[논문리뷰] MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
CVPR 2022. [Paper] [Github]
Yanghao Li, Chao-Yuan Wu, Haoqi Fan, Karttikeya Mangalam, Bo Xiong, Jitendra Malik, Christoph Feichtenhofer
Facebook AI Research | UC Berkeley
2 Dec 2021
Introduction
다양한 시각적 인식 task를 위한 아키텍처를 설계하는 것은 역사적으로 어려웠으며 가장 널리 채택된 아키텍처는 단순성과 효율성을 결합한 아키텍처였다 (ex. VGGNet, ResNet). 최근 ViT는 유망한 성능을 보여 CNN과 경쟁하고 있으며 최근 다양한 비전 task에 적용하기 위한 다양한 수정이 제안되었다.
ViT는 이미지 분류 분야에서 널리 사용되지만 고해상도 object detection과 시공간 동영상 이해 task에 사용하는 것은 여전히 어려운 일이다. 시각적 신호의 밀도는 Transformer 기반 모델의 self-attention 블록 내에서 복잡도가 2차적으로 확장되므로 컴퓨팅 및 메모리 요구 사항에 심각한 문제를 야기한다. 비전 커뮤니티는 다양한 전략을 사용하여 이러한 부담에 접근했다. 두 가지 인기 있는 전략은 object detection을 위한 window 내의 로컬 attention 계산과 동영상 task에서 self-attention을 계산하기 전에 로컬로 feature를 집계하는 pooling attention이다.
후자는 ViT를 간단한 방식으로 확장하는 아키텍처인 MViT를 촉진하였다. 즉, 네트워크 전체에 고정된 해상도를 갖는 대신 고해상도에서 저해상도까지 여러 단계로 구성된 feature 계층 구조를 갖는다. MViT는 SOTA 성능을 갖춘 동영상 task를 위해 설계되었다.
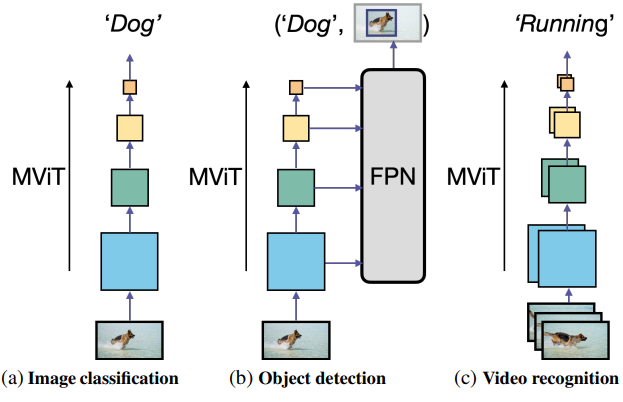
본 논문에서는 성능을 더욱 향상시키기 위해 두 가지 간단한 기술 개선 사항을 개발하고 MViT가 공간 및 시공간 인식 task를 위한 일반적인 비전 backbone 역할을 할 수 있는지 이해하기 위해 이미지 분류, object detection, 동영상 분류의 3가지 task에 걸쳐 시각적 인식을 위한 단일 모델 제품군으로 MViT를 연구하였다. 저자들의 경험적 연구는 향상된 아키텍처인 MViTv2로 이어졌다.
저자들은 두 축을 따라 pooling attention을 향상시키는 강력한 기준선을 만들었다. 하나는 분해된 위치 거리를 사용하여 Transformer 블록에 위치 정보를 주입하는 이동 불변 위치 임베딩이고, 다른 하나는 attention 계산에서 pooling stride의 효과를 보상하기 위한 residual pooling connection이다. 간단하면서도 효과적인 업그레이드로 훨씬 더 나은 결과를 얻을 수 있다.
MViT의 향상된 구조를 사용하여 Feature Pyramid Network (FPN)가 포함된 Mask R-CNN이라는 표준 dense prediction 프레임워크를 사용하고 이를 object detection과 instance segmentation에 적용한다.
