[논문리뷰] Neural Haircut: Prior-Guided Strand-Based Hair Reconstruction
ICCV 2023 (Oral). [Paper] [Page] [Github]
Vanessa Sklyarova, Jenya Chelishev, Andreea Dogaru, Igor Medvedev, Victor Lempitsky, Egor Zakharov
Samsung AI Center | Rockstar Games | FAU Erlangen-Nurnberg | Cinemersive Labs
9 Jun 2023
Introduction
본 논문은 멀티뷰 이미지 또는 동영상 프레임에서 사람의 머리카락을 복원하는 새로운 이미지 기반 모델링 방법을 제안한다. 머리카락 재구성은 매우 복잡한 기하학, 물리학, 반사율로 인해 인간 3D 모델링에서 가장 어려운 문제 중 하나로 남아 있다. 그럼에도 불구하고 특수 효과, 텔레프레즌스, 게임과 같은 많은 애플리케이션에 중요하다.
컴퓨터 그래픽에서 머리카락에 대한 지배적인 표현은 3D polyline, 즉 머리카락 가닥으로, 사실적인 렌더링과 물리 시뮬레이션을 모두 용이하게 할 수 있다. 동시에 현대의 이미지 및 동영상 기반 인간 재구성 시스템은 종종 자유도가 더 적고 추정하기 쉬운 데이터 구조를 사용하여 헤어스타일을 모델링한다. 결과적으로 이러한 방법은 종종 과도하게 매끄러운 머리카락 형상을 얻고 내부 구조 없이 헤어스타일의 외부 껍질만 모델링할 수 있다.
제어된 조명 장비와 동기화된 카메라를 사용한 조밀한 캡처 설정을 통해 정확한 가닥 기반 머리카락 재구성을 수행할 수 있다. 최근에는 재구성 프로세스를 용이하게 하기 위해 균일하거나 구조화된 조명과 카메라 보정에 의존하여 인상적인 결과를 얻었다. 최신 연구들은 물리적으로 그럴듯한 재구성을 달성하기 위해 머리카락 성장 방향의 수동 프레임별 주석을 추가로 활용했다. 그러나 결과의 인상적인 품질에도 불구하고 정교한 캡처 설정과 수동 전처리 요구 사항으로 인해 이러한 방법은 많은 실제 애플리케이션에 적합하지 않다. 헤어스타일 모델링을 위한 일부 학습 기반 방법은 획득 프로세스를 용이하게 하기 위해 가닥 기반 합성 데이터에서 학습된 머리카락 prior를 통합한다. 그러나 이러한 방법의 정확도는 자연스럽게 학습 데이터셋의 크기에 따라 달라진다. 기존 데이터셋은 일반적으로 수백 개의 샘플로 구성되어 있으며 인간 헤어스타일의 다양성을 처리하기에는 부적절하게 작기 때문에 재구성의 충실도가 낮다.
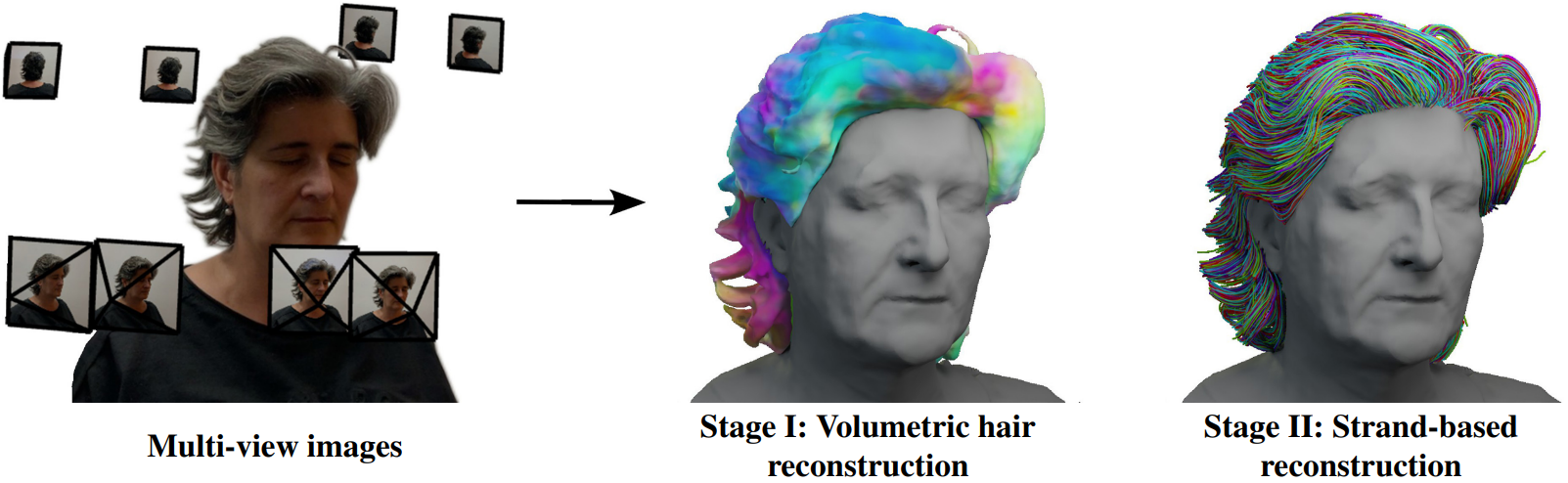
본 논문에서는 별도의 수동 주석 없이 이미지 또는 동영상 기반 데이터만을 사용하고 제어되지 않은 조명 조건에서 작동하는 헤어 모델링 방법을 제안한다. 이를 위해 저자들은 2단계 재구성 파이프라인을 설계했다. 첫 번째 단계인 대략적인 볼륨메트릭 머리카락 재구성은 암시적 체적 표현을 사용하며 순전히 데이터 기반이다. 두 번째 단계인 세밀한 가닥 기반 재구성은 머리카락 레벨에서 작동하며 소규모 합성 데이터셋에서 학습한 prior에 크게 의존한다.
