[논문리뷰] Neural Directional Encoding for Efficient and Accurate View-Dependent Appearance Modeling
CVPR 2024. [Paper] [Page] [Github]
Liwen Wu, Sai Bi, Zexiang Xu, Fujun Luan, Kai Zhang, Iliyan Georgiev, Kalyan Sunkavalli, Ravi Ramamoorthi
UC San Diego | Adobe Research
23 May 2024
Introduction
새로운 뷰 합성을 위해 사진에서 반사 효과를 충실하게 재현하려면 형상과 뷰에 따른 외형을 모두 캡처해야 한다. 최근 NeRF는 학습 가능한 spatial feature grid를 사용하여 효율적인 형상 표현 및 인코딩에 있어 인상적인 진전을 이루었다. 그러나 디테일한 뷰에 따른 외형을 모델링하는 것은 훨씬 덜 주목을 받았다. 방향 정보의 효율적인 인코딩은 specular highlight나 상호반사(interreflection)과 같은 모델링 효과에도 마찬가지로 중요하다. 본 논문에서는 광택이 있는 물체의 모양을 정확하게 모델링할 수 있는 feature grid와 비슷한 neural directional encoding (NDE)을 제시하였다.
NeRF의 뷰에 따른 색상은 일반적으로 spatial feature와 인코딩된 방향을 디코딩하여 얻는다. 이 접근 방식에는 대규모 MLP가 필요하며 analytical directional encoding function으로 인해 수렴이 느리다. 저자들은 feature grid 기반 인코딩을 directional 도메인으로 가져와 글로벌 환경 맵에 저장된 학습 가능한 feature 벡터를 통해 먼 소스로부터의 반사를 나타낸다. Feature들은 신호 학습을 localize하여 디테일한 원거리 반사를 모델링하는 데 필요한 MLP 크기를 줄인다.
원거리 반사 외에도 공간적으로 다양한 근거리 상호반사도 광택이 있는 물체를 렌더링하는 데 중요한 효과이다. 위치에 의존하지 않는 NeRF의 spatio-angular parameterization으로는 이러한 효과를 정확하게 모델링할 수 없다. 대조적으로, NDE는 근거리 반사를 인코딩하기 위해 spatial feature grid를 tracing함으로써 새로운 spatio-spatial parameterization을 제안하였다. Cone tracing은 쿼리된 방향과 위치를 따라 spatial encoding을 축적하므로 공간적으로 다양하다. 이전 연구들에서는 한 번의 반사 또는 diffuse interreflection만 고려했지만, NDE는 일반적인 여러 번의 반사 효과를 모델링할 수 있다.
전반적으로 NDE는 뷰에 따른 효과의 고품질 모델링과 빠른 평가를 모두 달성하였다. NDE는 SOTA 모델들이 어려움을 겪는 반사 물체의 정확한 렌더링과 품질 손실 없는 실시간의 높은 추론 속도를 보여준다.
Preliminaries
저자들은 diffuse 성분과 specular 성분이 있는 불투명한 물체를 가정하고 SDF $s (\mathbf{x})$와 color field $\mathbf{c} (\mathbf{x}, \boldsymbol{\omega})$를 사용하여 장면을 나타내는 표면 기반 모델을 사용하였다. SDF는 경계의 부드러움을 제어하는 학습 가능한 파라미터 $\beta$를 사용하여 VolSDF를 따라 NeRF의 density field $\sigma$로 변환된다.
\[\begin{equation} \sigma (\mathbf{x}) = \begin{cases} \frac{1}{2 \beta} \exp \bigg( \frac{s (\mathbf{x})}{\beta} \bigg) & \; \textrm{if } s(\mathbf{x}) \le 0, \\ \frac{1}{\beta} \bigg( 1 - \frac{1}{2} \exp \bigg( - \frac{s (\mathbf{x})}{\beta} \bigg) \bigg) & \; \textrm{otherwise} \end{cases} \end{equation}\]따라서 원점 $\mathbf{x}$와 방향이 $\boldsymbol{\omega}$인 광선의 색상 \(\mathbf{C} (\mathbf{x}, \boldsymbol{\omega})\)는 다음과 같이 볼륨 렌더링될 수 있다.
