[논문리뷰] NeRDi: Single-View NeRF Synthesis with Language-Guided Diffusion as General Image Priors
CVPR 2023. [Paper]
Congyue Deng, Chiyu “Max’’ Jiang, Charles R. Qi, Xinchen Yan, Yin Zhou, Leonidas Guibas, Dragomir Anguelov
Waymo | Stanford University | Google Research
6 Dec 2022
Introduction
새로운 view 합성은 컴퓨터 비전과 컴퓨터 그래픽 분야에서 오랫동안 존재해온 문제이다. NeRF와 같은 뉴럴 렌더링의 최근 발전은 새로운 view 합성 분야에서 큰 진전을 이루었다. 알려진 카메라 포즈가 포함된 multi-view 이미지 세트가 주어지면 NeRF는 정적 3D 장면을 신경망에 의해 parameterize된 radiance field로 표현하므로 학습된 네트워크를 통해 새로운 view에서 렌더링이 가능하다. 일련의 연구들은 보정된 카메라 포즈가 있는 조밀한 입력부터 잡음이 있거나 카메라 포즈가 없는 희박한 이미지에 이르기까지 NeRF 재구성에 필요한 입력을 줄이는 데 중점을 두고 있다.
그러나 단일 view에서의 NeRF 합성 문제는 2D 이미지에서 3D 장면까지의 일대일 대응이 존재하지 않기 때문에 잘못된 특성으로 인해 여전히 어려운 과제로 남아 있다. 대부분의 기존 연구에서는 이를 재구성 문제로 공식화하고 입력 이미지에서 NeRF 파라미터를 예측하도록 네트워크를 학습하여 문제를 해결한다. 그러나 supervision을 위해 보정된 카메라 포즈와 일치하는 multi-view 이미지가 필요하며 이는 인터넷의 이미지나 전문가가 아닌 사용자가 모바일 장치로 캡처한 이미지와 같은 많은 경우에 액세스할 수 없다. 최근 시도는 새로운 view의 adversarial loss와 self-consistency을 갖춘 unsupervised learning을 사용하여 이러한 제약을 완화하는 데 중점을 두었다. 그러나 학습 분포를 따라야 하는 테스트 사례가 여전히 필요하며, 이는 일반화 가능성을 제한한다. 합성 multi-view 데이터셋에서 학습한 prior를 집계하고 데이터 distillation를 사용하여 이를 실제 이미지로 전송하는 연구도 있다. 그러나 보지 못한 카테고리에 대한 일반화가 부족하여 세밀한 디테일이 누락되었다.
2D-to-3D 매핑은 컴퓨터의 어려움에도 불구하고 실제로 인간에게는 어려운 작업이 아니다. 인간은 일상의 관찰을 통해 3차원 세계에 대한 지식을 얻고, 사물이 어떻게 보여야 하고 보여서는 안 되는지에 대한 상식을 형성한다. 특정 이미지가 주어지면 사전 지식을 시각적 입력으로 빠르게 좁힐 수 있다. 이는 인간이 단일 view 3D 재구성과 같은 잘못된 인식 문제를 해결하는 데 능숙하도록 만든다.
본 논문은 이에 영감을 받아 대규모 diffusion 기반 2D 이미지 생성 모델을 활용하여 3D supervision 없이 단일 이미지 NeRF 합성 프레임워크를 제안한다. 입력 이미지가 주어지면 입력 이미지를 조건으로 diffusion model을 사용하여 임의 view 렌더링에 대한 이미지 분포 loss를 최소화하여 NeRF를 최적화한다. 제약되지 않은 이미지 diffusion은 포괄적이지만 모호한 ‘general prior’이다. 사전 지식을 좁히고 이를 입력 이미지와 연관시키기 위해 diffusion model에 대한 조건 입력으로 두 가지 semantic feature를 설계한다. 첫 번째 semantic feature는 전반적인 semantic을 전달하는 이미지 캡션이다. 두 번째는 textual inversion을 통해 입력 이미지에서 추출된 텍스트 임베딩으로, 추가 시각적 단서를 캡처한다. 언어 guidance의 이 두 semantic feature는 다양한 view 간의 의미론적 및 시각적 일관성을 통해 현실적인 NeRF 합성을 촉진한다. 또한 기본 3D 구조를 정규화하기 위해 입력 view의 추정 깊이를 기반으로 기하학적 loss를 도입한다. 모든 guidance와 제약 조건을 통해 학습된 모델은 general prior를 활용하고 단일 이미지 입력에 대해 zero-shot NeRF 합성을 수행할 수 있다.
