[논문리뷰] MoBA: Mixture of Block Attention for Long-Context LLMs
arXiv 2025. [Paper] [Github]
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, Zhiqi Huang, Huan Yuan, Suting Xu, Xinran Xu, Guokun Lai, Yanru Chen, Huabin Zheng, Junjie Yan, Jianlin Su, Yuxin Wu, Neo Y. Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, Jiezhong Qiu
Moonshot AI | Tsinghua University | Zhejiang University
18 Feb 2025
Introduction
시퀀스 길이의 제곱에 비례하는 attention 메커니즘과 관련된 계산 복잡도로 인해 LLM에서 시퀀스 길이를 확장하는 것은 어려운 일이다. 성능을 희생하지 않고 효율성을 개선하기 위한 한 가지 방향은 attention score의 고유한 sparsity를 활용하는 것이다.
기존 접근 방식은 sliding window attention과 같은 미리 정의된 구조적 제약을 활용하여 이러한 sparsity를 활용한다. 이러한 방법은 효과적일 수 있지만, task에 따라 매우 특정화되어 모델의 전반적인 일반화를 방해할 가능성이 있다.
Mamba, RWKV, RetNet과 같은 linear attention model은 기존의 softmax 기반 attention을 선형 근사로 대체하여 긴 시퀀스 처리에 대한 계산 오버헤드를 줄였다. 그러나 linear attention과 기존 attention 사이에 상당한 차이가 있기 때문에, 기존 Transformer 모델을 적용하려면 일반적으로 높은 변환 비용이 발생하거나 완전히 새로운 모델을 처음부터 학습시켜야 한다. 또한 복잡한 추론 task에서의 효과에 대한 증거가 제한되어 있다.
저자들은 “덜 구조적인” 원칙을 고수하면서 원래의 Transformer 프레임워크를 유지하는 강력하고 적응 가능한 attention 아키텍처를 설계하는 것을 목표로 하였다. 이를 통해 모델이 사전 정의된 편향에 의존하지 않고 어디에 attention할 지 결정할 수 있다. 이상적으로는 이러한 아키텍처는 full attention과 sparse attention 사이에 원활하게 전환되어 기존 사전 학습된 모델과의 호환성을 극대화하고 성능을 저하시키지 않으면서 효율적인 inference와 가속 학습을 모두 가능하게 한다.
본 논문은 Mixture of Experts (MoE)의 원리를 기반으로 하고, 이를 Transformer 모델의 attention 메커니즘에 적용하는 새로운 아키텍처인 Mixture of Block Attention (MoBA)을 소개한다. MoE가 주로 Transformer의 FFN layer에서 사용되는 것과 달리, MoBA는 긴 컨텍스트 attention에 대한 적용을 개척하여 각 query 토큰에 대해 관련성이 있는 key 블록과 value 블록을 동적으로 선택할 수 있도록 한다. 이 접근 방식은 LLM의 효율성을 향상시킬 뿐만 아니라, 리소스 소비를 비례적으로 증가시키지 않고도 더 길고 복잡한 프롬프트를 처리할 수 있도록 한다.
MoBA는 컨텍스트를 블록으로 분할하고 gating 메커니즘을 사용하여 query 토큰을 가장 관련성이 높은 블록으로 선택적으로 라우팅함으로써 기존 attention 메커니즘의 계산 비효율성을 해결하였다. 이 블록 sparse attention은 계산 비용을 크게 줄여 긴 시퀀스를 보다 효율적으로 처리할 수 있는 길을 열어주었다. MoBA는 가장 유익한 key 블록을 동적으로 선택할 수 있어 성능과 효율성이 향상되며, 특히 광범위한 컨텍스트 정보가 포함된 task에 유용하다.
본 논문에서는 MoBA의 아키텍처, 블록 분할 및 라우팅 전략, 기존 attention 메커니즘과 비교한 계산 효율성을 자세히 설명하였다. MoBA는 긴 시퀀스를 처리해야 하는 task에서 우수한 성능을 보여주며, 효율적인 attention 계산에 대한 새로운 접근 방식을 제공하여 복잡하고 긴 입력을 처리하는 데 있어 LLM의 경계를 넓혔다.
