[논문리뷰] MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
ICLR 2025 (Spotlight). [Paper] [Page] [Github]
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jampani, Trevor Darrell, Forrester Cole, Deqing Sun, Ming-Hsuan Yang
UC Berkeley | Google DeepMind | Stability AI | UC Merced
4 Oct 2024

Introduction
DUSt3R는 장면 형상을 직접 회귀시키는 새로운 패러다임을 도입하였다. 한 쌍의 이미지가 주어지면, DUSt3R는 pointmap 표현을 생성한다. 이는 각 이미지의 모든 픽셀을 추정된 3D 위치와 연관시키고 첫 번째 프레임의 카메라 좌표계에서 이러한 pointmap 쌍을 정렬한다. 여러 프레임의 경우, DUSt3R는 쌍별 추정치를 글로벌 포인트 클라우드로 누적하고 이를 사용하여 수많은 3D task를 해결하였다.
본 논문은 DUSt3R의 pointmap 표현을 활용하여 동적 장면의 형상을 직접 추정한다. 핵심 통찰력은 pointmap을 timestep별로 추정할 수 있으며 동일한 카메라 좌표계에서 표현하는 것이 동적 장면에 대해 여전히 개념적으로 의미가 있다는 것이다. 동적 장면에 대한 추정된 pointmap은 동적 물체가 움직이는 방식에 따라 여러 위치에 나타나는 포인트 클라우드로 나타닌다. 정적 장면 요소를 기반으로 pointmap 쌍을 정렬하여 다중 프레임 정렬을 달성할 수 있다. 이 설정은 DUSt3R를 동적 장면에 일반화한 것이며 동일한 네트워크와 원래 가중치를 시작점으로 사용할 수 있게 해준다.

자연스러운 의문 중 하나는 DUSt3R가 이미 움직이는 물체가 있는 동영상 데이터를 효과적으로 처리할 수 있는지 여부이다. 그러나 위 그림에서 볼 수 있듯이 DUSt3R의 학습 데이터 분포에서 비롯된 두 가지 중요한 한계가 존재한다.
- 학습 데이터에 정적 장면만 포함되어 있기 때문에 DUSt3R는 움직이는 물체가 있는 장면의 pointmap을 올바르게 정렬하지 못한다. 종종 정렬을 위해 움직이는 물체에 의존하여 정적인 배경에 대한 잘못된 정렬을 초래한다.
- 학습 데이터가 대부분 건물과 배경으로 구성되어 있기 때문에 DUSt3R는 때때로 움직임에 관계없이 전경 물체의 형상을 올바르게 추정하지 못하고 배경에 배치한다.
원칙적으로 두 문제 모두 학습과 inference 사이의 도메인 불일치에서 비롯되며 네트워크를 다시 학습시키면 해결할 수 있다.
그러나 깊이와 포즈가 있는 동적 데이터는 주로 그 희소성 때문에 어려움을 겪는다. COLMAP과 같은 기존 방법은 종종 복잡한 카메라 궤적이나 매우 동적인 장면에 어려움을 겪어 학습을 위한 가상 GT 데이터조차 생성하기 어렵다. 이러한 한계를 해결하기 위해 저자들은 목적에 필요한 속성을 가진 여러 소규모 데이터셋을 식별하였다.
이 제한된 데이터를 최대한 활용하도록 설계된 적절한 학습 전략을 통해 DUSt3R를 fine-tuning함으로써 DUSt3R가 동적 장면을 처리하도록 적용시킬 수 있다. 그런 다음 이러한 pointmap을 사용하여 동영상 task에 대한 여러 가지 새로운 최적화 방법을 도입하고, 동영상 깊이 및 카메라 포즈 추정에 대한 강력한 성능과 주로 feed-forward 4D 재구성에 대한 유망한 결과를 보여주었다.
Method
1. Training for dynamics
주요 아이디어
DUSt3R는 주로 정적 장면에 초점을 맞추는 반면, 제안된 MonST3R는 시간에 따른 동적 장면의 형상을 추정할 수 있다.
MonST3R는 시간 $t$에서 단일 이미지 $\textbf{I}^t$에 대해 pointmap $\textbf{X}^t \in \mathbb{R}^{H \times W \times 3}$도 예측한다. 한 쌍의 이미지 $\textbf{I}^t$와 $\textbf{I}^{t^\prime}$에 대해, 네트워크는 confidence map \(\textbf{C}^{t; t \leftarrow t^\prime}\)과 \(\textbf{C}^{t^\prime; t \leftarrow t^\prime}\)을 사용하여 두 개의 pointmap \(\textbf{X}^{t; t \leftarrow t^\prime}\)과 \(\textbf{X}^{t^\prime; t \leftarrow t^\prime}\)를 예측한다.