\[\begin{equation} \mathbf{C} (\mathbf{x}, \boldsymbol{\omega}) = \sum_i w (\sigma (\mathbf{x}_i)) \mathbf{c} (\mathbf{x}_i, \boldsymbol{\omega}) \\ \textrm{where} \quad w (\sigma (\mathbf{x}_i)) = (1 - \exp (- \sigma (\mathbf{x}_i) \delta_i)) \prod_{j < i} \exp (- \sigma (\mathbf{x}_j) \delta_j), \quad \delta_i = \| \mathbf{x}_i - \mathbf{x}_{i-1} \|_2 \end{equation}\]\(\mathbf{x}_i\)는 광선을 따라 샘플링된 $i$번째 샘플 포인트를 나타낸다. Ref-NeRF와 마찬가지로 색상 $\mathbf{c}$를 diffuse color cd, specular tint \(\mathbf{k}_s\), 반사 방향 \(\boldsymbol{\omega}_r\)에서 쿼리된 specular color \(\mathbf{c}_s\)로 분해하고 SDF 기울기에 의해 주어진 surface normal $\mathbf{n}$을 사용한다.
\[\begin{equation} \mathbf{c} (\mathbf{x}, \boldsymbol{\omega}) = \mathbf{c}_d (\mathbf{x}) + \mathbf{k}_s (\mathbf{x}) \mathbf{c}_s (\mathbf{x}, \boldsymbol{\omega}_r) \\ \textrm{where} \quad \boldsymbol{\omega}_r = \textrm{reflect} (\boldsymbol{\omega}, \mathbf{n}), \quad \mathbf{n} = \textrm{normalize} (\nabla_{\mathbf{x}} s (\mathbf{x})) \end{equation}\]여기서 specular color \(\mathbf{c}_s\)는 spatial feature $\mathbf{f} (\mathbf{x})$, 표면 거칠기 $\rho$에 의해 제어되는 directional encoding $\mathbf{H}$, 코사인 항 $\mathbf{n} \cdot \boldsymbol{\omega}$를 조건으로 하는 MLP에서 디코딩된다.
\[\begin{equation} \mathbf{c}_s (\mathbf{x}, \boldsymbol{\omega}_r) = \textrm{MLP} (\mathbf{f} (\mathbf{x}), \mathbf{H} (\mathbf{x}, \boldsymbol{\omega}_r, \rho (\mathbf{x})), \mathbf{n} \cdot \boldsymbol{\omega}) \end{equation}\]\(\mathbf{c}_d\), \(\mathbf{k}_s\), $\mathbf{f}$, $\rho$는 모두 spatial MLP에서 나온다.
Discussion. 이전 연구들에서는 \(\boldsymbol{\omega}_r\)과 $\rho$에만 의존하는 $\mathbf{H}$에 대한 analytical function을 사용했는데, 여기에는 몇 가지 제한 사항이 있다.
- 인코딩 함수는 학습 가능하지 않다.
- 공간 컨텍스트는 $\mathbf{f} (\mathbf{x})$에서만 나온다.
둘 다 디코더 MLP가 specular color의 spatio-angular 디테일에 맞게 커야 하므로 비용이 많이 들고 느릴 수 있다.
