[논문리뷰] MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
NeurIPS 2023 (Spotlight). [Paper] [Page] [Github]
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, Yasutaka Furukawa
Simon Fraser University | Bytedance
3 Jul 2023
Introduction
사실적인 이미지 합성은 매우 사실적인 이미지를 생성하여 VR, AR, 게임 및 영화 제작에 폭넓게 적용하는 것을 목표로 한다. 이 분야는 diffusion 기반 생성 모델과 같은 딥러닝 기술의 급속한 발전에 힘입어 최근 몇 년간 상당한 발전을 이루었다. 특히 성공적인 도메인 중 하나는 text-to-image 생성이며, 최근에는 diffusion model이 주목받고 있다. DALL-E 2, Imagen 등은 대규모 diffusion model을 사용하여 사실적인 이미지를 생성한다. Latent diffusion model은 latent space에 diffusion process를 적용하여 더 효율적인 계산과 더 빠른 이미지 합성을 가능하게 한다.
인상적인 발전에도 불구하고 멀티뷰 text-to-image 합성은 여전히 계산 효율성과 뷰 전반의 일관성 문제에 직면해 있다. 일반적인 접근 방식은 autoregressive 생성 프로세스이며, $n$번째 이미지 생성은 이미지 워핑 및 인페인팅 기술을 통해 $(n-1)$번째 이미지를 조건으로 한다. 그러나 이 autoregressive 접근 방식은 오차가 누적되고 처음 이미지와 마지막 이미지를 연결하지 않는다. 또한 이전 이미지에 의존하면 복잡한 시나리오나 큰 시점 변화에 어려움을 겪을 수 있다.
