[논문리뷰] Moûsai: Efficient Text-to-Music Diffusion Models
arXiv 2023. [Paper] [Page] [Github]
Flavio Schneider, Ojasv Kamal, Zhijing Jin, Bernhard Schölkopf
ETH Zürich | IIT Kharagpur | MPI for Intelligent Systems
27 Jan 2023
Introduction
최근 몇 년 동안 자연어 처리(NLP)는 딥 러닝과 대규모 사전 학습 모델의 발전으로 인간 언어를 이해하고 생성하는 데 큰 진전을 이루었다. 대부분의 NLP 연구는 텍스트 데이터에 중점을 두고 있지만, 풍부하고 표현력이 풍부한 또 다른 의사소통 언어인 음악이 있다. 음악은 텍스트와 마찬가지로 감정, 이야기, 아이디어를 전달할 수 있으며 고유한 구조와 구문을 가지고 있다.
본 논문에서는 NLP 기술의 힘을 활용하여 텍스트 입력에 따라 음악을 생성함으로써 텍스트와 음악 사이의 격차를 해소하였다. 본 논문은 NLP 응용 범위를 확장하는 것을 목표로 할 뿐만 아니라 언어, 음악, 기계 학습 기술의 교차점에서 학제간 연구에 기여하는 것을 목표로 한다.
그러나 텍스트와 마찬가지로 음악 생성도 다양한 수준의 추상화에서 여러 측면을 요구하기 때문에 오랫동안 어려운 작업이었다. 기존 오디오 생성 모델은 RNN, GAN, 오토인코더, transformer의 사용을 탐색하였다. 컴퓨터 비전에서 diffusion 기반 생성 모델이 최근 발전함에 따라 음성 연구자들은 음성 합성과 같은 작업에서 diffusion model의 사용을 탐구하기 시작했다. 그러나 이러한 모델 중 소수만이 음악 생성 작업에 잘 적용될 수 있다.
또한, 음악 생성 분야에는 몇 가지 오랜 과제가 있다.
- 길이가 긴 음악 생성: 대부분의 text-to-audio 시스템은 단 몇 초의 오디오만 생성할 수 있다.
- 모델 효율성: 단 1분의 오디오를 생성하기 위해 GPU에서 몇 시간 동안 실행되어야 한다.
- 생성된 음악의 다양성 부족: 많은 사람들이 단일 형식을 취하는 학습 방법으로 인해 제한됨
- 텍스트 프롬프트에 의한 쉬운 제어 가능성: 대부분은 latent 상태, 음악의 시작 부분 또는 텍스트에 의해서만 제어되지만 음악은 일상적인 소리에 대한 가사 또는 설명이다.
이러한 모든 측면을 마스터하는 단일 모델은 더 많은 대중이 접근 가능한 텍스트 기반 인터페이스를 사용하여 음악을 작곡할 수 있게 함으로써 창작 과정에 참여할 수 있게 하고, 창작자가 영감을 찾는 데 도움을 주고, 새로운 오디오 샘플을 무제한으로 제공할 수 있으므로 음악 산업에 크게 기여할 것이다.