위 첨자 $t; t \leftarrow t^\prime$는 네트워크가 $t$, $t^\prime$에서 두 프레임을 입력받고, pointmap이 $t$에서의 카메라 좌표계에 있음을 나타낸다. DUSt3R와의 주요 차이점은 MonST3R의 각 pointmap이 하나의 시점과 관련이 있다는 것이다.
학습 데이터셋
동적 장면을 timestep별 pointmap으로 모델링하는 데 있어 핵심 과제는 적절한 학습 데이터가 부족하다는 것이다. 여기에는 입력 이미지, 카메라 포즈, 깊이에 대한 동기화된 주석이 필요하다. 실제 동적 장면에 대한 정확한 카메라 포즈를 얻는 것은 특히 어려운 일이며, 종종 센서 측정이나 SfM을 통한 후처리에 의존하면서 움직이는 물체를 필터링한다. 따라서 저자들은 주로 합성 데이터셋을 활용하였으며, 렌더링 프로세스 중에 정확한 카메라 포즈와 깊이를 쉽게 추출할 수 있다.

동적 fine-tuning을 위해 4개의 대규모 동영상 데이터셋, 3개의 합성 데이터셋인 PointOdyssey, TartanAir, Spring과 현실 데이터셋인 Waymo를 사용한다. 이러한 데이터셋에는 다양한 실내/실외 장면, 동적 물체, 카메라 모션, 카메라 포즈 및 깊이에 대한 레이블이 포함되어 있다.
PointOdyssey와 Spring은 모두 관절이 있는 동적 물체가 있는 합성적으로 렌더링된 장면이다. TartanAir는 동적 물체가 없는 다양한 장면의 합성적으로 렌더링된 드론 플라이스루로 구성되어 있다. Waymo는 LiDAR로 레이블링된 실제 주행 데이터셋이다.
PointOdyssey는 더 동적이고 관절이 있는 물체가 많기 때문에 더 많은 가중치를 두고, 동적 물체가 없는 TartanAir와 도메인이 매우 특수한 Waymo에는 가중치를 덜 두어 데이터셋을 샘플링한다. 이미지는 가로, 세로 중 긴 쪽이 512가 되도록 다운샘플링된다.
학습 전략
이 혼합 데이터셋의 크기가 비교적 작기 때문에 데이터 효율성을 극대화하도록 설계된 여러 가지 학습 기법을 사용한다.
- 인코더를 고정하고 네트워크의 prediction head와 디코더만 fine-tuning한다. 이 전략은 CroCo feature의 기하학적 지식을 보존하고 fine-tuning에 필요한 데이터 양을 줄인다.
- 1~9 사이의 temporal stride로 두 프레임을 샘플링하여 각 동영상에 대한 학습 쌍을 만든다. 샘플링 확률은 stride 길이에 따라 선형적으로 증가하며 9가 선택될 확률은 1이 선택될 확률의 두 배이다. 이를 통해 카메라와 장면 모션의 다양성이 커지고 더 큰 모션에 더 많은 가중치를 둔다.
- 다양한 이미지 스케일의 center crop을 사용하는 FOV augmentation 기법을 활용한다. 이를 통해 모델이 다양한 intrinsic에 대해 일반화하도록 장려한다.
2. Downstream applications
Instrinsic 및 상대적 포즈 추정
Intrinsic 파라미터는 자체 카메라 프레임의 pointmap \(\textbf{X}^{t; t \leftarrow t^\prime}\)을 기반으로 추정되므로 DUSt3R에 나열된 가정과 계산은 여전히 유효하며, instrinsic 파라미터 $\textbf{K}^t$를 얻기 위해 초점 거리 $f^t$에 대해서만 풀면 된다.
동적 물체가 포함되어 있기 때문에 상대적 포즈 $\textbf{P} = [\textbf{R} \vert \textbf{T}]$를 추정하기 위해 RANSAC과 PnP를 사용한다. 대부분의 픽셀이 정적일 때, 랜덤 샘플 포인트는 정적 요소에 더 많은 강조점을 두고, 상대적 포즈는 inlier들을 사용하여 robust하게 추정할 수 있다.