Method
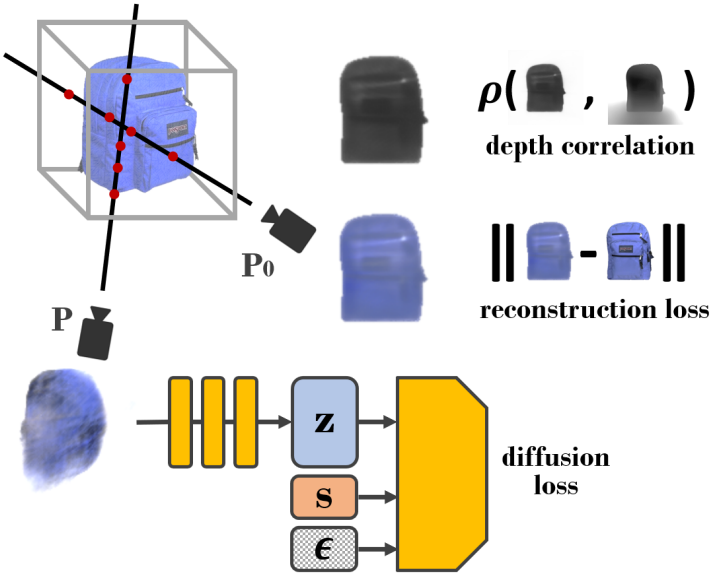
본 논문의 방법의 개요는 위 그림에 나와 있다. 입력 이미지 $x_0$가 주어지면 NeRF 표현 $F_\omega: (x, y, z) \mapsto (c, \sigma)$를 3D 재구성으로 학습하려고 한다. NeRF는 포즈가 $P$인 모든 카메라 view에 대해 카메라 광선 $r(t) = o + td$를 샘플링하고 다음과 같이 이 view에서 이미지 $x$를 렌더링할 수 있다는 렌더링 방정식을 가진다.
단순화를 위해 이 전체 렌더링 방정식을 $x = f(P, \omega)$로 표시한다. 이는 NeRF $f$가 파라미터 $\omega$를 사용하여 카메라 포즈 $P$에서 이미지 $x$를 렌더링한다는 것을 의미한다. Forward pass에서 $x_0$으로부터 NeRF 파라미터 $\omega$를 예측하는 대신 이를 조건부 3D 생성 문제로 공식화한다.
\[\begin{equation} f(\cdot, \omega) \sim \textrm{3D scene distribution} \; \vert \; f(P_0, \omega) = x_0 \end{equation}\]여기서 주어진 view $P_0$에서의 렌더링 $f(P_0, \omega)$가 입력 이미지 $x_0$이어야 한다는 조건으로 3D 장면 분포를 따르도록 NeRF를 최적화한다.
3D 장면 분포를 직접 학습하려면 대규모 3D 데이터셋이 필요하다. 이는 획득하기가 덜 간단하고 학습 중에 보지 못한 장면 카테고리에 대한 적용을 제한한다. 실제 시나리오에 대한 더 나은 일반화를 가능하게 하기 위해 대신 2D 이미지 prior를 활용하고 목적 함수를 다음과 같이 재구성한다.
\[\begin{equation} \forall P, \; f(P, \omega) \sim \mathcal{P} \; \vert \; f (P_0, \omega) = x_0 \end{equation}\]임의로 샘플링된 view에서 렌더링된 이미지 $f(P, \omega)$에 대해 최적화가 수행되어 $x_0 = f(P_0, \omega)$ 제약 조건을 충족하면서 이미지 prior $P$를 따르도록 한다. 전체 목적 함수는 조건부 확률을 최대화하는 것으로 작성할 수 있다.
