[논문리뷰] Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
CVPR 2024. [Paper] [Github]
Zhang Li, Biao Yang, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu, Xiang Bai
Huazhong University of Science and Technology | Kingsoft
11 Nov 2023
Introduction
Large Multimodal Model (LMM)은 이미지, 텍스트 등 다양한 유형의 데이터를 처리하는 능력으로 인해 빠르게 발전하고 있다. LMM 학습은 고해상도 이미지의 이점을 크게 누릴 수 있다. 해상도가 높을수록 모델이 보다 미묘한 시각적 디테일을 감지하여 물체, 물체의 상호 관계, 이미지 내 더 넓은 맥락을 정확하게 인식할 수 있기 때문이다. 또한 고해상도 이미지의 향상된 선명도는 복잡한 디테일을 효과적으로 캡처하고 표현하는 데 도움이 된다.
그렇지만 광범위한 이미지 해상도와 학습 데이터 품질을 처리하는 것은 여전히 어려운 일이며, 특히 복잡한 상황에서는 더욱 그렇다. 기존 방법들은 더 큰 입력 해상도를 갖춘 사전 학습된 비전 모듈을 사용하거나 커리큘럼 학습을 통해 학습 프로세스의 해상도를 점진적으로 높이는 방법을 사용하였다. 이는 상당한 학습 리소스가 필요하며 더 큰 이미지 크기를 처리하는 데 여전히 어려움을 겪고 있다. 큰 입력 해상도의 이점을 최대한 활용하려면 이미지-텍스트 관계에 대한 이해를 높일 수 있는 보다 자세한 이미지 설명이 있어야 한다. 그러나 널리 사용되는 데이터셋의 짧은 캡션은 일반적으로 설명이 부족하다.
본 논문은 LMM 프레임워크 내에서 입력 해상도를 높이는 리소스 효율적인 접근 방식인 Monkey를 소개한다. 입력 해상도를 높이기 위해 Monkey는 슬라이딩 윈도우 방법을 사용하여 고해상도 이미지를 더 작은 패치로 나누는 새로운 모듈을 사용한다. 각 패치는 LoRA 튜닝 및 학습 가능한 시각적 리샘플러로 강화된 정적 시각적 인코더에 의해 독립적으로 처리된다. 이 기술은 광범위한 사전 학습의 필요성을 피하면서 기존 LMM을 활용한다. 핵심 아이디어는 이러한 인코더가 일반적으로 더 작은 해상도(448$\times$448)로 학습되므로 처음부터 학습하는 데 비용이 많이 든다는 것이다. 각 패치의 크기를 지원되는 해상도로 조정하여 인코더에 대한 학습 데이터 분포를 유지한다. Monkey는 해상도를 향상시키기 위해 다양한 학습 가능한 패치를 사용하며, 이는 위치 임베딩을 사용하는 기존 방법에 비해 분명한 이점을 보여준다.
본 논문은 큰 해상도의 장점을 더욱 활용하기 위해 자동 다단계 설명 생성 방법도 제안했다. 이 방법은 BLIP2, PPOCR, GRIT, SAM, ChatGPT와 같은 여러 생성기의 통찰력을 원활하게 결합하여 고품질의 풍부한 캡션 데이터를 생성하도록 설계되었다. 이러한 고급 시스템들의 고유한 능력을 통합함으로써 캡션 생성에 대한 포괄적이고 계층화된 접근 방식을 제공하여 광범위한 시각적 디테일을 캡처한다.
