[논문리뷰] Mixture-of-Agents Enhances Large Language Model Capabilities
ICLR 2025 (Spotlight). [Paper] [Github]
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, James Zou
Together AI | Duke University | University of Chicago | Stanford University
7 Jun 2024
Introduction
LLM은 방대한 양의 데이터에 대해 사전 학습된 후 인간의 선호도에 맞춰 조정되어 유용하고 일관된 결과를 생성한다. 그러나 여전히 모델 크기와 학습 데이터에 대한 본질적인 제약에 직면해 있다. LLM을 추가로 확장하려면 비용이 매우 많이 들고, 종종 수조 개의 토큰에 대한 광범위한 재학습이 필요하다.
동시에 다양한 LLM은 고유한 강점을 보유하고 있으며 다양한 task를 전문으로 한다. 예를 들어 일부 모델은 복잡한 명령을 따르는 데 탁월한 반면 다른 모델은 코드 생성에 더 적합할 수 있다. 다양한 LLM 사이의 다양성은 흥미로운 질문을 제시한다.
여러 LLM의 집단적 전문 지식을 활용하여 보다 유능하고 강력한 모델을 만들 수 있을까?
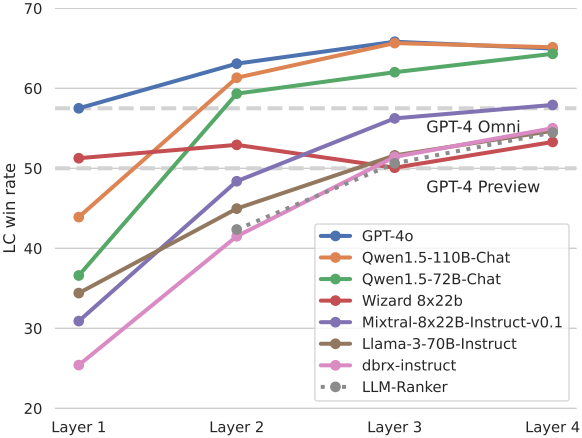
이 질문에 대한 본 논문의 대답은 ‘그렇다’이다. 저자들은 LLM의 협업성(collaborativeness)이라고 부르는 고유한 현상을 식별하였다. LLM은 자체의 능력이 떨어지더라도 다른 모델의 결과가 제시될 때 더 나은 응답을 생성하는 경향이 있다. 아래 그래프는 6개의 인기 LLM에 대한 AlpacaEval 2.0 벤치마크의 LC (length-controlled) 승률을 보여준다.
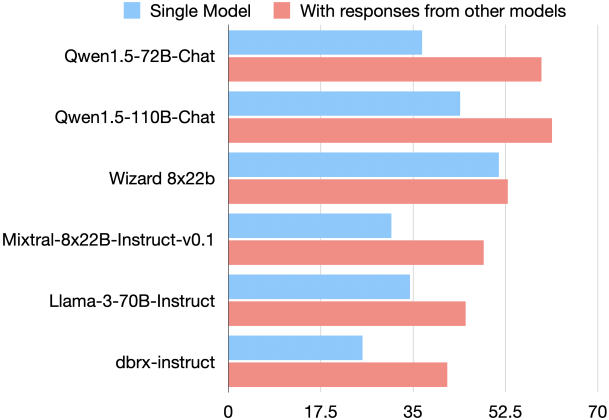
모델에 독립적으로 생성된 답변이 제공되면 LC 승률이 크게 향상된다. 이는 협업 현상이 LLM 간에 널리 퍼져 있음을 나타낸다. 놀랍게도 이러한 개선은 다른 모델에서 제공하는 보조 응답의 품질이 개별 LLM이 독립적으로 생성할 수 있는 것보다 낮은 경우에도 발생한다.
