[논문리뷰] Noise2Music: Text-conditioned Music Generation with Diffusion Models
arXiv 2023. [Paper] [Page]
Qingqing Huang1, Daniel S. Park1, Tao Wang, Timo I. Denk, Andy Ly, Nanxin Chen, Zhengdong Zhang, Zhishuai Zhang, Jiahui Yu, Christian Frank, Jesse Engel, Quoc V. Le, William Chan, Wei Han
Google Research, Brain Team
8 Feb 2023
Introduction
본 논문은 텍스트 프롬프트에서 음악을 생성하는 diffusion 기반 방법인 Noise2Music을 소개하고 30초 길이의 24kHz 음악 클립을 생성하여 그 능력을 시연한다.
첫 번째 모델은 텍스트 프롬프트에서 30초 waveform의 압축된 표현을 생성하는 생성 task를 학습하고 두 번째 모델은 압축된 표현과 선택적으로 텍스트 프롬프트에서 16kHz waveform을 생성하도록 학습된다. 저자들은 중간 표현에 대한 두 가지 옵션인 log-mel spectrogram과 3.2kHz waveform을 조사했다. 1D U-Net은 diffusion model의 noise 벡터를 학습하는 데 사용된다. Diffusion model은 사전 학습된 언어 모델(LM)로 인코딩되고 cross-attention을 통해 1D U-Net layer에서 수집되는 자유 형식 텍스트 형식의 사용자 프롬프트로 컨디셔닝된다. 최종 super-resolution cascader는 16kHz waveform에서 24kHz 오디오를 생성하는 데 사용된다.
심층 생성 모델에서 고품질 샘플을 생성하려면 많은 양의 학습 데이터가 중요하다. 저자들은 데이터 마이닝 파이프라인을 사용하여 각각 여러 개의 설명 텍스트 레이블과 쌍을 이루는 다양한 음악 오디오 클립으로 구성된 대규모 학습 데이터셋을 구성한다. 오디오에 대한 텍스트 레이블은 한 쌍의 사전 학습된 심층 모델을 사용하여 생성된다. 먼저 대규모 언어 모델을 사용하여 캡션 후보로 많은 일반 음악 설명 문장 셋을 생성한다. 그런 다음 사전 학습된 음악-텍스트 공동 임베딩 모델을 사용하여 레이블이 없는 각 음악 클립을 모든 캡션 후보에 대해 점수를 매기고 유사성 점수가 가장 높은 캡션을 오디오 클립의 pseudo-label로 선택한다. 이러한 방식으로 15만 시간 정도의 오디오 소스에 주석을 달아 학습 데이터를 구성할 수 있다.
이 작업의 부산물로 위에서 설명한 과정을 통해 AudioSet에서 음악 콘텐츠에 주석을 추가하여 얻은 40만 시간 정도의 음악-텍스트 쌍으로 구성된 MuLan-LaMDA 음악 캡션 데이터셋(MuLaMCap)을 소개한다. 632개의 레이블 클래스 중 141개가 음악과 관련된 원래의 AudioSet ontology에 비해 MuLaMCap의 캡션은 훨씬 더 높은 수준의 다양성과 세분성을 가진 400만 개의 음악 설명 문장 및 구문으로 구성된 대규모 vocabulary에서 나온다. 저자들은 이 데이터셋이 사운드 분류를 넘어서는 애플리케이션 (ex. 음악 캡션, 검색, 생성)에 활용될 것으로 기대한다.
본 논문의 모델은 장르, 악기, 시대와 같은 단순한 음악 속성 조건을 넘어설 수 있고 분위기, 느낌 또는 활동과 같은 부드러운 속성을 반영할 수 있는 복잡하고 세분화된 semantic을 처리할 수 있음을 보여준다. 이는 metadata 태그에 의존할 뿐만 아니라 사전 학습된 음악-텍스트 결합 임베딩 모델을 활용하여 semantic을 오디오 feature에 적용하는 학습 데이터셋을 구성함으로써 달성된다.
