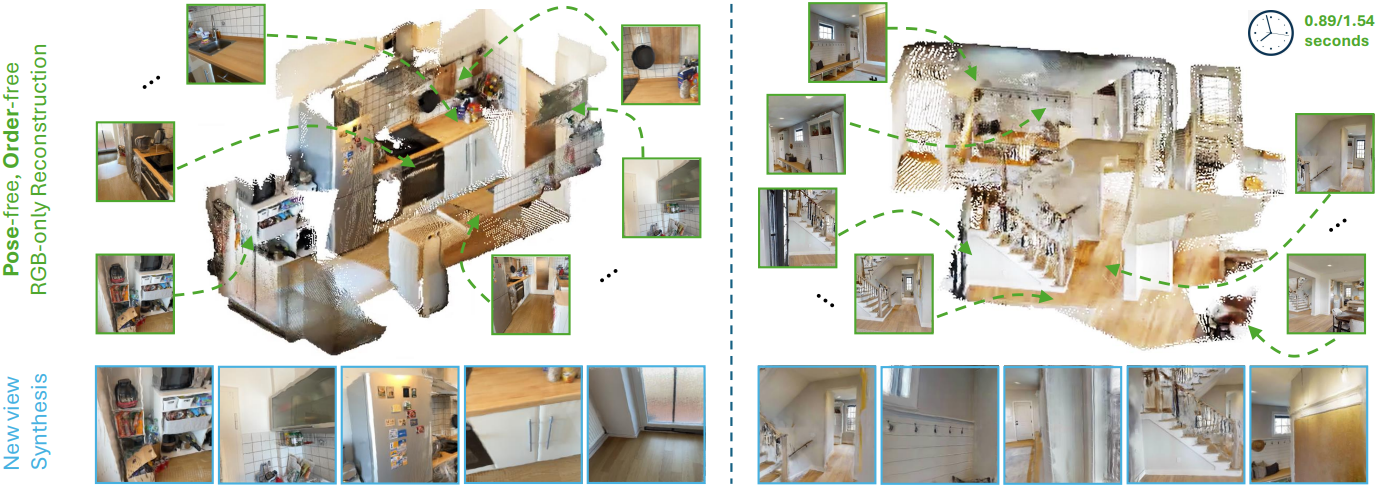
[논문리뷰] MV-DUSt3R+: Single-Stage Scene Reconstruction from Sparse Views In 2 Seconds
CVPR 2025. [Paper] [Page] [Github]
Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexander Schwing, Zhicheng Yan
Meta Reality Labs | University of Illinois Urbana Champaign
9 Dec 2024
Introduction
최근, DUSt3R나 MASt3R와 같은 멀티뷰 장면 재구성 방식은 카메라 intrinsic과 포즈를 모르는 RGB 뷰 집합을 직접 처리하였다. 이러한 방법은 한 번에 두 개의 뷰, 즉 선택한 레퍼런스 뷰와 다른 소스 뷰를 처리하고 레퍼런스 뷰의 카메라 좌표계에서 픽셀 정렬된 3D 포인트맵을 직접 추론한다. 더 많은 입력 뷰 집합을 처리하기 위해 여러 쌍의 추론을 조합한 후 두 번째 글로벌 최적화 단계를 거쳐 로컬 쌍의 재구성을 하나의 글로벌 좌표계로 정렬한다.
이러한 방법은 물체 중심의 DTU 데이터셋에서는 유망하지만, 2-view 입력의 스테레오 큐가 모호할 수 있으므로 장면을 재구성하는 데 비효율적이다. 또한 개별 2-view 입력의 그럴듯한 재구성에도 불구하고, 글로벌 좌표계에서 정렬할 때 종종 충돌이 발생한다. 이러한 충돌은 글로벌 최적화로 해결하기 어려울 수 있으며, 이는 쌍별 예측만 회전시키고 잘못된 쌍별 매칭은 수정하지 않는다.