본 논문은 이러한 발견을 바탕으로 여러 LLM을 활용하여 생성 품질을 반복적으로 향상시키는 Mixture-of-Agents (MoA) 방법론을 소개한다. 처음에는 에이전트 첫 번째 레이어의 LLM이 주어진 프롬프트에 대한 응답을 독립적으로 생성한다. 그런 다음 이러한 응답은 추가 개선을 위해 다음 레이어의 에이전트에 제공된다 (첫 번째 레이어의 모델을 재사용할 수 있음). 이러한 반복적인 개선 프로세스는 보다 강력하고 포괄적인 응답을 얻을 때까지 여러 주기 동안 계속된다.
모델 간의 효과적인 협업을 보장하고 전반적인 응답 품질을 향상하려면 각 MoA 레이어에 대한 LLM을 신중하게 선택하는 것이 중요하다. 이 선택 프로세스는 두 가지 기준에 따라 진행된다.
- 성능: $i$번째 레이어에 있는 모델의 평균 승률은 $i+1$번째 레이어에 포함하기에 적합한지 결정하는 데 중요한 역할을 한다. 따라서 성능을 기반으로 모델을 선택한다.
- 다양성: 모델 결과의 다양성도 중요하다. 다양한 모델에 의해 생성된 응답은 동일한 모델에 의해 생성된 응답보다 훨씬 더 많은 기여를 한다.
MoA는 성능과 다양성이라는 기준을 활용하여 개별 모델의 결함을 완화하고 협업을 통해 전반적인 응답 품질을 향상시키는 것을 목표로 한다.
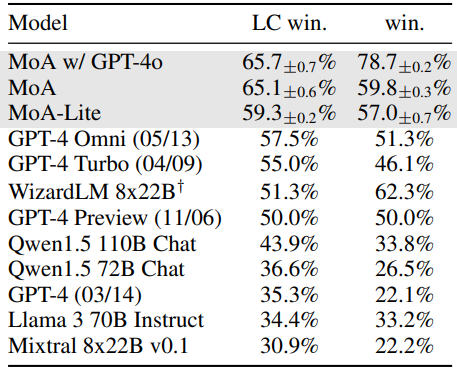
저자들은 다양한 기준으로 응답 품질을 평가하기 위해 AlpacaEval 2.0, MT-Bench, FLASK 벤치마크를 사용하여 종합적인 평가를 수행하였다. 결과는 GPT-4 Omni가 AlpacaEval 2.0에서 달성한 최고 승률 57.5%를 넘어 65.8%의 새로운 SOTA 승률을 달성하여 상당한 개선을 보여주었다.
Method
1. Collaborativeness of LLMs
여러 LLM의 협업에서 최대 이점을 얻는 중요한 경로는 협업의 다양한 측면에서 다양한 모델이 얼마나 뛰어난지 특성을 파악하는 것이다. 협업 프로세스 중에 LLM을 두 가지 역할로 분류할 수 있다.
- Proposer는 다른 모델에서 사용할 수 있는 유용한 참조 응답을 생성하는 데 탁월하다. 좋은 proposer 자체가 반드시 높은 점수를 받는 응답을 생성할 수는 없지만, 더 많은 맥락과 다양한 관점을 제공해야 하며, 궁극적으로 aggregator가 사용할 때 더 나은 최종 응답에 기여해야 한다.
- Aggregator는 다른 모델의 응답을 하나의 고품질 출력으로 합성하는 데 능숙한 모델이다. 효과적인 aggregator는 자신보다 품질이 낮은 입력을 통합하는 경우에도 출력 품질을 유지하거나 향상해야 한다.
저자들은 aggregator와 proposer의 역할을 경험적으로 검증하였다. 특히, 많은 LLM이 aggregator와 proposer로서의 역량을 모두 보유하고 있는 반면, 특정 모델은 서로 다른 역할에서 전문적인 능력을 보여준다. GPT-4o, Qwen1.5, LLaMA-3는 두 역할 모두에 효과적이었지만, WizardLM은 proposer 모델로서만 뛰어난 성능을 보였다.
