[논문리뷰] NeRFLiX: High-Quality Neural View Synthesis by Learning a Degradation-Driven Inter-viewpoint MiXer
CVPR 2023. [Paper] [Page] [Github]
Kun Zhou, Wenbo Li, Yi Wang, Tao Hu, Nianjuan Jiang, Xiaoguang Han, Jiangbo Lu
SSE, CUHK-Shenzhen | SmartMore Corporation | CUHK | Shanghai AI Laboratory
13 Mar 2023

Introduction
NeRF의 성공에 힘입어 이와 유사한 수많은 접근 방식이 제안되어 성능을 지속적으로 더 높은 수준으로 끌어올렸다. 사실, NeRF의 전제 조건 중 하나는 학습을 위해 촬영한 사진의 정확한 카메라 설정이다. 그러나 정확한 카메라 포즈를 얻는 것은 실제로 매우 어렵다. 모양-radiance 공동 적응 문제는 학습된 radiance field가 부정확한 형상으로 학습 뷰를 완벽하게 설명할 수 있지만 보이지 않는 뷰로 일반화하는 데는 적합하지 않다. 반면 정교한 형상, 조명, 재료 및 기타 요소를 표현하는 능력은 NeRF의 단순화된 장면 표현에 의해 제한된다. 이러한 제한에 따라 NeRF 모델은 눈에 띄는 아티팩트 (흐림, 노이즈, 세부 정보 누락 등)를 초래할 수 있으며, 이를 NeRF-style degradations라고 한다.
앞서 언급한 한계를 해결하기 위해 수많은 연구가 제안되었다. 예를 들어, 일부 연구에서는 카메라 파라미터를 radiance field와 공동으로 최적화하여 가능한 한 정확하게 카메라 포즈를 개선하였다. 또 다른 연구들은 재료와 환경 조명을 동시에 고려하는 물리 기반 모델을 제시하였다. 고품질 뷰 합성에 대한 요구 사항을 충족하려면 복잡한 inverse rendering 시스템을 구축할 때 모든 요소를 신중하게 검사해야 한다. 최적화하기 어려울 뿐만 아니라 새로운 환경에서 빠르게 배포할 수 있도록 확장할 수도 없다.
복잡한 물리 기반 렌더링 모델에 관계없이 NeRF에서 합성된 뷰를 직접 향상시키기 위한 NeRF와 독립적인 복원 모델을 설계하는 것이 가능할까?
현실 세계의 아티팩트를 제거하기 위한 복원 모델을 학습시키기 위해 대규모의 쌍 데이터를 구성하는 것이 중요하다. NeRF-style degradation에 관해서는 두 가지 과제가 있다.
- 상당한 쌍의 학습 데이터
- NeRF degradation 분석
첫째, 대규모 학습 쌍, 즉 잘 학습된 NeRF의 출력과 해당 GT 이미지를 수집하는 것은 비실용적이다. 둘째, NeRF-style degradation은 거의 주목받지 못했다. 일반적으로 JPEG 압축, 센서 노이즈, 모션 블러로 어려움을 겪는 실제 이미지와 달리 NeRF-style 아티팩트는 복잡하고 기존 아티팩트와 다르다. 지금까지 NeRF-style degradation을 조사한 연구는 없었다.
본 논문에서는 NeRF-style의 대규모 쌍 데이터를 시뮬레이션하는 것의 타당성에 대한 연구를 처음하고자 한다. 이를 위해 NeRF 메커니즘을 고려한 일반적인 NeRF 스타일 아티팩트에 대한 새로운 degradation 시뮬레이터를 제시하였다. 저자들은 전반적인 NeRF 렌더링 파이프라인을 검토하고, NeRF 합성 뷰의 실제 렌더링된 아티팩트를 시뮬레이션하기 위한 세 가지 기본 degradation 유형을 제시하고 실제 렌더링된 사진과 시뮬레이션된 사진 간의 분포 유사성을 경험적으로 평가하였다. NeRF에 독립적인 복원 모델을 개발하는 것은 다양한 장면에 걸쳐 다양한 NeRF-style degradation을 포괄하는 상당한 데이터셋을 구성함으로써 가능해졌다.
다음으로, 시뮬레이션된 데이터셋을 사용하여 기존 SOTA 이미지 복원 프레임워크로 NeRF 아티팩트를 제거한다. NeRF 입력 뷰는 매우 다양한 각도와 위치에서 가져오기 때문에 대응 관계를 추정하는 것이 매우 어렵다. 이 문제를 해결하기 위해 픽셀 및 패치 수준에서 이미지 콘텐츠를 점진적으로 정렬하는 degradation 기반 inter-viewpoint mixer (IVM)를 제안하였다. 효율성을 극대화하고 성능을 개선하기 위해 가장 관련성 있는 레퍼런스 학습 뷰만 선택하는 뷰 선택 기술도 제안하였다.