Method
1. Preliminaries: Standard Attention in Transformer
먼저, 하나의 query 토큰 $q \in \mathbb{R}^{1 \times d}$가 $N$개의 key 및 value 토큰 $K, V \in \mathbb{R}^{N \times d}$에 attention하는 경우를 살펴보자. 표준 attention은 다음과 같이 계산된다.
\[\begin{equation} \textrm{Attn} (q, K, V) = \textrm{Softmax}(qK^\top) V \end{equation}\]($d$는 하나의 attention head의 차원)
명확성을 위해 single-head attention에 초점을 맞춘다. Multi-head attention은 여러 개의 single-head attention 연산의 출력을 concat한다.
2. MoBA Architecture
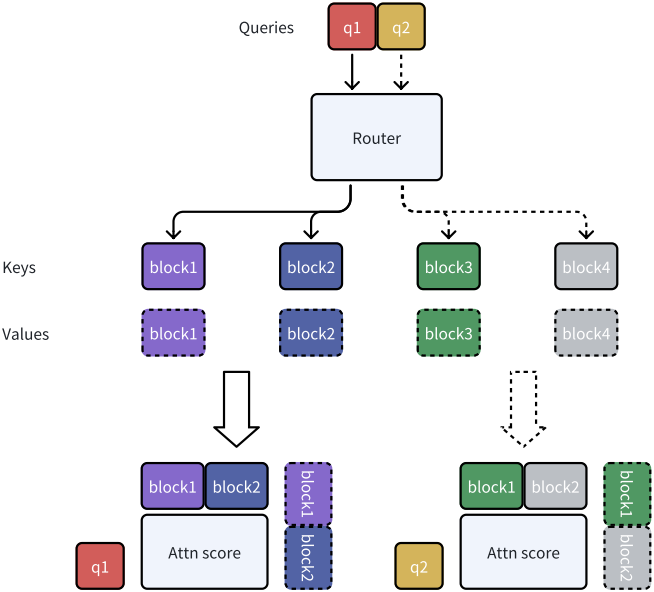
각 query 토큰이 전체 컨텍스트에 attention하는 표준 attention과 달리, MoBA에서는 각 query 토큰이 key와 value의 부분집합에만 attention할 수 있다.
\[\begin{equation} \textrm{MoBA} (q, K, V) = \textrm{Softmax} (q K [I]^\top) V[I] \end{equation}\]($I \subseteq [N]$은 선택된 key들과 value들의 집합)
MoBA의 핵심은 블록 분할 및 선택 전략이다. 길이 $N$의 전체 컨텍스트를 $n$개의 블록으로 나누며, 각 블록은 후속 토큰의 부분집합을 나타낸다. 일반성을 잃지 않고 컨텍스트 길이 $N$이 블록 수 $n$으로 나누어 떨어진다고 가정하자. 또한 $B$를 블록 크기로, $I_i$를 $i$번째 블록의 범위라 하자.
\[\begin{equation} B = \frac{N}{n}, \quad I_i = [(i-1) \times B + 1, i \times B] \end{equation}\]MoE의 top-$k$ gating 메커니즘을 적용함으로써, 각 query가 전체 컨텍스트 $I$가 아닌 다른 블록의 토큰 부분집합에 선택적으로 초점을 맞출 수 있도록 한다.
\[\begin{equation} I = \cup_{g_i > 0} I_i \end{equation}\]모델은 gating 메커니즘을 사용하여 각 query 토큰에 가장 관련성 있는 블록을 선택한다. MoBA 게이트는 먼저 query $q$와 $i$번째 블록 간의 관련성을 측정하는 affinity score $s_i$를 계산하고 모든 블록에 top-$k$ gating을 적용한다. 구체적으로, $i$번째 블록에 대한 게이트 값 $g_i$는 다음과 같이 계산된다.
\[\begin{equation} g_i = \begin{cases} 1 & s_i \in \textrm{Topk} (\{ s_j \vert j \in [n] \}, k) \\ 0 & \textrm{otherwise} \end{cases} \end{equation}\]여기서 $\textrm{Topk}(\cdot, k)$는 각 블록에 대해 계산된 affinity score 중에서 $k$개의 가장 높은 점수를 포함하는 집합을 나타낸다. 점수 $s_i$는 $q$와 $K[I_i]$의 mean pooling (시퀀스 차원에서 수행됨) 사이의 내적으로 계산된다.