Aggregator가 다른 모델의 결과를 바탕으로 더 높은 품질의 응답을 생성할 수 있다는 점을 고려하여 추가 aggregator를 도입하여 이러한 협업 가능성을 더욱 강화한다. 한 가지 직관적인 아이디어는 처음에 여러 aggregator를 사용하여 더 나은 답변을 집계한 다음 이러한 집계된 답변을 다시 집계하는 것이다. 더 많은 aggregator를 프로세스에 통합함으로써 여러 모델의 강점을 활용하여 우수한 결과를 생성하면서 응답을 반복적으로 종합하고 개선할 수 있다.
2. Mixture-of-Agents
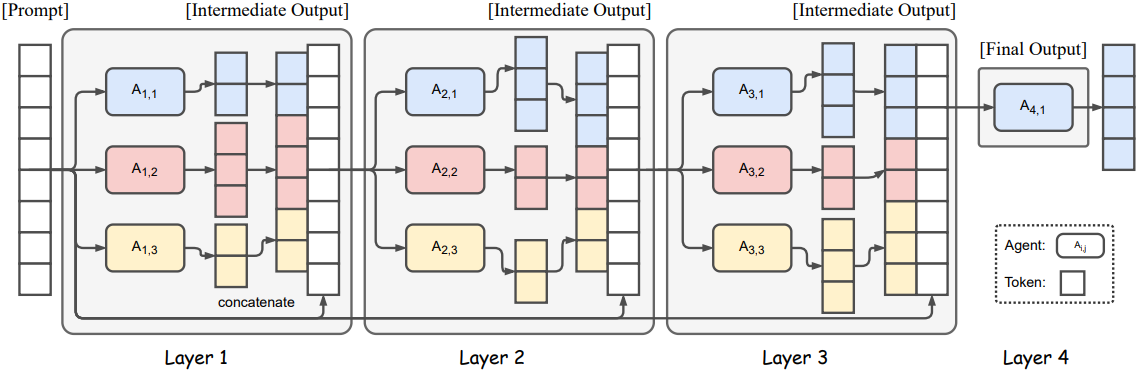
MoA의 구조는 위 그림 2에 나와 있다. MoA는 $l$개의 레이어를 가지고 있으며 각 $i$번째 레이어는 $n$개의 LLM \(A_{i,1}, A_{i,2}, \ldots, A_{i,n}\)으로 구성된다. LLM은 동일한 레이어 내에서 또는 다른 레이어에서 재사용될 수 있다. 레이어의 많은 LLM이 동일한 경우 temperature 샘플링의 stochasticity로 인해 여러 개의 서로 다른 출력을 생성하는 모델에 해당한다. 이 설정을 single-proposer라고 부르며, 모델의 부분 집합만 활성화된다.
각 LLM \(A_{i,j}\)는 입력 텍스트를 처리한다. 본 논문의 방법은 fine-tuning이 필요하지 않으며 LLM 프롬프트와 생성 인터페이스만 활용한다. 입력 프롬프트 $x_1$이 주어지면 $i$번째 MoA 레이어 $y_i$의 출력은 다음과 같이 표현될 수 있다.
\[\begin{equation} y_i = \oplus_{j=1}^n [A_{i,j} (x_i)] + x_1, \quad x_{i+1} = y_i \end{equation}\]여기서 $+$는 텍스트의 concatenation을 의미하며, $\oplus$는 아래 표와 같은 Aggregate-and-Synthesize 프롬프트를 모델 출력에 적용함을 의미한다.

실제로는 프롬프트와 모든 모델 응답을 concatenate할 필요가 없으므로 마지막 레이어에 하나의 LLM만 사용하면 된다. 따라서 $l$번째 레이어의 LLM 출력 \(A_{l,1} (x_l)\)을 최종 출력으로 사용한다.
3. Analogy to Mixture-of-Experts
Mixture-of-Experts (MoE)는 여러 expert 네트워크가 다양한 기술을 전문으로 하는 잘 확립된 기술이다. MoE는 복잡한 문제 해결을 위해 다양한 모델의 능력을 활용할 수 있어 다양한 응용 분야에서 상당한 성공을 거두었다.
