[논문리뷰] Muse: Text-To-Image Generation via Masked Generative Transformers
arXiv 2023. [Paper] [Page] [Github]
Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T. Freeman, Michael Rubinstein, Yuanzhen Li, Dilip Krishnan
Google Research
2 Jan 2023

Introduction
텍스트 프롬프트를 조건으로 하는 생성 이미지 모델은 지난 몇 년 동안 품질과 유연성 면에서 엄청난 도약을 이루었다. 이는 딥러닝 아키텍처 혁신, 언어 및 비전 task 모두에 대한 마스크 모델링과 같은 새로운 학습 패러다임, diffusion과 마스킹 기반 생성과 같은 새로운 생성 모델 클래스, 대규모 이미지-텍스트 쌍 데이터셋의 가용성의 조합으로 가능했다.
본 논문에서는 masked image modeling 접근 방식을 사용하여 text-to-image 합성을 위한 새로운 모델을 제시한다. 이미지 디코더 아키텍처는 사전 학습되고 고정된 T5-XXL LLM (large language model) 인코더의 임베딩을 기반으로 한다. 사전 학습된 LLM에 대한 컨디셔닝은 사실적인 고품질 이미지 생성에 중요하다. VQGAN quantizer를 제외한 본 논문의 모델은 Transformer 아키텍처를 기반으로 한다.
저자들은 파라미터 6.32억 개에서 30억개 범위의 Muse 모델 시퀀스를 학습시켰다. 각 모델은 여러 하위 모델로 구성된다. 먼저 한 쌍의 VQGAN “tokenizer” 모델이 있다. 이 모델은 입력 이미지를 개별 토큰 시퀀스로 인코딩하고 토큰 시퀀스를 다시 이미지로 디코딩할 수 있다. 두 개의 VQGAN을 사용하며, 하나는 256$\times$256 해상도 (“low-res”)이고 다른 하나는 512$\times$512 해상도 (“high-res”)이다. 둘째, 파라미터의 대부분을 포함하는 기본 masked image model이 있다. 이 모델은 부분적으로 마스킹된 저해상도 토큰 시퀀스를 사용하고 마스킹되지 않은 토큰과 T5-XXL 텍스트 임베딩을 조건으로 하여 마스킹된 각 토큰의 주변 분포를 예측한다. 셋째, 저해상도 토큰을 고해상도 토큰으로 변환하는 “super-res” transformer 모델이 있다.
계단식 pixel-space diffusion model을 기반으로 구축된 Imagen 또는 Dall-E2와 비교할 때 Muse는 개별 토큰을 사용하기 때문에 훨씬 더 효율적이다. 흡수 상태 [MASK]를 갖는 discrete diffusion process로 생각할 수 있다. SOTA autoregressive model인 Parti에 비해 Muse는 병렬 디코딩을 사용하기 때문에 더 효율적이다. 유사한 하드웨어 (TPU-v4 칩)에 대한 비교를 바탕으로 Muse는 Imagen-3B 또는 Parti-3B 모델보다 inference 시간이 10배 이상 빠르고 Stable Diffusion v1.4보다 3배 빠르다. 이러한 모든 비교는 동일한 크기의 이미지일 때이다. 두 모델 모두 VQGAN의 latent space에서 작동함에도 불구하고 Muse는 Stable Diffusion v1.4보다 빠르며, 이는 Stable Diffusion이 inference 시간에 훨씬 더 많은 반복이 필요하기 때문이다.
