[논문리뷰] MUSt3R: Multi-view Network for Stereo 3D Reconstruction
CVPR 2025. [Paper] [Page]
Yohann Cabon, Lucas Stoffl, Leonid Antsfeld, Gabriela Csurka, Boris Chidlovskii, Jerome Revaud, Vincent Leroy
NAVER LABS Europe
3 Mar 2025

Introduction
DUSt3R는 임의의 이미지 컬렉션에 대해 dense하고 제약 없는 스테레오 3D 재구성을 제공할 수 있다. 쌍별 재구성 문제를 픽셀과 3D 포인트 간의 매핑인 pointmap 쌍을 예측하는 문제로 변환함으로써, 일반적인 카메라 모델의 경직된 제약 조건을 효과적으로 완화하였다. Pointmap 표현은 3D 형상 구조와 카메라 파라미터를 모두 포괄하며, 깊이, 카메라 포즈, 초점 거리 추정, 3D 재구성, 픽셀 correspondence 등 다양한 3D 비전 task를 통합하고 공동으로 해결할 수 있도록 한다. 수백만 개의 이미지 쌍으로 학습된 DUSt3R는 zero-shot으로 다양한 실제 시나리오에서 전례 없는 성능과 일반화를 보여주었다.
이러한 아키텍처는 monocular나 binocular의 경우에서 원활하게 작동하지만, 많은 이미지를 공급할 때 이 접근 방식의 쌍별 특성은 단점이 된다. 예측된 pointmap은 각 쌍의 첫 번째 이미지로 정의된 로컬 좌표계로 표현되므로 모든 예측은 서로 다른 좌표계에 있다. 따라서 모든 예측을 하나의 글로벌 좌표계로 정렬하기 위한 글로벌 후처리 단계가 필요하며, 이미지가 많은 경우 빠르게 처리하기 어려워진다.
본 논문에서는 임의의 규모의 대규모 이미지 컬렉션에 확장 가능하고 빠른 속도로 동일한 좌표계에서 pointmap을 추론할 수 있는 새로운 아키텍처를 설계하였다. 이를 위해, Multi-view network for Stereo 3D Reconstruction (MUSt3R)는 대칭화 및 메모리 메커니즘 추가 등 여러 가지 수정을 통해 DUSt3R 아키텍처를 확장하였다.
MUSt3R는 Structure-from-Motion (SfM) 시나리오에서 순서가 지정되지 않은 이미지 컬렉션의 오프라인 재구성을 처리하는 것 외에도, 움직이는 카메라로 촬영된 동영상 스트림의 카메라 포즈와 3D 구조를 온라인으로 예측하는 것을 목표로 하는 Visual Odometry (VO)와 SLAM도 처리할 수 있다. 본 논문에서는 메모리 메커니즘을 활용하여 하나의 네트워크로 두 시나리오를 모두 원활하게 처리할 수 있는 최초의 접근법을 제시하였다.
Method
1. DUSt3R: a binocular architecture
DUSt3R는 두 개의 이미지 쌍을 공통 좌표계에 있는 3D pointmap에 매핑하여 이미지 쌍으로부터 3D 재구성 및 카메라 파라미터를 공동으로 추론하도록 설계되었다. Transformer 기반 네트워크는 두 개의 입력 이미지가 주어졌을 때 두 개의 3D pointmap
\[\begin{equation} \{\textbf{X}_{i,1}\} \in \mathbb{R}^{H \times W \times 3}, \quad i \in \{1, 2\} \end{equation}\]형태로 3D 재구성을 예측한다. 즉, 이미지 \(\{I_i\}\)의 각 픽셀 $p$와 첫 번째 카메라의 좌표계에서 관찰되는 3D 포인트 \(\textbf{X}_{i,1}[p] \in \mathbb{R}^3\) 간의 2D-to-3D 매핑이다.