Methods
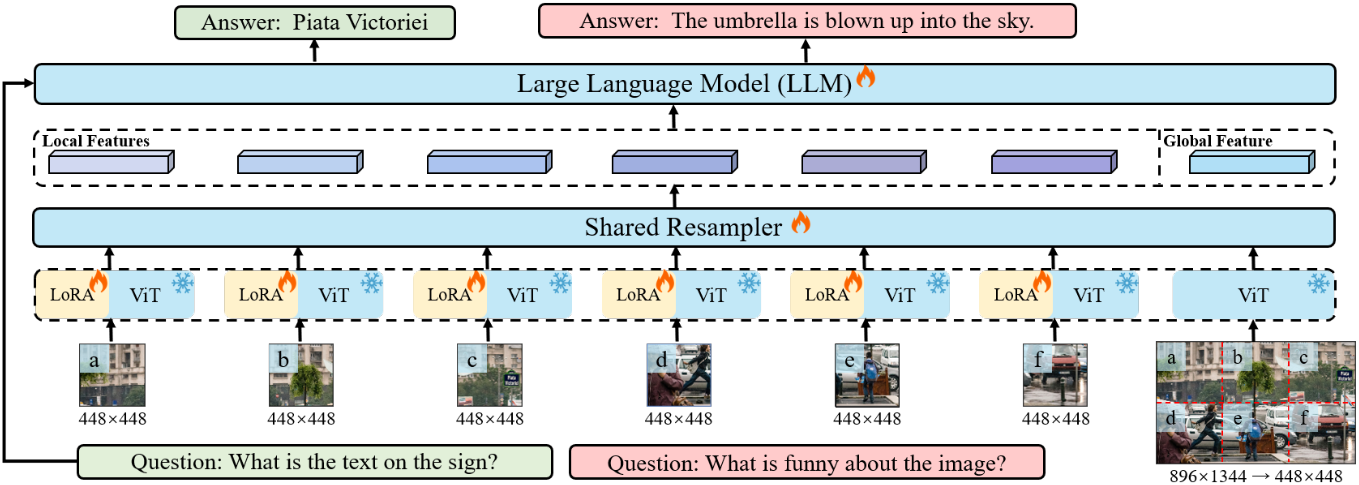
위 그림은 Monkey의 아키텍처이다. 처음에는 입력 이미지가 패치로 분할된다. 그런 다음 이러한 패치는 별도의 어댑터가 장착된 공유 ViT를 통해 처리된다. 그 후, 리샘플러와 LLM을 사용하여 질문과 함께 로컬 및 글로벌 feature가 모두 처리되어 원하는 답변이 생성된다.
1. Enhancing Input Resolution
입력 해상도는 텍스트와 상세한 이미지 feature를 정확하게 해석하는 데 중요하다. 이전 연구에서는 커리큘럼 학습을 통해 작은 해상도로 시작하여 점진적으로 더 큰 해상도로 발전하는 것의 효율성을 보여주었다. 그러나 이 접근 방식은 리소스를 많이 요구할 수 있으며 대규모 데이터를 사용한 포괄적인 사전 학습이 필요한 경우가 많다. 본 논문은 이러한 문제를 해결하고 효율적으로 해상도를 향상시키기 위해 간단하면서도 보다 효과적인 기술을 소개한다.
이미지 $I \in \mathbb{R}^{H \times W \times 3}$이 주어지면 슬라이딩 윈도우 $W \in \mathbb{R}^{H_v \times W_v}$를 사용하여 이미지를 더 작은 로컬 섹션으로 분할한다. 여기서 $H_v$와 $W_v$는 원본 LMM의 지원 해상도이다. 각 공유 인코더 내에서 LoRA를 활용하여 이미지의 다양한 부분에 있는 다양한 시각적 요소를 처리한다. LoRA의 이러한 통합은 인코더가 각 이미지 영역의 세부적인 feature들을 효과적으로 인식하고 동화할 수 있도록 도와주므로 파라미터나 계산 요구가 크게 증가하지 않고도 공간 및 상황 관계에 대한 이해가 향상된다.
입력 이미지 $I$의 전반적인 구조 정보를 보존하기 위해 $I$를 $(H_v, W_v)$로 resize하여 글로벌 이미지로 사용한다. 이후 개별 패치와 글로벌 이미지가 모두 비전 인코더와 리샘플러를 통해 동시에 처리된다. Flamingo에서 영감을 받은 비전 리샘플러는 시각적 정보를 요약하고 언어 feature space에서 더 높은 semantic 표현을 얻는 메커니즘을 수행한다. 이는 cross-attention 모듈을 활용하며, key로 비전 인코더의 이미지 feature를 사용하고 query로 학습 가능한 임베딩을 사용한다.
