[논문리뷰] Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
NeurIPS 2023. [Paper]
Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim Alabdulmohsin, Avital Oliver, Piotr Padlewski, Alexey Gritsenko, Mario Lučić, Neil Houlsby
Google DeepMind
12 Jul 2023
Introduction
Vision Transformer (ViT)는 단순하고 유연하며 확장 가능한 특성으로 인해 convolution 기반 신경망을 대체하였다. ViT는 이미지를 패치로 분할하고, 각 패치는 토큰에 선형적으로 projection된다. 일반적으로 입력 이미지는 고정된 정사각형 종횡비로 resize된 다음 고정된 수의 패치로 분할된다.
최근 연구에서는 이 패러다임에 대한 대안을 모색했다. FlexiViT는 각 학습 step에서 패치 크기를 무작위로 샘플링하고 초기 convolution 임베딩이 여러 패치 크기를 지원할 수 있도록 하였다. Pix2Struct는 종횡비를 보존하는 alternative patching 접근 방식을 도입했다.
본 논문은 NaViT를 제시하였다. 다양한 이미지의 여러 패치가 단일 시퀀스로 패킹된다. 이를 Patch n’ Pack이라고 하며, 종횡비를 유지하면서 가변 해상도를 가능하게 한다. 이는 NLP의 example packing에서 영감을 받은 것으로, 가변 길이 입력에 대한 효율적인 학습을 위해 여러 예제가 단일 시퀀스로 패킹된다. 저자들은 다음과 같은 사실을 보여주었다.
- 학습 시에 해상도를 무작위로 샘플링하면 학습 비용이 크게 줄어든다.
- NaViT는 광범위한 해상도에서 고성능을 제공하여 inference 시에 비용 대비 성능의 원활한 균형을 이룰 수 있으며, 새로운 task에 적은 비용으로 적용할 수 있다.
- 고정된 batch 모양은 종횡비를 보존한 해상도 샘플링, 가변 token dropping 비율, 적응형 계산과 같은 새로운 아이디어로 이어진다.
고정된 계산 예산에서 NaViT는 지속적으로 ViT보다 우수한 성능을 보인다. 예를 들어, 4배 적은 계산으로 최고 성능의 ViT의 성능과 맞먹는다. 저자들은 계산 예산 내에서 처리되는 학습 예제의 수가 상당히 증가한 것을 ViT에 비해 성능이 향상된 주요 요인으로 파악하였다. 가변 해상도 입력, 가변 token dropping과 결합된 example packing을 통해 NaViT-L/16은 학습 중에 5배 더 많은 이미지를 처리할 수 있다. 이러한 향상된 효율성은 fine-tuning 프로세스로 확장된다. 또한 사전 학습과 fine-tuning 중에 NaViT를 여러 해상도에 노출시킴으로써 모델은 다양한 해상도에서 평가할 때 뛰어난 성능을 보여 inference 비용 측면에서 NaViT에 상당한 이점을 제공한다.
Method
신경망은 일반적으로 batch로 학습되고 실행된다. 현재 하드웨어에서 효율적인 처리를 위해 고정된 batch 모양을 사용하며, 고정된 이미지 크기를 의미한다. 이는 역사적으로 CNN과 관련된 구조적 한계와 결합하여 이미지 크기를 고정된 크기로 조정하거나 패딩하는 관행으로 이어졌으며, 두 가지 모두 결함이 있다. 전자는 성능에 해를 끼치고 후자는 비효율적이다. 또한 이미지 데이터셋은 일반적으로 종횡비가 정사각형이 아니다.
언어 모델링에서 고정된 시퀀스 길이의 제한을 example packing을 통해 우회하는 것이 일반적이다. 여러 개의 개별 예제에서 토큰을 하나의 시퀀스로 결합하여 언어 모델의 학습을 상당히 가속화할 수 있다. 이미지를 패치 (토큰) 시퀀스로 처리하여 ViT가 동일한 이점을 얻을 수 있다. 이 기술을 사용하면 ViT가 “네이티브” 해상도의 이미지에서 학습될 수 있으며, 이 접근 방식을 NaViT라고 한다.