간단히 말해서, 본 논문은 NeRF에 독립적인 복원 모델인 NeRFLiX를 제시하였으며, NeRFLiX는 다양한 렌더링 degradation이 있는 NeRF 합성 프레임이 주어지면 고품질 결과를 성공적으로 복원한다.
Methodology
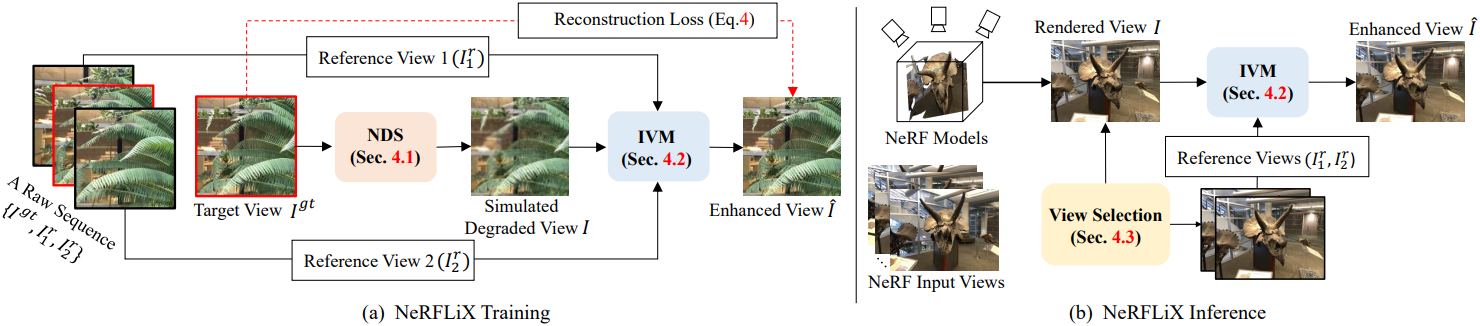
본 논문에서는 NeRF 모델에서 렌더링된 새로운 뷰 이미지를 향상시키기 위해 NeRF에 독립적인 복원 모델인 NeRFLiX를 제시하였다. NeRFLiX는 NeRF-style degradation simulator (NDS)와 inter-viewpoint mixer (IVM)의 두 가지 필수 구성 요소로 구성된다. 학습 단계에서는 제안된 NDS를 사용하여 대규모 학습 데이터를 생성한 다음, 이 데이터를 사용하여 두 개의 레퍼런스 뷰로부터 NeRF에서 렌더링된 뷰를 개선하기 위한 IVM을 학습시킨다. Inference 단계에서는 IVM을 채택하여 선택된 가장 관련성 있는 레퍼런스 뷰에서 유용한 정보를 융합하여 렌더링된 뷰를 향상시킨다.
1. NeRF-Style Degradation Simulator (NDS)
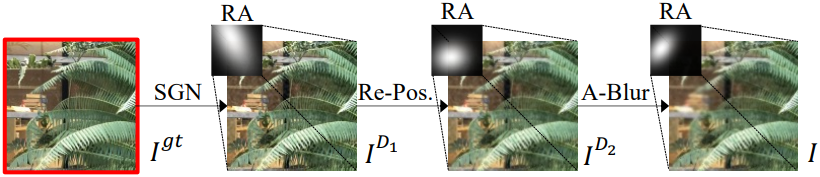
다양한 환경에서 잘 구성된 장면을 수집하고 각 장면에 대한 NeRF 모델을 학습시키는 데 어려움이 있기 때문에, 아티팩트 제거를 위한 대규모 NeRF 데이터를 직접 수집하는 것은 불가능하다. 저자들은 NeRF 렌더링 이미지와 시각적, 통계적으로 비슷한 상당한 규모의 학습 데이터셋을 생성하는 NeRF degradation 시뮬레이터를 설계하였다.
우선 저자들은 인접한 프레임을 시퀀스로 처리하는 LLFF-T와 Vimeo90K에서 데이터를 수집하였다. 각 시퀀스는 세 개의 이미지, 즉 대상 뷰 \(I^\textrm{gt}\)와 두 개의 레퍼런스 뷰 \(\{I_1^r, I_2^r\}\)로 구성된다. 시퀀스에서 쌍을 이룬 데이터를 구성하기 위해 제안된 NDS를 사용하여 $I^\textrm{gt}$를 저하시키고 시뮬레이션된 저하된 뷰 $I$를 얻는다.
