[논문리뷰] MusicLM: Generating Music From Text
arXiv 2023. [Paper] [Page] [Dataset]
Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G. Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, Lu Jiang
Google Research | Sorbonne University
26 Jan 2023
Introduction
조건부 오디오 생성은 TTS에서 가사 조건 음악 생성과 MIDI 시퀀스의 오디오 합성에 이르기까지 광범위한 애플리케이션을 포괄한다. 이러한 task들은 컨디셔닝 신호와 해당 오디오 출력 사이의 일정 수준의 시간적 정렬에 의해 촉진된다. 대조적으로, text-to-image 생성의 발전에 영감을 받은 최근 연구들에서는 “바람이 부는 휘파람”과 같은 시퀀스 전체의 높은 수준의 캡션에서 오디오를 생성하는 방법을 탐구했다. 이러한 대략적인 캡션에서 오디오를 생성하는 것은 돌파구를 나타내지만 이러한 모델은 몇 초 동안 몇 개의 음향 이벤트로 구성된 단순한 음향 장면으로 제한된다. 따라서 단일 텍스트 캡션을 음악 클립과 같이 장기 구조와 많은 줄기를 가진 풍부한 오디오 시퀀스로 변환하는 것은 여전히 어려운 과제로 남아 있다.
최근 AudioLM은 오디오 생성을 위한 프레임워크로 제안되었다. 이산 표현 공간에서 언어 모델링 task로 오디오 합성을 캐스팅하고 coarse-to-fine 오디오 이산 단위 (또는 토큰)의 계층 구조를 활용하는 AudioLM은 수십 초 동안 높은 충실도와 장기적인 일관성을 모두 달성한다. 또한 오디오 신호의 내용에 대해 가정하지 않음으로써 AudioLM은 주석 없이 음성 또는 피아노 음악과 같은 오디오만 있는 코퍼스에서 사실적인 오디오를 생성하는 방법을 학습한다. 다양한 신호를 모델링할 수 있는 능력은 이러한 시스템이 적절한 데이터에 대해 학습된 경우 더 풍부한 출력을 생성할 수 있음을 시사한다.
고품질의 일관된 오디오를 합성하는 데 내재된 어려움 외에도 또 다른 방해 요소는 쌍을 이룬 오디오-텍스트 데이터의 부족이다. 이는 이미지 도메인과 극명한 대조를 이룬다. 방대한 데이터셋의 가용성이 최근 달성된 놀라운 이미지 생성 품질에 크게 기여했다. 게다가 일반적인 오디오에 대한 텍스트 설명을 만드는 것은 이미지를 설명하는 것보다 훨씬 어렵다. 첫째, 음향적 장면 (ex. 기차역이나 숲에서 들리는 소리)이나 음악 (ex. 멜로디, 리듬, 음색 보컬, 반주에 사용되는 많은 악기)의 두드러진 특성을 단 몇 마디로 명확하게 포착하는 것은 간단하지 않다. 둘째, 오디오는 시퀀스 전체 캡션을 이미지 캡션보다 훨씬 약한 수준의 주석으로 만드는 시간적 차원을 따라 구조화된다.
본 논문에서는 텍스트 설명에서 고충실도 음악을 생성하는 모델인 MusicLM을 소개한다. MusicLM은 AudioLM의 다단계 autoregressive 모델링을 생성 구성 요소로 활용하는 동시에 텍스트 조건을 통합하도록 확장한다. 쌍을 이룬 데이터 부족이라는 주요 문제를 해결하기 위해 임베딩 공간에서 서로 가까운 표현에 음악과 해당 텍스트 설명을 project하도록 학습된 공동 음악 텍스트 모델인 MuLan에 의존한다. 이 공유 임베딩 공간은 학습 시간에 캡션이 필요하지 않으며 대규모 오디오만 있는 코퍼스에 대한 학습을 허용한다. 즉, 학습 중에는 오디오에서 계산된 MuLan 임베딩을 컨디셔닝으로 사용하고 inference 중에는 텍스트 입력에서 계산된 MuLan 임베딩을 사용한다.