MVDiffusion이라고 불리는 본 논문의 접근 방식은 perspective image에 대해 사전 학습된 표준 text-to-image 모델의 여러 branch를 사용하여 멀티뷰 이미지를 동시에 생성한다. 구체적으로, Stable Diffusion (SD) 모델을 사용하고 UNet 블록 사이에 correspondence-aware attention (CAA) 메커니즘을 추가하여 뷰 사이의 상호 작용을 촉진하고 멀티뷰 일관성을 적용하는 방법을 학습한다. CAA 블록을 학습시킬 때 사전 학습된 모델의 일반화 능력을 보존하기 위해 원래 SD의 모든 가중치를 고정한다.
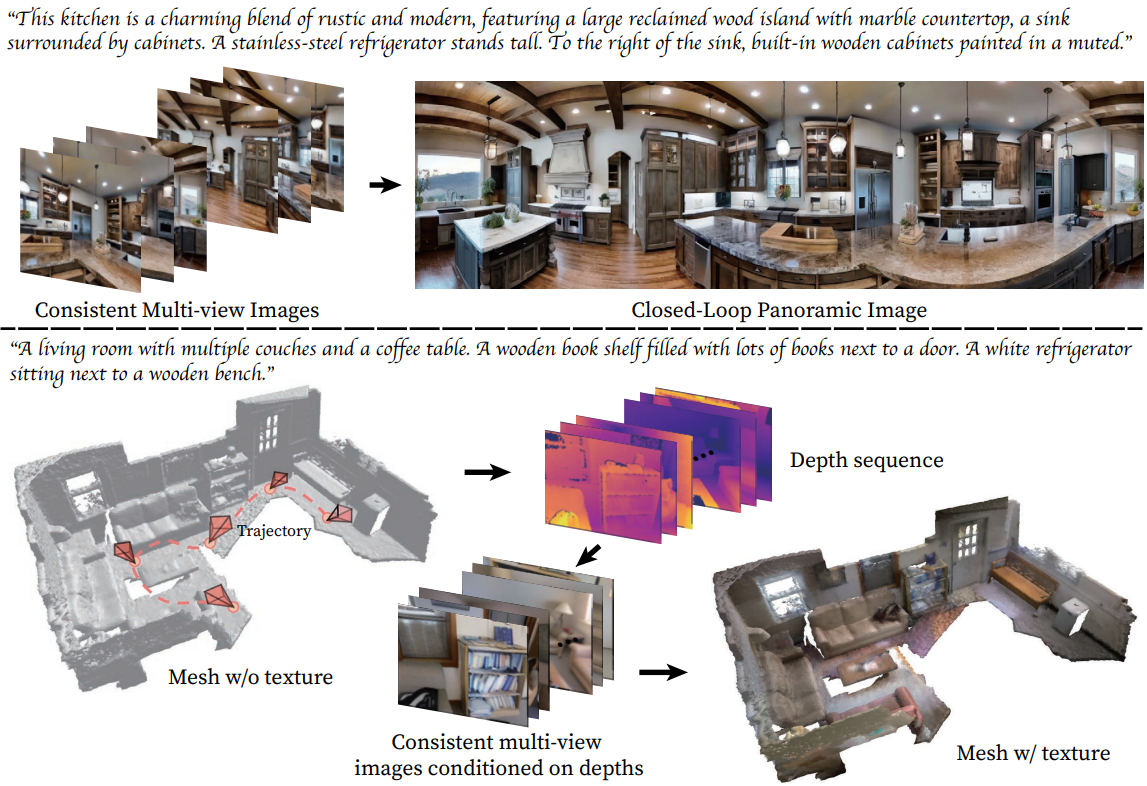
요약하면, 본 논문은 표준 사전 학습된 text-to-image diffusion model에 대한 최소한의 변경이 필요한 멀티뷰 text-to-image 생성 아키텍처인 MVDiffusion을 제시하여 두 개의 멀티뷰 이미지 생성 task에서 SOTA 성능을 달성하였다. 파노라마를 생성하기 위해 MVDiffusion은 임의의 뷰별 텍스트가 제공되는 고해상도의 사실적인 파노라마 이미지를 합성하거나 하나의 perspective image를 전체 360도 뷰로 추정한다. 놀랍게도 MVDiffusion은 현실적인 실내 파노라마 데이터셋으로만 학습하였음에도 불구하고 다양한 파노라마를 생성할 수 있는 능력을 보유하고 있다. 깊이/포즈로 컨디셔닝된 멀티뷰 이미지 생성의 경우 MVDiffusion은 장면 메쉬 텍스처링을 위한 SOTA 성능을 보여준다.
MVDiffusion: Holistic Multi-view Image Generation
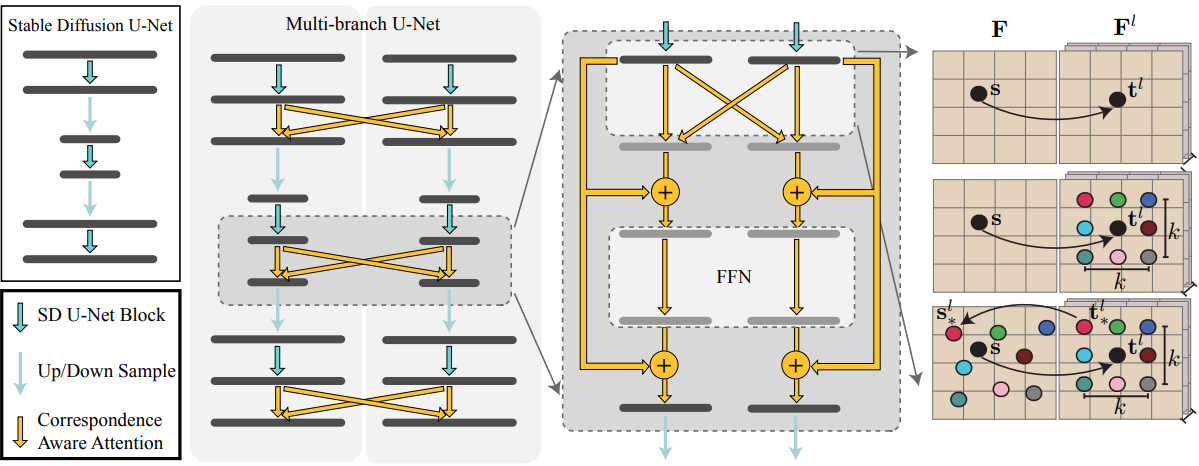
MVDiffusion은 멀티뷰 일관성을 촉진하기 위한 branch 사이의 새로운 correspondence-aware attention (CAA) 메커니즘을 사용하여 Stable Diffusion 모델의 여러 복사본/branch를 실행하여 여러 이미지를 동시에 생성한다. 위 그림은 multi-branch UNet과 CAA 설계의 개요를 보여준다. 이 시스템은 이미지 간에 픽셀 간 correspondences를 아는 경우에 적용 가능하다. 특히 다음 2가지 경우에 적용 가능하다.