Neural directional encoding
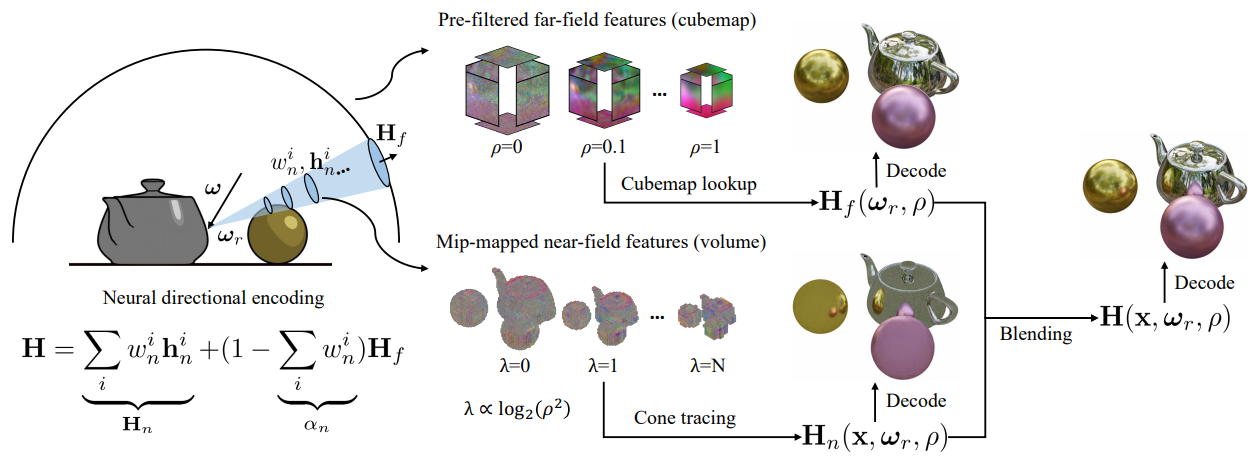
MLP 복잡도를 최소화하기 위해 공간 위치에 따라 달라지는 학습 가능한 neural directional encoding (NDE)을 사용한다. 특히, NDE는 원거리 반사를 위한 큐브맵 feature grid \(\mathbf{h}_f\)와 근거리 상호반사를 모델링하는 공간 볼륨 \(\mathbf{h}_n\)으로 다양한 유형의 반사를 인코딩한다. 위 그림에서 볼 수 있듯이 반사 광선을 따라 누적된 \(\mathbf{h}_n\)을 먼저 cone tracing하여 근거리 feature \(\mathbf{H}_n\)을 산출하고 \(\mathbf{h}_f\)에서 쿼리된 원거리 feature \(\mathbf{H}_f\)를 동일한 방향으로 혼합하여 $\mathbf{H}$를 계산한다.
여기서 $\alpha_n$은 cone tracing 불투명도이고 두 feature 모두 mip level을 결정하는 $\rho$로 mip-mapping된다.
1. Far-field features
Feature grid 기반 표현들은 로컬 신호의 제어를 위해 feature 벡터를 voxel에 저장하여 학습 속도를 높인다. 마찬가지로 이상적인 정반사를 인코딩하기 위해 글로벌 큐브맵의 모든 픽셀에 feature 벡터 \(\mathbf{h}_f\)를 배치한다. 큐브맵은 split-sum 스타일의 거친 표면 아래의 반사를 모델링하기 위해 사전 필터링된다. 여기서 $k$번째 레벨의 mip-map \(\mathbf{h}_f^k\)는 거칠기 $\rho_k$가 $[0,1]$에 균일하게 배치된 GGX 커널 $D$를 사용하여 다운샘플링된 \(\mathbf{h}_f\)를 convolution하여 생성된다.
\[\begin{equation} \mathbf{h}_f^k = \textrm{convolution} (\textrm{downsample} (\mathbf{h}_f, k), D(\rho_k)) \end{equation}\]표면 거칠기가 주어지면 반사 방향에서 큐브맵 lookup을 수행하고 mip level 사이를 보간하여 원거리 feature를 얻는다.
\[\begin{equation} \mathbf{H}_f (\boldsymbol{\omega}_r, \rho) = \textrm{lerp} \bigg( \mathbf{h}_f^k (\boldsymbol{\omega}_r), \mathbf{h}_f^{k+1} (\boldsymbol{\omega}_r), \frac{\rho - \rho_k}{\rho_{k+1} - \rho_k} \bigg) \end{equation}\]여기서 $\textrm{lerp}(\cdot)$은 linear interpolation이고 $\rho \in [\rho_k, \rho_{k+1}]$이다.

큐브맵 기반 인코딩을 사용하면 feature 벡터를 조정하여 서로 다른 방향의 신호를 독립적으로 최적화할 수 있다. 이는 MLP 파라미터를 글로벌하게 해결하는 것보다 최적화하기가 더 쉽기 때문에 각도 도메인에서 디테일을 모델링하는 데 더 적합하다. Coarse level의 feature는 fine level의 일관되게 필터링된 버전으로, 각 mip level에서 독립적인 feature 벡터를 사용하는 것보다 더 잘 제한된다.