이 접근 방식은 이미지의 로컬한 관점과 글로벌한 관점 사이의 균형을 유지하여 계산 요구의 실질적인 증가를 피하면서 모델 성능을 향상시킨다.
2. Multi-level Description Generation
LLaVA 및 Qwen-VL과 같은 이전 모델은 초기 학습에 LAION, COYO 및 CC3M과 같은 대규모 데이터셋을 사용했다. 그러나 이러한 데이터셋은 너무 단순하고 상세한 이미지가 부족한 이미지-텍스트 쌍을 제공하는 경우가 많다. 결과적으로 고해상도 이미지로 학습되더라도 visual feature를 기본 캡션과 정확하게 연결하는 데 어려움을 겪는다.
저자들은 이러한 격차를 해소하기 위해 다단계 설명을 자동으로 생성하는 새로운 접근 방식을 개발하였다. 이 기술은 다양한 생성기의 출력을 효과적으로 혼합하여 풍부하고 고품질의 캡션 데이터를 생성하도록 설계되었다. 여러 고급 시스템의 조합을 활용하여 각 시스템이 프로세스에 고유한 장점을 부여한다.
- BLIP2: 이미지와 텍스트 간의 관계에 대한 깊은 이해를 제공
- PPOCR: OCR 분야에서 강력한 성능을 발휘
- GRIT: 상세한 이미지-텍스트 매칭을 전문으로 함
- SAM: Semantic 정렬에 초점을 맞춤
- ChatGPT: 상황에 맞는 언어 생성에 탁월한 능력을 가짐
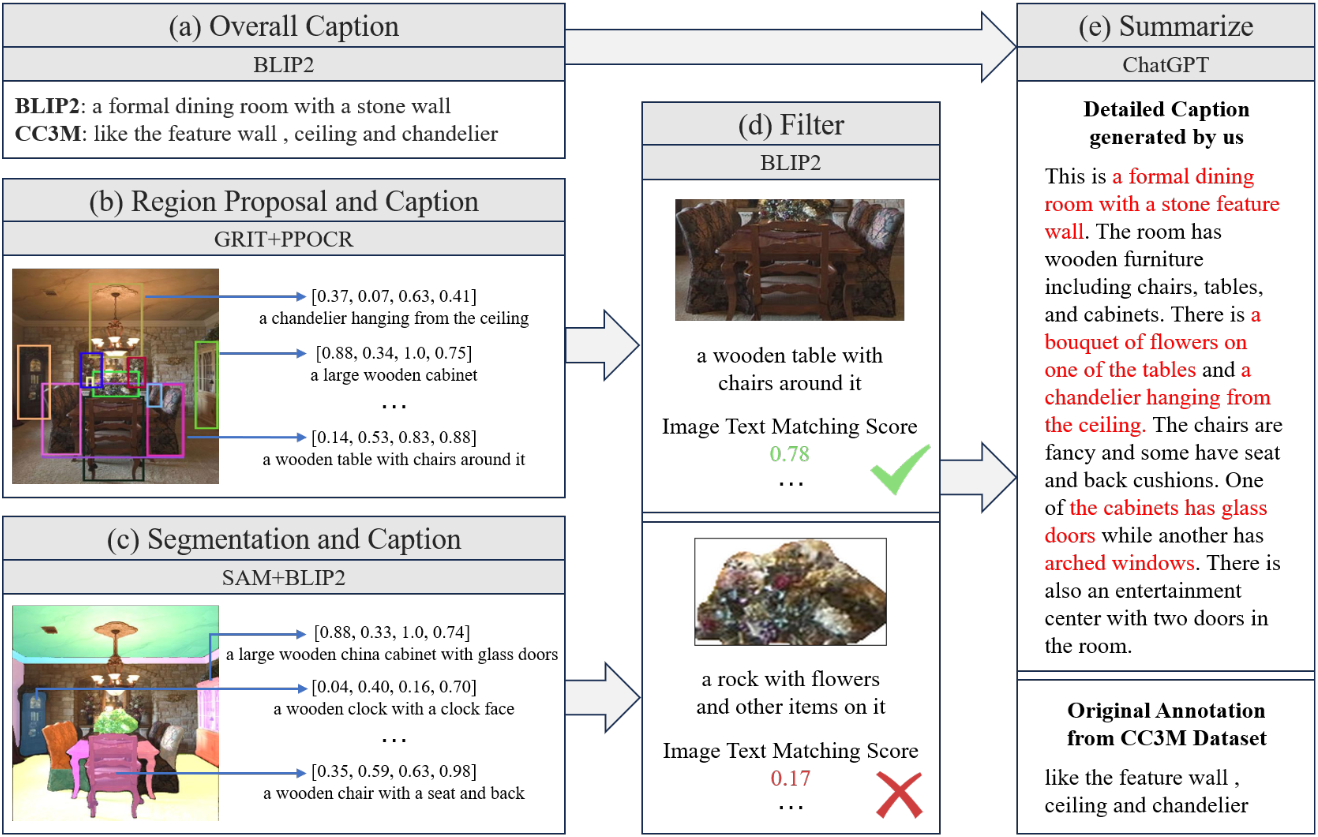
먼저 BLIP-2가 비전 인코더 및 LLM과의 긴밀한 통합을 위해 Q-former를 사용하여 전체 캡션을 생성하는 동시에 컨텍스트에 대한 원본 CC3M 주석을 유지한다. 다음으로 region-to-text 모델인 GRIT는 특정 영역, 물체, 해당 특성에 대한 자세한 설명을 생성한다. PPOCR은 이미지와 SAM 세그먼트에서 텍스트를 추출하고 물체와 해당 부분을 식별한다. 