한 쌍의 이미지 \(\{I_i\}\)가 주어지면, 먼저 이 이미지들을 일반 패치 또는 토큰으로 분할하고, 이를 Siamese ViT 인코더로 인코딩하여 두 개의 latent 표현 \(\textbf{E}_i\)를 생성한다. 이 표현들은
\[\begin{equation} \textbf{D}_i^0 = \textrm{Lin} (\textbf{E}) \end{equation}\]에 linear projection되며, 이는 $L$개의 얽혀있는 디코더 블록 \(\{\textrm{Dec}_1^l, \textrm{Dec}_2^l\}_{l=1}^L\)의 입력이다. 이 블록들은 두 이미지를 공동으로 처리하며, 각 레이어에서 cross-attention을 통해 정보를 교환하여 시점들과 글로벌한 3D 형상 간의 공간적 관계를 이해한다.
\[\begin{aligned} \textbf{D}_1^l &= \textrm{Dec}_1^l (\textbf{D}_1^{l-1}, \textbf{D}_2^{l-1}) \\ \textbf{D}_2^l &= \textrm{Dec}_2^l (\textbf{D}_2^{l-1}, \textbf{D}_1^{l-1}) \end{aligned}\]마지막으로, 두 개의 DPT prediction head \(\{\textrm{Head}_i^\textrm{3D}\}\)는 최종 pointmap \(\textbf{X}_{i,1}\)과 연관된 신뢰도 \(\textbf{C}_i\)를 마지막 레이어의 출력 \(\textbf{D}_i^L\)와 \(\textbf{E}_i\)에서 예측한다.
\[\begin{equation} \textbf{X}_{i,1}, \textbf{C}_i = \textrm{Head}_i^\textrm{3D} (\textbf{E}_i, \textbf{D}_i^L) \end{equation}\]DUSt3R는 간단한 pixel-wise regression loss를 사용하여 supervised 방식으로 학습된다.
\[\begin{equation} \ell_\textrm{regr} (i,j) [p] = \left\| \frac{\textbf{X}_{i,j} [p]}{z} - \frac{\hat{\textbf{X}}_{i,j} [p]}{\hat{z}} \right\| \end{equation}\]($j=1$은 레퍼런스 시점, $p$는 GT 3D 포인트 \(\hat{\textbf{X}}_{i,j} [p]\)가 정의된 픽셀)
재구성을 scale-invariant로 만들기 위해 $z$와 $\hat{z}$가 도입되었다. $z$와 $\hat{z}$는 모든 유효한 3D 포인트에서 원점까지의 평균 거리로 정의된다. 본 논문에서는 MASt3R를 따라 GT가 metric이면 $z = \hat{z}$로 설정한다. DUSt3R를 따라 이 loss를 confidence-aware loss로 래핑한다.
\[\begin{equation} \mathcal{L}_\textrm{conf} = \sum_{i = \{1, 2\}} \sum_{p \in I_i} \textbf{C}_i [p] \cdot \ell_\textrm{regr} (i,j) [p] - \alpha \log \textbf{C}_i [p] \end{equation}\]2. MUSt3R: a Multi-view Architecture
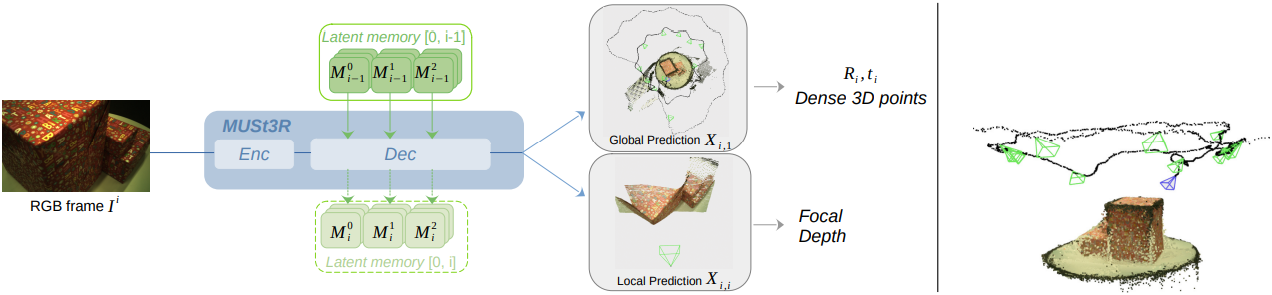
단순히 $N$개 뷰로 확장하는 것은 사실상 $N$개의 서로 다른 디코더 세트를 필요로 하므로 확장성이 떨어진다. 대신, 뷰 간에 가중치를 공유하는 하나의 Siamese 디코더를 사용하여 아키텍처를 대칭적으로 구성한다. 이 아키텍처는 $N$개의 뷰로 자연스럽게 확장되는 동시에 DUSt3R에 비해 디코더의 학습 가능한 파라미터 수를 절반으로 줄인다. 또한, 효율적인 카메라 파라미터 추정에 활용될 추가 pointmap을 예측하도록 DUSt3R를 확장한다.