\[\begin{equation} \max_\omega \mathbb{E}_P \mathbb{P} (f (P, \omega) \; \vert \; f(P_0, \omega) = x_0, s) \end{equation}\]여기서 $s$는 생성 컨텍스트에 맞게 이미지 prior 분포를 추가로 제한하기 위해 적용하는 추가적인 semantic guidance 항이다. 샘플링된 view에 대한 2D 이미지 prior로 언어 기반 이미지 diffusion model을 활용하는 DreamFusion과 달리, 본 논문은 생성된 3D 볼륨의 identity를 입력과 일치하도록 추가로 제한한다.
1. Novel View Distribution Loss
DDPM은 학습 데이터 샘플에 대한 분포를 학습하는 생성 모델 클래스이다. 최근에는 diffusion model을 이용한 언어 기반 이미지 합성 분야에서 많은 발전이 이루어졌다. 이미지 생성의 높은 품질과 효율성을 위해 Latent Diffusion Model (LDM)을 기반으로 방법을 구축한다. 이미지 $x$를 latent code $s$로 매핑하는 인코더 $\mathcal{E} (x) = z$와 이미지를 복구하는 디코더 $\mathcal{D} (\mathcal{E} (x)) = x$가 있는 사전 학습된 이미지 오토인코더를 채택한다. Diffusion process는 목적 함수를 최소화하여 latent space에서 학습된다.
\[\begin{equation} \mathbb{E}_{z \sim \mathcal{E} (x), s, \epsilon \sim \mathcal{N}(0,1), t} [\| \epsilon - \epsilon_\theta (z_t, t, c_\theta (s)) \|_2^2] \end{equation}\]여기서 $t$는 diffusion 시간이고, $\epsilon \sim \mathcal{N} (0, 1)$은 랜덤 noise 샘플이고, $z_t$는 시간 $t$까지 noise가 적용된 latent code $z$이고, $\epsilon_\theta$는 noise를 회귀하기 위한 파라미터 $\theta$가 있는 denoising network이다. 또한 diffusion model은 $c_\theta (s)$로 인코딩되고 denoising process의 guidance 역할을 하는 조건 입력 $s$를 사용한다. LDM과 같은 text-to-image 생성 모델의 경우 $c_\theta$는 조건부 텍스트 $s$를 인코딩하는 사전 학습된 대규모 언어 모델이다.
사전 학습된 diffusion model에서 네트워크 파라미터 $\theta$는 고정되어 있으며, 대신 $s$로 컨디셔닝된 이미지 분포 prior를 따르도록 $x$를 변환하는 동일한 목적 함수로 입력 이미지 $x$를 최적화할 수 있다. $x = f(P, \omega)$를 임의로 샘플링된 view $P$에서의 NeRF 렌더링이라고 가정하면, 기울기를 NeRF 파라미터 $\omega$에 역전파하여 $\omega$에 대한 stochastic gradient descent를 얻을 수 있다.