첫 번째 단계에서 머리카락과 흉상 (머리와 어깨) 영역에 대한 암시적 표면 표현을 재구성한다. 또한 학습 이미지 또는 2D 방향 맵에서 관찰된 머리카락 방향과 미분 가능한 projection을 통해 일치시켜 3D orientation이라고 부르는 머리카락 성장 방향 필드를 학습한다. 이 필드는 보다 정확한 머리카락 모양 피팅을 용이하게 할 수 있지만 두 번째 단계에서 머리카락 가닥의 최적화를 제한하기 위해 주로 사용된다. 입력 프레임에서 머리카락 방향 맵을 계산하기 위해 이미지 기울기를 기반으로 하는 고전적인 접근 방식을 사용한다.
두 번째 단계는 가닥 기반 재구성을 얻기 위해 사전 학습된 prior에 의존한다. 오토인코더를 사용하여 합성 데이터에서 학습한 개선된 파라메트릭 모델을 사용하여 개별 가닥을 나타내고 새로운 diffusion 기반 prior와 결합하여 공동 분포, 즉 완전한 헤어스타일을 모델링한다. 따라서 이 단계는 최적화 프로세스를 통해 학습 기반 prior와 함께 첫 번째 단계에서 얻은 대략적인 머리카락 재구성을 조정한다. 마지막으로 soft rasterization 기반의 새로운 머리카락 렌더러를 사용하여 differentiable rendering을 통해 재구성된 헤어스타일의 충실도를 향상시킨다.
Method
1. Overview
단일 동영상 또는 멀티뷰 이미지가 3D에서 polyline 형태로 주어진 가닥 기반 머리카락 형상을 재구성한다.
\[\begin{equation} S = \{p^l\}_{l=1}^L \end{equation}\]머리카락 재구성 파이프라인은 두 단계로 구성된다. 먼저 암시적 필드의 형태로 대략적인 볼륨메트릭 머리카락 재구성을 얻는다. 그런 다음 대략적인 형상 기반, 렌더링 기반, prior 기반 항의 최적화를 사용하여 세밀한 머리카락 가닥을 재구성한다. 헤어스타일 prior는 합성 데이터셋에 대한 사전 학습 중에 별도로 얻는다.
머리카락 prior 학습
Neural strands를 따라 머리 두피에 정의되고 $T$로 표시되는 latent 형상 텍스처를 사용하여 헤어스타일을 parameterize한다. 머리카락 가닥과 latent 임베딩 사이의 매핑은 머리카락 파라메트릭 모델에 의해 제공된다. 곱슬머리 재구성의 충실도를 향상시키는 수정된 데이터 항 외에 원래 접근 방식과 동일한 아키텍처와 학습 절차를 가지고 있다. 주어진 latent 임베딩으로 가닥을 생성하는 디코더를 $\mathcal{G}$로, 인코더를 $\mathcal{E}$로 나타낸다.
그런 다음 형상 텍스처 맵 $T$에 정의된 latent diffusion 기반 prior $\mathcal{D}$ 학습한다. DDPM과 같은 이전 접근 방식을 능가하는 EDM 공식을 사용한다. 수백 개의 샘플로만 구성된 작은 헤어스타일 데이터셋을 학습하면서 헤어스타일의 사실성을 보존하는 여러 data augmentation을 도입한다.