\[\begin{equation} s_i = \langle q, \textrm{mean_pool} (K [I_i]) \rangle \end{equation}\]인과관계 (Causality)
Autoregressive한 언어 모델은 이전 토큰을 기반으로 다음 토큰 예측을 통해 텍스트를 생성하기 때문에 인과관계를 유지하는 것이 중요하다. 이 순차적 생성 프로세스는 토큰이 앞에 오는 토큰에 영향을 미칠 수 없도록 보장하여 인과관계를 보존한다. MoBA는 두 가지 특정 설계를 통해 인과관계를 보존한다.
미래 블록에 대한 attention 없음
MoBA는 query 토큰이 향후 블록으로 라우팅될 수 없도록 보장한다. MoBA는 attention 범위를 현재 및 과거 블록으로 제한함으로써 언어 모델링의 autoregressive한 특성을 고수한다. 구체적으로, $\textrm{pos}(q)$를 query $q$의 위치 인덱스라 하면, $\textrm{pos}(q) < i \times B$인 모든 블록 $i$에 대해 $s_i = -\infty$, $g_i = 0$으로 설정한다.
현재 블록 attention과 causal masking
“현재 블록”을 query 토큰 자체가 포함된 블록으로 정의한다. 현재 블록으로의 라우팅은 전체 블록에 걸친 mean pooling이 의도치 않게 미래 토큰의 정보를 포함할 수 있기 때문에 인과관계를 위반할 수도 있다.
이를 해결하기 위해 각 토큰이 해당 현재 블록으로 라우팅되도록 하고, 현재 블록 attention 동안 causal mask를 적용한다. 구체적으로, 쿼리 토큰 $\textrm{pos}(q)$의 위치가 $I_i$ 내에 있는 블록 $i$에 대해 $g_i = 1$로 설정한다. 이 전략은 후속 토큰의 정보 누출을 방지할 뿐만 아니라 로컬 컨텍스트에 대한 attention을 장려한다.
Fine-Grained Block Segmentation
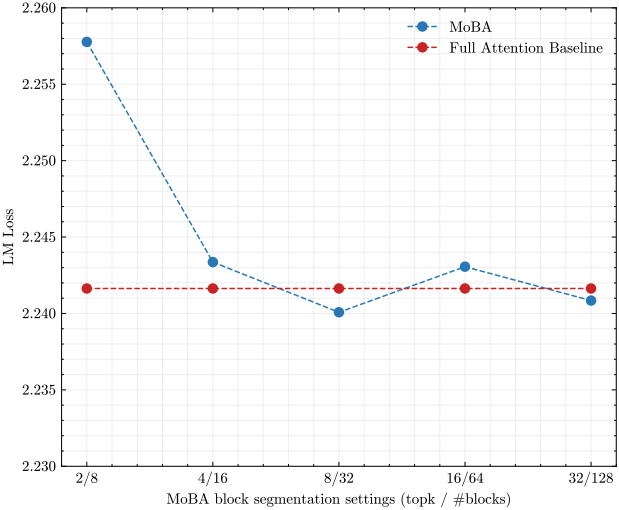
MoE의 경우, 세분화된 전문가로 분할하면 모델 성능이 개선되는 것으로 알려져 있다. MoBA에도 유사한 전문가 분할 기술을 적용할 수 있으며, MoBA는 FFN의 중간 hidden dimension이 아닌 컨텍스트 길이 차원을 따라 세분화한다. 컨텍스트를 더 세분화된 블록으로 분할하면 성능이 좋아진다. 예를 들어, 8개의 블록 중 2개를 선택하는 것보다 32개 중에 8개를 선택하는 것이 성능이 더 좋다.