2. Semantics-Conditioned Image Priors
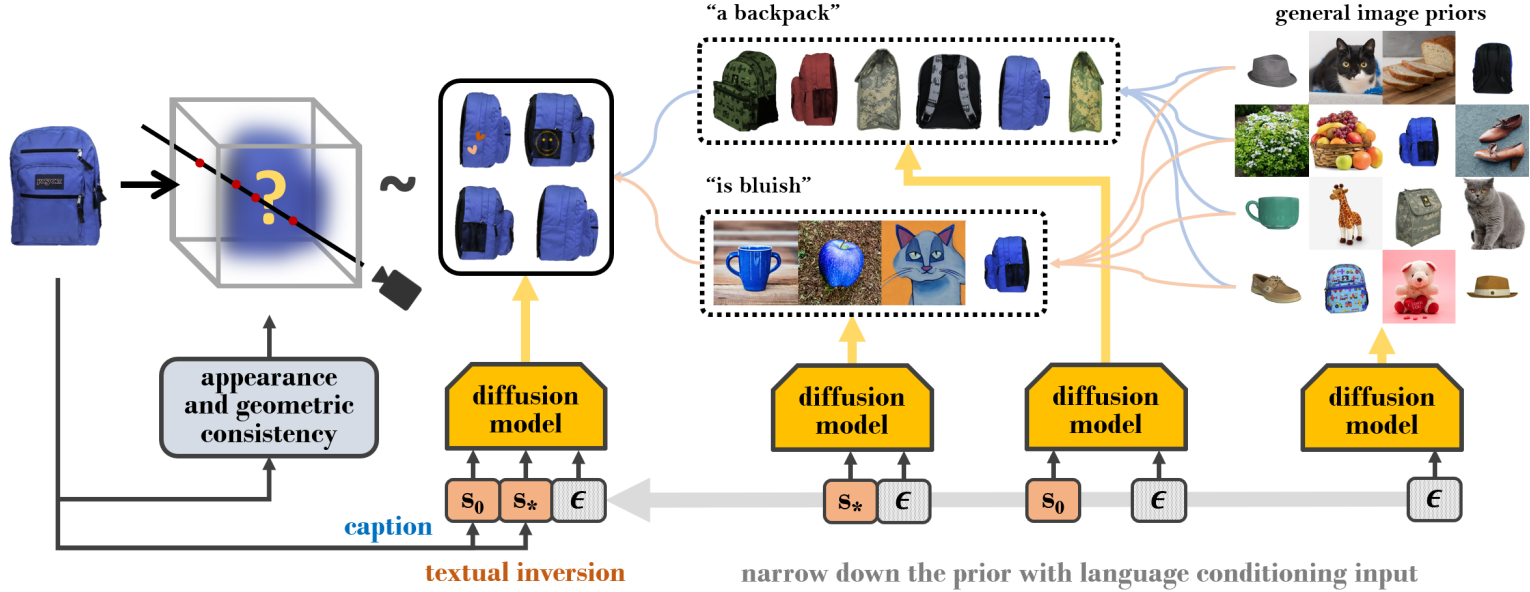
저자들은 모든 실제 이미지에 대한 prior 분포가 임의의 이미지로부터 새로운 view 합성을 가이드할 만큼 충분히 구체적이지 않다고 주장한다. 따라서 자연 이미지에 대한 일반적인 prior를 입력 이미지 $x_0$와 관련된 이미지의 prior로 좁히는 잘 설계된 guidance를 소개한다. 여기서는 임의의 입력 이미지를 설명하는 데 유연한 텍스트를 guidance로 선택한다. LDM과 같은 text-to-image diffusion model은 사전 학습된 대규모 언어 모델을 언어 인코더로 활용하여 언어에 따른 이미지에 대한 조건부 분포를 학습한다. 이는 공간 prior의 이미지를 제한하는 수단으로 언어를 활용하는 자연스러운 관문 역할을 한다.
입력 이미지에서 텍스트 프롬프트를 얻는 가장 간단한 방법은 (이미지, 텍스트) 데이터셋에 대해 학습된 이미지 캡션 또는 분류 네트워크 $S$를 사용하고 텍스트 $s_0 = S(x_0)$를 예측하는 것이다. 그러나 텍스트 설명은 이미지의 semantic을 요약할 수 있지만 모호함의 큰 공간을 남기므로 특히 프롬프트 길이가 제한된 경우 이미지에 모든 시각적 디테일을 포함하기가 어렵다.

위 그림 맨 위 행에서는 왼쪽 입력 이미지에서 “a collection of products”이라는 캡션으로 생성된 이미지를 보여준다. Semantic은 언어 설명과 관련하여 매우 정확하지만 생성된 이미지는 시각적 패턴의 분산이 매우 높고 입력 이미지와의 상관 관계가 낮다.