신뢰할 수 있는 정적 영역
프레임 $t$와 $t^\prime$에서 신뢰할 수 있는 정적인 영역을 추론할 수 있는 방법은 $t$에서 $t^\prime$으로의 카메라 모션만으로 생성된 flow field를 추정된 optical flow와 비교하는 것이다. 두 flow field는 형상이 올바르게 추정되고 정적인 픽셀에 대해서는 일치해야 한다.
한 쌍의 프레임 $\textbf{I}^t$와 $\textbf{I}^{t^\prime}$이 주어진 경우, 다음과 같이 flow field를 계산할 수 있다.
- 두 세트의 pointmap $\textbf{X}^{t; t \leftarrow t^\prime}$, $\textbf{X}^{t^\prime; t \leftarrow t^\prime}$과 $\textbf{X}^{t; t^\prime \leftarrow t}$, $\textbf{X}^{t^\prime; t^\prime \leftarrow t}$를 계산한다.
- 이 pointmap들을 사용하여 위에서 설명한 방법대로 각 프레임의 카메라 intrinsic $\textbf{K}^t$, $\textbf{K}^{t^\prime}$과 $t$에서 $t^\prime$으로의 상대적 카메라 포즈 $\textbf{P}^{t \rightarrow t^\prime} = [\textbf{R}^{t \rightarrow t^\prime} \vert \textbf{T}^{t \rightarrow t^\prime}]$을 추정한다.
- 각 픽셀을 3D로 backprojection하고 상대적인 카메라 모션을 적용한 다음 이미지 좌표로 다시 projection하여 카메라 모션으로 유도된 optical flow field \(\textbf{F}_\textrm{cam}^{t \rightarrow t^\prime}\)를 계산한다.
($\textbf{x}$는 픽셀 좌표 행렬, $\textbf{x}$는 $\textbf{x}$의 homogeneous coordinate, \(\textbf{D}^{t; t \leftarrow t^\prime}\)는 pointmap \(\textbf{X}^{t; t \leftarrow t^\prime}\)에서 추출한 깊이)
그런 다음, 이를 기존 optical flow 방법으로 계산된 optical flow \(\textbf{F}_\textrm{est}^{t \rightarrow t^\prime}\)와 비교하고 간단한 threshold $\alpha$를 통해 신뢰할 수 있는 정적 마스크 \(\textbf{S}^{t \rightarrow t^\prime}\)를 유추한다.
\[\begin{equation} \textbf{S}^{t \rightarrow t^\prime} = [\alpha > \| \textbf{F}_\textrm{cam}^{t \rightarrow t^\prime} - \textbf{F}_\textrm{est}^{t \rightarrow t^\prime} \|_\textrm{L1}] \end{equation}\](\(\| \cdot \|_\textrm{L1}\)은 smooth-L1 norm, $[\cdot]$는 괄호 안이 참이면 1이고 거짓이면 0)
이 신뢰할 수 있는 정적 마스크는 잠재적인 출력이며 이후의 글로벌 포즈 최적화에 사용된다.
3. Dynamic global point clouds and camera pose
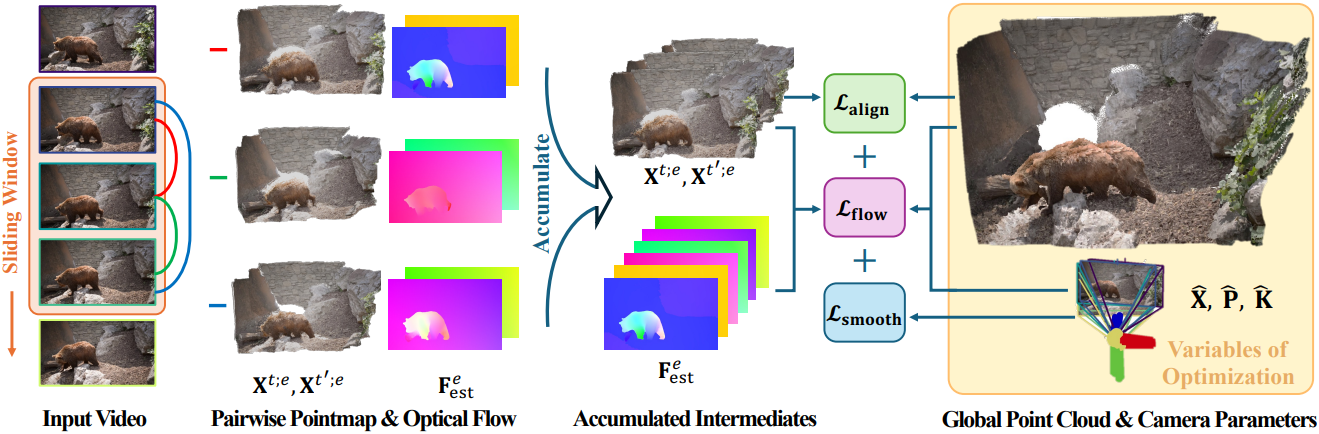
짧은 동영상조차도 수많은 프레임을 포함하고 있다. 따라서 동영상 전체의 쌍별 pointmap 추정치에서 하나의 동적 포인트 클라우드를 추출하는 것은 쉽지 않다.