DUSt3R 아키텍처를 단순화
먼저, DUSt3R 아키텍처를 공유 가중치를 갖는 Siamese 디코더 $\textrm{Dec}$와 Siamese head $\textrm{Head}^\textrm{3D}$로 대체한다. 공통 좌표계를 정의하는 레퍼런스 이미지 $I_1$을 식별하기 위해, 공유 디코더의 시작 부분에 학습 가능한 임베딩 $\textbf{B}$를 \(\textbf{D}_2^0\)에 추가한다.
\[\begin{equation} \textbf{D}_2^0 = \textrm{Lin}(\textbf{E}_2) + \textbf{B} \end{equation}\]멀티뷰로 확장
프레임워크는 자연스럽게 세 개 이상의 이미지를 처리하도록 확장된다. 이는 각 디코더 블록 \(\textrm{Dec}^l\)에서 cross-attention의 동작을 변경하여 간단히 수행할 수 있다. 이들은 모두 residual이며, self-attention, cross-attention, 최종 MLP를 포함한다. 따라서 cross-attention이 이미지 $I_i$의 토큰과 다른 모든 이미지 $j \ne i$의 토큰 사이에서 작동하도록 할 수 있다.
모델은 각 레이어 $l$에서 이미지 $I_i$의 토큰과 다른 모든 이미지의 토큰 간의 cross-attention을 적용한다.
\[\begin{aligned} &\textbf{D}_i^l = \textrm{Dec}^l (\textbf{D}_i^{l-1}, \textbf{M}_{n, -i}^{l-1}) \\ &\textrm{where} \; \textbf{M}_{n, -i}^l = \textrm{Cat}_N (\textbf{D}_1^l, \ldots, \textbf{D}_{i-1}^l, \textbf{D}_{i+1}^l, \ldots, \textbf{D}_n^l) \end{aligned}\](\(\textrm{Cat}_N\)은 시퀀스 차원으로의 이미지 토큰의 concat)
빠른 상대적 포즈 예측
DUSt3R에서는 $(I_1, I_2)$에서 예측한 \(\textbf{X}_{1,1}\)로 $I_1$의 intrinsic을 추정하고, $(I_2, I_1)$에서 예측한 \(\textbf{X}_{2,2}\)로 $I_2$의 intrinsic을 추정한다. 낮은 계산 비용으로 이러한 성능을 유지하는 멀티뷰 모델을 구축하여야 한다. 이를 위해 prediction head를 변경하여 추가적인 pointmap \(\textbf{X}_{i,i}\)도 함께 예측한다.
\[\begin{equation} (\textbf{X}_{i,1}, \textbf{X}_{i,i}, \textbf{C}_i) = \textrm{Head}^\textrm{3D} (\textbf{D}_i^L), \quad i \in \{1, \ldots, n\} \end{equation}\]이러한 변화를 통해, \(\textbf{X}_{i,i}\)와 \(\textbf{X}_{i,1}\) 사이의 변환을 Procrustes analysis을 통해 추정함으로써 $I_1$과 $I_i$ 사이의 상대적 포즈를 쉽게 복원할 수 있다. 이 방법은 PnP보다 더 간단하고 빠르며, PnP 방식과는 달리 초점 거리에 관계없이 계산할 수 있다.