1. Architectural changes
NaViT는 원래 ViT를 기반으로 구축되었지만, 원칙적으로 패치 시퀀스에서 작동하는 모든 ViT 변형을 사용할 수 있다. Patch n’ Pack을 활성화하기 위해 다음과 같이 아키텍처를 수정한다.
Masked self attention and masked pooling.

예제가 서로 attention되는 것을 방지하기 위해 추가적인 self attention 마스크가 도입된다. 마찬가지로 인코더 위의 mask pooling은 각 예제 내의 토큰 표현을 pooling하여 시퀀스에서 예제별로 하나의 벡터 표현을 생성하는 것을 목표로 한다.
Factorized & fractional positional embeddings
임의의 해상도와 종횡비를 처리하기 위해 위치 임베딩을 수정한다. 해상도 $R \times R$의 정사각형 이미지가 주어지면 패치 크기 $P$의 ViT는 길이가 $(R/P)^2$인 1차원 위치 임베딩을 학습한다. 더 높은 해상도 $R$에서 학습하거나 평가하기 위해서는 이러한 임베딩을 interpolation해야 한다.
가변적인 종횡비를 지원하고 처음 보는 해상도로 쉽게 extrapolate하기 위해 factorized positional embedding을 도입한다. 여기서는 $x$ 좌표와 $y$ 좌표에 해당하는 개별 임베딩 $\phi_x$와 $\phi_y$로 분해한다. 그런 다음 두 임베딩을 더한다.
저자들은 두 가지 방식을 고려하였다.
- Absolute embedding $\phi (p) : [0, \textrm{maxLen}] \rightarrow \mathbb{R}^D$: 패치 인덱스의 함수
- Fractional embedding $\phi (r) : [0, 1] \rightarrow \mathbb{R}^D$: 상대적인 거리 $r = p/\textrm{side-length}$의 함수
후자는 이미지 크기와 무관한 위치 임베딩을 제공하지만 원래 종횡비를 부분적으로 난독화하여 패치의 수에서만 암시적으로 나타난다. 저자들은 단순히 학습된 임베딩, sinusoidal 임베딩, NeRF에서 사용하는 학습된 푸리에 위치 임베딩을 고려하였다.
2. Training changes
Continuous Token dropping
Token dropping (학습 중 입력 패치의 무작위 생략)은 학습을 가속화하기 위해 개발되었다. 그러나 일반적으로 모든 예제에서 동일한 비율의 토큰이 드롭되지만, 패킹은 token dropping을 연속적으로 수행할 수 있게 하며, token dropping 비율을 이미지별로 다르게 할 수 있다. 이를 통해 완전한 이미지를 여전히 보면서 dropping을 수행하여 학습/inference 불일치를 줄이고 빠른 처리량의 이점을 얻을 수 있다. 또한 패킹을 사용하면 dropping 비율을 미리 정의된 schedule에 따라 학습하는 동안 지속적으로 변경할 수 있다.
Resolution sampling
NaViT는 각 이미지의 원래 해상도를 사용하여 학습할 수 있다. 또는 종횡비를 유지하면서 총 픽셀 수를 다시 샘플링할 수 있다. ViT에서는 더 큰 처리량과 더 큰 성능 사이에 trade-off가 있다. 종종 모델은 더 작은 해상도에서 사전 학습되고 더 높은 해상도에서 fine-tuning된다.
NaViT는 훨씬 더 유연하다. 각 이미지의 원래 종횡비를 유지하면서 이미지 크기를 샘플링하여 혼합 해상도 학습이 가능하다. 이를 통해 더 높은 처리량과 큰 이미지에 대한 노출이 모두 가능하여 동등한 ViT에 비해 상당히 향상된 성능을 제공한다.
3. Efficiency of NaViT
Self attention 비용

Attention의 $O(n^2)$ 비용은 여러 이미지를 더 긴 시퀀스로 패킹할 때 자연스럽게 발생하는 문제이다. NaViT에서는 transformer의 hidden 차원이 스케일링됨에 따라 attention이 전체 비용에서 차지하는 비중이 점점 작아지고, MLP의 계산 비용도 함께 줄어든다.