Methods
1. Diffusion models
DDPM 논문리뷰 참고
\[\begin{equation} \mathbb{E}_{x, c, \epsilon, t} [w_t \| \epsilon_\theta (x_t, c, t) - \epsilon \|^2] \end{equation}\]Classifier-free guidance (CFG)
Classifier-free guidance 논문리뷰 참고
\[\begin{equation} w \epsilon_\theta (x_t, c) + (1 - w) \epsilon_\theta (x_t, \cdot), \quad w > 1 \end{equation}\]2. Architecture
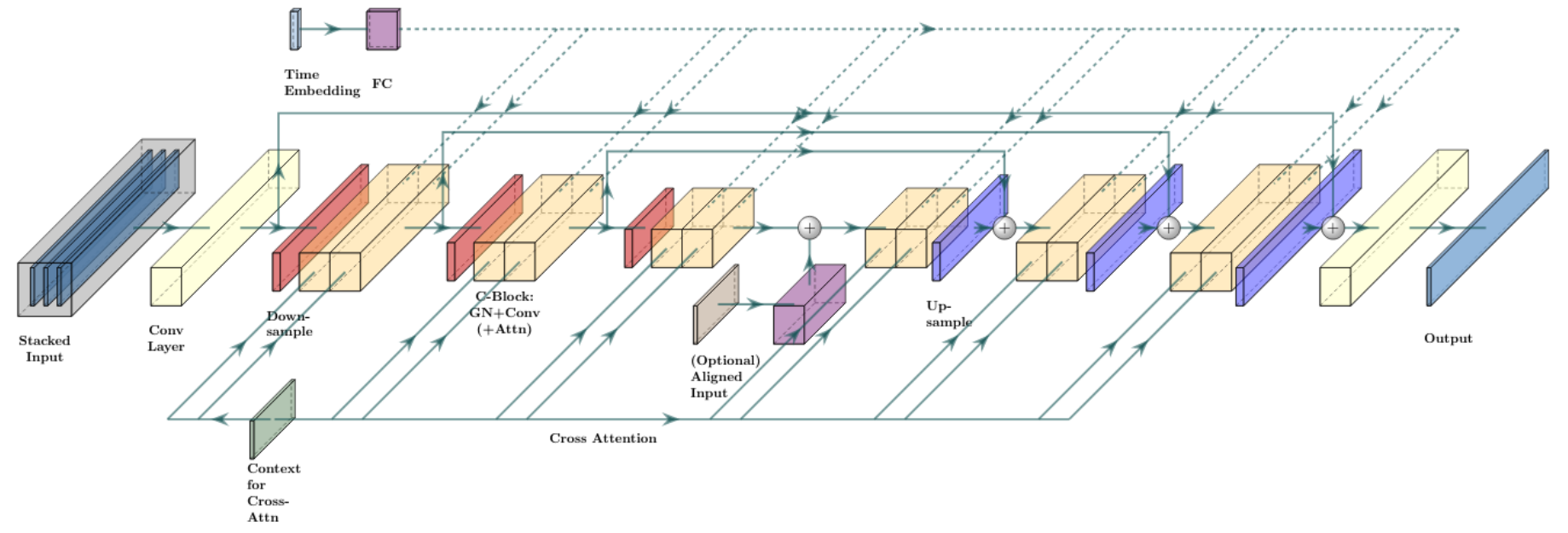
저자들은 diffusion model을 위해 Efficient U-Net의 1차원 버전인 1D Efficient U-Net을 사용한다. 위 그림에 표시된 U-Net 모델은 residual connection으로 연결된 일련의 downsampling 및 upsampling block으로 구성된다. Down/upsampling block은 down/upsampling layer 뒤에 1D convolution layer, self/cross-attention layer, combine layer를 구성하여 얻은 일련의 block으로 구성된다. Combine layer를 사용하면 단일 벡터가 일련의 벡터와 상호 작용할 수 있으며, 단일 벡터는 채널 방향 scaling괴 bias을 생성하는 데 사용된다. 이러한 block은 Efficient U-Net block 구조를 따르며, 2차원 convolution은 1차원 convolution으로 대체된다.
모델에 진입할 수 있는 네 가지 경로가 있다. 스택된 입력과 출력은 모두 길이 $T$의 시퀀스로 구성되며, diffusion time $t$는 단일 시간 임베딩 벡터로 인코딩되고 down/upsampling block 내에서 앞서 언급한 combine layer를 통해 모델과 상호 작용한다. 길이 $T$의 시퀀스를 생성하려는 경우 noisy한 샘플 $x_t$는 항상 스택된 입력의 일부이며 출력은 noise 예측으로 해석된다. Cascading model의 경우 조건으로 주어지는 저음질 오디오를 upsampling하고 쌓을 수 있다. 한편, 임의의 길이를 가진 일련의 벡터는 cross-attention을 통해 block과 상호 작용할 수 있다. 이것은 텍스트 프롬프트가 모델에 공급되는 경로이다. 또한 U-Net의 “U” 맨 아래에 추가하여 정렬된 시퀀스의 압축된 표현에서 모델을 컨디셔닝할 공간도 있다.
3. Cascaded diffusion
본 논문에서는 텍스트 프롬프트에서 고품질 30초 오디오를 생성하기 위해 두 종류의 diffusion model을 학습시킨다. 텍스트 프롬프트에 따라 최종 오디오의 일부 중간 표현을 생성하는 generator model과 중간 표현을 기반으로 최종 오디오를 생성하는 cascader model을 학습시킨다. 중간 표현의 경우 저음질 오디오와 spectrogram을 모두 고려한다.
Waveform model
Generator model: Generator model은 텍스트 입력을 조건으로 3.2kHz 오디오를 생성한다. 텍스트 입력에서 파생된 일련의 벡터가 생성되어 cross-attention 시퀀스로 네트워크에 공급된다.
Cascader model: Cascader model은 텍스트 프롬프트와 generator model에서 생성된 저음질 오디오로 컨디셔닝되어 16kHz 오디오를 생성한다. 텍스트 컨디셔닝은 cross-attention을 통해 이루어진다. 저음질 오디오는 upsampling되고 $x_t$와 함께 스택되어 모델에 공급된다. Upsampling은 저음질 오디오 시퀀스에 고속 푸리에 변환(FFT)을 적용한 다음 inverse FFT를 적용하여 저음질 푸리에 계수에서 고음질 오디오를 얻음으로써 수행된다.