- 파노라마 생성: 파노라마는 평면 단층 촬영을 통해 픽셀 간 correspondence들이 얻어지는 카메라 중심을 공유하는 perspective image로 구성된다.
- 주어진 형상의 텍스처 매핑 (멀티뷰 depth-to-image 생성): 임의의 카메라 포즈의 여러 이미지가 깊이 기반 unprojection과 projection을 통해 픽셀 간 correspondences들을 설정한다.
파노라마 생성은 생성 모듈을 사용하며, 멀티뷰 depth-to-image 생성은 생성 모듈과 interpolation 모듈을 사용한다.
1. Panorama generation
MVDiffusion에서는 각각 45도씩 겹치는 90도의 수평 FOV를 갖는 8개의 perspective view를 생성하여 파노라마를 구현한다. 이를 위해 고정된 사전 학습된 Stable Diffusion 모델을 사용하여 생성 모듈을 통해 8개의 512$\times$512 이미지를 생성한다.
생성 모듈
생성 모듈은 8개의 512$\times$512 이미지를 생성한다. 이는 동시 denoising process를 통해 수행된다. 이 프로세스에는 noise를 동시에 예측하기 위해 multi-branch UNet이라고 불리는 공유 UNet 아키텍처에 각 noise latent를 공급한다. 멀티뷰 일관성을 보장하기 위해 각 UNet 블록 다음에 correspondence-aware attention (CAA) 블록이 도입되었다. CAA 블록은 마지막 ResNet 뒤에 오며 멀티뷰 feature들을 가져와 함께 융합하는 역할을 한다.
Correspondence-aware attention (CAA)
CAA 블록은 $N$개의 feature map에서 동시에 작동한다. $i$번째 소스 feature map $\mathbf{F}$의 경우 나머지 $(N - 1)$개의 타겟 feature map $\mathbf{F}^l$과 cross-attention을 수행한다.
소스 feature map의 위치 $\mathbf{s}$에 위치한 토큰의 경우, local neighborhood들과 함께 타겟 feature map \(\{\mathbf{F}^l\}\)의 대응되는 픽셀 \(\{\mathbf{t}^l\}\)을 기반으로 message를 계산한다. 구체적으로, 각 타겟 픽셀 $\mathbf{t}^l$에 대해 ($x$/$y$) 좌표에 정수 변위 ($d_x$/$d_y$)를 추가하여 $K \times K$ neighborhood $\mathcal{N} (\mathbf{t}^l)$을 고려한다. 여기서 $\vert d_x \vert < K/2$, $\vert d_y \vert < K/2$이다. 실제로 $K = 3$을 사용한다.
\[\begin{equation} \mathbf{M} = \sum_l \sum_{t_\ast^l \in \mathcal{N}(\mathbf{t}^l)} \textrm{Softmax} ([\mathbf{W_Q} \bar{\mathbf{F}}(\mathbf{s})] \cdot [\mathbf{W_K} \bar{\mathbf{F}}^l (t_\ast^l)]) \mathbf{W_V} \bar{\mathbf{F}}^l (t_\ast^l) \\ \textrm{where} \quad \bar{\mathbf{F}} (\mathbf{s}) = \mathbf{F} (\mathbf{s}) + \gamma (0), \quad \bar{\mathbf{F}}^l (t_\ast^l) = \mathbf{F}^l (t_\ast^l) + \gamma (\mathbf{s}_\ast^l - \mathbf{s}) \end{equation}\]Message $\mathbf{M}$ 계산은 타겟 feature 픽셀들 \(\{t_\ast^l\}\)에서 소스로 정보를 집계하는 표준 attention 메커니즘을 따른다. $\mathbf{W_Q}$, $\mathbf{W_K}$, $\mathbf{W_V}$는 각각 query, key, value 행렬이다. 주요 차이점은 소스 이미지의 해당 위치 \(\mathbf{s}_\ast^l\)과 $\mathbf{s}$ 사이의 2D 변위에 기반하여 타겟 feature \(\mathbf{F}^l (t_\ast^l)\)에 추가한 위치 인코딩 $\gamma(\cdot)$이다. 변위는 local neighborhood의 상대적 위치를 제공한다. 변위는 2D 벡터이며 $x$ 및 $y$ 좌표 모두에서 변위에 표준 주파수 인코딩을 적용한 다음 concatenate한다. 타겟 feature \(\mathbf{F}^l (t_\ast^l)\)은 정수 위치에 있지 않으며 bilinear interpolatio을 통해 얻는다. Stable diffusion 모델의 고유 능력을 유지하기 위해 ControlNet에서 제안한 대로 transformer 블록의 최종 linear layer와 residual block의 마지막 convolution layer를 0으로 초기화한다. 이 초기화 전략은 Stable Diffusion 모델의 원래 능력이 중단되지 않도록 보장한다.