2. Near-field features
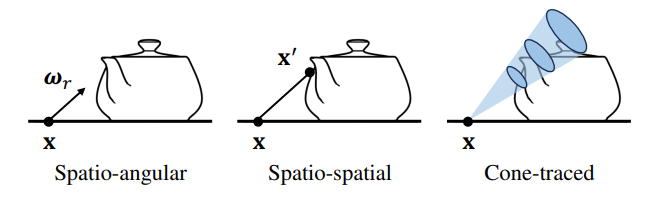
Spatial feature와 angular feature로 specular color를 parameterization하는 것은 원거리 반사에 충분하지만 근거리 상호반사에 대한 표현력이 부족하다. 서로 다른 지점이 동일한 \(\mathbf{h}_f\)를 쿼리하므로 공간적으로 다양한 성분이 최적화 중에 평균화될 수 있다. 저자들의 통찰력은 spatio-angular 반사가 현재 위치와 다음 반사되는 위치의 spatio-spatial 함수로 parameterization될 수도 있다는 것이다. 따라서 MLP는 $\mathbf{f}(\mathbf{x})$를 사용하여 두 번째 반사되는 위치의 spatial feature을 디코딩할 수 있다.
거친 반사의 경우 cone tracing을 통해 reflection lobe 아래의 평균 feature를 집계한다. 이 볼륨은 반사된 광선 \(\mathbf{x} + \boldsymbol{\omega}_r t\)를 따라 mip-mapping된 density $\sigma_n$을 사용하여 mip-mapping된 spatial feature \(\mathbf{h}_n\)을 렌더링한다. 이 때 샘플 포인트 \(\mathbf{x}_i^\prime\)은 원뿔 \(r_i = \sqrt{3} \rho^2 \vert \mathbf{x} - \mathbf{x}_i^\prime \vert\)에 의해 결정되며 mip level은 $\lambda_i = \log_2 (2r_i)$이다.
\[\begin{equation} \mathbf{H}_n (\mathbf{x}, \boldsymbol{\omega}_r, \rho) = \sum_i w_n^i \mathbf{h}_n^i \\ \textrm{where} \quad w_n^i = w (\sigma_n (\mathbf{x}_i^\prime, \lambda_i)), \quad \mathbf{h}_n^i = \mathbf{h}_n (\mathbf{x}_i^\prime, \lambda_i) \end{equation}\]원뿔은 $\mathbf{x}$에서 GGX lobe를 덮도록 선택된다. SDF로 변환된 $\sigma$는 mip-mapping이 불가능하기 때문에 사용하지 않는다. 대신에 $\sigma$를 일치시키기 위해 간접 feature \(\mathbf{h}_n\)와 별도의 $\sigma_n$을 최적화한다. 둘 다 tri-plane \(\mathbf{T}_n\)에서 디코딩되며, 각 2D 평면은 Tri-MipRF와 유사하게 mip-mapping된다.
\[\begin{equation} \sigma_n (\mathbf{x}_i^\prime, \lambda_i), \mathbf{h}_n (\mathbf{x}_i^\prime, \lambda_i) = \textrm{MLP} (\textrm{mipmap} (\mathbf{T}_n (\mathbf{x}_i^\prime), \lambda_i)) \end{equation}\]
간접 광선은 공간적으로 다양하므로 근거리 feature도 공간적으로 다양하다. 이는 상호반사 학습을 위한 angular-only feature에 비해 이점이 있으며 위 그림에서 볼 수 있듯이 overfitting될 가능성이 적다. 이는 학습 시 서로 다른 광선에서 동일한 \(\mathbf{h}_n\)이 추적되어 기본 표현이 잘 제한되기 때문이다. \(\mathbf{H}_n\)과 \(\mathbf{H}_f\)는 일반적인 볼륨 렌더링에서 전경색과 배경색과 유사하므로 불투명도 $\alpha_n$을 사용하여 둘을 자연스럽게 합성할 수 있다.