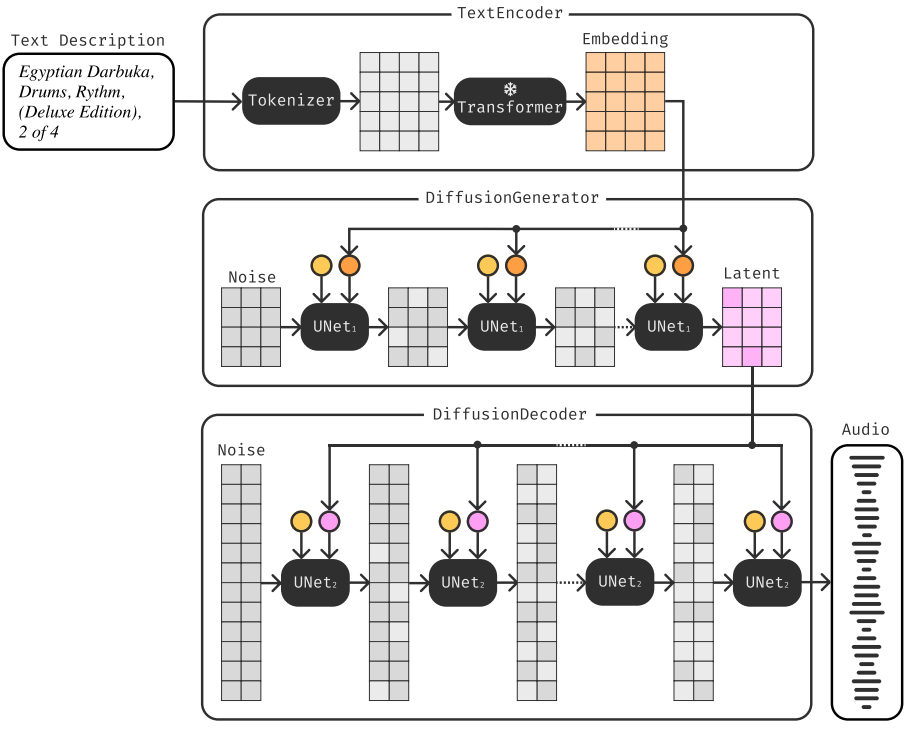
이러한 문제를 해결하기 위해 본 논문은 새로운 텍스트 조건부 2단계 계단식 diffusion model인 Moûsai를 제안하였다. 구체적으로 첫 번째 단계에서는 새로운 diffusion autoencoder로 오디오를 압축하는 diffusion magnitude-autoencoding (DMAE)를 통해 음악 인코더를 학습시킨다. 두 번째 단계에서는 text-conditioned latent diffusion (TCLD)를 통해 텍스트 설명을 조건으로 축소된 표현을 생성하는 방법을 학습시킨다. 2단계 생성 프로세스는 위 그림에 나와 있다.
저자들은 새로운 text-to-music diffusion model을 제안하는 것 외에도 모델 효율성을 높이고 모델의 접근성을 높이기 위한 몇 가지 특별한 디자인도 도입하였다. 첫째, DMAE는 64배의 오디오 신호 압축률을 달성할 수 있다. 또한, 저자들은 경량화되고 특화된 1D U-Net 아키텍처를 설계하였다. Moûsai는 GPU에서 몇 분 밖에 걸리지 않는 빠른 inference 속도를 달성하고, A100 GPU 1개에서 단계당 약 1주일의 학습 시간이 필요하여 대부분의 대학에서 사용할 수 있는 리소스를 사용하여 전체 시스템을 학습시키고 실행할 수 있다.
저자들은 다양한 음악 장르를 포괄하는 50,000개의 텍스트-음악 쌍을 포함하여 새로 수집된 데이터셋인 Text2Music을 기반으로 모델을 학습시켰다. 놀랍게도 Moûsai는 다양한 음악 장르에 대해 학습할 수 있고, 고품질 48kHz 스테레오 음악으로 몇 분 동안 긴 맥락의 음악을 생성하고, 몇 분 내에 효율적으로 실시간 inference를 실행할 수 있고, 텍스트로 쉽게 제어할 수 있기 때문에 이전 모델보다 크게 향상되었다.
Moûsai: Efficient Long-Context Music Generation from Text
Moûsai에는 2단계 학습 과정이 포함되어 있다. 1단계에서는 diffusion autoencoder를 사용하여 오디오 파형을 64배로 압축하는 diffusion magnitude-autoencoding (DMAE)를 사용한다. 2단계에서는 고정된 transformer 언어 모델에서 얻은 텍스트 임베딩을 조건으로 diffusion을 통해 새로운 latent space를 생성하기 위해 latent text-to-audio diffusion model을 사용한다.