파노라마 extrapolation
목표는 하나의 perspective image (1개의 조건 이미지)와 뷰별 텍스트 프롬프트를 기반으로 완전한 360도 파노라마 뷰 (7개의 타겟 이미지)를 생성하는 것이다. 하나의 조건 이미지를 취하므로 Stable Diffusion의 인페인팅 모델을 기본 모델로 사용한다. 생성 모델과 유사하게 초기화가 0인 CAA 블록이 UNet에 삽입되고 데이터셋에 대해 학습된다.
생성 프로세스에서 모델은 표준 Gaussian의 noise를 사용하여 타겟 이미지와 조건 이미지 모두의 latent를 다시 초기화한다. 조건 이미지의 UNet branch에서 모두 1인 마스크를 이미지에 concatenate한다 (총 4개 채널). 이 concatenate된 이미지는 인페인팅 모델에 대한 입력 역할을 하여 조건 이미지의 내용이 동일하게 유지되도록 한다. 반대로 타겟 이미지에 대한 UNet branch에서는 검정색 이미지(픽셀 값 0)를 모두 0인 마스크와 concatenate하여 입력으로 사용하므로 인페인팅 모델이 텍스트 조건과 조건 이미지와의 대응을 기반으로 완전히 새로운 이미지를 생성해야 한다.
학습
멀티뷰 일관성을 보장하기 위해 사전 학습된 Stable Diffusion Unet 또는 Stable Diffusion inpainting Unet에 CAA 블록을 삽입한다. CAA 블록을 학습시키기 위해 다음과 같은 loss를 사용하며, 사전 학습된 네트워크는 동결된다.
\[\begin{equation} L_\textrm{MVDiffusion} := \mathbb{E}_{\{\mathbf{Z}_t^i = \mathcal{E}(\mathbf{x}^i)\}_{i=1}^N, \{\epsilon^i \sim \mathcal{N}(0,I)\}_{i=1}^N, \mathbf{y}, t} [\sum_{i=1}^N \| \epsilon^i - \epsilon_\theta^i (\{\mathbf{Z}_t^i\}, t, \tau_\theta (\mathbf{y})) \|_2^2] \end{equation}\]2. Multiview depth-to-image generation
멀티뷰 depth-to-image task는 주어진 깊이/포즈에 따라 멀티뷰 이미지를 생성하는 것을 목표로 한다. 이러한 이미지는 깊이 기반 unprojection과 projection을 통해 픽셀 간 correspondence들을 설정한다. MVDiffusion의 프로세스는 생성 모듈에서 주요 이미지를 생성하는 것부터 시작되며, 이 이미지는 보다 자세한 표현을 위해 interpolation 모듈에 의해 dense해진다.
생성 모듈
멀티뷰 depth-to-image 생성을 위한 생성 모듈은 파노라마 생성을 위한 생성 모듈과 유사하다. 모듈은 192$\times$256 이미지 집합을 생성한다. 기본 생성 모듈로 깊이 조건이 적용된 Stable Diffusion 모델을 사용하고 multi-branch UNet을 통해 멀티뷰 이미지를 동시에 생성한다. CAA 블록은 멀티뷰 일관성을 보장하기 위해 채택되었다.