대상 뷰 $I^\textrm{gt}$에 세 가지 유형의 degradation을 적용한다.
- splatted Gaussian noise (SGN)
- re-positioning (Re-Pos.)
- anisotropic blur (A-Blur)
이러한 시뮬레이션에 대한 다른 모델이 있을 수 있다.
Splatted Gaussian noise
Gaussian noise는 이미지/동영상 노이즈 제거에 자주 사용되지만 NeRF 렌더링 노이즈는 분명히 다르다. 3D 포인트에 부딪히는 광선은 노이즈가 많은 카메라 파라미터로 인해 근처 2D 영역 내에서 reprojection된다. 결과적으로 NeRF-style noise는 2D 공간에 분산된다. 이 관찰을 통해 저자들은 다음과 같이 정의되는 splatted Gaussian noise를 제시하였다.
\[\begin{equation} I^{D1} = (I^\textrm{gt} + n) \circledast g \end{equation}\]($n$은 $I^\textrm{gt}$와 동일한 해상도를 갖는 2D Gaussian noise map, $g$는 isotropic Gaussian blur kernel)
Re-positioning
저자들은 ray jittering을 시뮬레이션하기 위해 re-positioning degradation을 설계하였다. 위치 $(i,j)$의 픽셀에 대해 확률 0.1의 랜덤 2D offset \(\delta_i, \delta_j \in [-2, 2]\)를 추가한다.
\[\begin{equation} I^{D2} (i,j) = \begin{cases} I^{D1} (i,j) & \; \textrm{if} \; p > 0.1 \\ I^{D1} (i + \delta_i, j + \delta_j) & \; \textrm{else} \; p \le 0.1 \end{cases} \end{equation}\]Anisotropic blur
또한, 저자들의 관찰에 따르면 NeRF 합성 프레임에는 흐릿한 콘텐츠도 포함되어 있다. 흐릿한 패턴을 시뮬레이션하기 위해, anisotropic Gaussian kernel들을 사용하여 대상 프레임을 흐릿하게 한다.
Region adaptive strategy
NeRF는 종종 불균형한 학습 뷰로 학습된다. 결과적으로 새로운 뷰가 주어지면 projection된 2D 영역은 다양한 degradation 수준을 갖는다. 따라서 공간적으로 다양한 방식으로 사용된 각각의 degradation을 수행한다. 보다 구체적으로, 마스크 $M$을 2차원 oriented anisotropic Gaussian으로 정의한다.
\[\begin{equation} M(i,j) = G(i - c_i, j - c_j; \sigma_i, \sigma_j, A) \end{equation}\]($(c_i, c_j)$와 $(\sigma_i, \sigma_j)$는 평균과 표준 편차, $A$는 방향 각도)
그런 다음 마스크 $M$을 사용하여 각 degradation의 입력과 출력을 선형적으로 혼합한다. 아래 그림에서 볼 수 있듯이 시뮬레이션된 렌더링된 뷰는 실제 NeRF에서 렌더링된 뷰와 시각적으로 일치한다.

2. Inter-viewpoint Mixer (IVM)
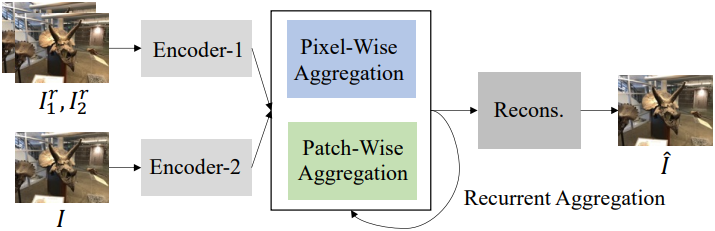
- 입력
- NDS 또는 NeRF 모델에서 생성된 저하된 뷰 $I$
- 두 개의 고품질 레퍼런스 뷰 \(\{I_1^r, I_2^r\}\)
- 목표
- 레퍼런스 뷰에서 유용한 정보를 추출하고 $I$의 향상된 버전 \(\hat{I}\)를 복원
기존 방법은 correspondence 추정 및 집계를 위해 optical flow 또는 deformable convolution을 사용하였다. 반면 NeRF 렌더링 및 입력 뷰는 매우 다른 각도와 위치에서 나오기 때문에 정확한 시점 간 집계를 수행하는 것이 어렵다.