3. Introducing Causality in MUSt3R
앞서 설명한 아키텍처를 기반으로 오프라인 또는 온라인에서 아무리 많은 이미지라도 효율적으로 처리할 수 있도록 반복적으로 업데이트되는 메모리를 모델에 부여하고, 추가 MLP를 통해 이전 레이어에 3D 피드백을 주입한다.
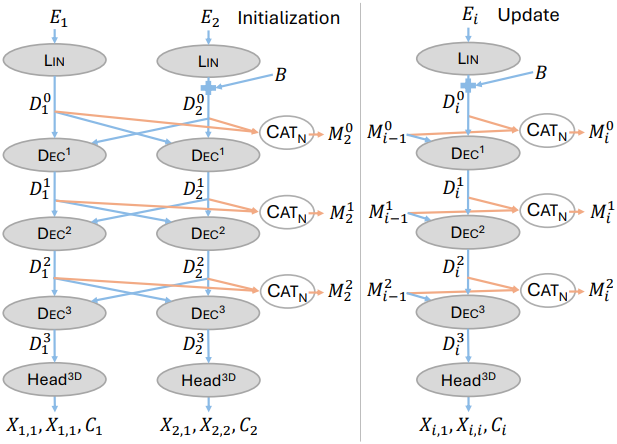
반복적인 메모리 업데이트
실제로 매우 큰 토큰 시퀀스에 대한 cross-attention은 계산적으로 어렵다. 게다가 VO와 같이 일부 시나리오에서는 이미지가 순차적으로 도착할 수 있다. 많은 수의 이미지를 처리하기 위해 Spann3R와 유사한 메모리를 사용하여 모델을 반복적으로 활용한다. Spann3R와는 달리, 이 메모리는 단순히 이전에 계산된 각 레이어의 \(\textbf{M}_n^l\)만 포함한다.
새로운 이미지 $I_{n+1}$이 들어오면 저장된 토큰과 cross-attention한다.
\[\begin{aligned} &\textbf{D}_{n+1}^l = \textrm{Dec}^l (\textbf{D}_{n+1}^{l-1}, \textbf{M}_n^{l-1}) \\ &\textrm{where} \; \textbf{M}_n^l = \textrm{Cat}_N (\textbf{D}_1^l, \ldots, \textbf{D}_n^l) \end{aligned}\]새 이미지의 feature \(\textbf{D}_{n+1}^l\)를 현재 메모리 \(\textbf{M}_n^l\)에 concat여 메모리를 \(\textbf{M}_{n+1}^l\)로 확장함으로써 메모리에 간단히 추가할 수 있다. 이 방법은 causal transformer inference의 KV cache와 비슷하다. 이전에 계산된 \(\textbf{D}_i^l\)을 모든 레이어에 캐싱함으로써 MUSt3R를 인과적으로 만든다. 모든 새 이미지는 이전에 본 이미지에 attention하지만, 이전에 본 이미지는 업데이트되지 않는다.
이 아키텍처를 사용하면 메모리에 새로운 토큰을 추가하지 않고도 이미지를 처리할 수 있다. 이 프로세스를 렌더링이라고 한다. 렌더링은 모델의 인과관계를 깨는 데, 즉 미래 프레임의 토큰을 고려하여 pointmap을 다시 계산하는 데 사용될 수 있다. 일반적으로 모든 이미지가 메모리에 있는 동영상 시퀀스가 끝날 때 렌더링을 수행한다. 프레임을 하나씩 순차적으로 처리하거나 $n$개씩 처리할 수 있으며, 순차적 예측이 일반적으로 더 나은 성능을 보인다.
글로벌 3D 피드백
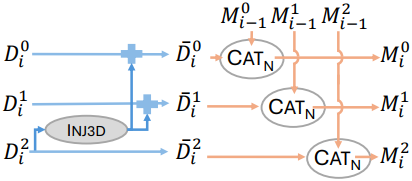
지금까지 제안된 방법은 최종 레이어의 메모리 토큰 \(\textbf{M}_n^l\)과 이전 레이어의 메모리 토큰 \(\textbf{M}_n^k (k < l)\) 사이의 피드백 메커니즘이 부족하다. 특히, \(\textbf{M}_i^0\)은 projection된 인코더 feature \(\textbf{D}_i^0\)의 concat일 뿐이며, 당연히 다른 프레임에 대한 정보가 없다.