저자들은 MViT가 관련된 계산 및 메모리 비용을 극복하기 위해 pooling attention을 사용하여 고해상도 시각적 입력을 처리할 수 있는지 연구하였다. 저자들의 실험은 pooling attention이 local-window attention 메커니즘 (ex. Swin)보다 더 효과적이라는 것을 시사한다. 저자들은 더 나은 정확도/계산 trade-off를 위해 pooling attention을 보완할 수 있는 간단하면서도 효과적인 Hybrid window attention 체계를 추가로 개발하였다.
저자들은 복잡도가 증가하는 5가지 크기 (너비, 깊이, 해상도)로 아키텍처를 인스턴스화하고 대규모 멀티스케일 transformer에 대한 실용적인 학습 방법을 제시하였다. MViT 변형은 일반적인 비전 아키텍처로서의 목적을 연구하기 위해 최소한의 수정으로 이미지 분류, object detection, 동영상 분류에 적용된다.
Revisiting Multiscale Vision Transformers
MViTv1의 핵심 아이디어는 ViT의 단일 스케일 블록 대신 낮은 수준과 높은 수준의 시각적 모델링을 위한 서로 다른 stage를 구성하는 것이다. MViT는 네트워크의 입력 stage에서 출력 stage까지 해상도 $L$ (즉, 시퀀스 길이)을 줄이는 동시에 채널 폭 $D$를 천천히 확장한다.
Transformer 블록 내에서 다운샘플링을 수행하기 위해 MViT는 pooling attention을 도입하였다. 구체적으로, 입력 시퀀스 $X \in \mathbb{R}^{L \times D}$의 경우 linear projection $W_Q, W_K, W_V \in \mathbb{R}^{D \times D}$를 적용한 다음 pooling 연산자 $\mathcal{P}$를 각각 query, key, value 텐서에 적용한다.
\[\begin{equation} Q = \mathcal{P}_Q (XW_Q), \quad K = \mathcal{P}_K (XW_K), \quad V = \mathcal{P}_V (XW_V) \end{equation}\]여기서 $Q \in \mathbb{R}^{\tilde{L} \times D}$의 길이 $\tilde{L}$은 \(\mathcal{P}_Q\)에 의해 감소될 수 있고 $K$와 $V$의 길이는 \(\mathcal{P}_K\)와 \(\mathcal{P}_V\)에 의해 감소될 수 있다.
이어서, pooling된 self-attention은 유연한 길이 $\tilde{L}$을 사용하여 출력 시퀀스 $Z \in \mathbb{R}^{\tilde{L} \times D}$를 계산한다.
\[\begin{equation} Z := \textrm{Attn} (Q, K, V) = \textrm{Softmax}(\frac{QK^\top}{\sqrt{D}}) V \end{equation}\]Key와 value 텐서에 대한 \(\mathcal{P}_K\)와 \(\mathcal{P}_V\)의 downsampling factor는 \(\mathcal{P}_Q\)에 적용되는 factor와 다를 수 있다.
Pooling attention을 사용하면 query 텐서 $Q$를 pooling하여 MViT의 여러 stage 간 해상도를 줄일 수 있으며, key $K$와 value $V$ 텐서를 pooling하여 컴퓨팅 및 메모리 복잡도를 크게 줄일 수 있다.