레이블이 지정되지 않은 대규모 음악 데이터셋에서 학습할 때 MusicLM은 “기억에 남는 색소폰 솔로와 솔로 가수가 있는 황홀한 재즈 노래” 또는 “낮은 베이스와 강한 킥의 베를린 90년대 테크노”와 같이 상당히 복잡한 텍스트 설명을 위해 24kHz에서 길고 일관된 음악을 생성하는 방법을 학습한다. 이 task에 대한 평가 데이터의 부족을 해결하기 위해 전문 음악가가 준비한 5500개의 예제가 포함된 새로운 고품질 음악 캡션 데이터셋인 MusicCaps를 도입하며, 향후 연구를 지원하기 위해 공개하였다.
본 논문의 실험은 MusicLM이 Mubert나 Riffusion과 같은 이전 시스템보다 품질과 캡션 준수 측면에서 우수한 성능을 보인다는 것을 보여준다. 또한 음악의 일부 측면을 단어로 설명하는 것은 어렵거나 불가능할 수 있으므로 본 논문의 방법이 텍스트 이외의 조건 신호를 지원하는 방법을 보여준다. 구체적으로, 텍스트 프롬프트에 설명된 스타일로 렌더링된 원하는 멜로디를 따르는 음악 클립을 생성하기 위한 조건으로 오디오 형식의 추가 멜로디를 허용하도록 MusicLM을 확장한다.
Method
1. Representation and Tokenization of Audio and Text

조건부 autoregressive 음악 생성에 사용할 오디오 표현을 추출하기 위해 세 가지 모델을 사용한다 (위 그림 참조). 특히 AudioLM의 접근 방식을 따라 SoundStream의 self-supervised 오디오 표현을 acoustic token으로 사용하여 활성화한다. 고충실도 합성과 w2v-BERT를 semantic token으로 사용하여 장기간 일관된 생성을 촉진한다. 컨디셔닝을 표현하기 위해 학습 중에는 MuLan 음악 임베딩에 의존하고 inference 시에는 MuLan 텍스트 임베딩에 의존한다. 이 세 가지 모델은 모두 독립적으로 사전 학습된 다음 고정되어 시퀀스 간 모델링을 위한 이산 오디오 및 텍스트 표현을 제공한다.
SoundStream
24kHz 모노 오디오용 SoundStream 모델을 480의 striding factor로 사용하여 50Hz 임베딩을 생성한다. 이러한 임베딩의 quantization은 각 vocabulary 크기가 1024인 12개의 quantizer가 있는 RVQ에 의해 학습된다. 그 결과 비트레이트는 6kbps이며 여기서 오디오의 1초는 600개의 토큰으로 표현된다. 이를 acoustic token $A$라고 한다.
w2v-BERT
AudioLM과 유사하게 파라미터가 6억 개인 w2v-BERT 모델의 masked-language-modeling (MLM) 모듈의 중간 레이어를 사용한다. 모델을 사전 학습하고 고정한 후 7번째 레이어에서 임베딩을 추출하고 임베딩에 대해 학습된 k-mean의 중심을 사용하여 quantize한다. 1024개의 클러스터와 25Hz의 샘플링 속도를 사용하여 매초당 25개의 오디오의 semantic token $S$를 생성한다.
MuLan
MusicLM을 학습하기 위해 MuLan의 오디오 임베딩 네트워크에서 타겟 오디오 시퀀스의 표현을 추출한다. 이 표현은 연속적이며 Transformer 기반 autoregressive 모델에서 컨디셔닝 신호로 직접 사용될 수 있다. 그러나 오디오와 컨디셔닝 신호가 이산 토큰을 기반으로 균질한 표현을 갖는 방식으로 MuLan 임베딩을 quantize하도록 선택하여 컨디셔닝 신호를 autoregressive 모델링하는 향후 연구를 돕는다.