Spectrogram model
Generator model: 이 모델은 텍스트 입력을 조건으로 log-mel spectrogram을 생성한다. Spectrogram에는 80개의 채널과 초당 100개 feature가 있다. 입력 및 출력 시퀀스에는 이제 시퀀스 차원 외에 채널 차원이 있다. Log-mel spectrogram의 픽셀 값은 $[-1, 1]$ 내에 있도록 normalize된다. 텍스트 컨디셔닝은 cross-attention을 통해 이루어진다.
Vocoder model: Vocoder model은 align된 입력으로 처리되는 spectrogram으로만 컨디셔닝되어 16kHz 오디오를 생성한다. U-Net 모델의 downsampling 및 upsampling 속도는 오디오에 대한 spectrogram의 압축 속도를 달성하도록 조정된다.
Super-Resolution Cascader
최종 경량 cascader는 두 모델에서 생성된 16kHz waveform에서 24kHz 오디오를 생성하는 데 사용된다. 16kHz 오디오는 모델에 대한 입력으로 $x_t$와 함께 upsampling되고 스택된다. 이 모델에는 텍스트 컨디셔닝이 사용되지 않는다.
4. Text understanding
Text-to-image diffusion model의 맥락에서 강력한 텍스트 인코더가 음악 설명 텍스트 프롬프트의 복잡성과 합성성을 캡처할 수 있음이 밝혀졌다. T5 인코더를 채택하고 pooling되지 않은 토큰 임베딩 시퀀스를 사용하여 diffusion model을 컨디셔닝한다. 서로 다른 대규모 언어 모델의 임베딩 또는 음악-텍스트 쌍에서 학습된 CLIP과 같은 텍스트 인코더의 단일 벡터 임베딩과 같은 대체 컨텍스트 신호와의 철저한 비교는 이 논문의 범위를 벗어난다.
5. Pseudo labeling for music audio
대규모 학습 데이터를 보유하는 것은 생성 심층 신경망의 품질을 보장하는 데 필요한 구성 요소이다. 음악 콘텐츠가 광범위하게 이용 가능하다는 사실에도 불구하고, 특히 높은 수준의 metadata를 넘어서는 음악 속성을 설명하는 자유 형식 텍스트의 경우 고품질의 음악-텍스트 쌍 데이터가 부족하다.
이러한 음악-텍스트 쌍을 생성하기 위해 LaMDA와 함께 사전 학습된 텍스트 및 음악 오디오 공동 임베딩 모델인 MuLan을 활용하여 pseudo-labeling 접근 방식을 사용한다. LaMDA는 레이블이 없는 음악 오디오 클립에 세밀한 semantic이 있는 pseudo-label을 할당하기 위해 사전 학습된 대규모 언어 모델이다.
먼저 음악 설명 텍스트의 list로 각각 구성된 여러 음악 캡션 vocabulary set을 큐레이팅한다. 이러한 텍스트는 표준 음악 분류 벤치마크(ex. MagnaTagATune, FMA, AudioSet)의 레이블 클래스의 캡션과 규모 및 semantic의 세분성에서 크게 다르다. 다음 세 가지 캡션 vocabulary를 고려한다.
LaMDA-LF: 노래 제목과 아티스트 이름이 제공된 150,000개의 인기 노래 목록을 설명하기 위해 대형 언어 모델 LaMDA를 사전 학습시킨다. 그런 다음 LaMDA 응답을 음악을 설명할 가능성이 있는 4백만 개의 깨끗한 긴 형식 문장으로 처리한다. 저자들은 LaMDA를 LM으로 선택했는데, 이는 LaMDA가 대화 애플리케이션용으로 학습되었기 때문이며 생성된 텍스트가 음악 생성을 위한 사용자 프롬프트에 더 가깝기를 기대한다.
Rater-LF: MusicCaps에서 10,028개의 평가자 작성 캡션을 얻고 각 캡션을 개별 문장으로 분할한다. 이것은 긴 형식의 문장을 설명하는 35,333개의 음악을 생성한다.
Rater-SF: 위의 동일한 evaluation set에서 평가자가 작성한 모든 짧은 형식의 음악 태그를 수집하며 이는 크기가 23,906인 vocabulary에 해당한다.

캡션 vocabulary의 예시는 위 표에 나와 있다.
MuLan 모델을 zero-shot 음악 classifier로 사용하여 vocabulary에서 레이블이 없는 오디오 클립에 캡션을 할당한다. MuLan은 텍스트 인코더와 오디오 인코더로 구성되어 있으며, contrastive learning 방식으로 noisy한 많은 텍스트 음악 쌍에 대해 학습된다. CLIP이 이미지와 텍스트를 함께 삽입하는 방식과 유사하게 MuLan이 학습한 동일한 semantic embedding space에 10초 길이의 음악 오디오 클립과 음악을 설명하는 문장이 밀접하게 배치된다.