Stage I: 대략적인 볼륨메트릭 재구성
Signed distance function (SDF) $f_\textrm{hair}, f_\textrm{bust}: \mathbb{R}^{3} \rightarrow \mathbb{R}$로 머리카락과 흉상 형상을 추정하여 대략적인 재구성에 접근한다. 시점에 의존하는 공유된 색상 필드 $c: \mathbb{R}^{3} \times \mathbb{S}^2 \rightarrow \mathbb{R}$을 사용하여 volumetric ray marching을 통해 이를 학습한다. Semantic segmentation mask를 통해 supervision을 사용하여 머리카락과 흉상 영역이 겹치지 않도록 한다. 또한 일반적으로 학습 샘플에서 볼 수 없는 머리 두피를 올바르게 재구성하기 위해 FLAME head mesh를 장면에 맞추고 흉상 SDF의 prio로 사용한다. 마지막으로 가닥 기반 재구성을 용이하게 하기 위해 머리카락 SDF를 사용하여 3D 머리카락 방향 $\beta: \mathbb{R}^3 \rightarrow \mathbb{S}^2$의 추가 필드를 학습하고 해당 projection을 관찰된 머리카락 가닥 방향과 일치시킨다.
Stage II: 세밀한 가닥 기반 재구성
머리카락 가닥을 형상 텍스처 $T$, 즉 latent 머리카락 벡터의 조밀한 2차원 맵으로 재구성한다. 여기서 맵의 위치는 두피의 모근 위치에 해당한다. 각 iteration에서 텍스처 $T$에서 $N$개의 랜덤 임베딩 \(\{z_i\}_{i=1}^N\)을 샘플링하고 사전 학습된 디코더 $\mathcal{G}$를 사용하여 해당 가닥 \(\{S_i\}_{i=1}^N\)을 얻는다. 그런 다음 이러한 가닥을 사용하여 형상 및 렌더링 기반 제약 조건을 평가한다. 형상 loss에서 머리카락 볼륨 외부의 가닥에 페널티를 부여하고 $f_\textrm{hair}$로 정의된 표면의 보이는 부분이 균일하게 덮이도록 한다. 또한 2개의 연속적인 점 사이의 정규화된 차이로 정의되는 예측된 가닥의 방향 $b_i^l$을 방향 필드 $\beta$에 일치시킨다.
\[\begin{equation} b_i^l = \frac{d_i^l}{\| d_i^l \|_2}, \quad d_i^l = p_i^{l+1} - p_i^l \end{equation}\]형상 제약 외에도 실루엣 기반 loss와 뉴럴 렌더링 loss도 사용한다. 그런 다음 렌더링된 머리카락 실루엣 $\hat{m}$과 RGB 이미지 $\hat{I}$는 neural soft hair rasterization $\mathcal{R}$을 사용하여 얻는다. 렌더러는 가려진 부분을 처리하기 위해 $f_\textrm{bust}$에서 추정된 흉상 표면을 사용한다. 실루엣 $\hat{m}$은 샘플링된 가닥에서 직접 예측되는 반면, 이미지 렌더링은 Neural Strands에서 영감을 받은 머리카락 렌더링 파이프라인을 통해 얻는다.
마지막으로 prior 기반 정규화는 사전 학습된 diffusion model을 사용하여 형상 텍스처 $T$에 직접 적용된다. 특히 형상 맵에 랜덤 noise를 적용하고 diffusion model $\mathcal{D}$를 사용하여 noise를 제거한다. 그런 다음 입력 맵 $T$의 재구성 오차를 평가하고 이 loss의 기울기를 다시 텍스처로 역전파한다. 이 파이프라인은 DreamFusion 방법에서 영감을 얻었지만 작은 헤어스타일 데이터셋에서 학습을 용이하게 하는 약간의 수정이 있다.