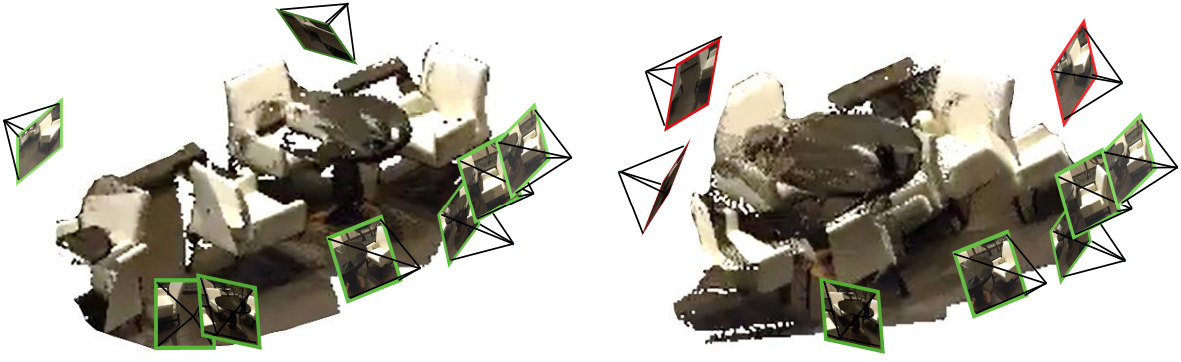
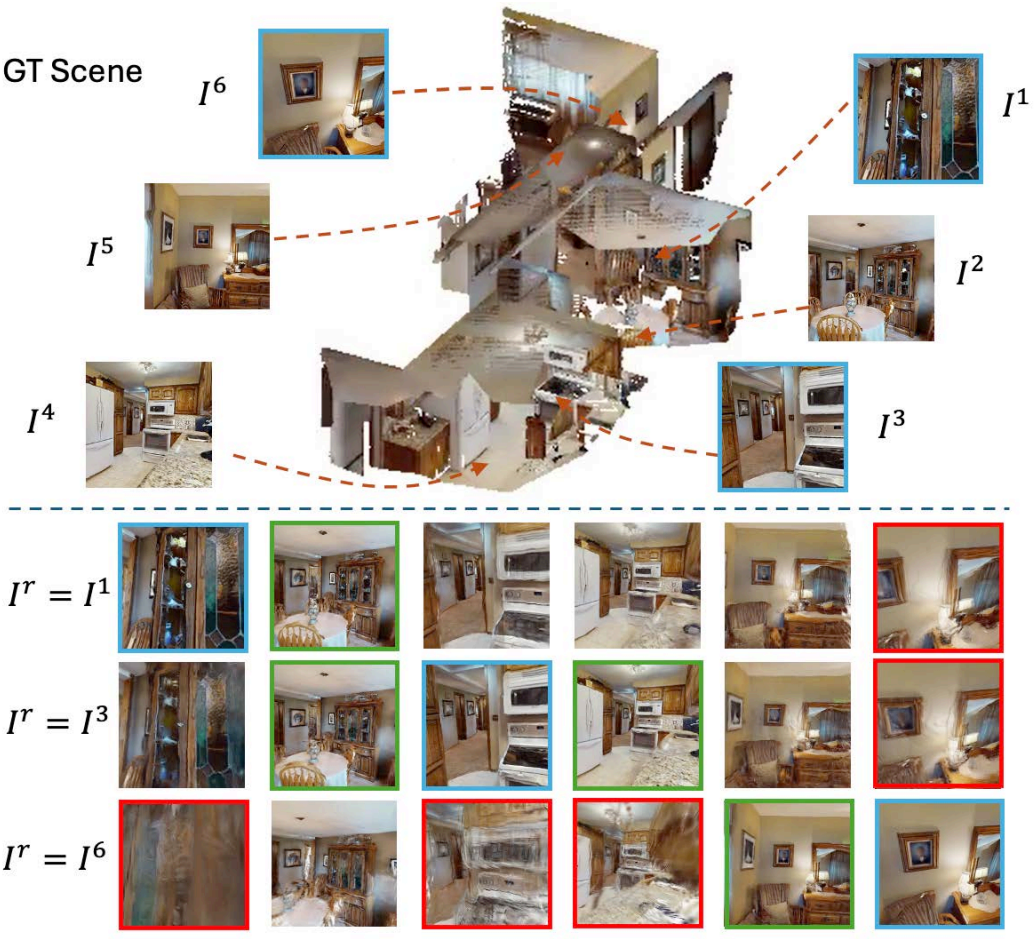
결과적으로 장면 재구성은 정렬되지 않은 포인트맵을 보인다. 위 그림은 (왼쪽) ground-truth 장면과 (오른쪽) 글로벌 최적화를 수행한 DUSt3R를 비교한 것이다.