Interpolation 모듈
VideoLDM에서 영감을 받은 MVDiffusion의 interpolation 모듈은 이전에 생성 모듈에서 생성된 한 쌍의 키프레임들 사이에 $N$개의 이미지를 생성한다. 이 모델은 생성 모델과 동일한 UNet 구조 및 CAA 가중치를 추가 convolution layer와 함께 활용하고 Gaussian noise를 사용하여 중간 이미지와 주요 이미지 모두의 latent를 다시 초기화한다. 이 모듈의 독특한 특징은 주요 이미지의 UNet branch가 이미 생성된 이미지로 컨디셔닝된다는 것이다. 특히 이 조건들은 모든 UNet 블록에 통합된다. 주요 이미지의 UNet branch에서 생성된 이미지는 모두 1인 마스크와 concatenate된 다음 (4개 채널) zero-convolution 연산을 사용하여 이미지를 해당 feature map 크기로 다운샘플링한다. 이러한 다운샘플링된 조건들은 이후에 UNet 블록의 입력에 추가된다. 중간 이미지의 branch에 대해서는 다른 접근 방식을 취한다. 검은색 이미지(픽셀 값 0)를 모두 0인 마스크에 concatenate하고 동일한 zero-convolution 연산을 적용하여 해당 feature map 크기와 일치하도록 이미지를 다운샘플링한다. 이러한 다운샘플링된 조건들도 UNet 블록의 입력에 추가된다. 이 절차는 기본적으로 마스크가 1일 때 branch가 컨디셔닝된 이미지를 재생성하고 마스크가 0일 때 branch가 중간 이미지를 생성하도록 모듈을 학습시킨다.
학습
2단계 학습 과정을 사용한다. 첫 번째 단계에서는 모든 ScanNet 데이터를 사용하여 SD UNet 모델을 fine-tuning한다. 이 단계는 CAA 블록이 없는 단일 뷰 학습이다. 두 번째 단계에서는 CAA 블록과 이미지 조건 블록을 UNet에 통합하고 추가된 파라미터만 학습한다. 모델 학습에는 파노라마 생성과 동일한 loss를 사용한다.
Experiments
- 구현 디테일
- Diffusers에서 제공하는 Stable Diffusion 코드 활용
- Stable Diffusion의 사전 학습된 VAE는 그대로 유지
- GPU: NVIDIA RTX A6000 GPU 4개
1. Panoramic image generation
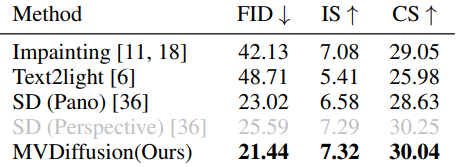
다음은 다른 방법들과 FID, Inception Score (IS), CLIP Score (CS)를 비교한 표이다.
다음은 다른 방법들과 결과를 비교한 것이다. 빨간색 상자는 가장 왼쪽과 가장 오른쪽이 연결된 영역을 나타낸다.

다음은 야외 장면에 대한 파노라마 생성 예시이다.

다음은 이미지/텍스트를 조건으로 한 파노라마 생성 예시이다.

2. Multi view depth-to-image generation
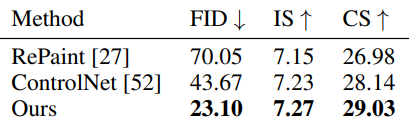
다음은 멀티뷰 depth-to-image 생성에 대한 FID, Inception Score (IS), CLIP Score (CS)를 다른 방법들과 비교한 표이다.
다음은 다른 방법들과 depth-to-image 생성 결과를 비교한 것이다.

다음은 이미지/텍스트를 조건으로 생성된 프레임들과 interpolation 결과를 시각화한 것이다.

다음은 메쉬를 시각화한 것이다.

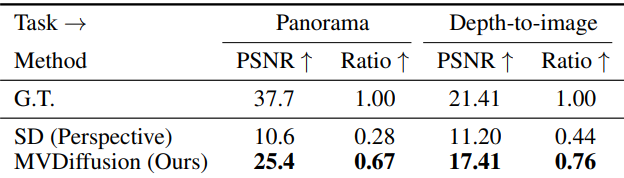
3. Measuring multi-view consistency
다음은 파노라마 생성과 멀티뷰 depth-to-image 생성에 대한 멀티뷰 일관성을 Stable Diffusion과 비교한 표이다.