Improved Multiscale Vision Transformers
1. Improved Pooling Attention
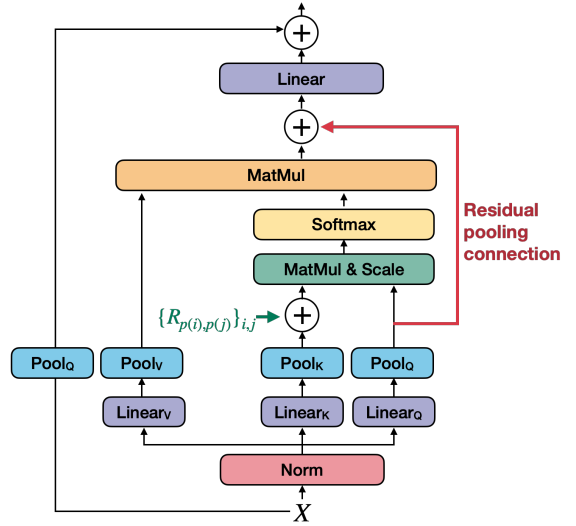
Decomposed relative position embedding
MViT는 토큰 간의 상호 작용을 모델링하는 능력을 보여주었지만 구조보다는 콘텐츠에 중점을 둔다. 시공간 구조 모델링은 위치 정보를 제공하기 위해 절대 위치 임베딩에만 의존한다. 이는 비전의 이동 불변성 (shift-invariance)의 기본 원리를 무시한다. 즉, MViT가 두 패치 간의 상호 작용을 모델링하는 방식은 상대 위치가 변경되지 않더라도 이미지의 절대 위치에 따라 변경된다. 이 문제를 해결하기 위해 pooling된 self-attention 계산에 토큰 사이의 상대적 위치 거리에만 의존하는 상대적 위치 임베딩을 통합한다.
두 입력 요소 $i$와 $j$ 사이의 상대 위치를 위치 임베딩 $R_{p(i),p(j)} \in \mathbb{R}^d$로 인코딩한다. 여기서 $p(i)$와 $p(j)$는 요소 $i$와 $j$의 공간(또는 시공간) 위치를 나타낸다. 그런 다음 쌍별 인코딩 표현이 self-attention 모듈에 내장된다.
\[\begin{equation} \textrm{Attn} (Q, K, V) = \textrm{Softmax} (\frac{QK^\top + E^\textrm{(rel)}}{\sqrt{d}}) V \\ \textrm{where} \quad E_\textrm{ij}^\textrm{(rel)} = Q_i \cdot R_{p(i),p(j)} \end{equation}\]그러나 가능한 임베딩 $R_{p(i),p(j)}$의 수는 $\mathcal{O}(TWH)$로 확장되므로 계산 비용이 많이 들 수 있다. 복잡도를 줄이기 위해 시공간 축을 따라 요소 $i$와 $j$ 사이의 거리 계산을 분해한다.
\[\begin{equation} R_{p(i), p(j)} = R_{h(i), h(j)}^\textrm{h} + R_{w(i), w(j)}^\textrm{w} + R_{t(i), t(j)}^\textrm{t} \end{equation}\]여기서 $R^\textrm{h}$, $R^\textrm{w}$, $R^\textrm{t}$는 높이, 너비, 시간 축을 따른 위치 임베딩이고, $h(i)$, $w(i)$, $t(i)$는 각각 토큰 $i$의 수직, 수평, 시간 위치를 나타낸다. $R^\textrm{t}$는 선택 사항이며 동영상에서 시간적 차원을 지원하는 데만 필요하다. 분해된 임베딩은 학습된 임베딩 수를 $\mathcal{O}(T + W + H)$로 줄여 초기 stage의 고해상도 feature map에 큰 영향을 미칠 수 있다.
Residual pooling connection
Attention pooling은 attention block의 계산 복잡도와 메모리 요구 사항을 줄이는 데 매우 효과적이다. MViTv1은 $Q$ 텐서의 stride보다 $K$와 $V$ 텐서에서 더 큰 stride를 가지며 출력 시퀀스의 해상도가 stage에 걸쳐 변경되는 경우에만 다운샘플링된다. 이는 정보 흐름을 증가시키고 MViT에서 pooling attention block 학습을 용이하게 하기 위해 pooling된 $Q$에 residual pooling connection을 추가하도록 동기를 부여한다.
구체적으로 pooling된 query 텐서를 출력 시퀀스 $Z$에 추가한다. 따라서 출력 시퀀스 $Z$는 다음과 같이 계산할 수 있다.
\[\begin{equation} Z := \textrm{Attn} (Q, K, V) + Q \end{equation}\]출력 시퀀스 $Z$는 pooling된 query 텐서 $Q$와 길이가 동일하다.