앞서 언급한 문제를 해결하기 위해, 본 논문은 단일 단계 네트워크 Multi-View Dense Unconstrained Stereo 3D Reconstruction (MV-DUSt3R)을 제안하였다. MV-DUSt3R는 하나의 feed-forward pass에서 많은 수의 입력 뷰를 공동으로 처리하고, 기존 방법들에서 사용된 계단식 글로벌 최적화를 완전히 제거하였다. 이를 달성하기 위해, 멀티뷰 디코더 블록을 사용하는데, 이는 선택된 레퍼런스 뷰와 다른 모든 소스 뷰 간의 모든 쌍별 관계를 공동으로 학습할 뿐만 아니라 모든 소스 뷰 간의 쌍별 관계를 적절히 처리한다. 게다가, 학습 시에 예측된 뷰별 포인트맵이 동일한 레퍼런스 카메라 좌표계를 고수하도록 장려하여 추가적인 글로벌 최적화의 필요성을 없앴다.
Sparse한 멀티뷰 이미지에서 큰 장면을 재구성할 때, 선택된 레퍼런스 뷰와 특정 소스 뷰 간의 스테레오 큐가 충분하지 않을 수 있다. 이는 카메라 포즈의 상당한 변화로 인해 레퍼런스 뷰와 해당 소스 뷰 간의 관계를 직접 추론하기 어렵기 때문이다. 따라서 해당 소스 뷰에 대한 장거리 정보 전파가 필요하다. 이를 효율적으로 처리하기 위해 저자들은 MV-DUSt3R+를 추가로 제시하였다. MV-DUSt3R+는 일련의 레퍼런스 뷰에 작동하며 효과적인 장거리 정보 전파를 위해 Cross-Reference-View attention block들을 사용한다.
MV-DUSt3R는 HM3D, ScanNet, MP3D에서 DUSt3R보다 48~78배 빠르면서도 멀티뷰 스테레오 재구성 및 멀티뷰 포즈 추정 task에서 상당히 더 나은 결과를 달성하였다. 특히 MV-DUSt3R+는 더 어려운 설정에서 재구성 품질을 개선할 수 있으며, DUSt3R보다 10배 이상 더 빠르다.
Novel view synthesis (NVS)로 확장하기 위해 3D Gaussian 속성으로 예측하는 가벼운 예측 head를 추가로 연결한다. 예측된 뷰별 Gaussian은 splatting 기반 렌더링 전에 대상 뷰의 좌표로 변환된다. 이를 통해 Gaussian의 위치를 더 정확하게 예측할 수 있어, 경험적으로 설계된 3D Gaussian 파라미터를 사용한 DUSt3R보다 성능이 우수하다.
Method
본 논문의 목표는 카메라 intrinsic과 포즈를 모르는 sparse한 RGB 이미지 세트가 주어진 장면을 dense하게 재구성하는 것이다. DUSt3R를 따라, 모델은 각 뷰에 대해 2D 픽셀에 맞춰진 3D 포인트맵을 예측한다. DUSt3R와 달리, 모델은 한 번의 forward pass에서 모든 입력 뷰에 대한 3D 포인트맵을 공동으로 예측한다.
$I^v \in \mathbb{R}^{H \times W \times 3}$인 장면 \(\{I^v\}_{v=1}^N\)의 $N$개 입력 이미지 뷰가 주어지면, 하나의 레퍼런스 \(r \in \{1, \ldots, N\}\)을 선택하고, 뷰별로 3D 포인트맵 \(\{X^{v,r}\}_{v=1}^N\)을 예측한다. 3D 포인트맵 $X^{v,r} \in \mathbb{R}^{H \times W \times 3}$은 레퍼런스 뷰 $r$의 카메라 좌표계에서 이미지 $I^v$에 대한 3D 포인트의 좌표를 나타낸다.