1. Stage 1: Music Encoding by Diffusion Magnitude-Autoencoding (DMAE)
Moûsai의 첫 번째 단계는 음악의 latent 표현 공간을 포착하기 위해 좋은 음악 인코더를 학습하는 것이다. 표현 학습은 고차원 입력 데이터를 처리하는 것보다 훨씬 더 효율적일 수 있으므로 생성 모델에 매우 중요하다.
Overview
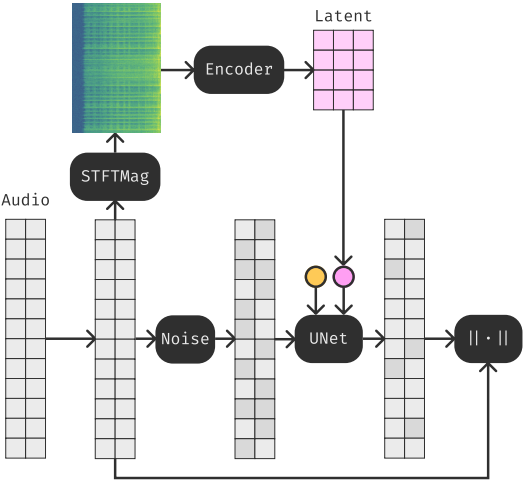
음악의 표현 공간을 학습하기 위해 위 그림에 표시된 DMAE를 사용한다. 특히 diffusion 기반 오디오 오토인코더를 채택하여 오디오를 원래 파형에서 64배 더 작은 latent space로 압축한다. 모델을 학습시키기 위해 먼저 파형을 오디오 모델에 대한 더 나은 표현인 magnitude spectrogram으로 변환한 다음 이를 latent 표현으로 오토인코딩한다.
동시에 임의의 양의 noise로 원본 오디오를 손상시키고 해당 noise를 제거하는 1D U-Net을 학습시킨다. Denoising process 동안 noise level과 압축된 latent으로 U-Net을 컨디셔닝하여 noise가 없는 오디오의 축소 버전을 얻는다.
$v$-Objective Diffusion
$v$-objective diffusion process를 사용한다. 분포 $p(x_0)$의 샘플 $x_0$, noise schedule $\sigma_t \in [0, 1]$, noisy한 데이터 포인트 \(x_{\sigma_t} = \alpha_{\sigma_t} x_0 + \beta_{\sigma_t} \epsilon\)이 있다고 가정하자. v-objective diffusion은 다음과 같은 목적 함수를 최소화하여 모델 \(\hat{v}_{\sigma_t} = f(x_{\sigma_t}, \sigma_t)\)를 추정하려고 시도한다.
\[\begin{equation} \mathbb{E}_{t \sim [0,1], \sigma_t, x_{\sigma_t}} [\| f_\theta (x_{\sigma_t}, \sigma_t) - v_{\sigma_t} \|_2^2] \\ \textrm{where} \; v_{\sigma_t} = \frac{\partial x_{\sigma_t}}{\sigma_t} = \alpha_{\sigma_t} \epsilon - \beta_{\sigma_t} x_0 \\ \alpha_{\sigma_t} := \cos (\phi_t), \; \beta_{\sigma_t} := \sin (\phi_t), \; \phi_t = \frac{\pi}{2} \sigma_t \end{equation}\]DDIM Sampler for Denoising
Denoising step에서는 ODE 샘플러를 사용하여 변화율을 추정하고 noise를 새로운 데이터 포인트로 전환한다. 본 논문에서는 잘 작동하고 step 수와 오디오 품질 사이에 합리적인 균형을 이루는 DDIM 샘플러를 채택했다. DDIM 샘플러는 다음을 반복적으로 적용하여 신호의 noise를 제거한다.