2. MViT for Object Detection
FPN integration
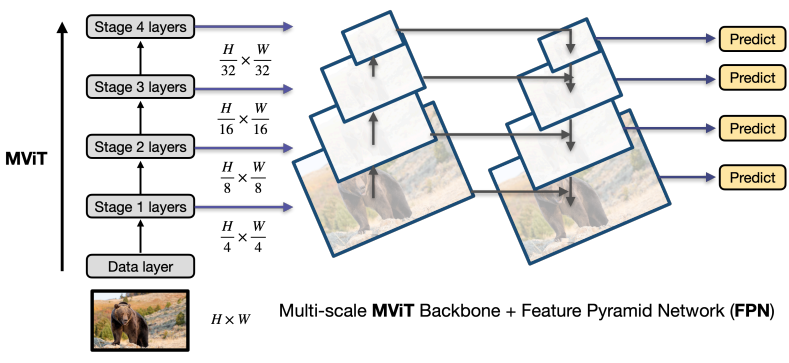
MViT의 계층적 구조는 4 stage로 멀티스케일 feature map을 생성하므로 위 그림과 같이 object detection을 위해 Feature Pyramid Network (FPN)에 자연스럽게 통합된다. FPN에서 측면 연결이 있는 하향식 피라미드는 모든 스케일에서 의미론적으로 강력한 feature map를 구성한다. MViT backbone과 함께 FPN을 사용하여 이를 다양한 detection 아키텍처 (ex. Mask R-CNN)에 적용한다.
Hybrid window attention
Transformers의 self-attention은 토큰의 수에 대하여 2차 복잡도를 갖는다. 이 문제는 일반적으로 고해상도 입력과 feature map이 필요하기 때문에 object detection의 경우 더욱 악화된다. 본 논문에서는 이러한 컴퓨팅 및 메모리 복잡성을 크게 줄이는 두 가지 방법을 연구하였다.
- MViT의 attention block에 설계된 pooling attention
- Swin에서 object detection을 위한 계산을 줄이기 위한 기술로 사용된 window Attention
Pooling attention과 window attention은 모두 self-attention을 계산할 때 query, key, value 텐서의 크기를 줄여 self-attention의 복잡도를 제어한다. 그러나 본질적인 성격은 다르다. Pooling attention은 로컬 집계를 통해 feature을 다운샘플링하여 글로벌한 self-attention 계산을 유지하는 반면, window attention은 텐서의 해상도를 유지하지만 입력(패치된 토큰)을 겹치지 않는 창으로 나누고 window 내에서 로컬로 self-attention을 수행한다. 두 접근 방식의 본질적인 차이점은 object detection에서 상호 보완적인 작업을 수행할 수 있는지 연구하도록 동기를 부여하였다.
기본 window attention은 window 내에서 로컬 self-attention만 수행하므로 window 간 연결이 부족하다. 본 논문은 이 문제를 완화하기 위해 shifted window를 사용하는 Swin과 달리 window 간 연결을 추가하는 간단한 Hybrid window attention (Hwin) 디자인을 제안한다. Hwin은 FPN에 공급되는 마지막 세 stage의 마지막 블록을 제외한 모든 window 내에서 로컬 attention을 계산한다. 이러한 방식으로 FPN에 매핑된 입력 feature에는 글로벌 정보가 포함된다.
Positional embeddings in detection
입력이 고정 해상도(ex. 224$\times$224)인 ImageNet 분류와 달리 object detection은 일반적으로 학습에서 다양한 크기의 입력을 포함한다. MViT의 위치 임베딩 (절대 또는 상대)의 경우 먼저 입력 크기가 224$\times$224인 위치 임베딩에 해당하는 ImageNet 사전 학습 가중치에서 파라미터를 초기화한 다음 object detection 학습을 위하여 해당 크기로 보간한다.
3. MViT for Video Recognition
MViT는 업그레이드된 모듈이 시공간 영역을 일반화하므로 MViTv1과 유사한 동영상 인식 task (ex. Kinetics 데이터셋)에 쉽게 채택될 수 있다. MViTv1은 Kinetics의 처음부터 학습 설정에만 초점을 맞추고 있지만, 본 논문에서는 ImageNet 데이터셋에서의 사전 학습의 효과도 연구하였다.