1. MV-DUSt3R
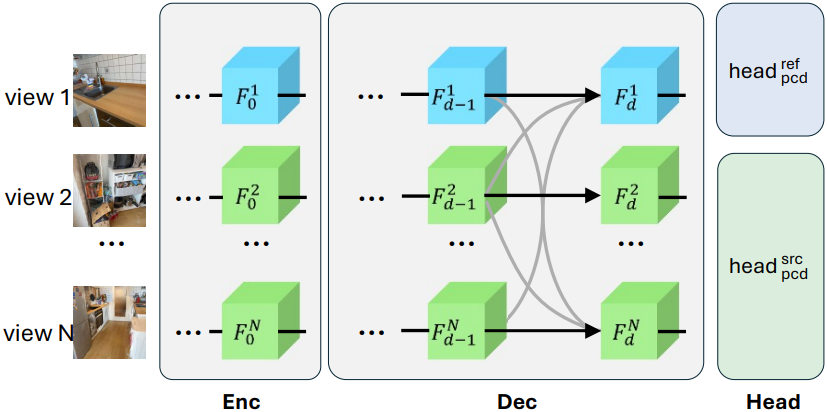
A Multi-View Model Architecture
MV-DUSt3R는 이미지를 시각적 토큰으로 변환하는 인코더, 뷰 간에 토큰을 융합하는 디코더 블록, 2D 픽셀에 맞춰진 뷰별 3D 포인트맵을 예측하는 regression head로 구성된다. DUSt3R와 달리, 한 번에 두 뷰에 대한 토큰만 독립적으로 융합하는 대신 디코더 블록을 사용하여 모든 뷰에서 토큰을 융합한다.
먼저 입력 뷰 \(\{I^v\}_{v=1}^N\)에 공유 가중치를 갖는 ViT 인코더 $\textrm{Enc}$가 적용되어 초기 시각적 토큰 \(\{F_0^v = \textrm{Enc} (I^v)\}_{v=1}^N\)를 계산한다. 인코더 출력 feature의 해상도는 토큰 시퀀스로 flatten되기 전에 입력 이미지보다 16배 작다.
토큰을 융합하기 위해 두 가지 유형의 디코더가 사용된다. 하나는 선택한 레퍼런스 뷰를 위한 디코더이고 다른 하나는 나머지 소스 뷰를 위한 디코더이다. 이들은 동일한 아키텍처를 공유하지만 가중치는 다르다. 각 디코더는 각각 $D$개의 디코더 블록 \(\textrm{DecBlock}_d^\textrm{ref}\)와 \(\textrm{DecBlock}_d^\textrm{src}\)으로 구성된다. 차이점은 \(\textrm{DecBlock}_d^\textrm{ref}\)가 레퍼런스 뷰 토큰 $F^r$을 업데이트하는 데 전념하는 반면, \(\textrm{DecBlock}_d^\textrm{src}\)는 다른 모든 소스 뷰에서 토큰 \(\{F^v\}_{v \ne r}\)을 업데이트한다는 것이다.
각 디코더 블록은 한 뷰에서 기본 토큰 집합과 다른 뷰에서 보조 토큰 집합을 입력으로 받는다. 각 블록에서 self-attention layer는 기본 토큰에만 적용되고 cross-attention layer는 최종 MLP가 기본 토큰에 적용되기 전에 기본 토큰과 보조 토큰을 융합한다. Attention과 MLP 전에 layer normalization이 적용된다. 디코더는 다음과 같이 최종 토큰 표현 $F_D^v$를 계산한다.
\[\begin{equation} F_d^v = \begin{cases} \textrm{DecBlock}_d^\textrm{ref} (F_{d-1}^v, \mathcal{F}_{d-1}^{-v}) & \textrm{if} \; v = r \\ \textrm{DecBlock}_d^\textrm{src} (F_{d-1}^v, \mathcal{F}_{d-1}^{-v}) & \textrm{otherwise} \end{cases} \end{equation}\](\(\mathcal{F}_d^{-v} = \{F_d^1, \ldots, F_d^{v-1}, F_d^{v+1}, \ldots, F_d^N\}\)는 $F_d^v$의 뷰를 제외한 모든 뷰의 토큰)
최종적으로 뷰별로 3D 포인트맵을 예측하기 위해 두 개의 head를 사용한다. 레퍼런스 뷰의 경우 \(\textrm{Head}_\textrm{pcd}^\textrm{ref}\), 다른 모든 뷰의 경우 \(\textrm{Head}_\textrm{src}^\textrm{ref}\)를 사용한다. 두 head는 동일한 아키텍처를 공유하지만 다른 가중치를 사용한다. 각각은 linear projection layer와 upscale factor가 16인 pixel shuffle layer로 구성되어 원래 입력 이미지 해상도를 복원한다. DUSt3R에서와 같이 head는 3D 포인트맵 $X^{v,r} \in \mathbb{R}^{H \times W \times 3}$과 신뢰도 맵 $C^{v,r} \in \mathbb{R}^{H \times W}$를 예측한다.