위 그래프는 이러한 추세를 보여주며, 패킹과 관련된 오버헤드가 모델 차원에 따라 감소한다. 속도 외에도 self-attention의 메모리 비용은 매우 긴 시퀀스에 문제가 될 수 있지만, 여러 메모리 효율적인 방법을 사용하여 해결할 수도 있다.
Packing & sequence-level padding
여러 예제를 포함하는 최종 시퀀스 길이는 고정되어야 하며, greedy packing 방식을 사용한다. 일반적으로 고정 길이에 정확히 합산되는 예제의 완벽한 조합은 없으며 패딩 토큰을 사용해야 한다. 시퀀스 마지막 예제의 해상도 또는 token dropping 비율을 동적으로 선택하여 길이를 정확히 맞출 수 있지만, 일반적으로 토큰의 2% 미만이 패딩 토큰이기 때문에 간단한 접근 방식으로 충분하다.
Padding examples & contrastive loss
Per-token loss는 패킹된 시퀀스로 구현하기 쉽다. 그러나 많은 컴퓨터 비전 모델은 pooling된 표현에 적용되는 예제 수준의 loss로 학습된다. 이를 위해서는 두 가지 수정이 필요하다.
- 패킹을 설명하기 위해 일반적인 pooling head를 수정해야 한다.
- 각 시퀀스에서 여러 pooling된 표현을 추출해야 한다. $B$개의 시퀀스의 batch에서 시퀀스당 최대 $E_\textrm{max}$개의 예제, 즉 최대 $B \times E_\textrm{max}$개의 pooling된 표현을 추출한다는 가정이 필요하다.
시퀀스에 $E_\textrm{max}$보다 많은 이미지가 포함된 경우 추가 이미지가 삭제되어 모델의 인코더 계산이 낭비된다. 시퀀스에 $E_\textrm{max}$보다 적은 예제가 있는 경우 loss는 많은 가짜 패딩 표현을 처리한다.
후자는 contrastive learning에서 문제로, loss 계산이 시간과 메모리 측면에서 $O(n^2)$로 확장된다. 이를 피하기 위해 저자들은 chunked contrastive loss를 사용했으며, 이는 softmax를 위해 모든 데이터 포인트를 모을 필요 없이 로컬 디바이스들에서 계산을 수행하고 글로벌 softmax 정규화를 위한 통계를 효율적으로 누적하여 문제를 해결한다. 이를 통해 높은 $E_\textrm{max}$ 값을 사용할 수 있어 모델 인코더를 효율적으로 사용할 수 있으며, loss로 인해 병목 현상이 발생하지 않는다.
Experiments
저자들은 두 가지 셋업으로 NaViT를 사전 학습시켰다.
- JFT-4B에서 classification training
- WebLI에서 contrastive language-image training (CLIP)
1. Improved training efficiency and performance
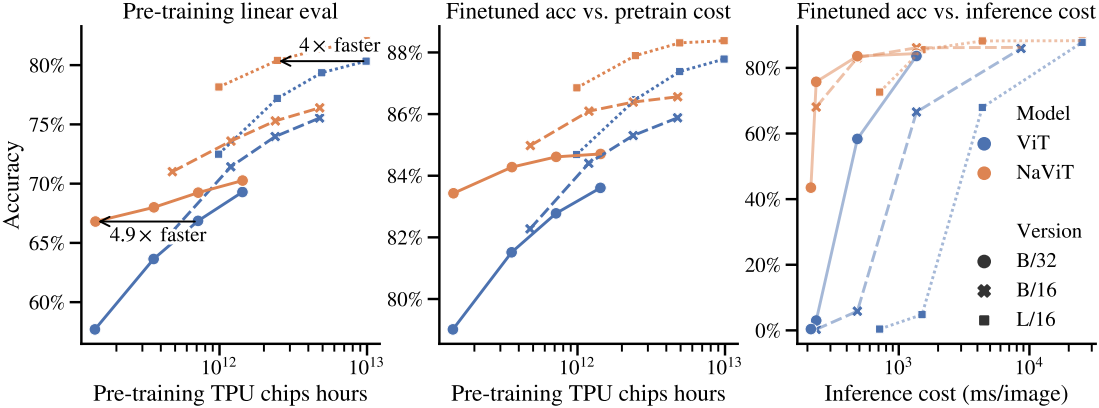
다음은 다양한 NaViT 모델의 JFT 사전 학습 성능을 계산량이 비슷한 ViT와 비교한 그래프이다.