\[\begin{aligned} \hat{v}_{\sigma_t} &= f_\theta (x_{\sigma_t}, \sigma_t) \\ \hat{x}_0 &= \alpha_{\sigma_t} x_{\sigma_t} - \beta_{\sigma_t} \hat{v}_{\sigma_t} \\ \hat{\epsilon}_{\sigma_t} &= \beta_{\sigma_t} x_{\sigma_t} + \alpha_{\sigma_t} \hat{v}_{\sigma_t} \\ \hat{x}_{\sigma_{t-1}} &= \alpha_{\sigma_{t-1}} \hat{x}_0 + \beta_{\sigma_{t-1}} \hat{\epsilon}_t \end{aligned}\]이는 1과 0 사이에서 균일한 간격의 시퀀스인 $T$-step noise schedule $\sigma_T, \ldots, \sigma_0$에 대해 step $\sigma_t$에서 초기 데이터 포인트와 noise를 모두 추정한다.
Diffusion Autoencoder for Audio Input
저자들은 먼저 magnitude spectrogram을 압축된 표현으로 인코딩하고 나중에 디코딩 모듈의 중간 채널에 latent를 주입하는 새로운 diffusion autoencoder를 제안하였다. 이미지 diffusion model과 같은 diffusion을 수행하는 표준 방법은 입력을 낮은 차원의 표현 공간으로 압축하고 축소된 latent space에 diffusion process를 적용하는 것이다. 저자들은 입력 자체의 압축된 latent 벡터로 diffusion process를 컨디셔닝하는 방법으로 diffusion 기반 오토인코딩을 통해 표현 공간을 더욱 압축하고 향상시킨다. Diffusion은 더욱 강력한 생성 디코더 역할을 하므로 입력은 압축률이 더 높은 latent 표현으로 축소될 수 있다.
Efficient and Enriched 1D U-Net
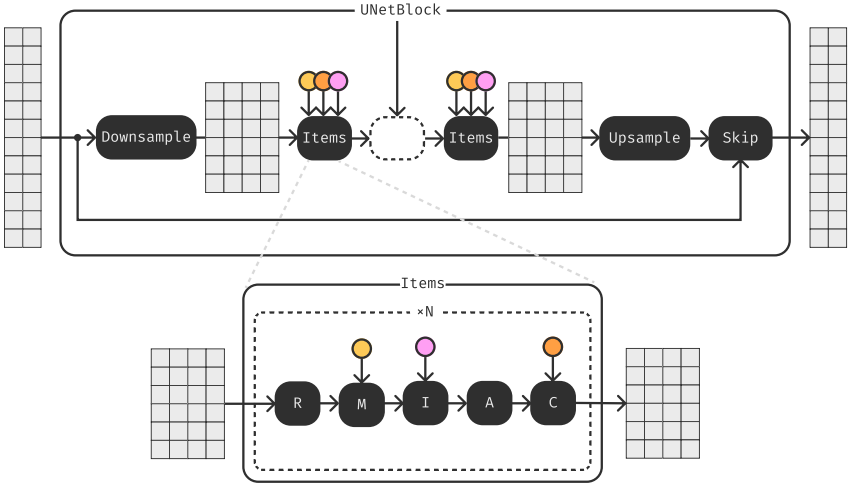
모델의 또 다른 중요한 모듈은 효율적인 1D U-Net이다. U-Net 아키텍처는 skip connection이 있는 모래시계 모양의 convolution 전용 2D 아키텍처를 사용하기 때문에 상대적으로 효율성과 속도가 제한적이다. 따라서 저자들은 속도 측면에서 원래의 2D 아키텍처보다 더 효율적이고 각 주파수가 다른 채널로 간주되는 경우 파형이나 스펙트로그램 모두에서 성공적으로 사용할 수 있는 1D convolution 커널만 가진 새로운 U-Net을 제안하였다.
또한 저자들은 위 그림에 표시된 것처럼 1D U-Net에 여러 가지 새로운 구성 요소를 주입하였다.
- ResNet residual 1D convolutional unit
- Diffusion noise level에서 얻은 feature의 채널을 변경하는 modulation unit
- 외부 채널을 현재 깊이의 채널에 concatenate하기 위한 inject item
Inject item은 음악의 latent 표현을 조건으로 하기 위해 첫 번째 단계에서 디코더의 특정 깊이에만 적용된다.
