosine similarity이다.
\[\begin{equation} \textrm{sim} (\Delta \epsilon_j^a, \Delta \epsilon_j^b) = \frac{\Delta \epsilon_j^a \cdot \Delta \epsilon_j^b}{\| \Delta \epsilon_j^a \| \| \Delta \epsilon_j^b \|} \end{equation}\]이미지 편집
발견된 방향 집합 \(\{d_1, \ldots, d_K\}\)이 주어지면, 이러한 semantic을 반영하여 disentangle된 방식으로 입력 이미지에 반영하는 것을 목표로 한다. 이러한 편집을 위해 classifier-free guidance와 유사하게 편집 방향 $d_e$로 \(\tilde{\epsilon_\theta} (x_t, c, d_e)\)를 얻는다.
\[\begin{equation} \tilde{\epsilon_\theta} (x_t, c, d_e) = \tilde{\epsilon_\theta}(x_t, c) + \lambda_e (\epsilon_\theta (x_t, d_e) - \epsilon_\theta (x_t, \varnothing)) \end{equation}\]여기서 $c$는 원본 이미지를 생성하는 데 사용되는 조건이다 \(\lambda_e\)는 editing scale이다.
여러 방향으로 편집
임의의 방향에 대한 편집을 예측된 noise들의 합으로 정의하였므로 주어진 입력 $x_t$에 대해 여러 편집을 수행할 수 있다. 발견된 방향 집합 \(L = \{d_1, \ldots, d_L\}\)으로 이미지 편집을 수행하려면 다음과 같은 식을 사용하면 된다.
\[\begin{equation} \tilde{\epsilon_\theta} (x_t, c, L) = \tilde{\epsilon_\theta}(x_t, c) + \sum_{i=1}^{\vert L \vert} \lambda_i (\epsilon_\theta (x_t, d_i) - \epsilon_\theta (x_t, \varnothing)) \end{equation}\]실제 이미지 편집
생성된 이미지에 대한 편집을 수행하는 것 외에도 실제 이미지에 적용할 수 있도록 편집 방식을 확장할 수 있다. 먼저 DDIM Inversion을 적용하여 초기 변수 $x_T$를 얻는다. 이미지가 $x_T$에 의해서만 컨디셔닝되므로 \(\tilde{\epsilon_\theta}(x_t, c, d_e)\)를 \(\tilde{\epsilon_\theta}(x_t, d_e)\)로 재구성한다.
\[\begin{equation} \tilde{\epsilon_\theta}(x_t, d_e) = \tilde{\epsilon_\theta}(x_t, \varnothing) + \lambda_e (\epsilon_\theta (x_t, d_e) - \epsilon_\theta (x_t, \varnothing)) \end{equation}\]여러 방향으로 편집하는 방법도 실제 이미지에 적용 가능하다.
\[\begin{equation} \tilde{\epsilon_\theta} (x_t, L) = \tilde{\epsilon_\theta}(x_t, \varnothing) + \sum_{i=1}^{\vert L \vert} \lambda_i (\epsilon_\theta (x_t, d_i) - \epsilon_\theta (x_t, \varnothing)) \end{equation}\]Experiments
- 데이터셋: FFHQ, AFHQ-Cats, Stanford Cars
- 구현 디테일
- 이미지 집합 크기: $N = 100$
- 방향 집합 크기: $K = 100$
- temperature: $\tau = 0.5$
- learning rate: $10^{-3}$
- batch size: 6
- optimizer: AdamW
- $\vert D^\prime \vert = 20$
- NVIDIA L40 GPU에서 학습은 7시간, 편집은 5초 소요
1. Qualitative Results
다음은 얼굴 도메인에 대해 학습된 방향들을 시각화한 것이다.

다음은 다양한 도메인에 대한 편집 결과이다.

다음은 (a) 도메인 내 편집과 (b) 도메인 간 편집 결과이다.

다음은 interpolation 결과이다.

다음은 다른 방법들과 정성적으로 비교한 결과이다.

2. Quantitative Results
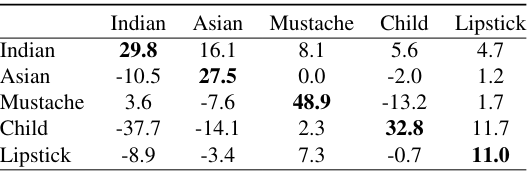
다음은 CLIP classifier를 사용하여 분류 확률의 변화를 측정한 표이다.
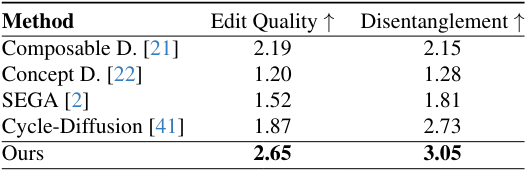
다음은 다른 방법들과 LPIPS를 비교한 표이다.

다음은 user study 결과이다.
Limitations
NoiseCLR은 사전 학습된 Stable Diffusion 모델을 기반으로 구축되었다. 결과적으로, 조작 능력은 Stable Diffusion이 학습한 데이터셋과 언어 모델 CLIP에 크게 의존한다. CLIP의 표현 능력은 한계가 있으며 특정 속성에 대한 편견을 나타낼 수 있다.