2. Benefits of variable resolution
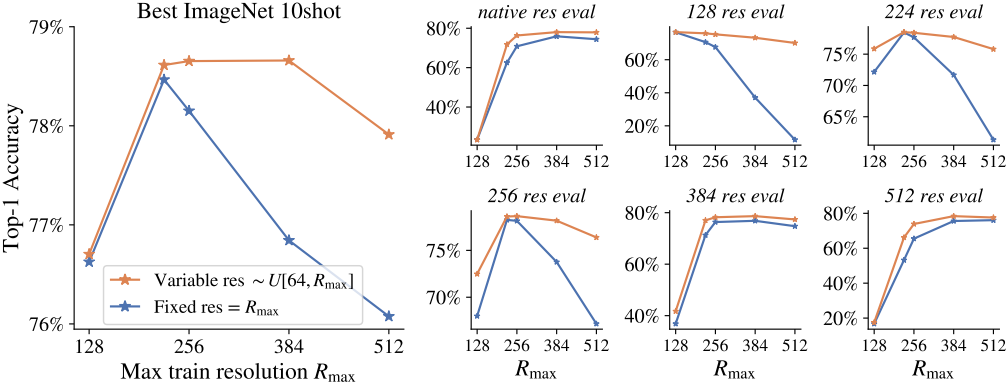
다음은 고정 및 가변 해상도 학습에 따른 모델의 성능을 비교한 그래프이다.
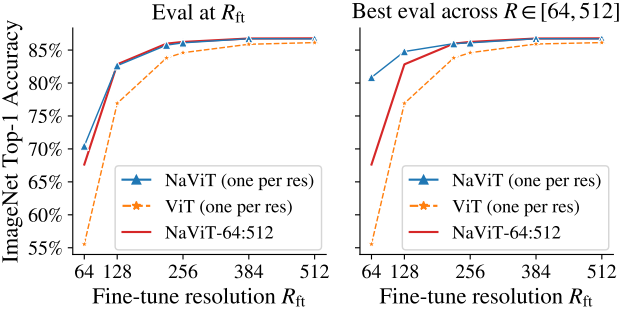
다음은 가변 해상도 fine-tuning에 따른 성능을 비교한 그래프이다.
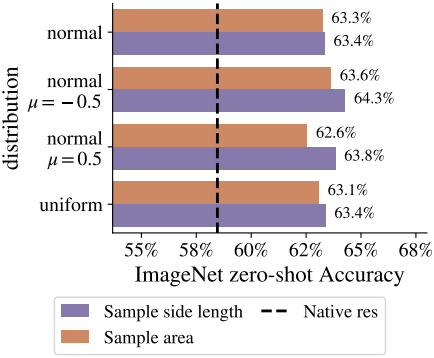
다음은 해상도 샘플링 전략에 따른 성능을 비교한 그래프이다.
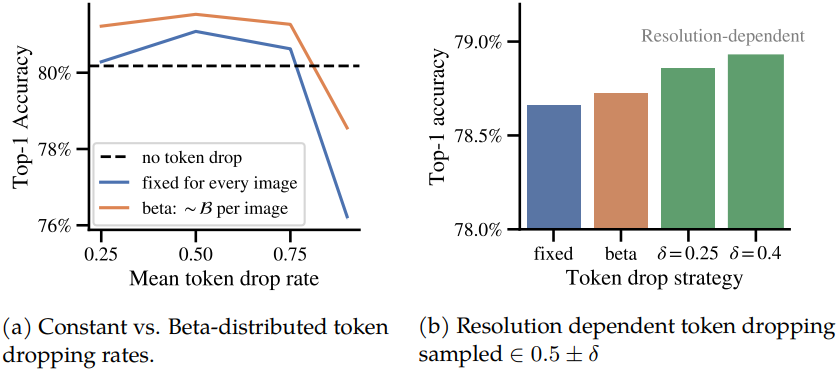
3. Benefits of variable token dropping
다음은 token dropping 전략에 따른 성능을 비교한 그래프이다.