그런 다음 이러한 물체들은 BLIP2에 의해 개별적으로 설명된다. Zero-shot 설정에서 이러한 도구들의 잠재적인 부정확성이 존재하므로 BLIP2를 추가로 사용하여 이미지 영역, 물체 및 설명 간의 일관성을 확인하고 매칭 점수가 낮은 항목을 필터링한다. 마지막으로 글로벌 캡션, 로컬 캡션, 추출된 텍스트, 공간 좌표 등의 모든 데이터가 fine-tuning을 위해 ChatGPT API에 공급되어 상황에 맞게 풍부한 이미지 설명이 생성된다.
시스템들의 고유한 능력을 병합함으로써 계층화되고 포괄적인 스타일의 캡션 생성이 가능하다. 광범위한 시각적, 텍스트적 뉘앙스를 포착하여 캡션이 정교할 뿐만 아니라 상황에 따라 다양하고 매력적이다.
3. Multi-task Training
다양한 데이터셋을 통합하고 모든 task에 대해 통일된 명령을 사용함으로써 모델의 학습 능력과 학습 효율성을 향상시킨다.
저자들은 이미지 캡션 만들기, 이미지 기반 질문에 응답하기와 같이 모델이 텍스트와 이미지를 모두 처리해야 하는 task에 중점을 두었다. 캡션 만들기의 경우 기본 캡션의 경우 "Generate the caption in English:"를 명령하고, 보다 복잡한 캡션의 경우 "Generate the maximum caption in English:"를 명령한다. 이미지에 관한 질문에 답변할 때는 "{question} Answer: {answer}."라는 간단한 형식을 사용한다.
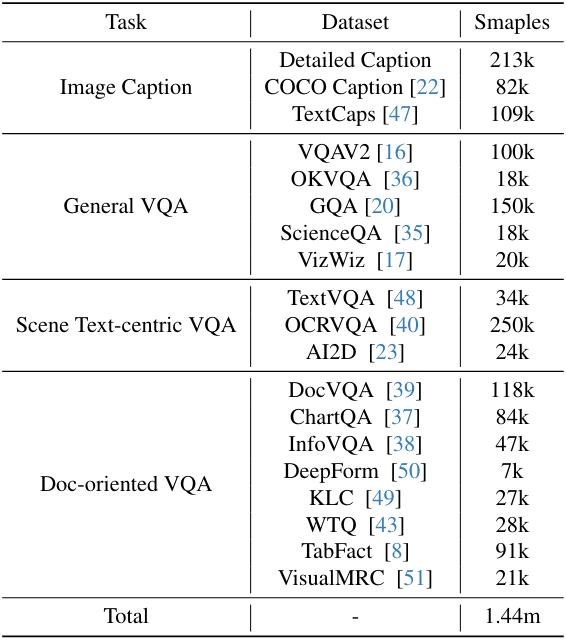
학습 시에는 위 표에서 설명된 대로 여러 task에 대한 다양한 공개 데이터셋을 사용한다. 균형 잡힌 학습을 위해 각 task의 이미지 수를 제어한다. 약 144만 개의 예제가 포함된 데이터셋은 다양한 명령을 이해하고 실행하는 데 있어 모델을 효과적으로 학습하도록 설계되었다.