이 문제를 해결하기 위해, 두 개의 고품질 레퍼런스 뷰에서 픽셀 단위 및 패치 단위 콘텐츠를 점진적으로 융합하여 보다 효과적인 뷰 집계를 달성하는 하이브리드 inter-viewpoint mixer인 IVM을 제안하였다. IVM은 feature 추출, 하이브리드 뷰 집계, 재구성의 세 가지 모듈이 있다.
- 두 개의 convolution 인코더는 feature 추출 단계에서 $I$와 \(\{I_1^r, I_2^r\}\)를 각각 처리하는 데 사용된다.
- Window 기반 attention 모듈과 deformable convolution을 사용하여 패치별 및 픽셀별 집계를 달성한다.
- 다음 loss로 학습된 재구성 모듈을 사용하여 향상된 뷰 $\hat{I}$가 생성된다.
($\theta$는 IVM의 학습 가능한 파라미터)
3. View Selection
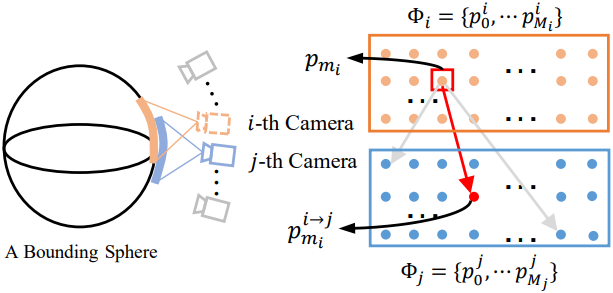
Inference 단계에서 NeRF 렌더링된 뷰 $I$의 경우, IVM은 인접한 두 개의 고품질 뷰에서 콘텐츠를 집계하여 향상된 버전을 생성한다. 하지만 여러 개의 입력 뷰를 사용할 수 있으며, 그 중 일부만이 $I$와 크게 겹친다. 일반적으로 가장 관련성 있는 입력 뷰만이 뷰 간 집계에 유용하다.
저자들은 렌더링된 뷰 $I$와 가장 많이 겹치는 입력 뷰에서 두 개의 레퍼런스 뷰 \(\{I_1^r, I_2^r\}\)를 선택하는 뷰 선택 전략을 개발하였다. 구체적으로, 핀홀 카메라 모델을 기반으로 뷰 선택 문제를 공식화한다. 임의의 3D 장면은 bounding sphere로 대략 근사될 수 있으며, 카메라가 그 주위에 배치된다. 카메라에서 방출된 광선이 구에 부딪히면 교차점 집합이 생긴다.
$i$번째 카메라와 $j$번째 카메라에 대하여, 3D 점 집합을 \(\Phi_i = \{p_0^i, p_1^i, \cdots, p_{M_i}^i\}\)와 \(\Phi_j = \{p_0^j, p_1^j, \cdots, p_{M_j}^j\}\)라고 하자. 뷰 $i$의 $m_i$번째 교차점 \(p_{m_i}^i \in \Phi_i\)에 대해 L2 거리를 사용하여 뷰 $j$에서 가장 가까운 점을 검색한다.
\[\begin{equation} p_{m_i}^{i \rightarrow j} = \underset{p \in \Phi_j}{\arg \min} (\| p - p_{m_i}^i \|_2^2) \end{equation}\]그러면 $i$번째 뷰에서 $j$번째 뷰로의 매칭 비용은 다음과 같이 계산된다.
\[\begin{equation} C_{i \rightarrow j} = \sum_{m_i = 0}^{M_i} \| p_{m_i}^i - p_{m_i}^{i \rightarrow j} \|_2^2 \end{equation}\]최종적으로 뷰 $i$와 $j$ 사이의 상호 매칭 비용을 다음과 같이 얻는다.
\[\begin{equation} C_{i \leftrightarrow j} = C_{i \rightarrow j} + C_{j \rightarrow i} \end{equation}\]위 방법을 통해, NeRF에서 렌더링된 뷰 $I$를 향상시키기 위해 상호 매칭 비용이 가장 작은 두 개의 레퍼런스 뷰 \(\{I_1^r, I_2^r\}\)가 선택된다. 또한 학습 단계에서 LLFF-T 데이터에 대한 두 개의 레퍼런스 뷰를 결정하기 위해 이 전략을 채택한다.