\[\begin{equation} X^{v,r}, C^{v,r} = \begin{cases} \textrm{Head}_\textrm{pcd}^\textrm{ref} (F_D^v) & \textrm{if } v = r \\ \textrm{Head}_\textrm{pcd}^\textrm{src} (F_D^v) & \textrm{otherwise} \end{cases} \end{equation}\]DUSt3R는 뷰가 2개인 MV-DUSt3R의 특수한 경우이다. 그러나 여러 입력 뷰의 경우 MV-DUSt3R는 훨씬 더 큰 보조 토큰 세트를 사용하여 기본 토큰을 업데이트하므로 더 많은 뷰의 이점을 얻을 수 있다. 중요한 점은 아키텍처 구성 요소와 구조가 DUSt3R와 약간만 다르기 때문에 (추가 skip connection, convolution) 학습 가능한 파라미터가 약간 더 많다는 것이다. MV-DUSt3R의 파라미터 수는 DUSt3R와 거의 동일하므로 MV-DUSt3R는 사전 학습된 DUSt3R 가중치를 사용하여 초기화할 수 있다.
Training Recipe
DUSt3R에서 영감을 받아 confidence-aware pointmap regression loss \(\mathcal{L}_\textrm{conf}\)를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{conf} = \sum_{v \in \{1, \ldots, N\}} \sum_{p \in P^v} C_p^{v,r} \left\| \frac{1}{z} X_p^{v,r} - \frac{1}{\bar{z}} \bar{X}_p^{v,r} \right\| - \beta \log C_p^{v,r} \\ \textrm{where} \; z = \textrm{norm} (\mathcal{X}^{\{v\},r}), \; \bar{z} = \textrm{norm} (\bar{\mathcal{X}}^{\{v\},r}) \end{equation}\]($P^v$는 GT 3D 포인트가 잘 정의된 뷰 $v$의 유효 픽셀 세트, \(\bar{X}_p^{v,r}\)는 뷰 $v$의 픽셀 $p$에 대한 레퍼런스 뷰 $r$에서의 GT 3D 포인트)
2. MV-DUSt3R+
다른 레퍼런스 뷰 선택에 대해 MV-DUSt3R로 재구성된 장면의 품질은 공간적으로 다르다. 입력 소스 뷰에 대한 예측된 포인트맵은 레퍼런스 뷰에 대한 뷰포인트 변화가 작을 때 더 나은 경향이 있으며, 뷰포인트 변화가 증가함에 따라 저하된다. 그러나 sparse한 입력 뷰 집합으로 큰 장면을 재구성하려면 다른 모든 소스 뷰에 대한 적당한 뷰포인트 변화만 있는 하나의 레퍼런스 뷰가 존재할 가능성이 낮다. 따라서 선택된 하나의 레퍼런스 뷰로 모든 곳에서 장면을 동일하게 잘 재구성하는 것은 어렵다.
저자들은 이를 해결하기 위해 여러 뷰를 레퍼런스 뷰로 선택하고 각 선택된 레퍼런스 뷰의 카메라 좌표에서 모든 입력 뷰에 대한 포인트맵을 공동으로 예측하는 MV-DUSt3R+를 제안하였다. 저자들은 특정 입력 뷰의 포인트맵은 한 레퍼런스 뷰에 대해 예측하기 어렵지만 다른 레퍼런스 뷰에 대해서는 예측하기가 더 쉽다고 가설을 세웠다. 모든 입력 뷰의 포인트맵 예측을 전체적으로 개선하기 위해 MV-DUSt3R+에 새로운 Cross-Reference-View 블록이 포함되었다.