Overall Model Architecture
전체 1단계 DMAE는 다음과 같이 작동한다. $w$를 $c$ 채널 및 $t$ timestep에 대하여 모양이 $[c, t]$인 파형이라 하고, $(m_w, p_w) = \textrm{stft}(w; n = 1024, h = 256)$을 window 크기가 1024이고 hop length가 256인 short-time furier tranform에서 얻은 파형의 magnitude와 phase라 하자. 그러면 결과 스펙트로그램의 모양은 $[cn, t/h]$이다. Phase를 버리고 1D convolutional 인코더를 사용하여 magnitude를 latent \(z = \mathcal{E}_{\theta_e} (m_w)\)로 인코딩한다. 그런 다음 diffusion model \(\hat{w} = \mathcal{D}_{\theta_d} (z, \epsilon, s)\)를 사용하여 잠재 신호를 디코딩하여 원래 파형을 재구성한다. 여기서 \(\mathcal{D}_{\theta_d}\)는 시작 noise $\epsilon$를 사용한 diffusion process이고 $s$는 디코딩 step 수이다. 디코더는 latent \(f_{\theta_d} (w_{\sigma_t}; \sigma_t, z)\)로 컨디셔닝되어 $v$-objective diffusion으로 학습된다. 여기서 \(f_{\theta_d}\)는 디코딩 중에 반복적으로 호출되는 제안된 1D U-Net이다.
Magnitude만 사용되고 위상(phase)은 버려지기 때문에 이 diffusion autoencoder는 압축 오토인코더이자 보코더이다. Magnitude spectrogram을 사용하면 파형을 직접 오토인코딩하는 것보다 더 높은 압축 비율을 얻을 수 있다. 파형은 압축 가능성이 낮고 작업 효율성이 낮다. Diffusion model은 인코딩된 magnitude로 컨디셔닝된 경우에도 현실적인 phase의 파형을 생성하는 방법을 쉽게 학습할 수 있다.
이러한 방식으로 음악의 latent space는 text-to-music generator의 출발점이 될 수 있다. 이 표현 공간이 다음 단계에 맞다는 것을 보장하기 위해 bottleneck에 tanh 함수를 적용하여 값을 $[-1, 1]$ 범위 내에 유지한다. VAE와 같이 더 disentangle한 bottleneck은 추가 정규화가 허용되는 압축 정도를 감소시키기 때문에 사용하지 않는다.
2. Stage 2: Text-to-Music Generation by Text-Conditioned Latent Diffusion (TCLD)
학습된 음악 표현 공간을 기반으로 2단계에서는 텍스트 설명을 통해 음악 생성을 가이드한다.
Overview
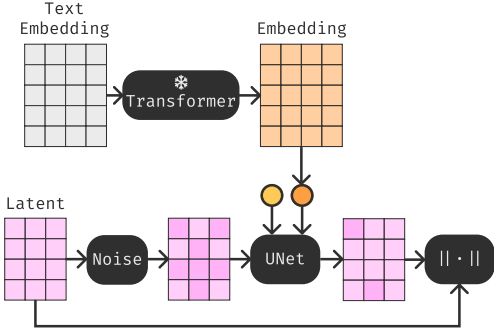
저자들은 위 그림과 같은 text-conditioned latent diffusion (TCLD) 프로세스를 제안하였다. 구체적으로, 먼저 랜덤한 양의 noise로 음악의 latent space를 손상시킨 다음 일련의 U-Net을 학습시켜 noise를 제거하고 transformer 모델로 인코딩된 텍스트 프롬프트로 U-Net의 denoising process를 컨디셔닝한다. 이러한 방식으로 생성된 음악은 음악의 latent space를 따르고 텍스트 프롬프트에 대응된다.