Initialization from pre-trained MViT
이미지 기반 MViT와 비교할 때 동영상 기반 MViT에는 세 가지 차이점만 있다.
- Patchification stem의 projection layer는 입력을 2D 패치 대신 시공간 큐브에 project해야 한다.
- Pooling 연산자는 시공간 feature map을 풀링한다.
- 상대 위치 임베딩은 시공간 위치를 참조한다.
Projection layer와 pooling 연산자는 기본적으로 convolutional layer로 인스턴스화되므로 CNN과 마찬가지로 inflation initialization를 사용한다. 구체적으로, 사전 학습된 모델의 2D conv layer의 가중치로 중앙 프레임에 대한 conv filter를 초기화하고 다른 가중치는 0으로 초기화한다. 상대 위치 임베딩의 경우 앞서 설명한 분해된 상대 위치 임베딩을 활용한다. 사전 학습된 가중치와 시간적 임베딩을 0으로 사용하여 공간 임베딩을 간단히 초기화한다.
4. MViT Architecture Variants
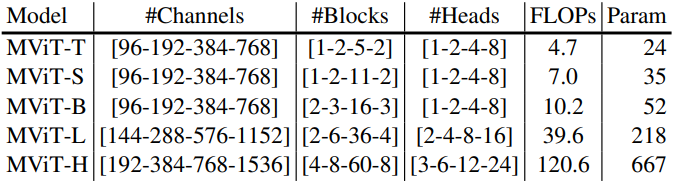
저자들은 다른 ViT와 공정한 비교를 위해 위 표와 같이 다양한 수의 파라미터와 FLOPs를 사용하여 여러 MViT 변형을 구축했다. 특히 기본 채널 차원, 각 stage의 블록 수, 블록의 head 수를 변경하여 MViT에 대한 5가지 변형 (Tiny, Small, Base, Large, Huge)을 설계하였다. Head가 많을수록 런타임이 느려지지만 FLOPs와 파라미터에는 영향을 미치지 않으므로 런타임을 개선하기 위해 더 적은 수의 head를 사용하였다.
MViT의 pooling attention 디자인을 따라 기본적으로 모든 pooling attention block에 key와 value pooling을 사용하고 pooling stride는 첫 번째 stage에서 4로 설정되고 stage 전반에 걸쳐 해상도에 따라 stride를 적응적으로 감소시켰다.
Experiments: Image Recognition
- 데이터셋
- classification: ImageNet
- object detection: COCO
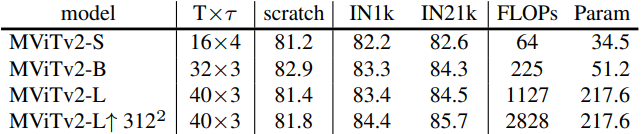
1. Image Classification on ImageNet-1K
다음은 ImageNet-1K에서 이전 연구들과 비교한 표이다.

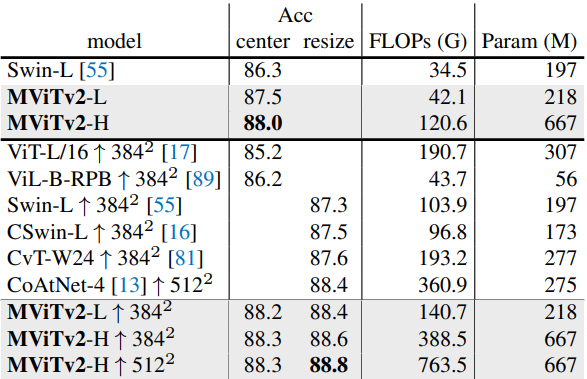
다음은 ImageNet-21K의 데이터를 사용한 ImageNet-1K fine-tunning 결과이다.