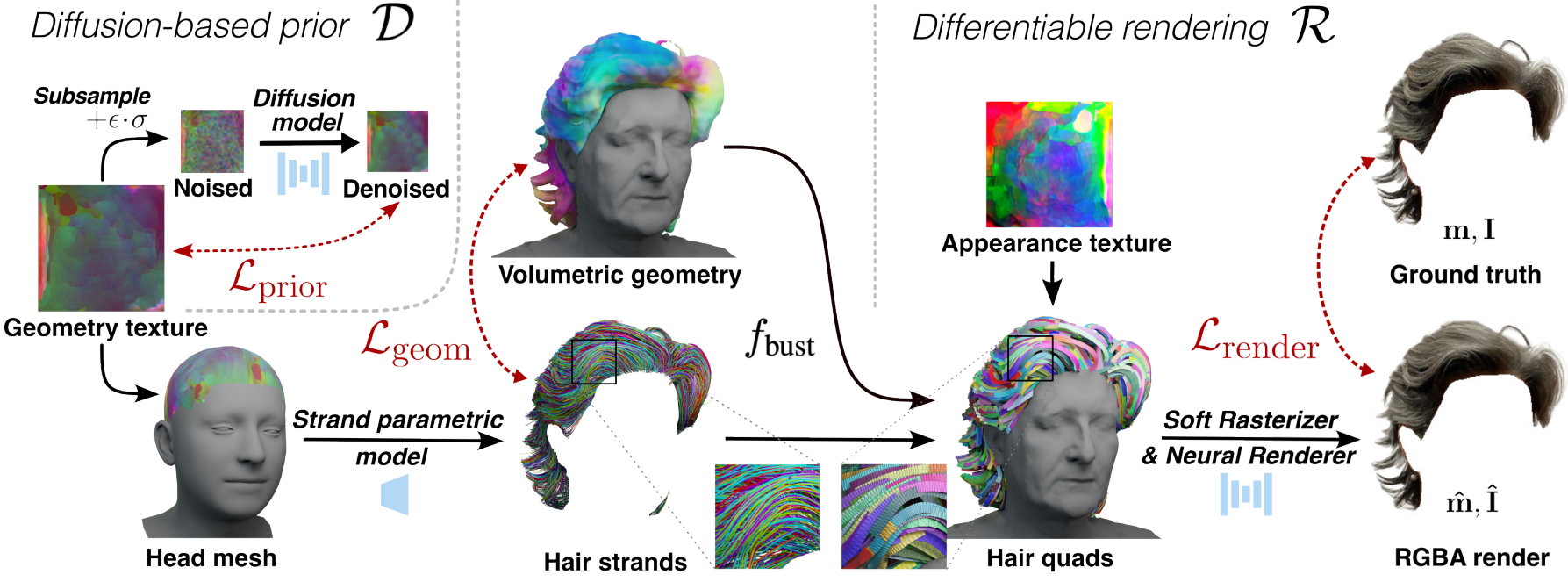
세밀한 재구성 단계의 계획은 위 그림에 나와 있다.
2. Hair prior training
글로벌 헤어스타일 prior는 형상 텍스처 $T$를 통해 서로 인터페이스하는 머리카락 가닥 파라메트릭 모델과 latent diffusion 네트워크를 사용하여 학습된다.
머리카락 가닥 파라메트릭 모델
머리카락 가닥에 대한 latent 표현을 얻기 위해 가닥 \(S = \{p^l\}_{l=1}^L\)을 인코더 $\mathcal{E}$를 통해 latent 벡터 $z$로 매핑하고 디코더 $\mathcal{G}$를 통해 다시 매핑하는 VAE를 따르고 학습한다. 학습 중에 reparameterization trick을 사용한다. 이 모델은 머리카락 가닥의 합성 데이터셋에서 데이터 항 \(\mathcal{L}_\textrm{data}\)와 KL divergence 항 $\mathcal{L}_\textrm{KL}$을 사용하여 학습된다. 데이터 항은 방향 \(\hat{b}^l\)과 $b^l$에 대한 코사인 거리뿐만 아니라 예측된 \(\hat{p}^l\)과 ground-truth 포인트 $p^l$ 사이의 L2 오차로 구성된다. 예측 가닥과 ground-truth 가닥의 곡률 \(\hat{g}^l\)과 $g^l$을 추가로 일치시켜 곱슬 머리를 더 잘 모델링한다. 여기서
\[\begin{equation} g^l = \| b^l \times b^{l+1} \|_2 \end{equation}\]이다. 따라서 데이터 항은 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{data} = \sum_{l=1}^L \| \hat{p}^l - p^l \|_2^2 + \lambda_d (1 - \hat{b}^l b^l) + \lambda_c \| \hat{g}^l - g^l \|_2^2 \end{equation}\]그리고 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{VAE} = \mathcal{L}_\textrm{data} + \lambda_\textrm{KL} \mathcal{L}_\textrm{KL} (\mathcal{N} (z_\mu, z_\sigma) \| \mathcal{N} (0, I)) \end{equation}\]헤어스타일 diffusion model
사전 학습된 가닥 인코더 $\mathcal{E}$를 사용하여 latent descriptor \(\{z_i\}_{i=1}^N\)을 먼저 추정하여 $N$개의 가닥 \(\{S_i\}_{i=1}^N\)로 구성된 합성 헤어스타일의 latent 표현을 얻는다. 그런 다음 가장 nearest neighbor interpolation을 사용하여 밀집된 텍스처 $T$로 변환한다. 학습 샘플의 다양성을 높이기 위해 인코딩 전에 헤어스타일의 사실성을 보존하는 augmentation을 사용한다. 또한 학습 속도를 높이고 diffusion model의 입력을 더욱 다양화하기 위해 전체 텍스처를 저해상도 맵 \(T_\textrm{LR}\)로 하위 샘플링한다.