각 오디오 클립에 대해 먼저 클립을 겹치지 않는 10초 window로 분할하고 각 window의 MuLan 오디오 임베딩의 평균을 계산하여 오디오 임베딩을 계산한다. Vocabulary에 있는 모든 후보 캡션의 텍스트 임베딩도 계산된다. Embeddign space에서 오디오에 가장 가까운 $K$개의 캡션이 각 클립에 대해 선택된다. 모든 클립에서 캡션의 빈도 수를 계산하고 각 클립에 대해 빈도 수에 반비례하는 확률로 $K$개의 캡션 중 $K’$을 추가로 샘플링한다. 이 마지막 샘플링 단계는 레이블 분포의 균형을 맞추고 캡션의 다양성을 높이는 역할을 한다. $K = 10$과 $K’ = 3$을 사용한다.
대규모 학습 셋의 pseudo-labeling을 위한 warm up으로 AudioSet에서 파생된 음악 캡션 데이터셋인 MuLaMCap을 AudioSet ontology의 음악 subtree에 레이블이 있는 AudioSet train / test set의 388,262 / 4,497개의 예시에 적용하여 생성한다. 음악 콘텐츠가 포함된 각 10초 오디오는 LaMDA-LF vocabulary의 3개 캡션, Rater-LF의 3개 캡션, Rater-SF의 짧은 형식 캡션 6개와 concat된다.
6. Training data mining
저자들은 오디오-텍스트 쌍의 대규모 컬렉션을 모으기 위해 약 680만 개의 음악 오디오 소스 파일을 수집하였다. 각 사운드트랙에서 6개의 겹치지 않는 30초 클립을 추출한다. 이것은 거의 34만 시간의 음악에 해당한다. 오디오는 super-resolution model 학습용으로 24kHz로 샘플링되고 다른 모든 모델 학습용으로 16kHz로 샘플링된다.
각 사운드트랙에 대해 노래 제목, 사운드트랙과 관련된 entity 태그(ex. 장르, 아티스트 이름, 악기), pseudo-label의 세 가지 유형의 noisy한 텍스트 레이블을 고려한다. LaMDA-LF vocabulary에서 3개의 pseudo-label을 사용하고 Rater-SF vocabulary에서 6개의 pseudo-label을 사용한다. LaMDA-LF와 Rater-SF의 pseudo-label은 entity 태그에 보완 정보를 제공한다. 객관적이고 높은 수준의 태그와 비교하여 pseudo-label에는 활동 (“고속도로 주행을 위한 음악”) 및 기분 (“느긋한 느낌”)과 관련된 주관적인 설명이 포함되며 세분화된 semantic이 포함된 구성 요소도 포함된다. Rater-LF의 문장이 파생된 MusicCaps에서 모델을 평가하므로 학습 데이터에서 Rater-LF vocabulary의 pseudo-label을 제외한다.
Pseudo-label이 지정된 큰 학습 셋에 소량의 고품질 오디오를 포함한다. 오디오는 내부적으로 관리되는 음악 라이브러리에서 속성이 필요하지 않은 음악 트랙의 부분 집합에서 가져온다. 음악 트랙은 겹치지 않는 30초 클립으로 분할되며 트랙의 metadata는 concat되어 오디오의 텍스트 프롬프트를 형성한다. 이것은 학습 데이터에 주석이 달린 오디오의 300 시간 정도를 기여한다.
Experiments and Results
1. Model training details
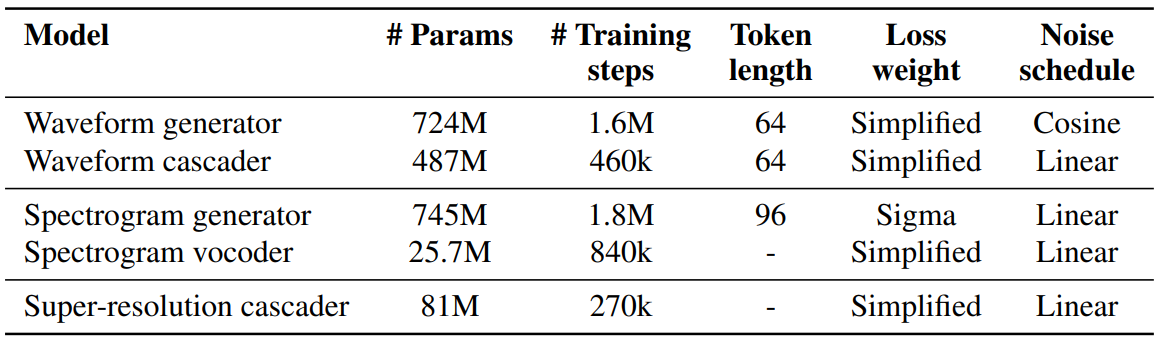
본 논문은 4개의 1D U-Net 모델(waveform generator와 cascader, spectrogram generator와 vocoder)을 학습시킨다. 모델에 대한 몇 가지 기본 정보는 위 표와 같다. Spectrogram generator의 수렴에 중요한 denoising schedule의 “백엔드”에서 loss에 더 많은 가중치를 부여하는 sigma-weighted loss를 발견했다.