2. Object Detection on COCO
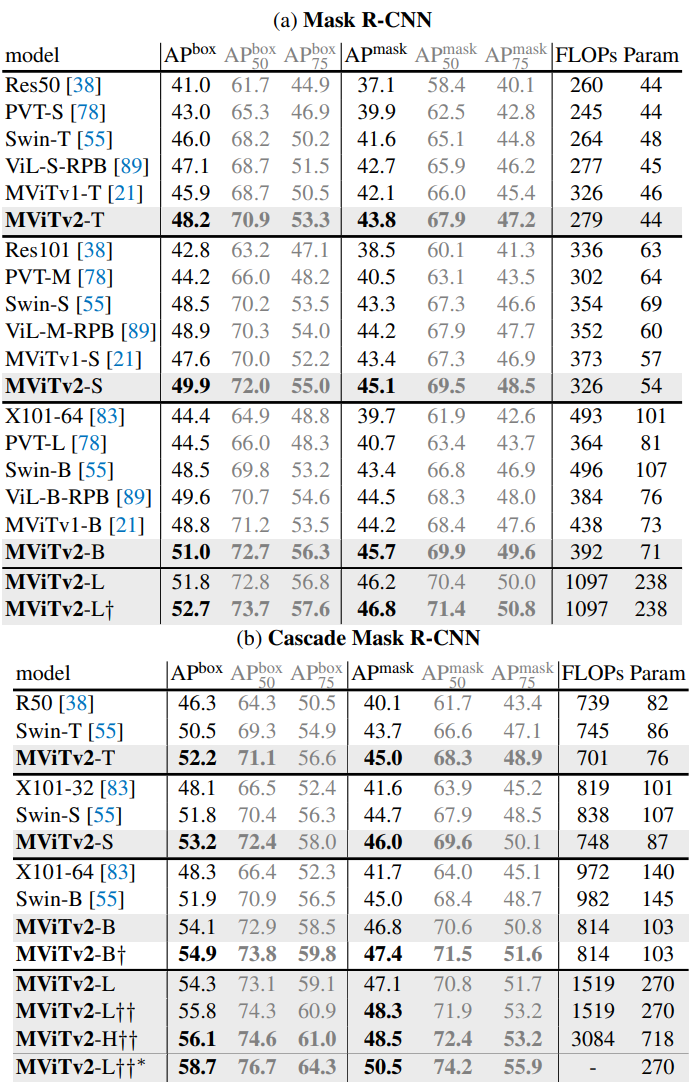
다음은 Mask RCNN (a)과 Cascade Mask R-CNN (b)을 사용한 COCO object detection에 대한 결과이다.
3. Ablations on ImageNet and COCO
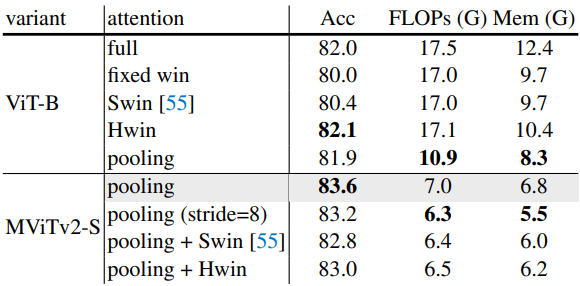
다음은 ImageNet에서 attention 메커니즘을 비교한 표이다.
다음은 COCO에서 attention 메커니즘을 비교한 표이다.
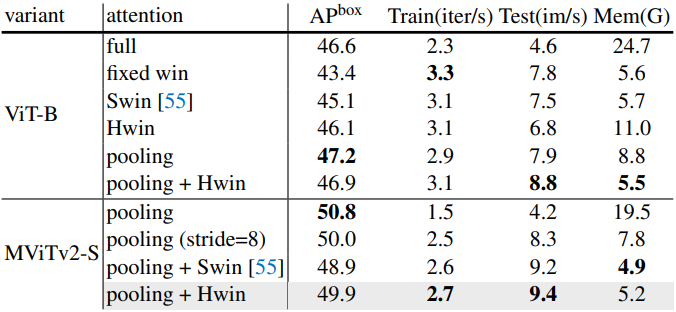
다음은 위치 임베딩에 대한 ablation 결과이다.