동영상 그래프
글로벌한 정렬을 위해 DUSt3R는 모든 쌍별 프레임에서 connectivity graph를 구성하는데, 이 프로세스는 동영상에서 엄청난 계산을 필요로 한다. 그 대신, sliding temporal window로 동영상을 처리하여 필요한 계산량을 크게 줄인다.
구체적으로, 동영상 \(\textbf{V} = [\textbf{I}^0, \ldots, \textbf{I}^N]\)이 주어지면 크기가 $w$인 temporal window \(\textbf{W}^t = \{(a, b) \vert a, b \in [t, \ldots, t+w], a \ne b\}\) 내의 모든 쌍 $e = (t, t^\prime)$에 대한 pointmap을 계산하고 모든 window $\textbf{W}$에 대해 pointmap을 계산한다. 실행 시간을 더욱 개선하기 위해 strided sampling도 적용한다.
동적 글로벌 포인트 클라우드 및 포즈 최적화
주요 목표는 모든 쌍별 pointmap 예측을 동일한 글로벌 좌표계에 누적하여 월드 좌표에서의 pointmap \(\textbf{X}^t \in \mathbb{R}^{H \times W \times 3}\)을 생성하는 것이다. 이를 위해 DUSt3R의 alignment loss를 사용하고 카메라 궤적에 대한 smoothness loss와 flow projection loss를 추가로 사용한다.
카메라 파라미터 $\textbf{P} = [\textbf{R}^t \vert \textbf{T}^t]$, $\textbf{K}^t$와 프레임별 depth map $\textbf{D}^t$를 사용하여 글로벌 pointmap Xt를 다음과 같이 re-parameterize한다.
\[\begin{equation} \textbf{X}_{i,j}^t = (\textbf{P}^{t})^{-1} h ((\textbf{K}^t)^{-1} [i \textbf{D}_{i,j}^t; j \textbf{D}_{i,j}^t; \textbf{D}_{i,j}^t]) \end{equation}\]($(i,j)$는 픽셀 좌표, $h(\cdot)$는 homogeneous mapping)
이를 통해 카메라 파라미터에서 직접 loss를 정의할 수 있다.
DUSt3R의 alignment loss는 $\textbf{X}^{t; t \leftarrow t^\prime}$와 $\textbf{X}^{t^\prime; t \leftarrow t^\prime}$이 모두 동일한 카메라 좌표계에 있기 때문에 각 쌍별 추정을 월드 좌표계의 pointmap과 정렬하는 하나의 강체 변환 (rigid transformation) $\textbf{P}^{t;e}$를 찾는 것을 목표로 한다.
\[\begin{equation} \mathcal{L}_\textrm{align} (\textbf{X}, \sigma, \textbf{P}_W) = \sum_{W^i \in W} \sum_{e \in W^i} \sum_{t \in e} \| \textbf{C}^{t;e} \cdot (\textbf{X}^t - \sigma^e \textbf{P}^{t;e} \textbf{X}^{t;e}) \|_1 \end{equation}\]($\sigma^e$는 쌍별 scale factor, $e = (t, t^\prime)$은 $t \leftarrow t^\prime$과 동일)
카메라 rotation과 translation의 큰 변화에 대한 페널티를 부과하여 부드러운 카메라 움직임을 장려하기 위해 카메라 궤적에 smoothness loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{smooth} (\textbf{X}) = \sum_{t=0}^N (\| (\textbf{R}^t)^\top \textbf{R}^{t+1} - I \|_f + \| (\textbf{R}^t)^\top (\textbf{T}^{t+1} - \textbf{T}^t) \|_2) \end{equation}\](\(\| \cdot \|_f\)는 Frobenius norm, $I$는 단위 행렬)
또한 flow projection loss를 사용하여 글로벌 pointmap과 카메라 포즈가 실제 프레임의 신뢰할 수 있는 정적 영역에 대해 추정된 flow와 일치하도록 유도한다.