EDM (Elucidating Diffusion Moldel)을 사용하여 denoiser $D$를 학습한다. 학습 샘플 \(T_\textrm{LR}\)을 EDM 논문과 일치시키기 위해 $y$로 표시하고 noised 입력 $x = y + \sigma \cdot \epsilon$을 얻는다. 여기서 $\epsilon \sim \mathcal{N} (0, I)$이고 $\sigma$는 noise 강도이다. 그런 다음 denoise된 입력을 예측한다.
\[\begin{equation} \mathcal{D} (x, \sigma) = c_\textrm{skip} (\sigma) \cdot x + c_\textrm{out} (\sigma) \cdot \mathcal{F} (c_\textrm{in} (\sigma) \cdot x, c_\textrm{noise} (\sigma)) \end{equation}\]여기서 $c_\textrm{skip}$, $c_\textrm{out}$, $c_\textrm{in}$, $c_\textrm{noise}$는 EDM 논문에서 제안된 전제 조건 접근 방식의 일부이며, 낮은 noise 강도 $\sigma$에 대한 $\mathcal{D}$의 robustness를 향상시키고 $\mathcal{F}$는 신경망이다. 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{diff} = \mathbb{E}_{y, \sigma, \epsilon} [\lambda_\textrm{diff} (\sigma) \cdot \| \mathcal{D} (x, \sigma) - y \|_2^2] \end{equation}\]여기서 $\lambda_\textrm{diff} (\sigma)$는 가중 함수이고 기대값은 샘플링에 의해 근사된다.
3. Coarse volumetric reconstrution
머리카락과 흉상 neural SDF를 사용하여 분할된 형태로 대략적인 머리 형상을 나타낸다. 뉴럴 암시적 표면에 대한 volumetric ray marching 접근 방식을 사용하고 이를 맞추기 위해 NeuS를 사용한다. 머리카락 형상과 흉상 (머리와 어깨) 형상을 별도의 모양으로 재구성할 때 다중 실험실 재구성을 수용하도록 NeuS를 수정한다. 학습은 해당 광선 $v$를 따라 샘플링된 $N$개의 포인트 $x_i$의 radiance를 사용하여 픽셀의 색상 $c$를 근사화하여 진행된다. 색상은 다음과 같이 예측된다.
\[\begin{equation} \hat{c} = \sum_{i=1}^N T_i \cdot \alpha_i \cdot c(x_i, v, l, n), \quad T_i = \sum_{j=1}^{i-1} (1 - \alpha_i) \end{equation}\]여기서 $T_i$는 누적 투과율, $\alpha_i$는 불투명도, $l$과 $n$은 혼합된 머리카락의 흉상 feature와 법선, $c$는 view-dependent radiance field이다. 머리카락과 흉상의 개별 불투명도를 혼합하여 광선을 따라 각 지점의 불투명도 $\alpha_i$를 계산한다.
\[\begin{equation} \alpha_i = \min (\alpha_i^\textrm{hair} + \alpha_i^\textrm{hair}, 1) \end{equation}\]색상 외에도 흉상과 머리카락 마스크도 렌더링한다.
\[\begin{equation} \hat{o}_\textrm{hair} = \sum_{i=1}^N T_i \cdot \alpha_i^\textrm{hair}, \quad \hat{o}_\textrm{bust} = \sum_{i=1}^N T_i \cdot \alpha_i^\textrm{bust} \end{equation}\]학습 loss에는 $\hat{c}$와 $c$를 일치시키는 photometric L1 loss \(\mathcal{L}_\textrm{color}\), 예측된 마스크와 ground-truth $m_\textrm{bust}$, $m_\textrm{bust}$ 사이에 binary cross-entropy를 적용하는 마스크 기반 loss \(\mathcal{L}_\textrm{mask}\), $f_\textrm{hair}$와 $f_\textrm{bust}$ 모두에 적용되는 regularizing Eikonal 항 \(\mathcal{L}_\textrm{reg}\)가 포함된다.