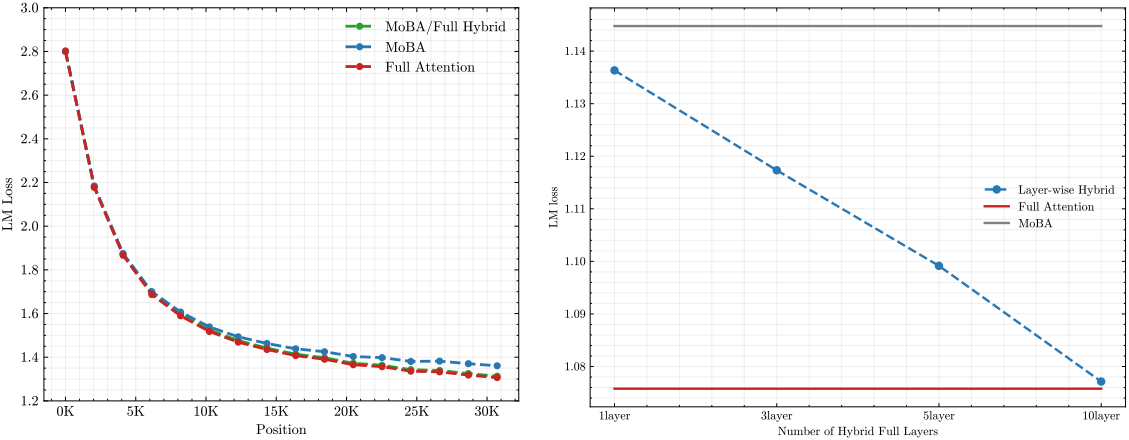
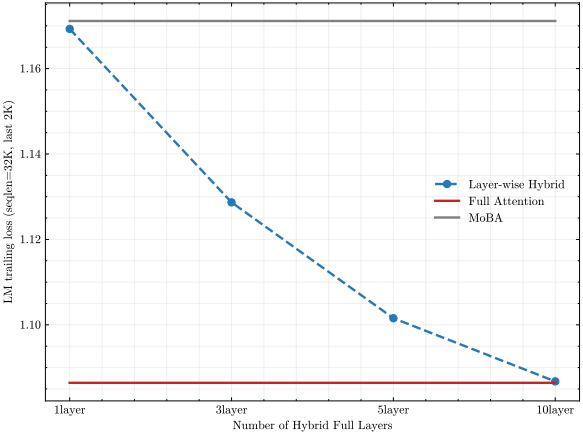
Hybrid of MoBA and Full Attention
MoBA는 full attention과 동일한 수의 파라미터를 유지하면서 대체할 수 있도록 설계되었기 때문에, full attention과 MoBA 간의 원활한 전환이 가능하다. 구체적으로, 초기화 단계에서 각 attention layer는 full attention 또는 MoBA를 선택할 수 있으며, 필요한 경우 학습 중에 동적으로 변경할 수도 있다.
3. Implementation
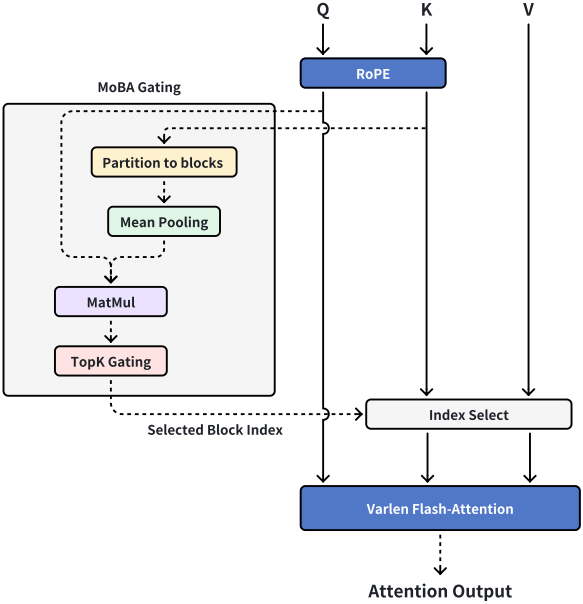
저자들은 FlashAttention과 MoE의 최적화 기술을 통합하였다. 구현은 5가지 주요 단계로 구성된다.
- Gating network와 causal mask에 따라 KV 블록에 대한 query 토큰의 할당을 결정한다.
- 할당된 KV 블록을 기준으로 query 토큰의 순서를 정렬한다.
- 각 KV 블록과 이에 할당된 query 토큰에 대한 attention 출력을 계산한다. (FlashAttention으로 최적화 가능)
- Attention 출력을 원래 순서로 다시 정렬한다.