구체적으로, 두 프레임 $t$와 $t^\prime$이 주어졌을 때, 장면이 정적이라고 가정하고 두 프레임의 글로벌 pointmap, intrinsic, extrinsic을 이용하여 글로벌 pointmap $\textbf{X}^t$에서 카메라를 $t$에서 $t^\prime$으로 이동시켰을 때의 flow field를 계산한다. 이 값을 \(\textbf{F}_\textrm{cam}^{\textrm{global}; t \rightarrow t^\prime}\)으로 표기하며, 이는 위에서 정의된 신뢰할 수 있는 정적 영역 계산에서 사용된 항과 유사하다.
그런 다음, 이를 추정된 flow \(\textbf{F}_\textrm{est}^{t \rightarrow t^\prime}\)와, 글로벌 파라미터에 따라 신뢰할 수 있는 정적 영역 \(\textbf{S}^{\textrm{global}; t \rightarrow t^\prime}\) 내에서 가깝게 유지하도록 유도할 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{flow} (\textbf{X}) = \sum_{W^i \in W} \sum_{t \rightarrow t^\prime \in W^i} \| \textbf{S}^{\textrm{global}; t \rightarrow t^\prime} \cdot (\textbf{F}_\textrm{cam}^{\textrm{global}; t \rightarrow t^\prime} - \textbf{F}_\textrm{est}^{t \rightarrow t^\prime}) \|_1 \end{equation}\]신뢰할 수 있는 정적 마스크는 앞서 설명한 대로 쌍별 예측 값을 사용하여 초기화된다. 최적화하는 동안 글로벌 pointmap과 카메라 파라미터를 사용하여 \(\textbf{F}_\textrm{cam}^\textrm{global}\)을 계산하고 신뢰할 수 있는 정적 마스크를 업데이트한다.
동적 글로벌 포인트 클라우드와 카메라 포즈에 대한 전체 최적화는 다음과 같다.
\[\begin{equation} \hat{\textbf{X}} = \underset{\textbf{X}, \textbf{P}_W, \sigma}{\arg \min} \mathcal{L}_\textrm{align} (\textbf{X}, \sigma, \textbf{P}_W) + w_\textrm{smooth} \mathcal{L}_\textrm{smooth} (\textbf{X}) + w_\textrm{flow} \mathcal{L}_\textrm{flow} (\textbf{X}) \end{equation}\]위의 re-parameterization에 따라 $\hat{\textbf{X}}$에는 $\hat{\textbf{D}}$, $\hat{\textbf{P}}$, $\hat{\textbf{K}}$에 대한 모든 정보가 포함된다.
동영상 깊이
글로벌 pointmap $\hat{\textbf{X}}$에는 프레임별 depth map $\hat{\textbf{D}}$에 대한 정보가 있으므로 이를 반환하기만 하면 시간적으로 일관된 동영상 깊이를 얻을 수 있다.