반면에 textual inversion은 텍스트 기반 이미지 diffusion model에서 하나 또는 몇 개의 이미지를 텍스트로 삽입하도록 최적화한다. LDM 식을 사용하면 다음과 같이 입력 이미지 $x_0$에 대한 텍스트 임베딩 $s_\ast$를 최적화할 수 있다.
\[\begin{equation} s_\ast = \underset{s}{\arg \min} \mathbb{E}_{z \sim \mathcal{E} (x_0), s, \epsilon \sim \mathcal{N} (0, 1), t} [\| \epsilon - \epsilon_\theta (z_t, t, c_\theta (s)) \|_2^2] \end{equation}\]위 그림의 중간 행에는 textual inversion으로 생성된 이미지가 표시된다. 입력 이미지의 색상과 시각적 단서가 잘 포착되었다 (주황색 요소, 음식, 브랜드 로고). 그러나 거시적 수준의 semantic은 때때로 잘못된 경우가 있 다 (두 번째 열은 스포츠를 하는 사람). 한 가지 이유는 textual inversion이 이러한 이미지의 공통 콘텐츠를 발견할 수 있는 다중 이미지 시나리오와 달리 하나의 단일 이미지에 대해 텍스트 임베딩이 초점을 맞춰야 하는 주요 feature가 무엇인지 명확하지 않기 때문이다.
새로운 view 합성 작업에서 입력 이미지의 semantic과 시각적 특성을 모두 반영하기 위해 텍스트 임베딩을 연결하여 공동 feature $s = [s_0, s_\ast]$를 형성함으로써 이 두 가지 방법을 결합하고 이를 diffusion process의 guidance로 사용한다. 위 그림의 맨 아래 줄은 균형 잡힌 semantic과 시각적 단서를 갖춘 이 공동 feature로 생성된 이미지를 보여준다.
3. Geometric Regularization
이미지 diffusion이 NeRF의 모양을 형성하지만 기본 3D 형상이 동일한 이미지 렌더링에서도 다를 수 있으므로 multi-view 일관성을 적용하기 어렵고 기울기 역전파를 제어할 수 없게 된다. 이 문제를 완화하기 위해 입력 view 깊이에 기하학적 정규화 항을 추가로 통합한다. Zero-shot 단안 깊이 추정을 위해 140만 개의 이미지에 대해 학습된 Dense Prediction Transformer (DPT) 모델을 채택하고 이를 입력 이미지 $x_0$에 적용하여 깊이 맵 $d_{0, \textrm{est}}$를 추정한다. 이 추정된 깊이를 사용하여 입력 view $P_0$에서 NeRF가 렌더링한 깊이를 정규화한다.
\[\begin{equation} \hat{d}_0 = \int_{t_n}^{t_f} \sigma (t) dt \end{equation}\]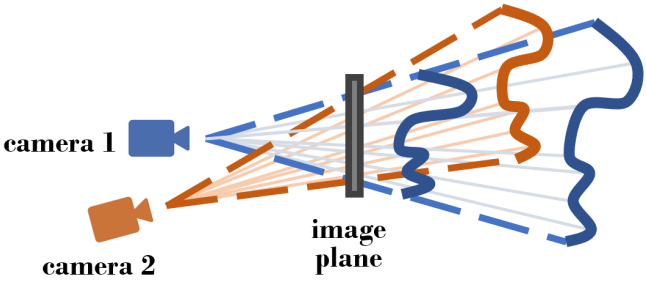
추정된 깊이 (scale, shift, camera intrinsic 포함)의 모호함과 추정 오차로 인해 (위 그림 참조) 깊이가 있는 픽셀을 3D로 다시 투영하고 정규화를 직접 계산할 수 없다. 대신, 렌더링된 깊이 분포와 잡음이 있는 추정 깊이 분포가 선형적으로 상관되어 있는지 측정하는 추정 깊이 맵과 NeRF 렌더링 깊이 간의 Pearson 상관 관계를 최대화한다.
Experiments
1. Synthetic Scenes
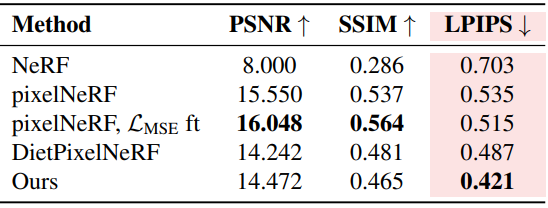
다음은 DTU 데이터셋에서의 단일 이미지 새로운 view 합성 결과이다.