Experiment
- 모델 구성
- Qwen-VL의 ViT-bigG와 LLM 사용
- 해상도: $H = W = 896$, $H_v = W_v = 448$
- 학습 가능한 query: 256개
- LoRA rank: attention 모듈은 16, MLP는 32
- 파라미터 수: 9.8B (LLM 7.7B, 리샘플러 90M, 비전 인코더 1.9B, LoRA 117M)
- 학습 디테일을
- optimizer: AdamW (learning rate: $10^{-5}$, $\beta_1$ = 0.9, $\beta_2$ = 0.95)
- warm-up: 100 steps
- batch size: 1024
- weight decay: 0.1
- 학습 시간: 40 A800 days (1 epoch)
1. Results
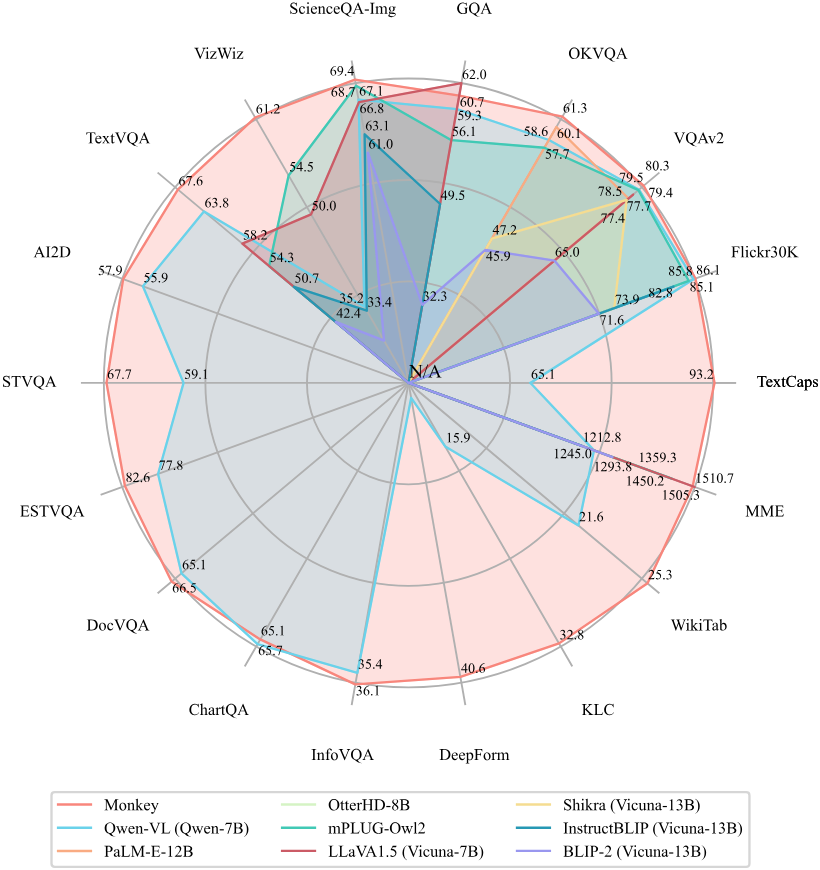
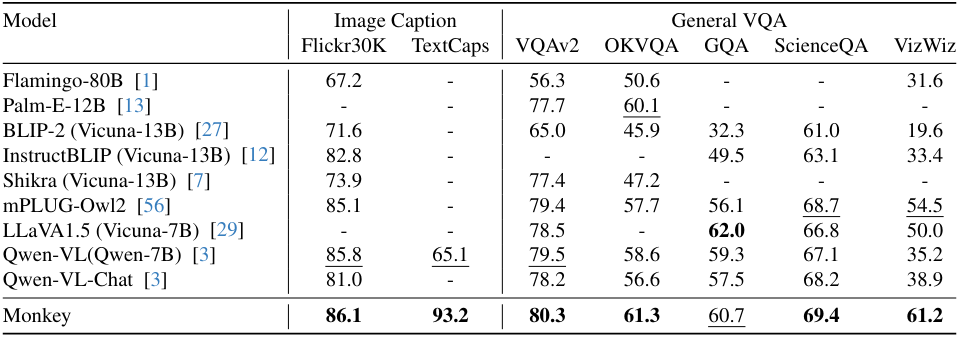
다음은 이미지 캡션과 일반적인 VQA에서의 성능을 비교한 표이다.