합리적인 가정 중 하나는 최종 레이어의 토큰 표현이 이전 레이어의 토큰 표현보다 더 많은 글로벌 3D 정보를 포함한다는 것이다. 따라서 모든 레이어에 글로벌 3D 지식을 전파하기 위해 모든 메모리 토큰에 마지막 레이어 $l = L-1$의 정보를 추가한다. 이는 이전 프레임의 마지막 레이어에 이미 이 정보가 포함되어 있으므로 위에서 설명한 반복적 프레임워크에서 가능하다.
이전 이미지의 집합을 $\mathcal{P}$, 새 이미지의 집합을 $\mathcal{N}$이라 하면, \(\textbf{M}_n^l\)을
\[\begin{aligned} \textbf{M}_n^l &= \textrm{Cat}_N (\bar{\textbf{D}}_1^l, \ldots, \bar{\textbf{D}}_n^l) \\ \bar{\textbf{D}}_i^l &= \begin{cases} \textbf{D}_i^l + \textrm{Inj}^\textrm{3D} (\textbf{D}_i^{L-1}) & \forall l < L-1 \; \textrm{and} \; i \in \mathcal{P} \\ \textbf{D}_i^l & l = L-1 \; \textrm{or} \; i \in \mathcal{N} \end{cases} \end{aligned}\]로 augmentation한다. \(\textrm{Inj}^\textrm{3D}\)는 Layer Norm과 2-layer MLP가 이어지는 구조이다.
4. Memory Management
메모리가 이미지 수에 따라 선형적으로 증가하기 때문에 대용량 이미지 컬렉션의 경우 연산 문제가 발생할 수 있다. 이를 완화하기 위해 메모리 토큰을 휴리스틱 방식으로 선택한다. 두 가지 시나리오를 구분한다.
- 온라인: 동영상 스트림의 프레임이 하나씩 들어오는 시나리오
- 오프라인: 순서가 지정되지 않은 이미지 컬렉션을 재구성하는 시나리오
모든 경우에서 동일한 네트워크를 사용한다.
온라인
동영상의 경우, 실행 중인 메모리와 현재 관측값의 3D 장면을 활용하며, 이는 실시간으로 업데이트된다. 메모리와 장면은 첫 번째 이미지의 예측을 기반으로 초기화된다. 그런 다음, 현재 메모리를 처리하는 모든 들어오는 프레임을 MUSt3R를 통해 전달한다. 이를 통해 보이는 dense한 형상과 카메라 파라미터를 모두 예측한다. 예측된 pointmap \(\textbf{X}_{i,1}\)과 현재 장면 사이의 공간적 발견률을 기반으로 현재 예측을 유지할지 결정한다. 즉, 장면에서 상당히 새로운 부분을 관찰하거나, 충분히 다른 시점에서 관찰했을 경우에만 해당 프레임을 유지한다.
이를 위해 장면을 KDTrees의 집합으로 저장한다. 트리를 구축하거나 쿼리할 때 각 3D 포인트는 관찰의 뷰 방향에 따라 인덱스로 트리에 연결된다. 이는 뷰 방향의 구면을 regular octant로 분할하여 수행된다. 각 픽셀의 뷰 방향을 구면 좌표에서 discretize하여 관련 octant의 인덱스에 매핑한다. 따라서 각 픽셀은 특정 트리에 매핑된 다음 현재 장면까지의 가장 가까운 거리를 복구하는 데 사용된다. 이 거리는 이 픽셀의 깊이로 정규화된다. 프레임의 발견률은 단순히 정규화된 거리의 $p$번째 백분위수이다. 발견률이 주어진 threshold \(\tau_d\)보다 높으면, 즉 들어오는 프레임이 충분히 새 영역을 관찰하면 프레임을 메모리에 추가하고 3D 포인트와 뷰 방향을 현재 3D 장면에 추가한다. 이 접근 방식은 각 뷰가 과거 프레임만 보기 때문에 순전히 인과적이지만, 모든 이미지를 다시 렌더링하여 인과관계를 끊을 수 있다.