Vocoder를 제외한 모든 모델은 오디오-텍스트 쌍에 대해 학습되는 반면 vocoder는 오디오에 대해서만 학습된다. 각 오디오 샘플에 대해 텍스트 batch가 형성된다. 세 개의 긴 프롬프트는 텍스트 batch의 세 가지 독립 요소를 구성하는 반면 짧은 프롬프트는 concat된 다음 위 표에 나온 설정된 토큰 길이로 분할되고 텍스트 batch에 추가된다. 각 오디오 클립에 대해 해당 텍스트 batch의 임의 요소가 학습 시에 선택되고 오디오에 쌍을 이루는 텍스트로 모델에 공급된다.
기타 설정은 다음과 같다.
- Adam optimizer $\beta_1 = 0.9$, $\beta_2 = 0.999$
- Cosine learning rate schedule (2.5M step), peak learning rate $10^{-4}$, 10k warm-up step
- EMA decay rate 0.9999
- Batch size 2048 (cascader만 4096)
- CFG 사용: 10%의 샘플은 텍스트 프롬프트를 조건으로 사용하지 않고 cross-attention layer의 출력을 0으로 설정
- Generator model은 self-attention을 사용하므로 전체 30초 표현으로 학습. Cascader와 vocoder는 3~4초를 랜덤하게 샘플링하려 학습
- Cascader와 vocoder에 2가지 augmentation 적용
- 컨디셔닝으로 사용하는 저음질 오디오나 spectrogram에 diffusion noise를 적용하여 랜덤하게 손상시킴
(diffusion time을 $[0, t_\textrm{max}]$에서 랜덤하게 샘플링, cascader는 $t_\textrm{max} = 1.0$, vocoder는 $t_\textrm{max} = 0.5$) - blur augmentation
(cascader는 크기가 10이고 표준편차 범위가 0.1~5.0인 Gaussian 1D blur kernel, vocoder는 표준편차 범위가 0.2~1.0인 2D 5$\times$5 blur kernel)
- 컨디셔닝으로 사용하는 저음질 오디오나 spectrogram에 diffusion noise를 적용하여 랜덤하게 손상시킴
2. Model inference and serving
저자들은 3가지 inference hyperparameter를 조정하였다.
- denoising schedule
- stochasticity parameter
- CFG scale
사용한 hyperparameter는 다음 표와 같다.
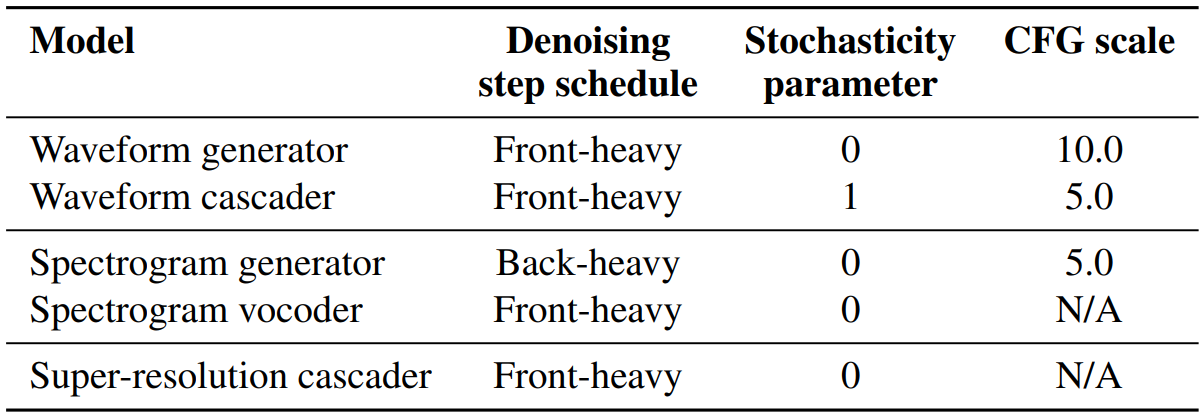
“Front-heavy”는 $t = 0$ 근처에 더 많은 step을 할당한 schedule이며, 반면에 “Back-heavy”는 $t = 1$ 근처에 더 많은 step을 할당한 schedule이다.
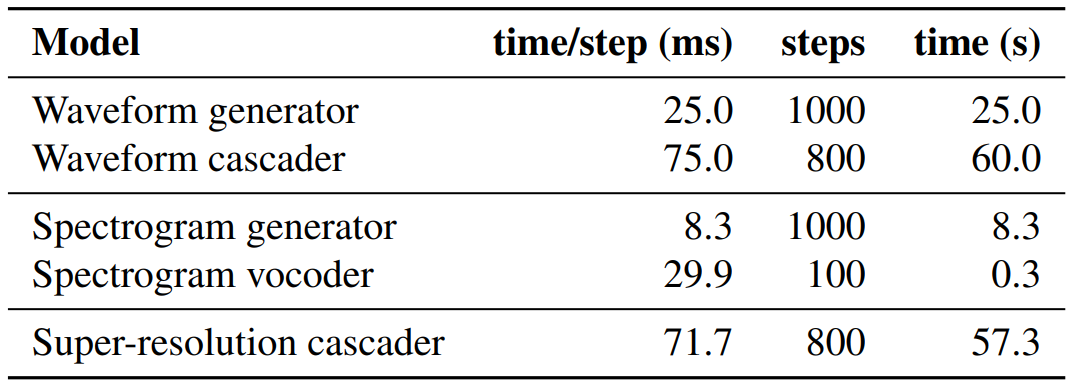
다음 표는 4개의 TPU V4에서의 inference time 비용을 나타낸 표이다.