MuLan은 10초 오디오 입력에서 작동하고 더 긴 오디오 시퀀스를 처리해야 하므로 1초 stride로 10초 window에서 오디오 임베딩을 계산하고 결과 임베딩의 평균을 낸다. 그런 다음 각각 vocabulary 크기가 1024인 12개의 vector quantizer로 RVQ를 적용하여 결과 임베딩을 discretize한다. 이 프로세스는 오디오 시퀀스에 대해 12개의 MuLan 오디오 토큰 $M_A$를 생성한다. Inference하는 동안 텍스트 프롬프트에서 추출한 MuLan 텍스트 임베딩을 컨디셔닝으로 사용하고 오디오 임베딩에 사용된 것과 동일한 RVQ로 quantize하여 12개의 토큰 $M_T$를 얻는다.
학습 중 $M_A$에 대한 컨디셔닝에는 두 가지 주요 이점이 있다.
- 텍스트 캡션의 필요성에 제한을 받지 않기 때문에 학습 데이터를 쉽게 확장할 수 있다.
- Contrastive loss을 사용하여 학습된 MuLan과 같은 모델을 활용하여 잡음이 많은 텍스트 설명에 대한 견고성을 높인다.
Hierarchical Modeling of Audio Representations
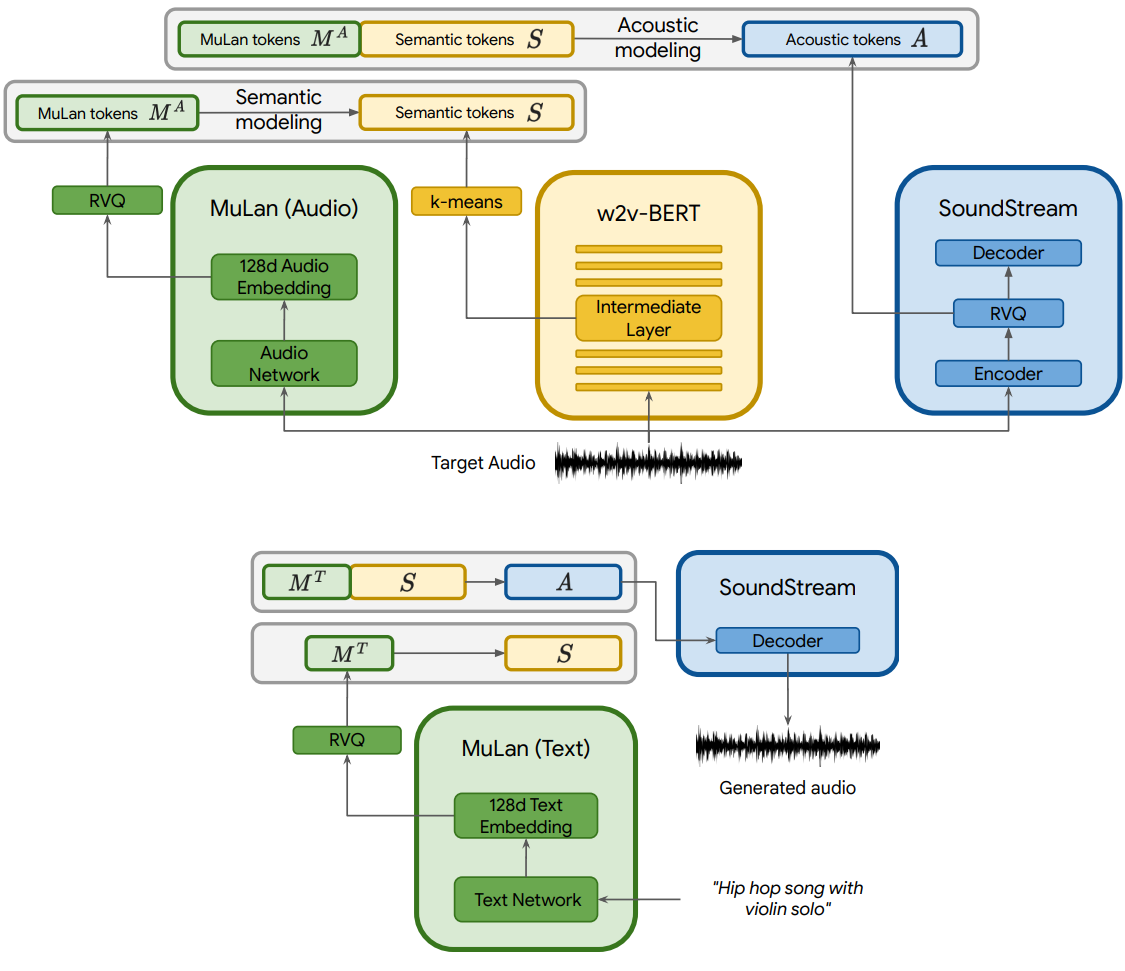
위에 제시된 이산 오디오 표현을 AudioLM과 결합하여 텍스트 조건부 음악 생성을 달성한다. 이를 위해 각 단계가 별도의 디코더만 있는 Transformer에 의해 autoregressive하게 모델링되는 계층적 sequence-to-sequence 모델링 task를 제안한다. 제안된 접근 방식은 위 그림에 설명되어 있다.