추가 loss에는 흉상 모양에 대한 정규화가 포함된다. 대략적인 재구성을 진행하기 전에 2D 얼굴 랜드마크를 기반으로 한 최적화를 사용하여 장면에 FLAME head mesh를 맞춘다. 이 mesh를 사용하여 SDF를 mesh에 일치시키는 정규화 제약 조건 \(\mathcal{L}_\textrm{head}\)을 적용하여 $f_\textrm{bust}$가 머리 두피 표면 영역을 포함하도록 한다. 이 loss를 구현하기 위해 mesh 기반 데이터를 사용하여 neural SDF를 피팅하는 이전 연구들을 따른다.
마지막으로 모발 성장 방향의 추가 필드인 $\beta$를 대략적인 재구성에 통합한다. $f_\textrm{hair}$의 미분 가능한 표면 렌더링을 통해 이를 학습한다. 다음으로 머리카락 표면과 광선 $v$의 교차점 $x_s$를 얻는다. 그런 다음 Plucker 선 좌표를 사용하여 3D 방향 필드 $\beta (x_s)$를 카메라 $P$에 project한다. Project된 방향 $L (x_s, \beta (x_s) ; P)$는 Gabor 필터를 사용하여 학습 이미지에서 추정된 2D 방향 맵과 일치된다. 매칭 loss \(\mathcal{L}_\textrm{dir}\)은 가닥 기반 재구성에 대한 이전 연구들을 따르고 예상 방향과 실제 방향 사이의 최소 각도 차이에 페널티를 준다.
전반적으로 대략적인 재구성을 위한 목적 함수는 다음과 같다.
\[\begin{aligned} \mathcal{L}_\textrm{coarse} = \mathcal{L}_\textrm{color} &+ \lambda_\textrm{mask} \mathcal{L}_\textrm{mask} + \lambda_\textrm{reg} \mathcal{L}_\textrm{reg} \\ &+ \lambda_\textrm{head} \mathcal{L}_\textrm{head} + \lambda_\textrm{dir} \mathcal{L}_\textrm{dir} \end{aligned}\]4. Fine strand-based reconstruction
머리카락을 재구성하기 위해 사전 학습된 네트워크 $\mathcal{G}$를 사용하여 헤어스타일을 디코딩할 수 있는 latent 머리카락 형상 텍스처 $T$를 학습한다. 그러나 이 맵을 직접 최적화하는 대신 소위 deep image prior를 사용하여 UNet과 같은 신경망으로 parameterize한다. 이러한 parameterization은 디코딩된 가닥에서 희소한 기울기의 추가 smoothing을 필요로 하지 않는다. 이러한 새로운 parameterization을 $T_\theta$로 표시한다.
학습은 피팅된 FLAME mesh의 두피 부분에서 $N$개의 포인트를 샘플링하고 이를 가닥 \(\{S_i\}_{i=1}^N\)으로 디코딩하여 진행되며, 각 가닥은 $L$개의 포인트로 구성된다.
\[\begin{equation} S_i = \{p_i^l\}_{l=1}^L \end{equation}\]그런 다음 다음 목적 함수들을 평가한다.
- 가닥을 대략적인 형상에 일치시키는 형상 기반 loss \(\mathcal{L}_\textrm{geom}\)
- Differentiable rendering을 통해 계산한 photometric 제약 \(\mathcal{L}_\textrm{render}\)
- Diffusion 기반 prior loss \(\mathcal{L}_\textrm{prior}\)
형상 기반 loss
최적화된 가닥이 대략적인 머리카락 볼륨 내부에 놓이도록 하기 위해 loss \(\mathcal{L}_\textrm{vol}\)을 사용하여 외부에서 이탈하는 가닥의 포인트에 페널티를 준다.
\[\begin{equation} \mathcal{L}_\textrm{vol} = \sum_{i=1}^N \sum_{l=1}^L \mathbb{I} [f_\textrm{hair} (p_i^l) > 0] (f_\textrm{hair} (p_i^l))^2 \end{equation}\]여기서 $\mathbb{I}$는 indicator function이다.