A Multi-Path Model Architecture
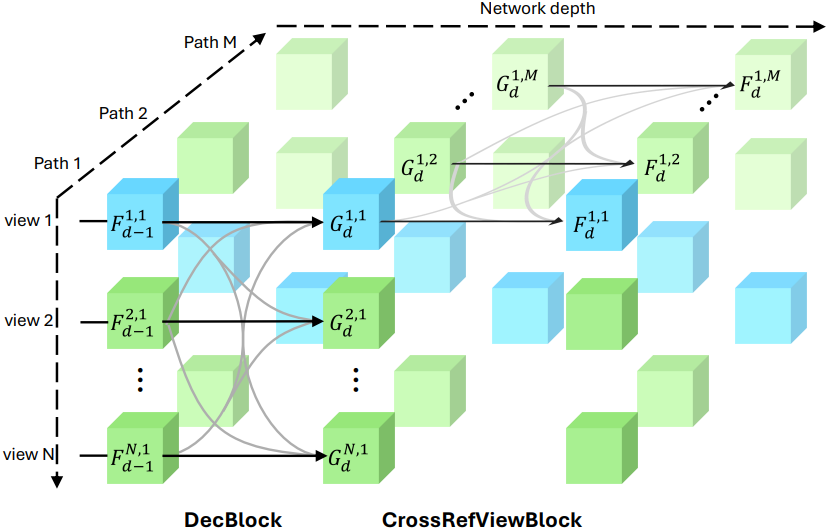
\(R = \{r^m\}_{m=1}^M\)은 입력 뷰 집합에서 무작위로 선택된 $M$개의 레퍼런스 뷰 집합이다. MV-DUSt3R와 동일한 디코더 블록을 여러 개 채택하여 모델 아키텍처에 배치하고, 이를 사용하여 입력 뷰 $v$와 레퍼런스 뷰 $r^m$에 대한 디코더 레이어 $d$에서 레퍼런스 뷰 종속 중간 표현 $G_d^{v,m}$를 계산한다.
각 디코더 블록 뒤에 Cross-Reference-View 블록을 추가하여 여러 레퍼런스 뷰에서 계산된 뷰별 토큰을 융합하고 업데이트한다.
\[\begin{equation} F_d^{v,m} = \textrm{CrossRefViewBlock}_d (G_d^{v,m}, \mathcal{G}_d^{v,-m}) \\ \textrm{where} \; \mathcal{G}_d^{v,-m} = \{G_{d-1}^{v,1}, \ldots, G_{d}^{v,m-1}, F_{d-1}^{v,m+1}, \ldots, F_{d-1}^{v,M}\} \end{equation}\]MV-DUSt3R와 마찬가지로 각 레퍼런스 뷰 $r^m$의 뷰별 포인트맵 $X^{v,m}$과 신뢰도 맵 $C^{v,m}$을 계산한다.
Training Recipe
학습하는 동안 $M$개의 입력 뷰 중 무작위 부분집합이 레퍼런스 뷰로 선택된다. 모든 레퍼런스 뷰에 대해 pointmap regression loss의 평균을 계산한다.
Model Inference
Inference 시에는 $M$개의 입력 뷰의 부분집합을 레퍼런스 뷰로 균일하게 선택하는 반면, 첫 번째 입력 뷰는 항상 선택된다. $M$개의 경로가 있는 모델이 사용되지만 최종 뷰별 포인트맵 예측은 첫 번째 경로의 head를 사용하여 계산된다.
3. MV-DUSt3R(+) for Novel View Synthesis
Gaussian Head
픽셀당 Gaussian 파라미터, 즉 scaling factor $S^{v,m} \in \mathbb{R}^{H \times W \times 3}$, rotation quaternion $q^{v,m} \in \mathbb{R}^{H \times W \times 4}$, opacity $\alpha^{v,m} \in \mathbb{R}^{H \times W}$를 예측하기 위해 별도의 head들을 추가한다. 레퍼런스 뷰와 다른 뷰들을 위해 각각 Gaussian head \(\textrm{Head}_\textrm{3DGS}^\textrm{ref}\)와 \(\textrm{Head}_\textrm{3DGS}^\textrm{src}\)를 추가한다.
\[\begin{equation} S^{v,m}, q^{v,m}, \alpha^{v,m} = \begin{cases} \textrm{Head}_\textrm{3DGS}^\textrm{ref} (F_D^{v,m}) & \textrm{if} \; v = r \\ \textrm{Head}_\textrm{3DGS}^\textrm{src} (F_D^{v,m}) & \textrm{otherwise} \end{cases} \end{equation}\]각 Gaussian의 중심은 예측된 포인트맵 $X^{v,m}$으로 설정되고, 픽셀 색상 $I^v$가 Gaussian의 색상으로 사용되며 spherical harmonics (SH)의 degree를 0으로 고정한다.
Training Recipe
학습하는 동안, 선택된 레퍼런스 뷰 $r^m$에 대해, 입력 뷰와 새로운 뷰에 대한 렌더링 예측을 생성하기 위해 미분 가능한 splatting 기반 렌더링을 수행한다. Gaussian head를 학습시키기 위해 3DGS와 동일한 렌더링 loss \(\mathcal{L}_\textrm{render}\)를 사용한다. 최종 학습 loss에는 \(\mathcal{L}_\textrm{conf}\)와 \(\mathcal{L}_\textrm{render}\)가 모두 포함된다.