3. Evaluation result
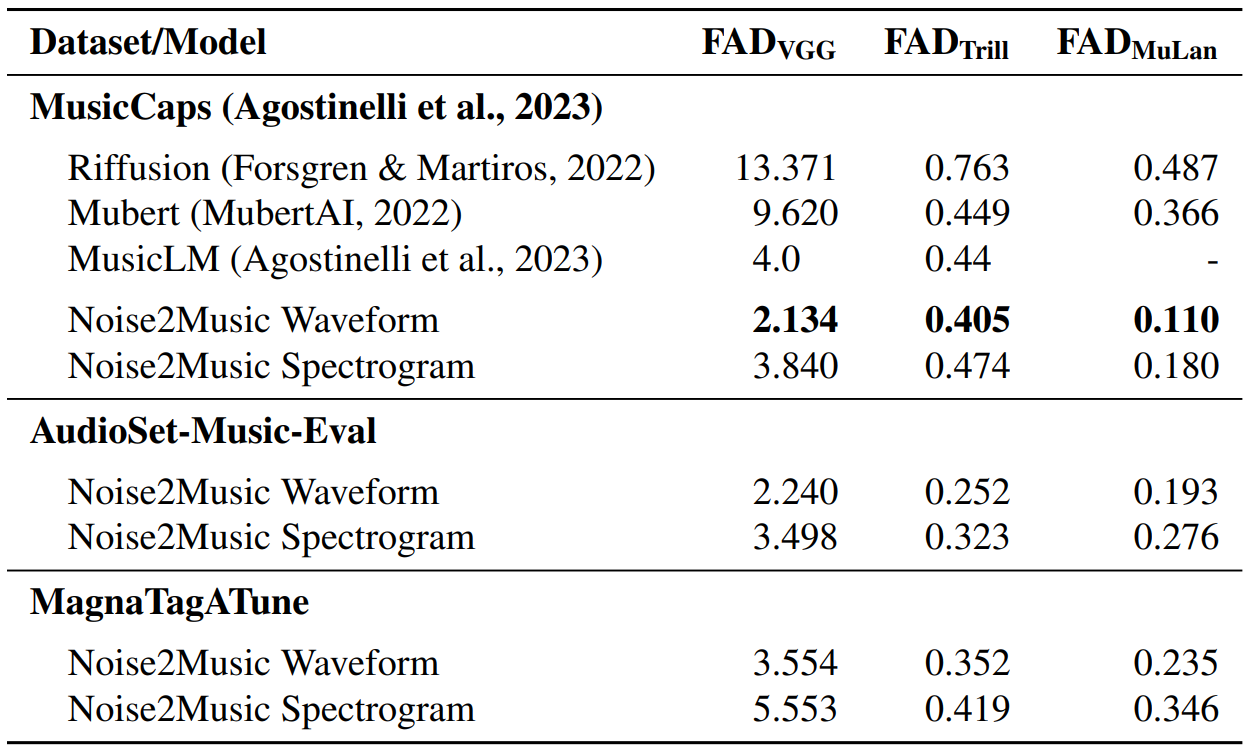
다음은 3가지 evaluation dataset에 대한 FAD를 측정한 표이다. FAD는 두 임베딩 분포의 Frechet distance를 측정한 metric이다.