Model
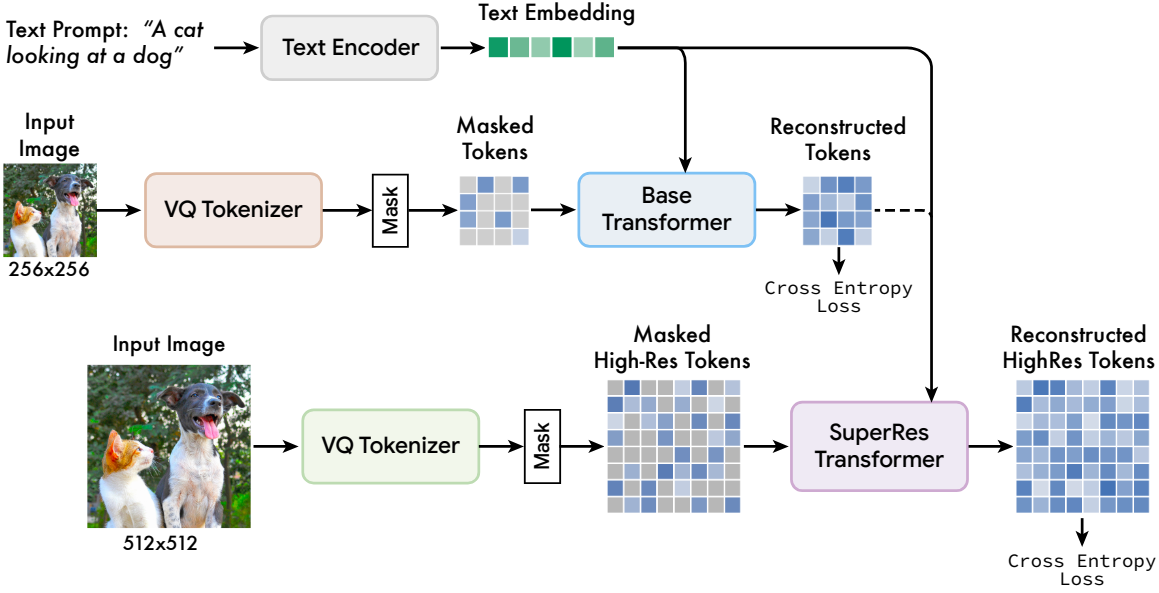
Muse는 여러 구성 요소를 기반으로 한다. 모델 아키텍처의 개요는 위 그림과 같다.
1. Pre-trained Text Encoders
사전 학습된 LLM을 활용하는 것은 고품질 이미지 생성에 도움이 된다. T5-XXL과 같은 LLM에서 추출된 임베딩은 개체 (명사), 동작 (동사), 시각적 속성 (형용사), 공간 관계 (전치사), 기타 속성에 대한 풍부한 정보를 전달한다. 저자들의 가설은 Muse 모델이 LLM 임베딩의 이러한 풍부한 시각적 및 semantic 개념을 생성된 이미지에 매핑하는 방법을 학습한다는 것이다. 최근 연구에서 LLM이 학습한 개념적 표현은 비전 task에 대해 학습된 모델이 학습한 개념적 표현에 대략 선형적으로 매핑할 수 있음이 나타났다. 입력 텍스트 캡션이 주어지면 고정된 T5-XXL 인코더를 통과하여 4096차원 언어 임베딩 벡터 시퀀스가 생성된다. 이러한 임베딩 벡터는 Transformer 모델 (base, super-res)의 hidden size에 선형으로 project된다.
2. Semantic Tokenization using VQGAN
모델의 핵심 구성 요소는 VQGAN 모델에서 얻은 semantic 토큰을 사용하는 것이다. 이 모델은 학습된 코드북의 토큰 시퀀스에 입력 이미지를 매핑하는 quantization layer와 함께 인코더와 디코더로 구성된다. 다양한 해상도의 이미지 인코딩을 지원하기 위해 인코더와 디코더를 convolutional layer로 완전히 구축한다. 인코더에는 입력의 공간 차원을 줄이기 위한 여러 개의 다운샘플링 블록이 있는 반면, 디코더에는 latent 이미지를 다시 원래 이미지 크기로 매핑하기 위한 같은 개수의 업샘플링 블록이 있다.
크기가 $H \times W$인 이미지가 주어지면 인코딩된 토큰의 크기는 $H/f \times W/f$이고 다운샘플링 비율은 $f$이다. 두 개의 VQGAN 모델을 학습시키며, 하나는 다운샘플링 비율이 $f = 16$이고 다른 하나는 다운샘플링 비율이 $f = 8$이다. 256$\times$256 픽셀 이미지에서 $f = 16$ VQGAN 모델을 사용하여 base model에 대한 토큰을 얻으므로 공간 크기가 16$\times$16인 토큰이 생성된다. 또한 512$\times$512 이미지에서 $f = 8$ VQGAN 모델을 사용하여 super-resolution 모델에 대한 토큰을 얻으며, 해당 토큰의 공간 크기는 64$\times$64이다. 인코딩 후, 결과 이산 토큰은 이미지의 더 높은 수준의 semantic을 캡처하는 반면 낮은 레벨의 noise를 무시한다. 또한 이러한 토큰의 이산적 특성으로 인해 출력에서 cross-entropy loss를 사용하여 다음 단계에서 마스킹된 토큰을 예측할 수 있다.
3. Base Model