Experiments
- 데이터셋: HM3D, ScanNet, MP3D
- 구현 디테일
- 입력 해상도: 224$\times$224
- GPU: Nvidia H100 64개
- 초기화: DUSt3R 가중치
- 입력 뷰 수: $N = 8$
- MV-DUSt3R+의 레퍼런스 뷰 수: $M = 4$
- epoch 당 15만 개의 궤적으로 총 100 epoch 학습 (180시간 소요)
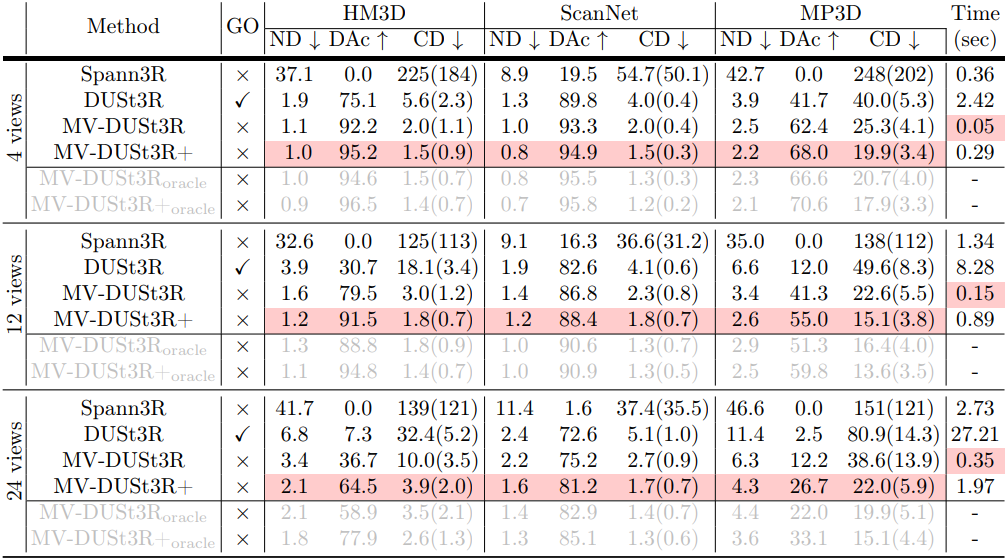
1. Multi-View Stereo Reconstruction
다음은 multi-view stereo (MVS) reconstruction 결과를 비교한 표이다. oracle은 레퍼런스 뷰 후보에서 가장 좋은 하나의 뷰를 직접 선택하여 달성한 성능이다.
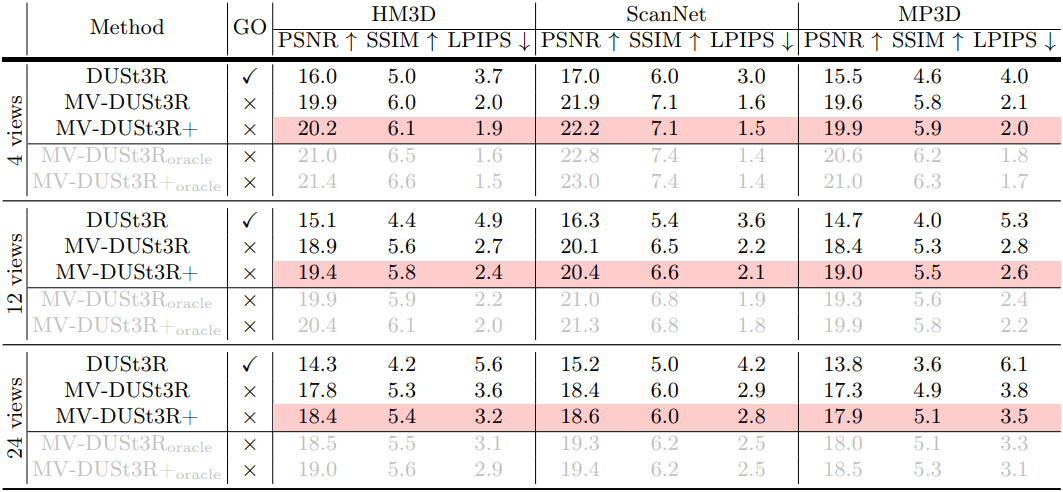
다음은 MVS reconstruction과 NVS 결과를 DUSt3R와 비교한 것이다.