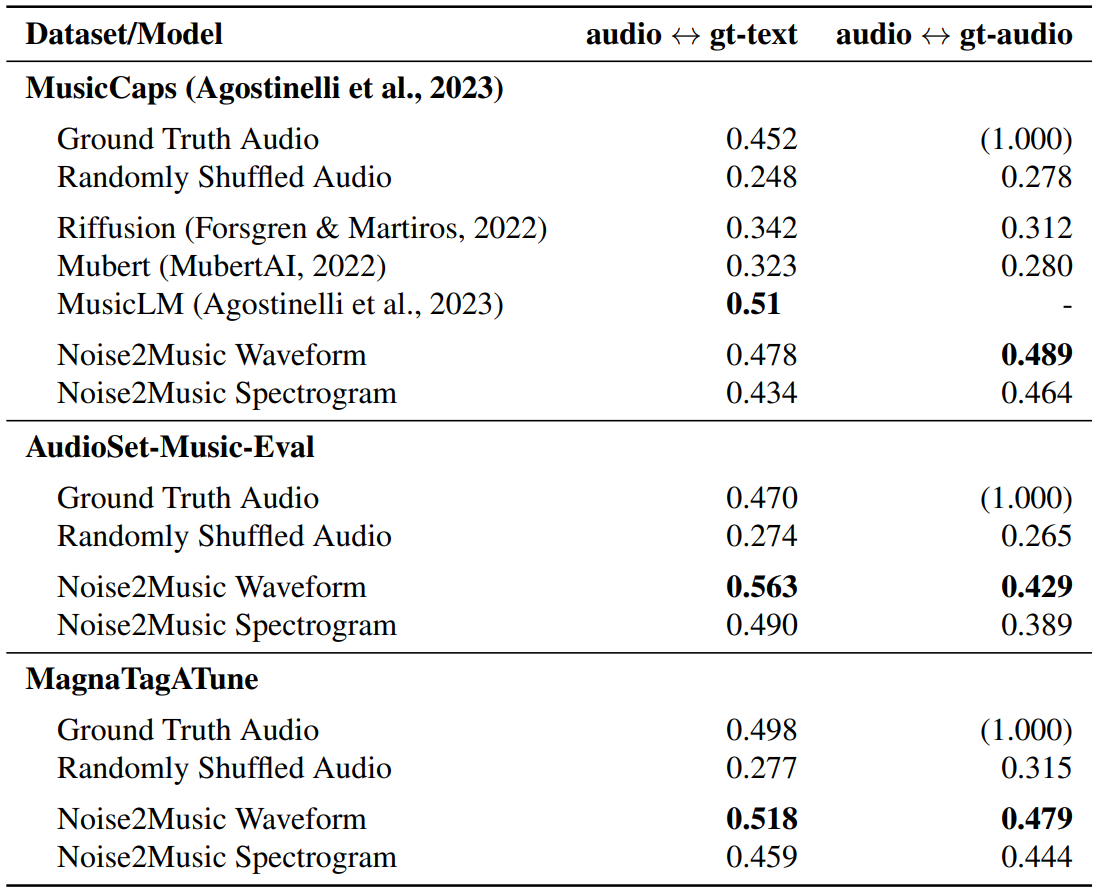
다음은 생성된 오디오와 groun-truth 텍스트 및 오디오 사이의 평균 MuLan similarity score를 측정한 표이다.
다음은 human listening study의 쌍별 비교에서 이긴 횟수를 나타낸 표이다.

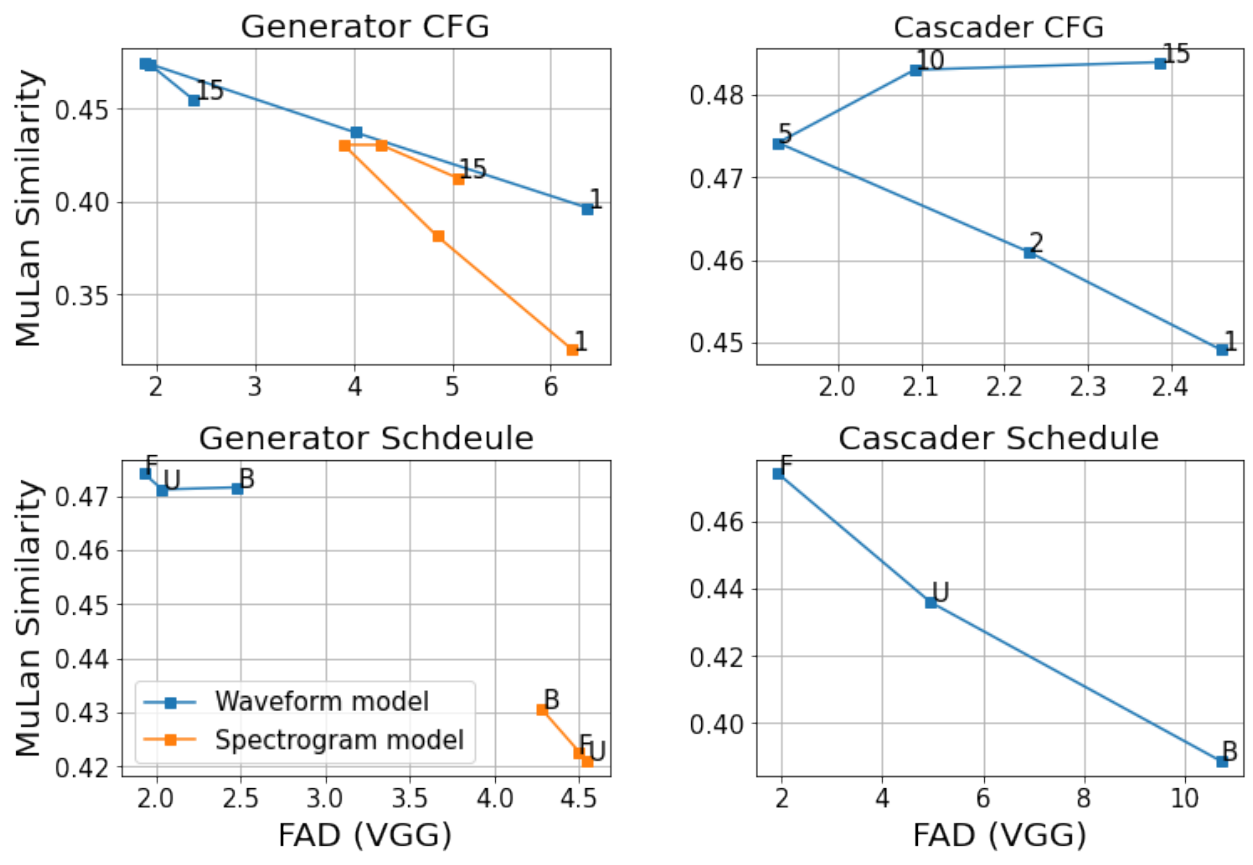
4. Inference parameter ablations
다음은 denoising step schedul과 CFG scale에 따라 FAD(VGG)와 MuLan similarity score가 어떻게 변하는지 나타낸 그래프이다.