오프라인
MASt3R-SfM에서 영감을 얻어, 모든 이미지 $I_i$의 인코더 feature \(\textbf{E}_i\)를 사용하는 ASMK (Aggregated Selective Match Kernels) 이미지 검색 방법을 사용한다. 먼저 farthest point sampling 방법을 따라 고정된 수의 키프레임을 선택한다. 문제는 이미지의 적절한 순서를 찾는 것이다. 따라서 다른 이미지와 가장 많이 연결된 키프레임부터 시작하여 greedy하게 가장 높은 유사도 순서대로 다른 이미지를 현재 뷰 세트에 반복적으로 추가한다. 이러한 키프레임은 네트워크를 통해 순차적으로 전달되어 전체 장면의 latent 표현을 구축한다. 그런 다음 이 메모리에서 모든 이미지를 렌더링한다.
Training
쌍을 이용한 MUSt3R 사전 학습
DUSt3R와 유사하게 MUSt3R를 여러 단계로 학습한다. 먼저, metric 예측을 위한 단순화된 아키텍처를 학습시킨다. 본 시나리오에서는 대규모 장면에서 멀리 떨어져 있을 수 있는 점들을 예측하는 것을 목표로 한다. 멀리 떨어진 점에 대한 더 나은 수렴 및 성능을 위해 로그 공간에서 계산한다.
\[\begin{aligned} & \ell_\textrm{regr} (i,j) = \sum_{p \in I_i} \| f (\frac{1}{z} \textbf{X}_{i,j} [p]) - f (\frac{1}{\hat{z}} \hat{\textbf{X}}_{i,j} [p]) \\ & \textrm{where} \; f(x) = \frac{x}{\| x \|} \log (1 + \| x \|) \\ \end{aligned}\]CroCo v2 ($L = 12$)에서 초기화된 linear head를 사용하여 224 해상도 이미지에서 모델 학습을 시작한다. 그런 다음, 512 해상도로 fine-tuning한다. 모델은 Habitat, ARKitScenes, Blended MVS, MegaDepth, Static Scenes 3D, ScanNet++, CO3D-v2, Mapfree, WildRGB-D, Virtual KITTI, Unreal4K, DL3DV, TartanAir, 내부 데이터셋 등 14개의 데이터셋를 혼합하여 학습된다.
MUSt3R 학습
그런 다음, 여러 뷰를 갖는 MUSt3R를 학습시킨다. 실험에서는 장면당 총 $N = 10$개의 이미지를 사용하였다. 이미지 시퀀스를 처리하기 위해 인코더를 고정시키고 xformers를 사용하여 attention을 효율적으로 계산한다. 모델은 Virtual KITTI와 Static Scenes 3D를 제외한 12개의 데이터셋으로 학습된다. 학습 과정에서 메모리는 두 이미지에서 초기화된 후, 개별 이미지에서 업데이트된다. 학습 loss는 두 단계로 나뉜다.
- 무작위로 선택된 $2 \le n \le N$개의 뷰에 대한 pointmap을 예측하고 latent 임베딩을 사용하여 메모리를 채운다.
- 이 메모리에서 $n$개의 메모리 프레임을 포함한 모든 뷰를 렌더링한다. 즉, 최종적으로 $n+N$개의 예측을 얻는다.
따라서 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \sum_{i=1}^{n+N} \ell_\textrm{regr} (i,1) + \ell_\textrm{regr} (i,i) \end{equation}\]Robustness를 높이고 중복성을 높이기 위해 토큰 dropout을 사용하여 학습을 강화한다. 첫 번째 이미지 $I_1$의 메모리 토큰은 DUSt3R와 유사하게 첫 번째 카메라의 좌표에 3D 포인트가 표현되는 데 특정 역할을 하므로 보호된다. 토큰 dropout은 현재 메모리에서 각 들어오는 프레임마다 수행되며, 모든 레이어에서 일관되게 적용된다. 따라서 토큰이 제거되면 어떤 레이어에도 나타나지 않는다. 224와 512 해상도에 대해 각각 0.05와 0.15의 dropout 확률을 사용한다.