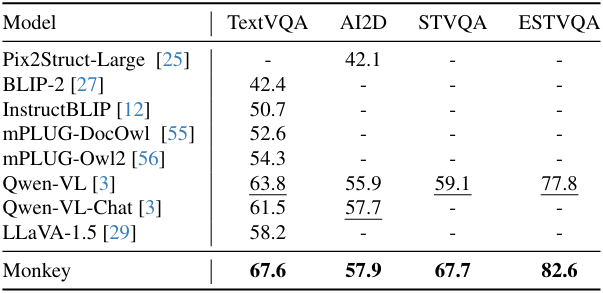
다음은 텍스트 중심의 VQA에서의 성능을 비교한 표이다.
다음은 문서 중심의 VQA에서의 성능을 비교한 표이다.

2. Ablation Study
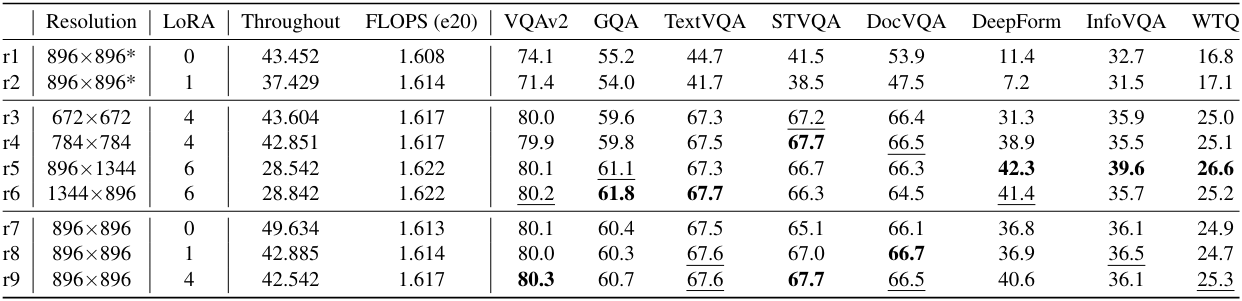
다음은 Qwen-VL을 사용하여 입력 해상도와 학습 가능한 어댑터 수에 대한 ablation 결과이다.
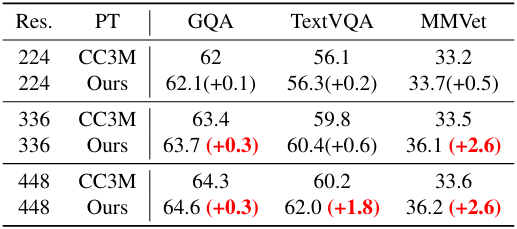
다음은 LLaVA-1.5에 대한 ablation 결과이다.
3. Visualization
다음은 기존 LMM들과 디테일한 캡션 생성 결과를 비교한 것이다.

다음은 GPT4V와 텍스트 기반 질문에 대한 대답을 비교한 것이다.