Base model은 masked transformer이며, 입력이 project된 T5 임베딩과 이미지 토큰이다. 모든 텍스트 임베딩을 마스킹하지 않은 상태로 두고 이미지 토큰의 다양한 부분을 무작위로 마스킹하고 특수 토큰 [MASK]로 대체한다. 그런 다음 학습된 2D 위치 임베딩과 함께 필요한 크기의 이미지 입력 임베딩에 이미지 토큰을 선형 매핑한다. 기존 transformer 아키텍처에 따라 self-attention 블록, cross-attention 블록, MLP 블록을 포함한 여러 transformer 레이어를 사용하여 feature를 추출한다. 출력 레이어에서 MLP를 사용하여 각 마스킹된 이미지 임베딩을 logit의 집합 (VQGAN 코드북 크기에 해당)로 변환하고 ground-truth 토큰 레이블을 대상으로 cross-entropy loss를 적용한다. 학습 시 base model은 각 단계에서 모든 마스킹된 토큰을 예측하도록 학습된다. 그러나 inference를 위해 마스크 예측은 품질을 크게 향상시키는 반복적인 방식으로 수행된다.
4. Super-Resolution Model
512$\times$512 해상도를 직접 예측하면 모델이 큰 규모의 semantic보다 낮은 수준의 디테일에 집중하게 된다. 결과적으로 일련의 모델을 사용하는 것이 유익하다. 먼저 base model로 16$\times$16 latent map (256$\times$256 이미지에 해당)을 생성한 후, super-resolution model로 base latent map을 64$\times$64 latent map (512$\times$512 이미지에 해당)으로 업샘플링한다. Super-resolution model은 base model이 학습된 후에 학습된다.
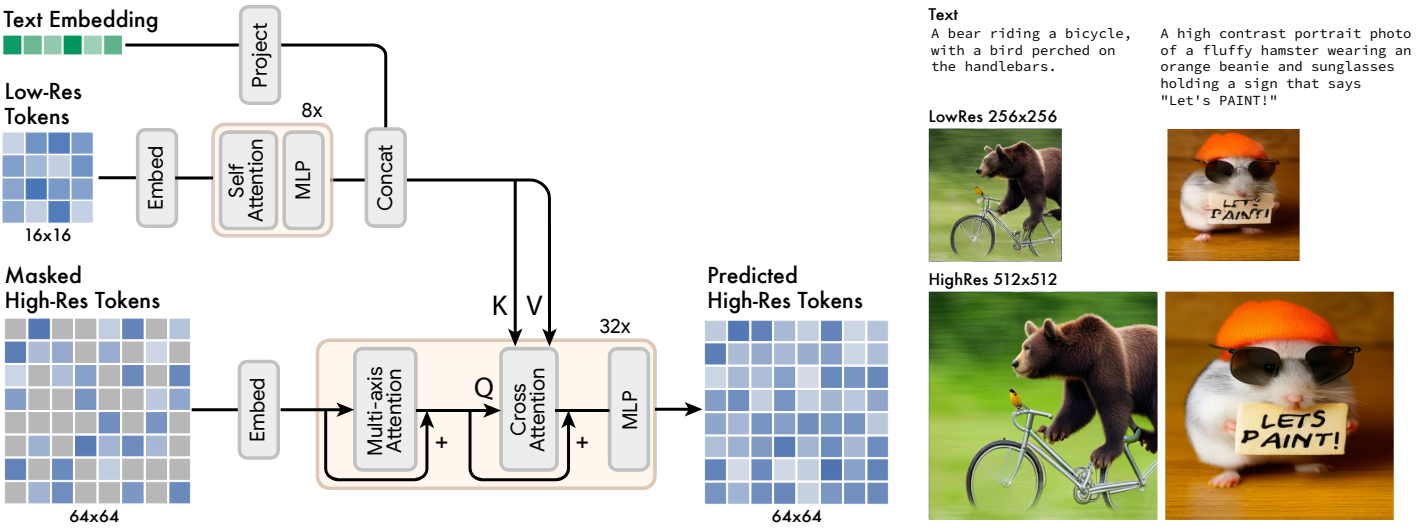
저자들은 두 개의 VQGAN 모델을 학습하였으며, 하나는 16$\times$16 latent 해상도와 256$\times$56 공간 해상도에서, 다른 하나는 64$\times$64 latent 해상도와 512$\times$512 공간 해상도에서 학습했다. Base model이 16$\times$16 latent map에 해당하는 토큰을 출력하기 때문에 super-resolution 절차는 저해상도 latent map을 고해상도 latent map으로 변환하는 방법을 학습한 다음 고해상도 VQGAN을 통해 디코딩하여 최종 고해상도 이미지를 제공한다. 이 latent map 변환 모델은 위 그림과 같이 base model과 유사한 방식으로 텍스트 컨디셔닝과 cross-attention을 통해 학습된다.
5. Decoder Finetuning
세밀한 디테일을 생성하는 모델의 능력을 더욱 향상시키기 위해 인코더 용량을 고정하면서 더 많은 residual layer와 채널을 추가하여 VQGAN 디코더의 용량을 늘린다. 그런 다음 VQGAN 인코더 가중치, 코드북, transformer들을 고정된 상태로 유지하면서 새로운 디코더 레이어를 fine-tuning한다. 이를 통해 다른 모델 구성 요소를 재학습하지 않고도 시각적 품질을 향상시킬 수 있다. 이는 시각적 토큰 “언어”가 고정된 상태로 유지되기 때문이다.
6. Variable Masking Rate
코사인 스케줄링을 기반으로 가변 마스킹 비율로 모델을 학습시킨다. 각 학습 예제에 대해 밀도 함수