Text Conditioning
텍스트 임베딩을 얻기 위해 텍스트 컨디셔닝에 대한 이전 연구들에서는 공동 데이터 텍스트 표현을 학습하거나 사전 학습된 언어 모델의 임베딩을 latent model의 직접적인 컨디셔닝으로 사용하였다. TCLD 모델에서는 사전 학습된 고정된 T5 언어 모델을 사용하여 주어진 설명에서 텍스트 임베딩을 생성하는 Imagen의 관행을 따른다. Inference 중 텍스트 임베딩의 강도를 향상시키기 위해 0.1의 확률로 학습된 마스크가 적용되는 classifier-free guidance (CFG)를 사용한다.
Adapting the U-Net for Text Conditioning
U-Net이 텍스트 임베딩 $e$로 컨디셔닝될 수 있도록 U-Net에 두 개의 블록을 추가한다. 즉, 긴 컨텍스트 구조 정보를 공유하는 attention 블록과 텍스트 임베딩으로 컨디셔닝하기 위한 cross-attention 블록이다. 이러한 attention 블록들은 전체 latent space에 대한 정보 공유를 보장하며, 이는 장거리 오디오 구조를 학습하는 데 중요하다.
Latent space의 압축된 크기를 고려하여 이 내부 U-Net의 크기를 첫 번째 단계보다 크게 늘린다. 모델의 효율적인 디자인 덕분에 파라미터 수가 많아도 합리적인 학습 속도와 inference 속도를 유지한다.
Overall Model Architecture
이전 단계와 일관되게 $v$-objective diffusion과 1D U-Net 아키텍처를 사용한다. 텍스트 임베딩 $e$로 컨디셔닝될 때 U-Net \(f_{\theta_g} (z_{\sigma_t}; \sigma_t, e)\)를 사용하여 압축된 latent \(z = \mathcal{E}_{\theta_e}(m_w)\)를 생성한다. 그런 다음 generator \(\mathcal{G}_{\theta_g} (e, \epsilon, s)\)는 DDIM 샘플링을 적용하고 U-Net의 시간 $s$를 호출하여 텍스트 임베딩 $e$와 시작 noise $\epsilon$로부터 대략적인 latent $\hat{z}$를 생성한다. 파형을 얻기 위한 최종 생성은 다음과 같다.
\[\begin{equation} \hat{w} = \mathcal{D}_{\theta_d} (\mathcal{G}_{\theta_d} (e, \epsilon_g, s_g), \epsilon_d, s_d) \end{equation}\]Experiments
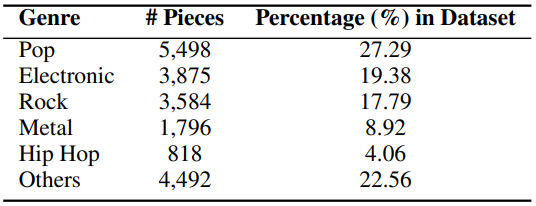
- 데이터셋: Text2Music