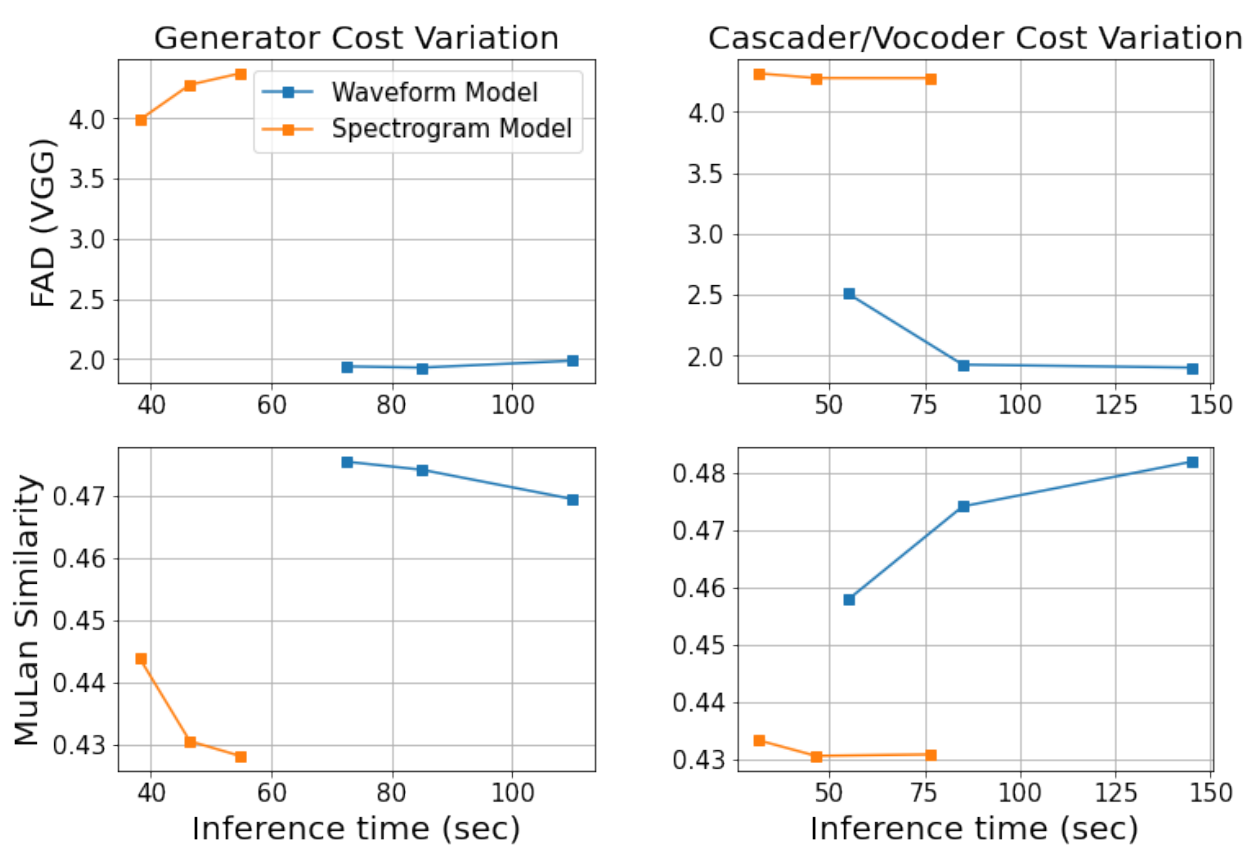
5. Inference cost and performance
다음은 inference 시간에 대한 FAD(VGG)와 MuLan similarity score를 plot한 그래프이다.
Qualitative analysis
Discussion
Spectrogram vs. waveform approach
Spectrogram과 waveform 접근 방식에는 서로 다른 이점이 있다. 본 논문에 사용된 spectrogram 모델은 waveform 모델에 비해 학습 및 serve 비용이 훨씬 저렴하고 시간 길이에서 더 확장 가능하다. 이는 spectrogram의 시퀀스 길이가 저음질 waveform의 시퀀스 길이보다 훨씬 짧기 때문이다. 또한 spectrogram에는 저음질 오디오에서 누락된 고주파수 정보가 포함되어 있다. 한편, waveform 모델은 생성 프로세스의 모든 step에서 해석 가능한 표현을 생성하므로 모델을 쉽게 디버깅하고 조정할 수 있다.