첫 번째 단계는 분포 $p(S_t \vert S_{< t}, M_A)$를 모델링하여 MuLan 오디오 토큰에서 semantic token $S$로의 매핑을 학습하는 semantic 모델링 단계이다. 여기서 $t$는 timestep에 해당하는 시퀀스의 위치이다. 두 번째 단계는 acoustic 모델링 단계로 acoustic token $A_q$는 MuLan 오디오 토큰과 semantic token 모두로 컨디셔닝 되어 예측되며 분포 $p(A_t \vert A_{< t}, S, M_A)$를 모델링한다.
특히, AudioLM은 긴 토큰 시퀀스를 피하기 위해 acoustic 모델링 단계를 대략적인 모델링 단계와 세밀한 모델링 단계로 추가로 분할한다. MusicLM은 동일한 접근 방식을 사용한다. 여기서 대략적인 모델링 단계는 SoundStream RVQ 출력의 처음 4개 레벨을 모델링하고 세밀한 모델링 단계는 나머지 8개 레벨을 모델링한다.
Results
- 데이터셋
- Free Music Archive (FMA): SoundStream과 w2v-BERT 학습에 사용
- 모델
- semantic 단계: 디코더만 있는 Transformer
- acoustic 단계: AudioLM
- 두 모델 모두 동일한 아키텍처
- 레이어 수: 24
- attention head 수: 16
- 임베딩 차원: 1024
- feed-forward layer 차원: 4096
- dropout: 0.1
- relative positional embedding 사용
- 파라미터 수: 4.3억
- Inference
- temperature
- semantic 단계: 1.0
- 대략적인 acoustic 단계: 0.95
- 세밀한 acoustic 단계: 0.4
- temperature
- Metrics
- Frechet Audio Distance (FAD)
- KL Divergence (KLD)
- MuLan Cycle Consistency (MCC)
MusicCaps
저자들은 MusicLM을 평가하기 위해 고품질 음악 캡션 데이터셋인 MusicCaps를 공개하였다. 이 데이터셋에는 AudioSet의 5500개의 음악 클립이 포함되어 있으며 각 클립은 10명의 전문 음악가가 작성한 해당 영어 텍스트 설명과 쌍을 이룬다. MusicCaps는 각 10초 길이의 음악 클립에 대해 다음을 제공한다.
- 음악을 설명하는 평균 4개의 문장으로 구성된 자유 텍스트 캡션
- 장르, 분위기, 템포, 가수 음성, 악기, 불협화음, 리듬 등을 설명하는 음악 aspect의 목록
평균적으로 데이터셋에는 클립당 11개의 aspect가 포함된다.
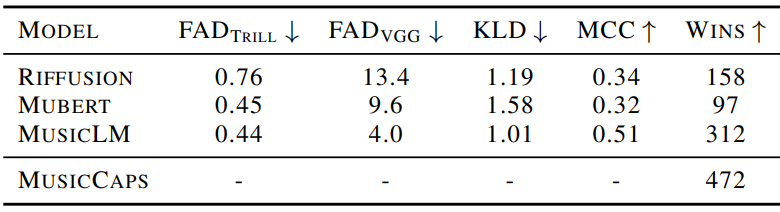
Baseline과의 비교
다음은 MusicCaps 데이터셋의 캡션을 사용하여 생성된 샘플을 평가한 표이다.