2. Images in the Wild
다음은 Google Scanned Objects Dataset의 객체에 대한 새로운 view 합성 결과를 비교한 것이다.

다음은 한 단어 또는 짧은 문구 캡션이 포함된 인터넷의 객체 중심 이미지에 대한 결과이다.
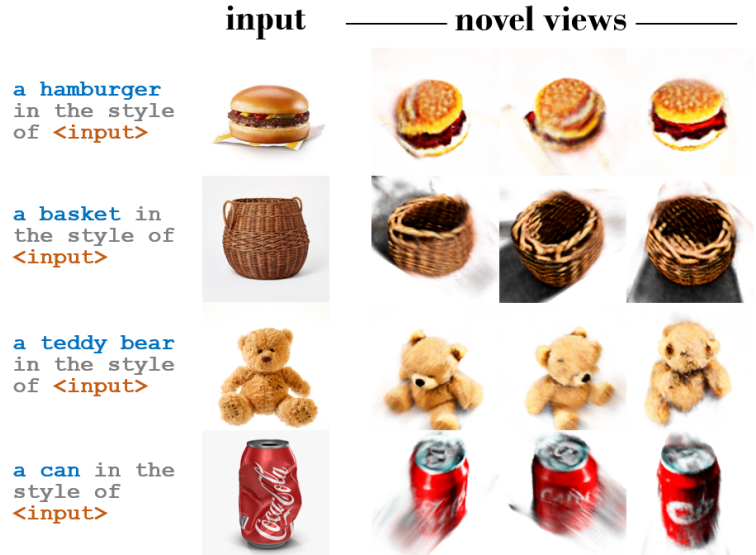
다음은 COCO 데이터셋에 대한 결과이다.

3. Ablation Studies
다음은 두 텍스트 임베딩, 이미지 캡션에서 얻은 $s_0$와 textual inversion에서 얻은 $s_\ast$에 대한 ablation 결과이다.

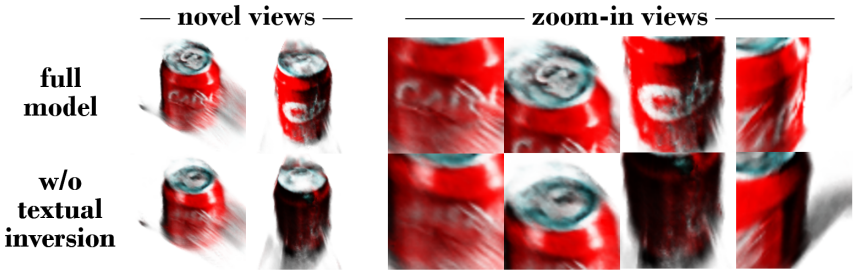
다음은 전체 모델 결과와 textual inversion이 없는 결과를 확대하여 비교한 것이다.

다음은 textual inversion 없는 모델 간의 또 다른 비교이다.
다음은 기하학적 정규화에 대한 ablation 결과이다.

Limitations

본 논문의 방법은 사전 학습된 여러 개의 대규모 이미지 모델에 의존하기 때문에 이러한 모델의 모든 편향은 합성 결과에 영향을 미친다. 위 그림은 텍스트 프롬프트가 “a single shoe”인 경우에도 LDM이 두 개의 신발을 생성할 수 있는 예를 보여 주며, 그 결과 여러 신발의 특징을 보여주는 합성 NeRF가 생성된다.

본 논문의 방법은 언어 guidance가 semantic과 스타일에 초점을 맞추지만 물리적 상태와 역학에 대한 전체적인 설명이 부족하기 때문에 변형 가능성이 높은 인스턴스에 대해서는 덜 강력하다. 위 그림은 이러한 실패 사례를 보여준다. 각 독립 view의 렌더링은 시각적으로 그럴듯하지만 동일한 인스턴스의 다양한 상태를 나타낸다.