\[\begin{equation} p(r) = \frac{2}{\pi} (1 − r^2)^{-\frac{1}{2}} \end{equation}\]을 사용하여 절단된 arccos 분포에서 마스킹 비율 $r \in [0, 1]$을 샘플링한다. 이것은 0.64의 마스킹 비율 기대값을 가지며 더 높은 마스킹 비율에 대한 강한 편향이 있다. 더 높은 마스킹 비율에 대한 편향은 예측 문제를 더 어렵게 만든다. 일부 고정된 토큰 순서에 대해 조건부 분포 $P(x_i \vert x_{< i})$를 학습하는 autoregressive 방식과 달리, 가변 마스킹 비율을 사용한 랜덤 마스킹을 통해 모델은 토큰 $\Lambda$의 임의의 부분 집합에 대해 $P(x_i \vert x_{\Lambda})$를 학습할 수 있다. 이것은 병렬 샘플링 체계에 중요할 뿐만 아니라 많은 zero-shot, 즉시 사용 가능한 편집을 가능하게 한다.
7. Classifier Free Guidance
생성 품질과 텍스트 이미지 정렬을 개선하기 위해 classifier-free guidance (CFG)를 사용한다. 학습 시에 무작위로 선택된 샘플의 10%에서 텍스트 조건을 제거한다. 따라서 attention이 이미지 토큰 self-attention으로 감소된다. inference 시 각 마스킹된 토큰에 대해 조건부 logit $\ell_c$와 unconditional logit $\ell_u$를 계산한다. 그런 다음 $\ell_u$에서 guidance scale $t$만큼 이동시켜 최종 logit $\ell_g$를 형성한다.
\[\begin{equation} \ell_g = (1 + t) \ell_c - t \ell_u \end{equation}\]직관적으로 CFG는 충실도를 위해 다양성을 절충한다. 이전 접근 방식과 달리 샘플링 절차를 통해 guidance scale $t$를 선형적으로 증가시켜 다양성에 대한 타격을 줄인다. 이렇게 하면 guidance가 낮거나 없는 상태에서 초기 토큰을 보다 자유롭게 샘플링할 수 있지만 이후 토큰에 대한 컨디셔닝 프롬프트의 영향이 증가한다.
또한 이 메커니즘을 이용하여 $\ell_u$를 “부정 프롬프트”로 컨디셔닝된 logit으로 대체하는 negative prompting (NegPrompt)를 사용한다. 이렇게 하면 결과 이미지가 긍정 프롬프트 $\ell_c$와 연관된 feature를 갖고 부정 프롬프트 $\ell_u$와 연관된 feature가 제거된다.
8. Iterative Parallel Decoding at Inference
모델의 inference 시간 효율성을 위해 중요한 것은 병렬 디코딩을 사용하여 하나의 forward pass에서 여러 출력 토큰을 예측하는 것이다. 병렬 디코딩의 효율성을 뒷받침하는 핵심 가정은 많은 토큰이 주어진 다른 토큰과 조건부로 독립적이라는 Markovian 속성이다. 디코딩은 해당 step에서 예측할 가장 신뢰도가 높은 마스킹된 토큰의 특정 고정 부분을 선택하는 코사인 스케줄링을 기반으로 수행된다. 그런 다음 이러한 토큰은 나머지 step에서 unmask로 설정되고 마스킹된 토큰 집합은 적절하게 줄어든다.
이 절차를 사용하면 base model에서 24개의 디코딩 step만 사용하여 256개의 토큰을 inference할 수 있으며, super-resolution model에서 8개의 디코딩 step을 사용하여 4096개의 토큰을 inference할 수 있다. 이와 달리 autoregressive model은 256 또는 4096 step이 필요하며, diffusion model은 수 백개의 step이 필요하다. Inference 샘플의 예시는 아래 그림과 같다.