Semantic token의 중요성
Acoustic 모델링에서 semantic 모델링을 분리하는 유용성을 이해하기 위해 $p(A_t \vert A_{< t}, M_A)$를 모델링하여 MuLan 토큰에서 대략적인 acoustic token을 직접 예측하는 Transformer 모델을 학습한다. FAD는 비슷하지만 KLD와 MCC는 semantic 모델링 단계를 제거할 때 악화된다. 특히 KLD는 1.01에서 1.05로 증가하고 MCC는 0.51에서 0.49로 감소하여 semantic token이 텍스트 설명 준수를 용이하게 함을 나타낸다. 또한 장기 구조의 열화가 관찰된다.
오디오 토큰으로 표현되는 정보
저자들은 semantic token과 acoustic token에 의해 캡처된 정보를 연구하기 위해 추가 실험을 수행하였다. 첫 번째 연구에서는 MuLan 텍스트 토큰과 semantic token을 수정하여 acoustic 모델링 단계를 여러 번 실행하여 여러 샘플을 생성하였다. 이 경우 생성된 음악을 들어보면 샘플이 다양하지만 동일한 장르, 리듬 속성 (ex. 드럼), 메인 멜로디의 일부를 공유하는 경향이 있음을 관찰할 수 있다. 그것들은 특정 acoustic 속성 (ex. 리버브 레벨, 왜곡) 측면에서 다르며 경우에 따라 유사한 피치 범위를 가진 다른 악기가 다른 예에서 합성될 수 있다.
두 번째 연구에서는 MuLan 텍스트 토큰만 수정하고 semantic token과 acoustic token을 모두 생성한다. 이 경우 멜로디와 리듬 속성 측면에서 훨씬 더 높은 수준의 다양성을 관찰할 수 있으며 여전히 텍스트 설명과 일관성이 있다. 첨부된 자료에서 이 연구의 샘플을 제공한다.
Memorization 분석
다음은 semantic token 프롬프트의 길이가 0초에서 10초 사이로 변할 때 정확한 일치 결과와 대략적인 일치 (\tau = 0.85) 결과를 나타낸 그래프이다.
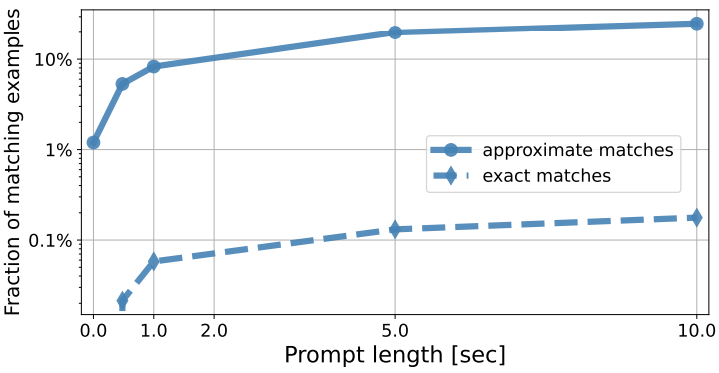
정확히 일치하는 비율은 10초 프롬프트를 사용하여 5초의 연속을 생성하는 경우에도 항상 매우 작게 (< 0.2%) 남아 있다. MuLan 토큰만 입력으로 사용하고 (프롬프트 길이 $T = 0$) 프롬프트 길이가 증가함에 따라 일치하는 예제의 비율이 증가하는 경우에도 이 방법론으로 더 많은 수의 일치 항목이 감지되는 것을 볼 수 있다. 일치 점수가 가장 낮은 항목이 낮은 수준의 토큰 다양성을 특징으로 하는 시퀀스에 해당한다. 즉, 125개의 semantic token 샘플의 평균 엔트로피는 4.6비트인 반면, 일치 점수가 0.5 미만인 대략적인 일치로 감지된 시퀀스를 고려할 때 1.0비트로 떨어진다. 두 번째 단계에서 수행되는 acoustic 모델링은 semantic token이 정확히 일치하는 경우에도 생성된 샘플에 더 많은 다양성을 도입한다.