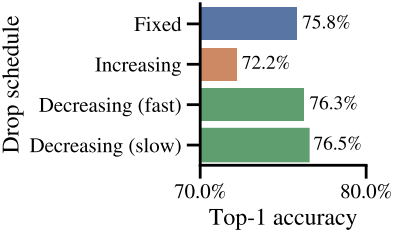
다음은 token dropping schedule에 따른 성능을 비교한 그래프이다.
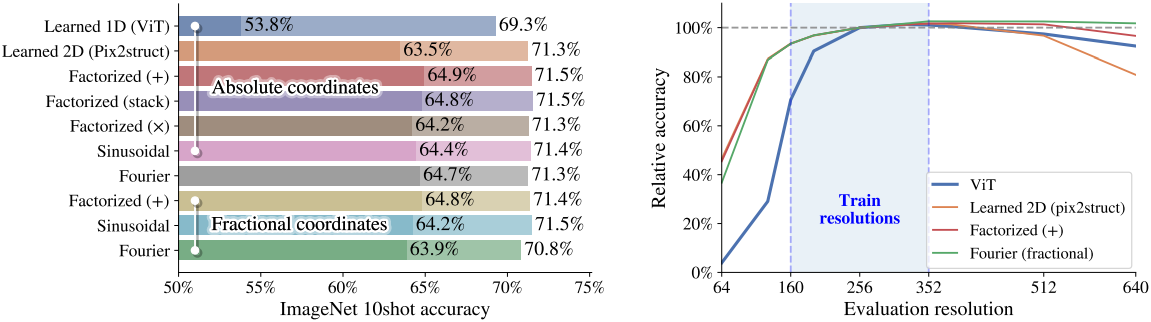
4. Positional embeddings
다음은 position embedding에 따른 성능을 비교한 그래프이다.
5. Other aspects of NaViT’s performance
다음은 out of distribution에 대한 평가 결과이다.
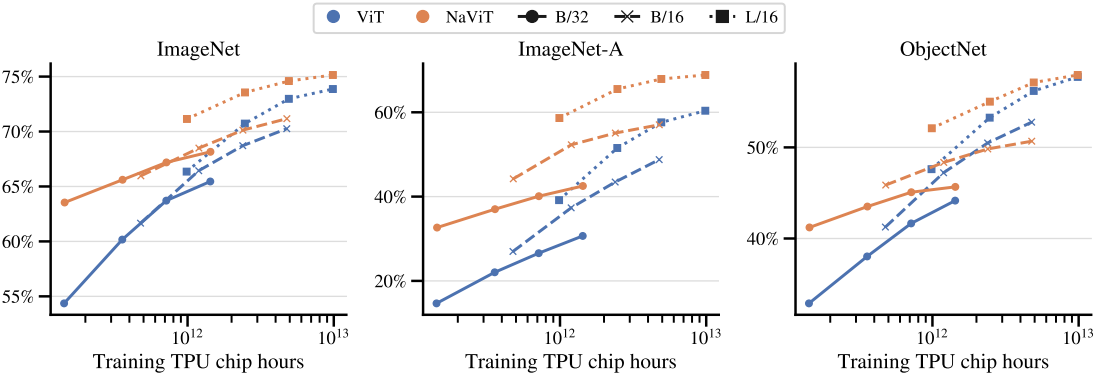
6. Other downstream tasks
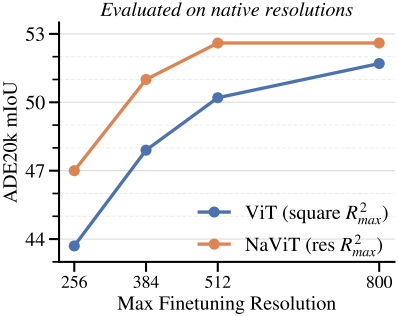
다음은 semantic segmentation 성능을 ViT와 비교한 그래프이다.
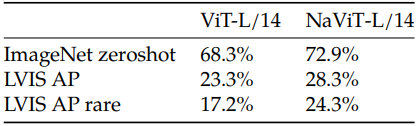
다음은 object detection 성능을 ViT와 비교한 표이다.