Results
1. Qualitative Performance
다음은 다양한 텍스트 속성들에 대한 text-to-image 능력을 나타낸 것이다.

다음은 동일한 텍스트 프롬프트에 대하여 DALL-E2, Imagen, Muse를 비교한 것이다.

2. Quantitative Performance
다음은 CC3M에서의 정량적 평가 결과이다.
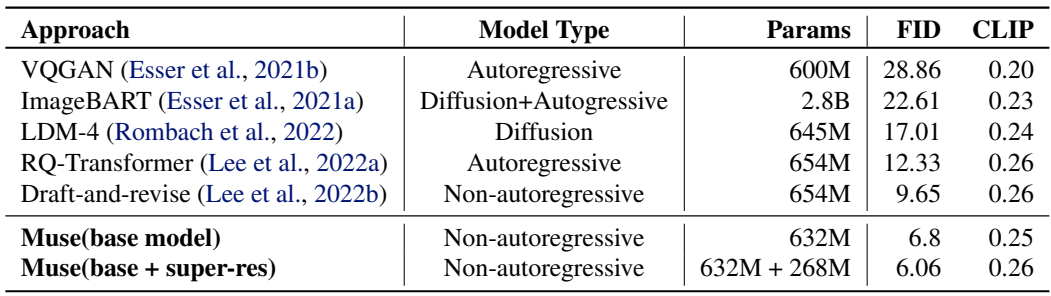
다음은 MS-COCO에서의 정량적 평가 결과이다.

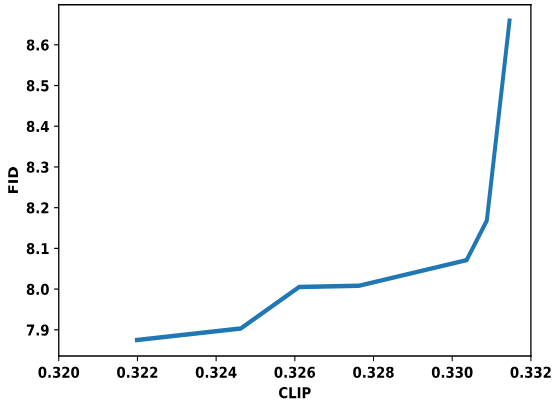
다음은 CLIP과 FID의 trade-off 그래프이다.
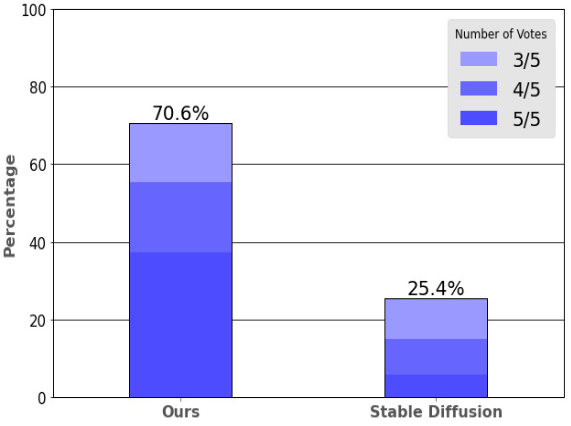
다음은 인간 평가자들이 모델 선호도를 나타낸 그래프이다.
다음은 다양한 모델의 batch 당 inference 시간을 비교한 표이다.

3. Image Editing
다음은 Muse를 사용한 텍스트로 가이드한 zero-shot 이미지 편집의 예시이다.

다음은 텍스트로 가이드한 인페인팅의 예시이다.

다음은 zero-shot mask-free 이미지 편집의 예시이다.

다음은 zero-shot mask-free 이미지 편집 중간의 이미지 변화를 나타낸 것이다.