3. Optimization
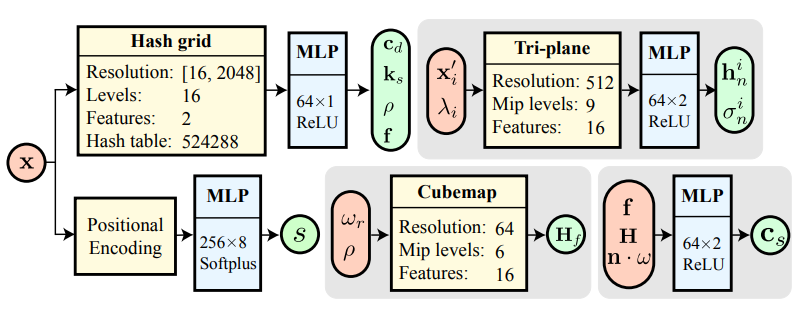
반사 물체를 모델링하려면 안정적인 형상 최적화가 필수적이므로 VolSDF의 positional encoding된 MLP를 사용하여 SDF를 출력한다. 계산 비용을 줄이기 위해 hash grid를 사용하여 다른 spatial feature (\(\mathbf{c}_d\), \(\mathbf{k}_s\), $\rho$, $\mathbf{f}$)를 인코딩한다. 실제 픽셀 색상 \(\mathbf{C}_\textrm{gt}\)와 tone-mapping function $\Gamma$로 매핑된 렌더링 $\mathbf{C}$ 간의 Charbonnier loss를 통해 최적화된다.
Occupancy-grid sampling. \(\mathbf{C} (\mathbf{x}, \boldsymbol{\omega})\)와 \(\mathbf{H}_n (\mathbf{x}, \boldsymbol{\omega}, \rho)\)는 빈 공간에서의 계산을 없애기 위해 NerfAcc의 occupancy-grid estimator에 의해 가속된다. 이는 각 광선 샘플에 대해 반사 광선을 tracing하기 때문에 효율적인 근거리 feature 평가에 특히 중요하다. 광선 렌더링은 0.005의 고정된 ray marching step을 사용한다. $\max(0.5r_i, 0.005)$에 비례하는 cone tracing step을 선택하고 올바른 occupancy 정보에 대해 mip-mapping된 occupancy grid를 쿼리한다.
Regularization. 광선 위의 샘플 \(\mathbf{x}_i\)가 주어지면 Eikonal loss \(L_\textrm{eik}\)이 SDF를 정규화하기 위해 적용되며, mip level 0에서 $\sigma_n$을 사용하는 렌더링이 GT에 가까워지도록 장려하여 $\sigma_n$을 암시적으로 정규화하여 $\sigma$와 일치하도록 한다.
\[\begin{equation} L_\sigma = \sum_{\mathbf{x}, \boldsymbol{\omega}} \| \mathbf{C}_\sigma (\mathbf{x}, \boldsymbol{\omega}) - \mathbf{C}_\textrm{gt} (\mathbf{x}, \boldsymbol{\omega}) \|_2^2 \\ \textrm{where} \quad \mathbf{C}_\sigma (\mathbf{x}, \boldsymbol{\omega}) = \sum_i w (\sigma_n (\mathbf{x}_i, 0)) \textrm{sg} (\mathbf{c} (\mathbf{x}_i, \boldsymbol{\omega})) \end{equation}\]여기서 $\textrm{sg}(\cdot)$는 stop-gradient이며, $\sigma_n$이 외형에 영향을 주지 못하도록 한다. 전체 loss는 $L + 0.1 L_\textrm{eik} + 0.01 L_\sigma$이다.