Experiments
- 학습 디테일
- ViT-Base decoder와 DPT head들을 fine-tuning
- epoch: 25 (epoch당 이미지 쌍 2만 개)
- optimizer: AdamW
- learning rate: $5 \times 10^{-5}$
- mini-batch size: GPU당 4
- GPU: RTX 6000 48GB 2개에서 1일 소요
- Inference
- $w$ = 9, stride 2인 60프레임 동영상은 약 30초 소요 (이미지 약 600쌍)
- 글로벌 최적화
- $w_\textrm{smooth}$ = 0.01, $w_\textrm{flow}$ = 0.01
- 카메라 포즈가 대략 정렬된 경우, flow loss의 평균 값이 20 미만일 때만 flow loss를 활성화
- 픽셀별 flow loss가 50보다 높으면 최적화 중에 모션 마스크가 업데이트됨
- optimizer: Adam
- learning rate: 0.01
- iteration: 300
- 60프레임 동영상의 경우, RTX 6000 GPU 1개에서 약 1분 소요
1. Single-frame and video depth estimation
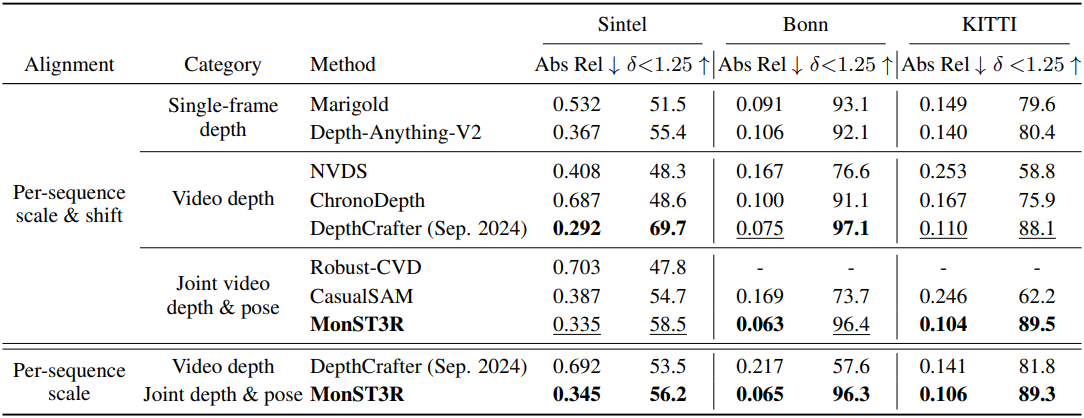
다음은 깊이 추정 결과를 비교한 것이다.

2. Camera pose estimation
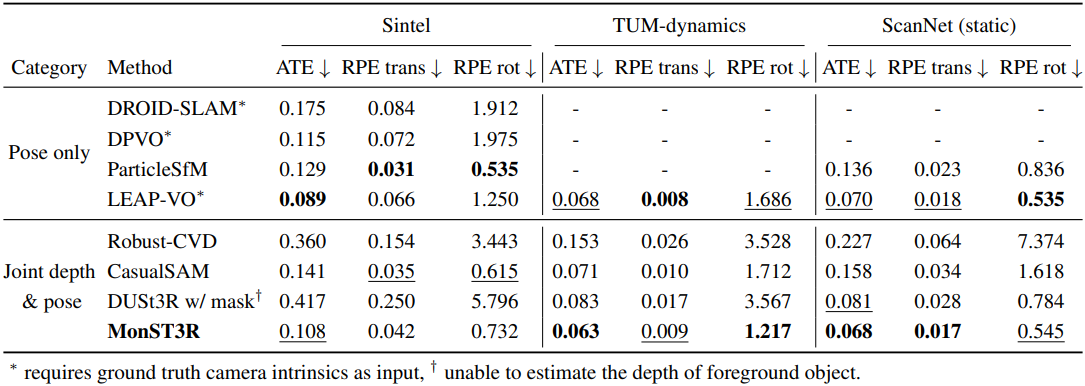
다음은 카메라 포즈 추정 결과이다.
3. Joint dense reconstruction and pose estimation
다음은 다른 방법들과 정성적으로 비교한 결과이다.

4. Ablation Study
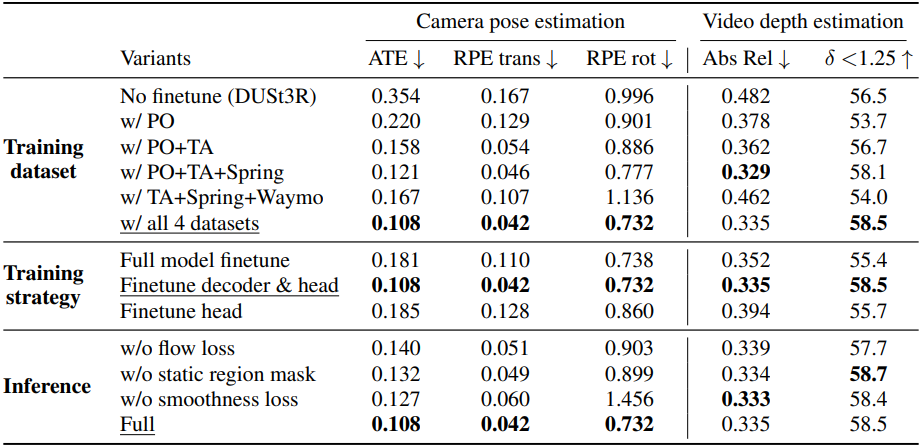
다음은 Sintel 데이터셋에서의 ablation study 결과이다.