또한 학습된 가닥이 대략적인 모발 표면 $S$의 보이는 부분을 조밀하게 덮도록 하기 위해 이 표면에서 샘플링된 $K$개의 무작위 점 $x_k$와 가닥의 가장 가까운 점 $p_k$ 사이의 오차를 최소화한다. 이 loss \(\mathcal{L}_\textrm{chm}\)은 대략적인 모발 표면의 보이는 부분과 학습된 가닥 사이의 단방향 챔퍼 거리와 정확히 동일하다.
\[\begin{equation} \mathcal{L}_\textrm{chm} = \sum_{k=1}^K \| x_k - p_k \|_2^2 \end{equation}\]마지막으로, 일부 작은 임계값 $\tau$보다 보이는 모발 표면 $S$에 더 가까운 가닥의 모든 지점에서 모발 방향과 암시적 필드 $\beta$ 사이의 거리를 계산한다. 이 $M$개의 포인트를 $p_m$으로 표시하고 방향을 $b_m$으로 표시한다. 방향 loss \(\mathcal{L}_\textrm{orient}\)는 다음과 같이 쓸 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{orient} = \sum_{m=1}^M (1 - \vert b_m \cdot \beta (p_m) \vert) \end{equation}\]\(\mathcal{L}_\textrm{dir}\)의 photometric 특성으로 인해 필드 $\beta$가 이 영역에서만 정확한 방향을 학습하도록 하기 때문에 외부 모발 표면 근처 가닥의 방향에 불이익을 준다.
전반적으로 전체 형상 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{geom} = \mathcal{L}_\textrm{vol} + \lambda_\textrm{chm} \mathcal{L}_\textrm{chm} + \lambda_\textrm{orient} \mathcal{L}_\textrm{orient} \end{equation}\]렌더링 기반 loss들
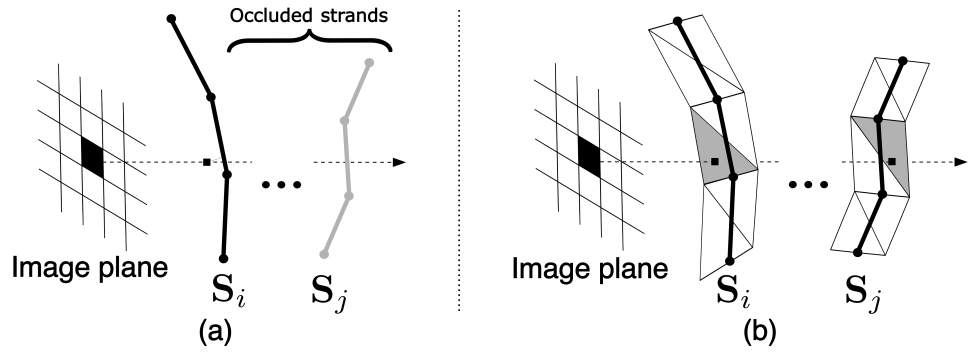
저자들은 가시적인 머리카락 형상을 개선하기 위해 머리카락 가닥의 미분 렌더링을 위한 새로운 접근 방식을 개발했다. 이전 hair rasterization 접근 방식은 그래픽 API line rasterization 알고리즘에 의존한다. 계산적으로 효율적이기는 하지만 이러한 방법은 위 그림의 (a)와 같이 선분 $z$-버퍼의 첫 번째 요소에 대한 기울기만 제공한다. 동시에 mesh inverse rendering task의 경우 기울기를 여러 $z$-버퍼 요소로 전파하는 것이 매우 유익한 것으로 나타났다. 위 그림의 (b)와 같이 mesh에 대한 soft rasterization을 머리카락 가닥의 differentiable rendering에 적용한다.
먼저 머리카락 가닥을 소위 hair quad들로 변환한다. 그들은 가닥 궤적을 따르고 법선이 카메라를 향하는 줄무늬 모양의 mesh로 구성된다. Quad mesh의 정점은 가닥에 대해 완전히 미분할 수 있다는 것이다. 그런 다음 soft rasterization을 사용하여 이 mesh를 렌더링한다. Marching Cubes를 사용하여 얻은 $f_\textrm{bust}$의 zero iso-surface를 렌더링 파이프라인에 포함시켜 머리카락-흉상 가려짐을 처리한다. 이전의 rasterization 방법과 달리, 본 논문의 접근 방식에서는 부드러운 실루엣 셰이더를 사용하여 머리카락 형상에서 머리카락에 대한 segmentation mask를 직접 예측한다. 이는 마스크 기반 목적 함수에서 형상으로의 제약 없는 gradient flow를 허용한다. 색상을 렌더링하기 위해 머리카락의 view-dependent reflectance을 처리할 수 있는 뉴럴 렌더링 접근 방식을 따르고 사용한다. 특히 형상 텍스처 $T$와 유사하게 외관 텍스처 $A$를 학습하고 렌더링 U-Net과 함께 사용하여 렌더링을 생성한다.