Experiments
- 구현 디테일
- optimizer: Adam
- step: 40만 / learning rate: 0.0005 / dynamic batch size
- $\beta$: 안정된 수렴을 위해 BakedSDF의 scheduler을 사용
- NVIDIA 3090 GPU 1개에서 15GB의 메모리로 10~18시간 소요
실제 장면의 경우 좌표 수축이 포함된 별도의 Instant-NGP를 사용하여 배경을 렌더링한다. NeRO와 유사하게, 데이터셋을 촬영한 사람에 대한 반사는 \(\mathbf{H}_f\)와 capturer plane feature \(\mathbf{h}_c\)를 불투명도 $\alpha_c$로 혼합하여 인코딩된다.
\[\begin{equation} \mathbf{H} = \mathbf{H}_n + (1 - \alpha_n) (\alpha_c \mathbf{h}_c + (1 - \alpha_c) \mathbf{H}_f) \\ \textrm{where} \quad \alpha_c, \mathbf{h}_c = \textrm{MLP} (\textrm{mipmap} (\mathbf{T}_c (\mathbf{u}), \lambda_c)) \end{equation}\]\(\mathbf{T}_c\)는 mip-mapping된 2D feature grid이며, $\mathbf{u}$는 광선과 평면의 교차 좌표이고 $\lambda_c$는 교차 공간에서 파생된 mip level이다. 전경 및 배경 네트워크를 공동으로 최적화하는 것은 불안정할 수 있으므로 NeRO의 stabilization loss를 적용하고, 처음 20만 step에 대하여 \(\mathbf{h}_f\), \(\mathbf{h}_n\), \(\mathbf{h}_c\)가 먼저 샘플링되어 색상으로 디코딩된 다음 색상을 혼합하여 specular color \(\mathbf{c}_s\)를 계산하도록 수정한다. Feature와 디코딩을 혼합하는 것에 비해 디코딩 후 혼합 전략이 더 나은 기하학적 최적화를 제공한다.
1. View synthesis
Results
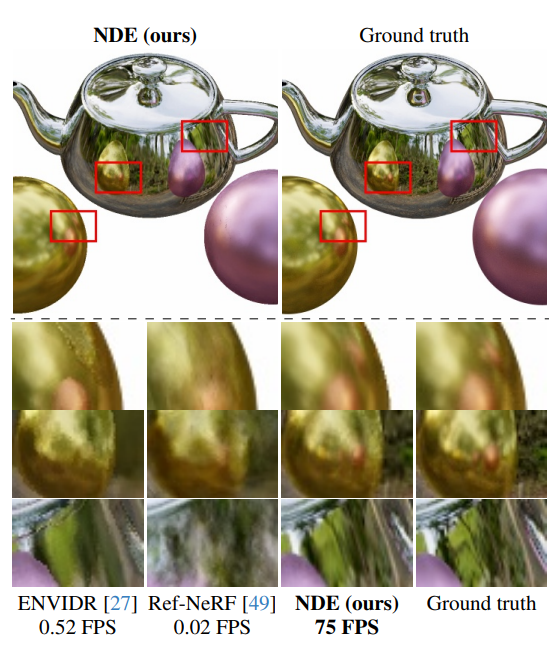
다음은 합성 장면들에 대한 비교 결과들이다.
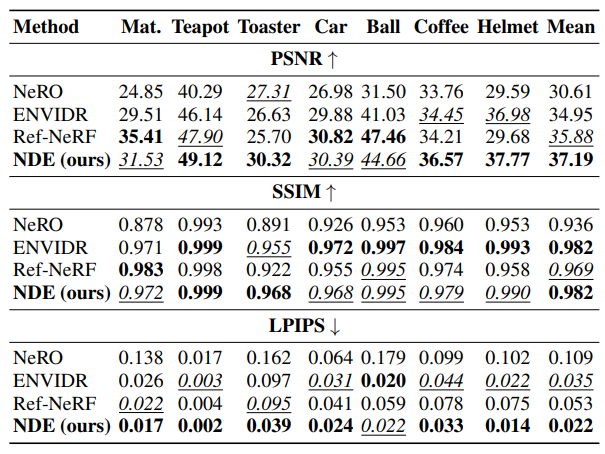

다음은 실제 장면들에 대한 비교 결과이다.

Editability
다음은 반사를 원거리와 근거리로 분리한 예시이다.