- Query 토큰이 현재 블록과 여러 과거 KV 블록에 attention할 수 있으므로 online Softmax, 즉 tiling을 사용하여 해당 attention 출력을 결합한다.

Experiments
1. Scaling Law Experiments and Ablation Studies
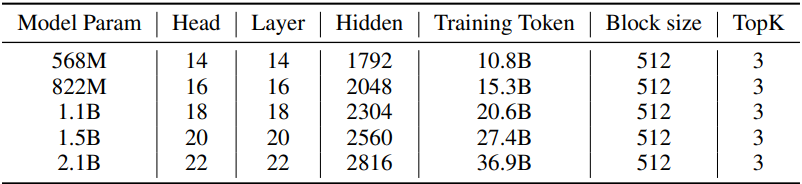
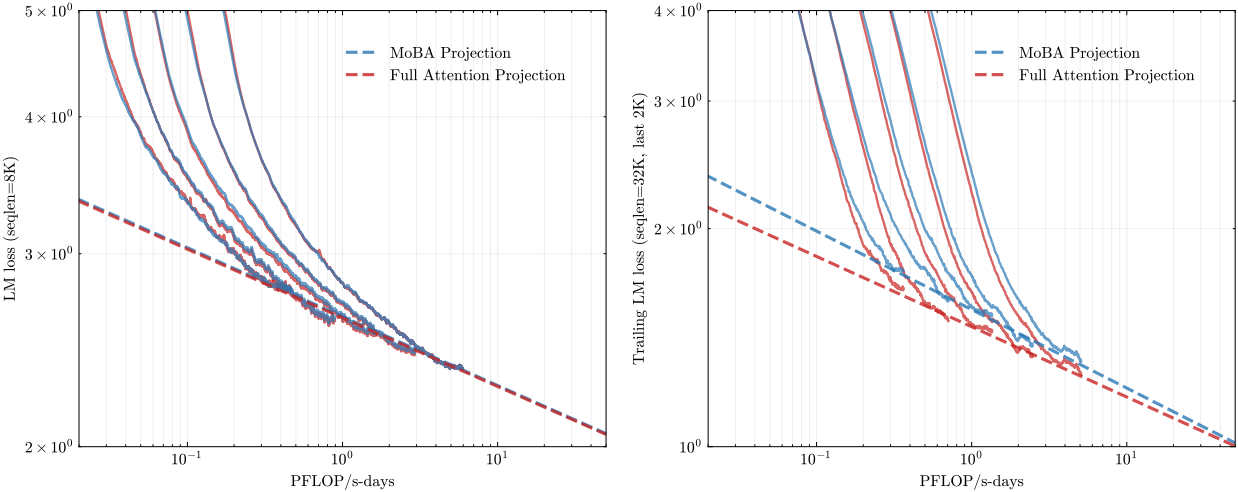
다음은 (위) scaling law 실험에 사용된 모델의 구성과 (아래) scaling law 결과이다.

다음은 블록 세분화에 대한 ablation 결과이다. (validation set에서의 LM loss)
2. Hybrid of MoBA and Full Attention
다음은 MoBA와 full attention을 결합한 결과이다.
3. Large Language Modeling Evaluation
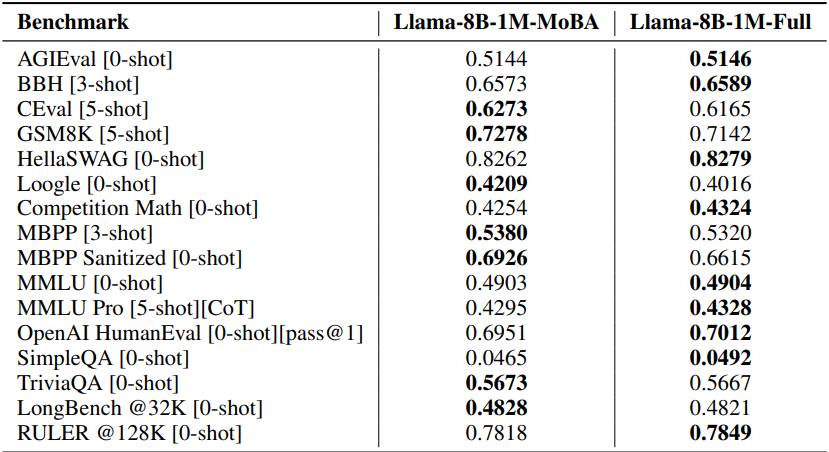
다음은 MoBA와 full attention을 다양한 벤치마크에서 비교한 결과이다.