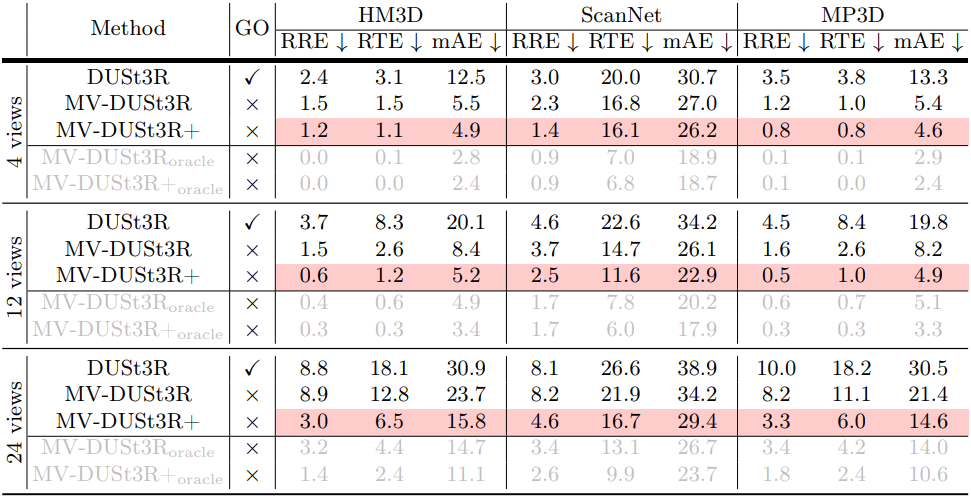
2. Multi-View Pose Estimation
다음은 multi-view pose estimation (MVPE) 결과를 비교한 표이다. (% 생략)
3. Novel View Synthesis
다음은 NVS 결과를 DUSt3R와 비교한 것이다. (SSIM과 LPIPS는 10배한 값)
4. Ablation Studies
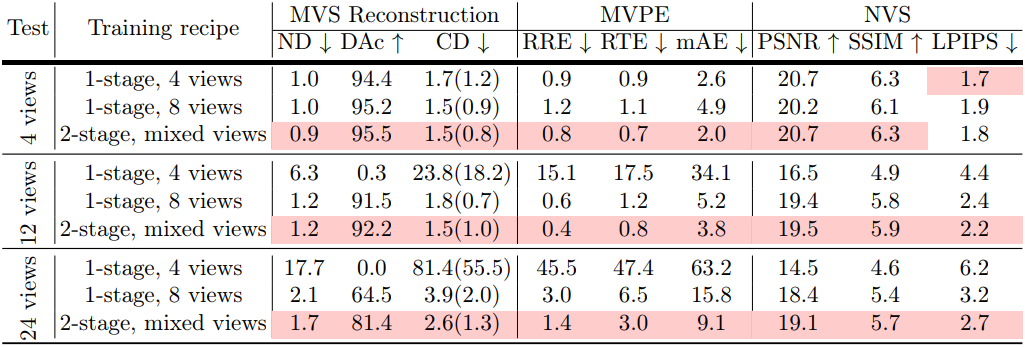
다음은 학습 시에 사용한 입력 뷰의 수에 따른 MV-DUSt3R+의 성능을 비교한 표이다. (HM3D evaluation set)
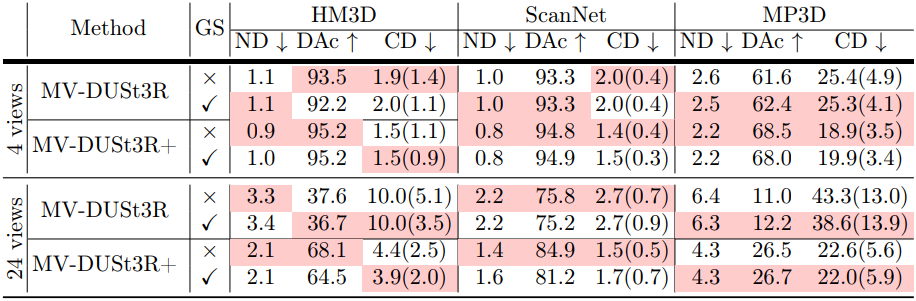
다음은 Gaussian (GS) head의 영향을 비교한 표이다.