- 총 2,500시간에 달하는 50,000개의 텍스트-음악 쌍으로 구성된 새로운 데이터셋
- 48kHz로 샘플링된 고품질 스테레오 음악을 보장하고 다양한 장르, 아티스트, 악기 및 출처를 포괄하는 다양한 음악을 포괄함
- Spotify의 권장 사항에 따라 각각 평균 7,000개의 음악이 포함된 7개의 매우 큰 재생 목록을 수집
- 이러한 재생 목록의 모든 음악 이름으로 YouTube에서 음악을 검색하고 다운로드하고 메타데이터를 사용하여 음악 제목, 작곡가, 앨범 이름, 장르, 출시 연도가 포함된 해당 텍스트 설명을 구성
- 구현 디테일
- 파라미터 수
- diffusion autoencoder: 1.85억 개
- TCLD: 8.57억 개
- 길이
- diffusion autoencoder: $2^{18}$ (∼5.5s, 48kHz), random crop
- TCLD: $2^{21}$ (∼44s, 48kHz), fixed crop
- 인코딩 채널: 32
- optimizer: AdamW ($\beta_1$ = 0.95, $\beta_2$ = 0.999)
- learning rate: $10^{-4}$
- weight decay: $10^{-3}$
- EMA: $\beta$ = 0.995, power = 0.7
- 파라미터 수
1. Property Analysis
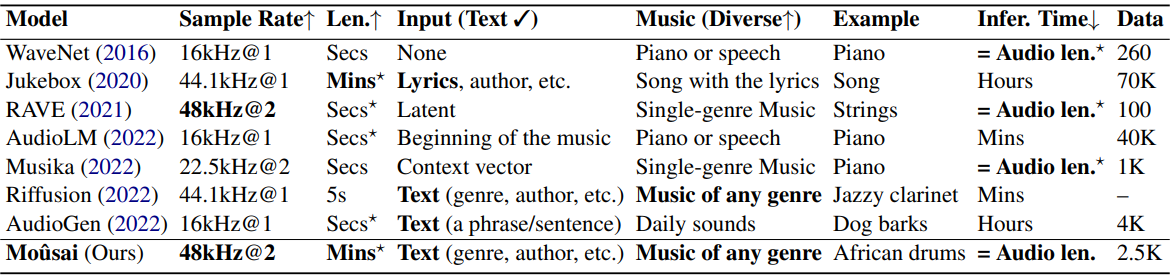
다음은 이전 음악/오디오 생성 모델들과 Moûsai를 비교한 표이다.
2. Efficiency of Our Model
다음은 Moûsai과 Riffusion의 효율성을 inference 시간(Inf. Time)과 inference 메모리(Mem.)로 평가한 표이다.

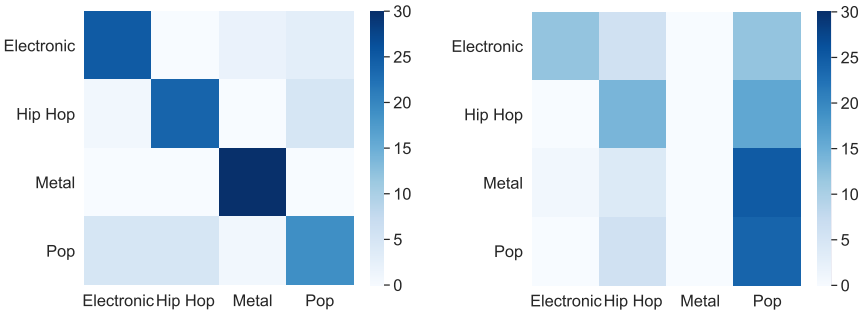
3. Evaluating the Text-Music Relevance
다음은 텍스트와 음악의 관련성을 확인한 그래프이다. $y$축의 실제 장르이고 $x$축은 사람이 분류한 장르이다.
다음은 Moûsai과 Riffusion의 CLAP score를 비교한 표이다.

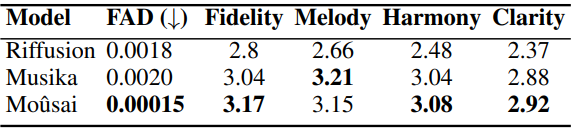
4. Evaluating the Music Quality
다음은 세 가지 모델의 음악 품질 점수를 비교한 표이다.
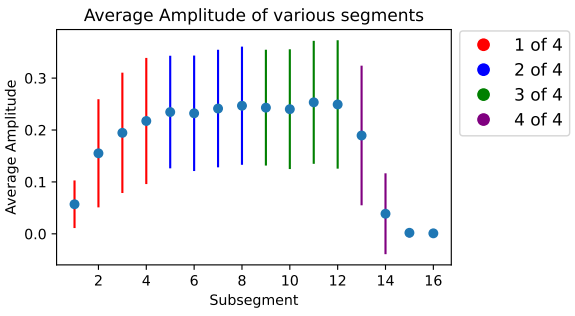
5. Long-Term Structure of the Music
다음은 다양한 세그먼트에 걸쳐 있는 1천 개의 랜덤 음악 샘플의 평균 amplitude와 variation이다.