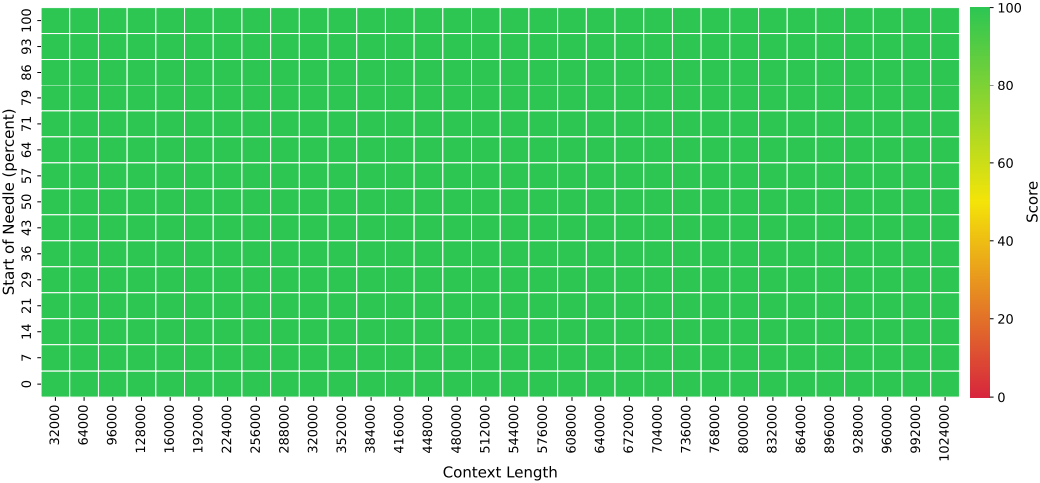
다음은 LLama-8B-1M-MoBA에 대한 Needle in the Haystack 결과이다.
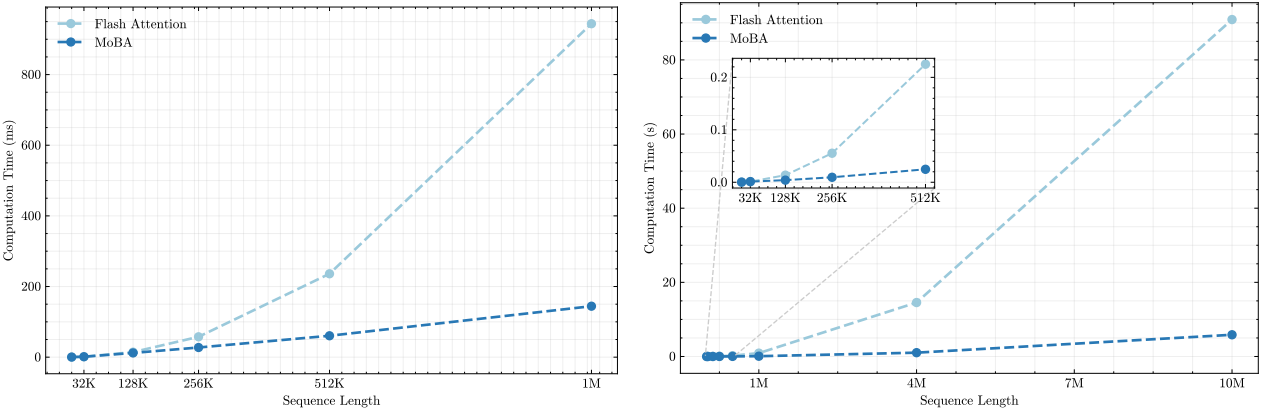
4. Efficiency and Scalability
다음은 MoBA와 full attention의 효율성을 시퀀스 길이에 따른 연산 시간으로 비교한 그래프들이다.