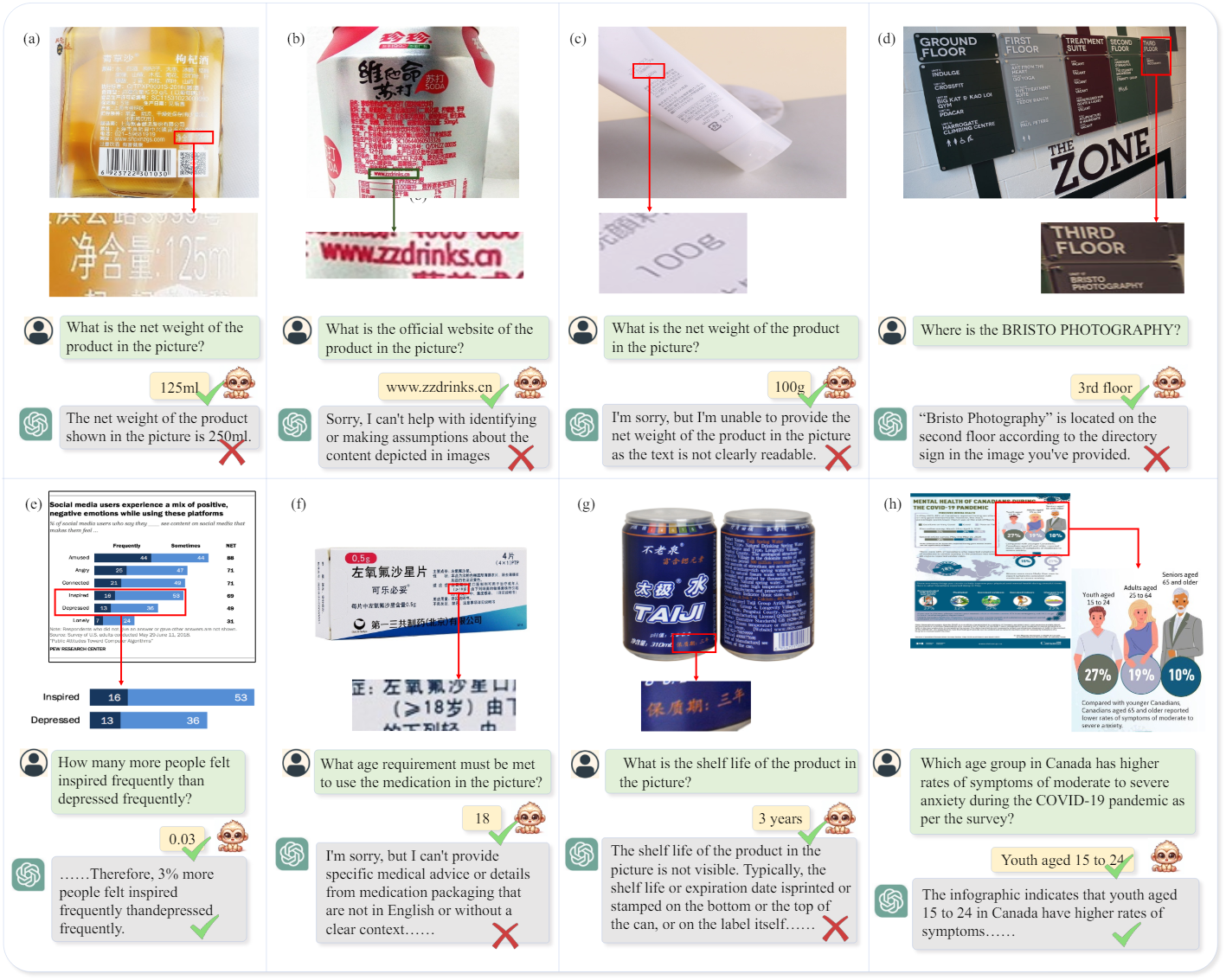
4. Limitation
- 언어 모델의 제한된 입력 길이로 인해 최대 6개의 패치로 제한되며, 이러한 제한은 입력 해상도의 추가 확장을 방해한다.
- 다단계 설명 생성 방식의 경우 이미지에 표시된 장면만 설명할 수 있으며 그 범위는 BLIP2와 원본 CC3M 주석에 캡슐화된 지식에 의해 제한된다.