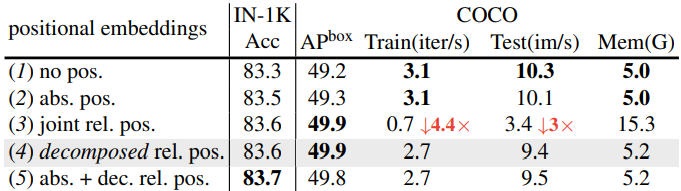
다음은 residual pooling connection에 대한 ablation 결과이다.
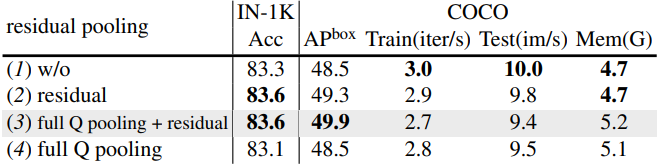
다음은 ImageNet-1K와 COCO에서 런타임을 비교한 표이다.
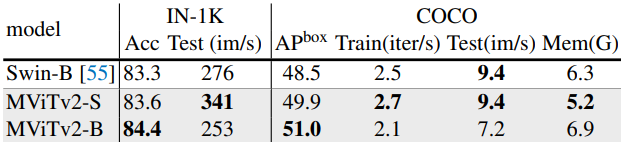
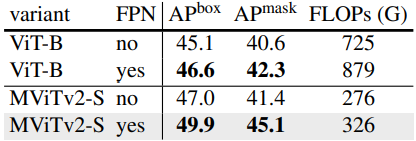
다음은 COCO에서 단일 스케일과 멀티스케일 (FPN)을 비교한 표이다.
Experiments: Video Recognition
- 데이터셋: Kinetics-400 (K400), Kinetics-600 (K600), Kinetics-700 (K700), Something-Something-v2 (SSv2)
1. Main Results
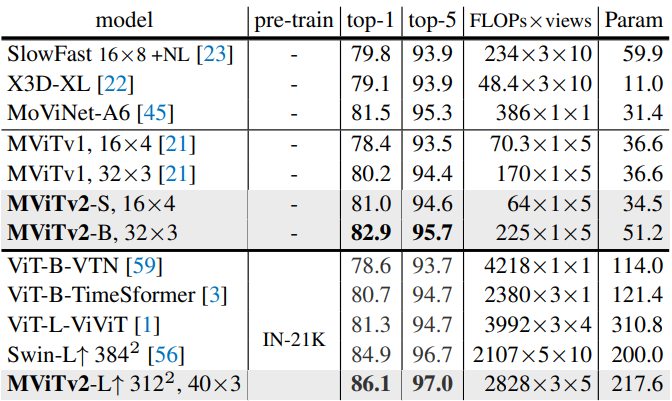
다음은 Kinetics-400에서 이전 연구들과 비교한 표이다.
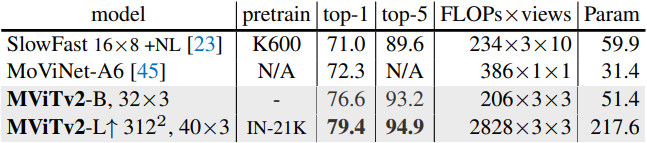
다음은 Kinetics-600에서 이전 연구들과 비교한 표이다.

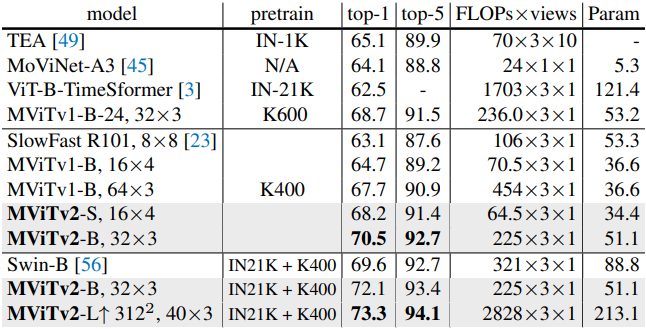
다음은 Kinetics-700에서 이전 연구들과 비교한 표이다.
다음은 SSv2에서 이전 연구들과 비교한 표이다.
2. Ablations on Kinetics
다음은 K400에서의 사전 학습에 대한 ablation 결과이다.