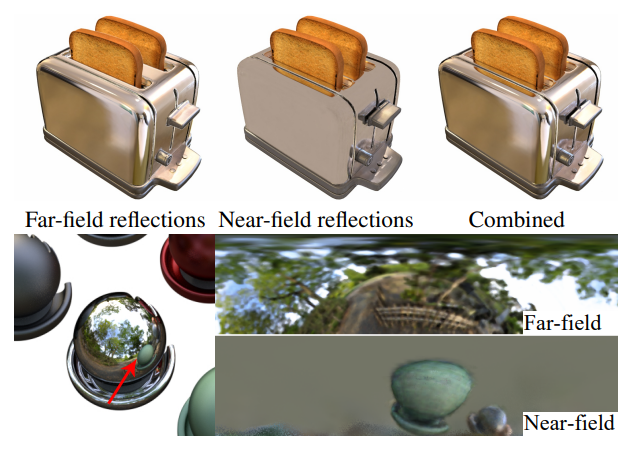
다음은 NDE의 편집 가능성을 보여주는 예시이다. 삭제된 구의 반사는 간접 feature들의 볼륨을 삭제하여 제거할 수 있다.

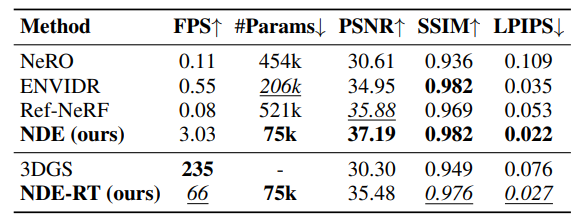
2. Performance comparison
다음은 성능을 비교한 표이다. NDE-RT는 marching cube를 통해 SDF를 메쉬로 변환하고 \(\textbf{c}_d\), \(\textbf{k}_s\), $\rho$, $\textbf{f}$를 메쉬 정점으로 베이킹한 NDE의 실시간 버전이다.
다음은 NDE와 NDE-RT의 error map을 비교한 것이다. NDE-RT는 물체 경계 근처에 오차가 발생하며, 이는 삼각형 메쉬의 marching cube 추출과 후속 rasterization으로 인해 발생한다. 이 오차는 상당한 질적 차이로 이어지지 않는다.

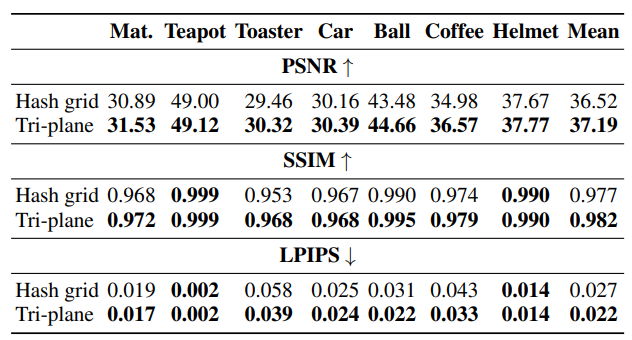
3. Ablation study
다음은 directional encoding에 대한 ablation 결과이다.


다음은 네트워크 아키텍처에 대한 ablation 결과이다.

다음은 mip-mapping 전략에 대한 ablation 결과이다.
4. Limitations
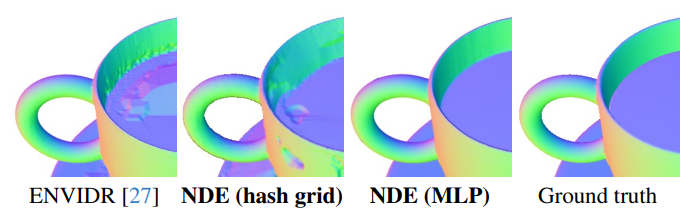
이전 방법들과 마찬가지로 NDE는 surface normal의 품질에 민감하다. 이는 손상된 형상을 생성하는 경향이 있는 hash grid와 같은 보다 효율적인 표현을 사용하기 어렵게 한다. 결과적으로 positional encoding된 MLP를 사용하여 SDF를 모델링하므로 학습 시간이 길고 투명한 객체를 모델링하기가 어렵다. 또한, NDE의 편집 가능성은 제한적이다.