Experiments
- 구현 디테일
- iteration: 300,000
- batch size: 16
- patch size: 128
- augmentation: random cropping, vertical/horizontal flipping, rotation
- optimizer: Adam
- learning rate: cosine annealing으로 $5 \times 10^{-4}$에서 0으로 감소
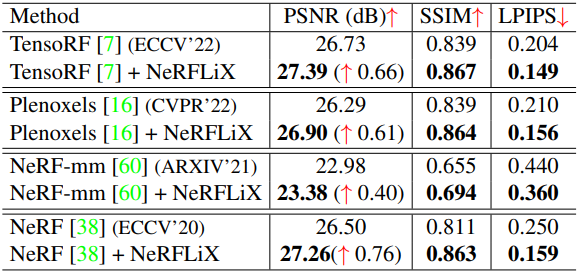
1. Improvement over SOTA NeRF Models
다음은 LLFF 데이터셋에서 NeRFLiX를 적용한 결과이다. (왼쪽: 1008$\times$756, 오른쪽: 504$\times$376)
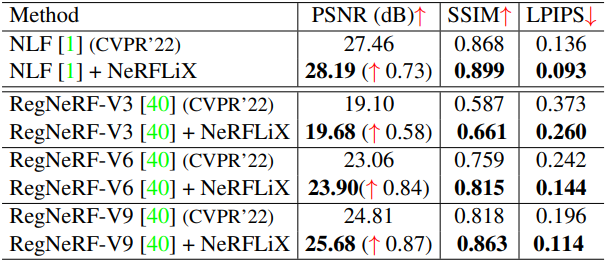
다음은 (왼쪽) Tanks and Temples와 (오른쪽) Noisy LLFF Synthetic에서 NeRFLiX를 적용한 결과이다.

다음은 LLFF, Tanks and Temples, Noisy LLFF Synthetic에서의 결과를 비교한 것이다.

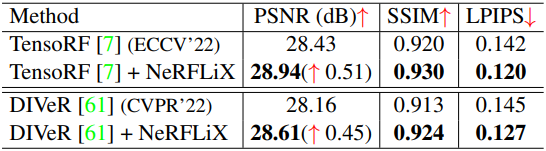
2. Training Acceleration for NeRF Models
다음은 LLFF (1008$\times$756)에서 절반의 iteration만 학습시킨 TensoRF와 Plenoxels에 NeRFLiX를 적용한 결과이다.

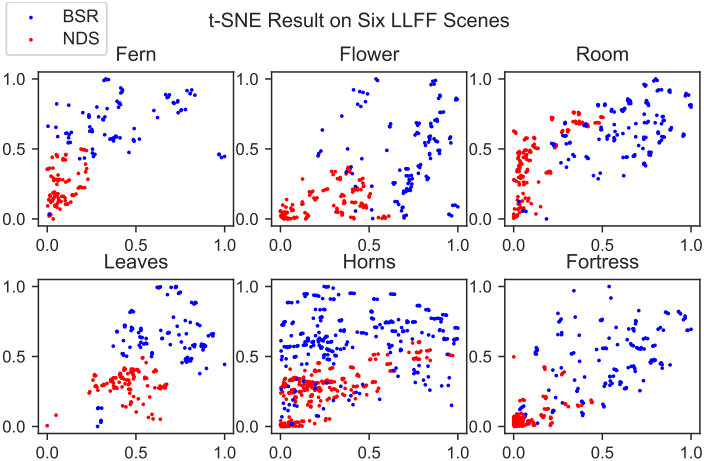
3. Ablation Study
다음은 6개의 LLFF 장면들에 대하여 NDS와 BSR을 정량적으로 비교한 결과이다.
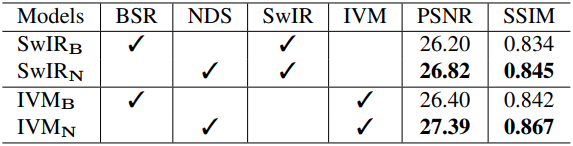
다음은 NDS에 사용된 degradation에 대한 ablation 결과이다.

다음은 뷰 선택 방법에 대한 ablation 결과이다. 그림에 있는 숫자는 계산된 매칭 비용이다.


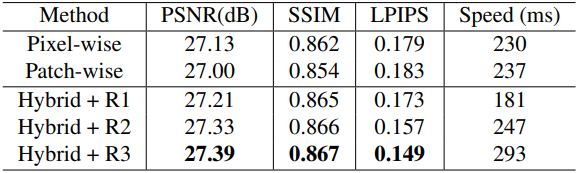
다음은 IVM에 대한 ablation 결과이다.
다음은 시뮬레이션 데이터셋으로 학습시킨 기존 이미지/동영상 처리 모델들을 사용하여 개선한 결과이다.