위에서 설명한 hair rasterization 파이프라인 $\mathcal{R}$의 결과로 완전히 미분 가능한 방식으로 머리카락 실루엣 $\hat{m}$과 이미지 $\hat{I}$를 모두 얻는다.
\[\begin{equation} \hat{m}, \hat{I} = \mathcal{R}_\phi (\{S_i\}_{i=1}^N, f_\textrm{bust}, \mathcal{P}) \end{equation}\]여기서 $\phi$는 외관 텍스처와 렌더링 UNet의 학습 가능한 파라미터를 나타내며, $\mathcal{P}$는 카메라 파라미터이다. 그런 다음 L1 loss \(\mathcal{L}_\textrm{mask}\)와 \(\mathcal{L}_\textrm{rgb}\)를 적용하여 얘측된 실루엣과 색상을 ground truth $m$, $I$와 일치시킨다. 최종 렌더링 loss는 이 항들의 가중 합이다.
\[\begin{equation} \mathcal{L}_\textrm{render} = \mathcal{L}_\textrm{rgb} + \lambda_\textrm{mask} \mathcal{L}_\textrm{mask} \end{equation}\]Diffusion 기반 prior
사전 학습된 diffusion을 prior에 적용하기 위해 DreamFusion의 Score Distillation Sampling (SDS) 접근 방식을 사용한다. 이 방법에서는 사전 학습된 diffusion model을 사용하여 이미지 공간의 기울기를 제공하여 neural radiance field의 최적화를 가이드한다. 이러한 기울기는 diffusion model을 학습하는 데 사용되는 것과 동일한 loss \(\mathcal{L}_\textrm{diff}\)에서 발생한다. 그러나 denoising 신경망 $\mathcal{F}$를 통해 이 loss를 역전파하는 대신 SDS 접근 방식은 noise가 있는 입력 $x$에 대한 기울기를 $\partial \mathcal{F} / \partial x = \mathcal{I}$라고 가정한다.
그러나 이러한 트릭은 DreamFusion에서 사용되는 DDPM 학습 공식에만 필요하다. 반면 본 논문이 사용하는 EDM의 경우 $\mathcal{F}$를 통한 적절한 역전파가 더 나은 결과를 가져온다. 따라서 본 논문의 경우 prior 정규화 항 \(\mathcal{L}_\textrm{prior} = \mathcal{L}_\textrm{diff}\)이다.
이 loss를 계산하기 위해 diffusion model을 학습하는 동안과 동일한 절차를 사용한다. 랜덤 noise $\epsilon$와 noise level $\sigma$를 샘플링하여 형상 맵에 적용한다. 그런 다음 diffusion model을 통해 전달하기 전에 무작위 서브 샘플링을 수행하여 $T_\theta$의 해상도를 줄인다. Denoiser의 가중치를 동결된 상태로 유지하면서 loss \(\mathcal{L}_\textrm{prior}\)를 형상 텍스처 $T_\theta$의 매개변수 $\theta$로 직접 역전파한다.
전반적으로 가닥 기반 재구성 단계의 최적화 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{fine} = \mathcal{L}_\textrm{geom} + \lambda_\textrm{render} \mathcal{L}_\textrm{render} + \lambda_\textrm{prior} \mathcal{L}_\textrm{prior} \end{equation}\]Experiments
- 데이터셋: USC-HairSalon, H3DS Dataset
1. Real-world evaluation
다음은 현실 평가 결과이다.

다음은 단일 동영상에서 얻은 높은 충실도의 머리카락 재구성 결과이다.

2. Ablation study
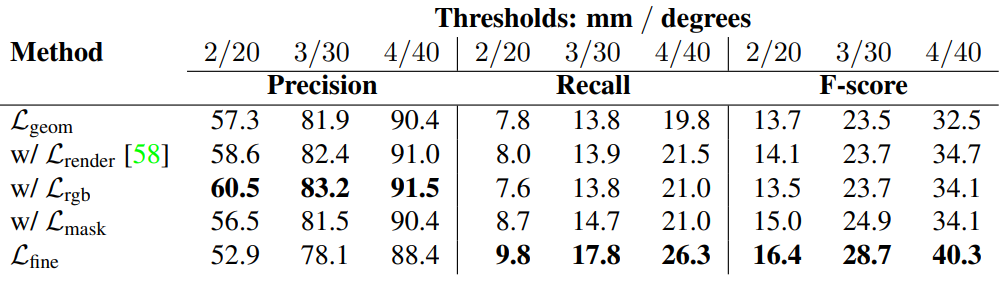
다음은 개별 구성 요소에 대한 광범위한 정량적 평가 결과이다.
다음은 곡률 (상단)과 diffusion loss들 (하단)에 대한 ablation 결과이다.

Limitations
본 논문의 시스템은 여전히 곱슬머리를 표현하는 데 어려움을 겪고 있으며 재구성을 생성하기 위해 정확한 머리카락과 신체 segmentation mask에 의존한다.