Experiments
1. Uncalibrated Visual Odometry
다음은 TUM RGB에 대한 VO 결과이다. (ATE RMSE [cm])
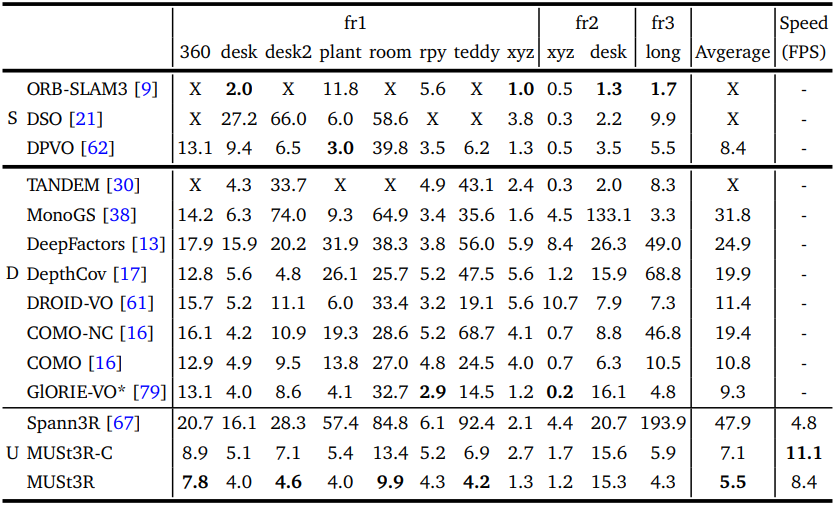
다음은 TUM RGBD에서의 tracking 정확도를 비교한 표이다.

다음은 TUM RGBD에서 수직 FOV 오차를 Spann3R와 비교한 결과이다.

다음은 TUM RGBD에서의 스케일 추정 오차이다.

다음은 ETH3D에서의 SLAM tracking 정확도를 비교한 표이다.

2. Relative pose estimation
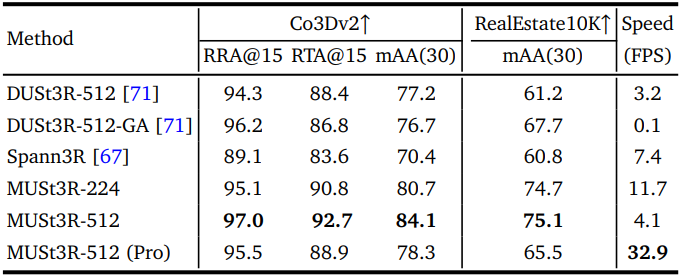
다음은 멀티뷰 포즈 추정 결과이다.
3. 3D Reconstruction
다음은 Spann3R와의 비교 결과이다.

4. Multi-view depth evaluation
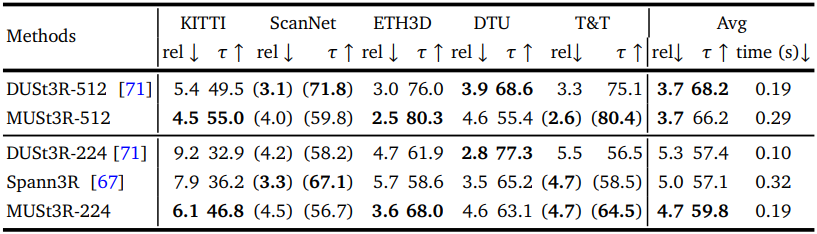
다음은 포즈나 intrinsic 없이 멀티뷰로 깊이를 추정한 결과이다.
Limitations
뷰가 첫 번째 뷰에서 너무 멀리 벗어나는 시퀀스에 대해서는 한계를 보인다.