일반적인 MoE 디자인은 MoE layer로 알려진 레이어 스택으로 구성된다. 각 레이어는 gating network와 함께 $n$개의 expert 네트워크들로 구성되며 향상된 gradient flow를 위한 residual connection을 포함한다. 레이어 $i$의 경우 이 디자인은 다음과 같이 표현될 수 있다.
\[\begin{equation} y_i = \sum_{j=1}^n G_{i,j} (x_i) E_{i,j} (x_i) + x_i \end{equation}\]여기서 \(G_{i,j}\)는 expert $j$에 해당하는 gating network의 출력이고, \(E_{i,j}\)는 expert $j$에 의해 계산된 함수이다. 여러 expert의 활용을 통해 모델은 다양한 기술을 학습하고 현재 task의 다양한 측면에 집중할 수 있다.
높은 수준의 관점에서 MoA 프레임워크는 activation 수준이 아닌 모델 수준에서 작동하여 MoE를 모델 수준으로 확장한다. 특히 MoA는 LLM을 활용하고 내부 activation 또는 가중치에 대한 수정을 요구하지 않고 프롬프트 인터페이스에 전적으로 작동한다. 이는 MoE와 같이 하나의 모델 내에 전문화된 하위 네트워크를 갖는 대신 다양한 레이어에 걸쳐 여러 LLM을 활용한다는 것을 의미한다. MoA에서는 LLM을 사용하여 gating network와 expert 네트워크의 역할을 통합한다. LLM의 본질적인 능력을 통해 외부 메커니즘 없이 프롬프트를 해석하고 일관된 출력을 생성하여 입력을 효과적으로 정규화할 수 있기 때문이다.
또한 MoA는 기존 모델에 내재된 프롬프팅 능력에만 의존하기 때문에 fine-tuning과 관련된 계산 오버헤드가 없으며 유연성과 확장성을 제공한다. MoA는 크기나 아키텍처에 관계없이 최신 LLM에 적용할 수 있다.
Evaluation
저자들은 경쟁력 있는 성과를 달성하기 위해 오픈소스 모델만 사용하여 기본 MoA를 구축했다. 포함된 모델은 다음과 같다.
- Qwen1.5-110B-Chat
- Qwen1.5-72B-Chat
- WizardLM-8x22B
- LLaMA-3-70B-Instruct
- Mixtral-8x22B-v0.1
- dbrx-instruct
저자들은 3개의 MoA 레이어를 구성하고 각 MoA 레이어에 동일한 모델 세트를 사용하였다. 마지막 레이어의 aggregator는 Qwen1.5-110B-Chat이다.
MoA w/ GPT-4o는 GPT-4o를 최종 MoA 레이어의 aggregator로 사용하여 고품질 출력을 우선시하는 변형 모델이다.
MoA-Lite는 2개의 MoA 레이어만 포함하고 Qwen1.5-72B-Chat을 aggregator로 사용하는 변형 모델이다. MoA-Lite는 AlpacaEval 2.0에서 품질을 1.8% 향상시키면서 GPT-4o보다 효율적이다.
1. Benchmark Results
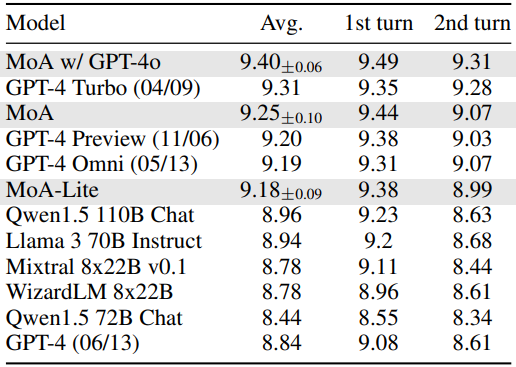
다음은 (왼쪽) AlpacaEval 2.0와 (오른쪽) MT-Bench에서의 결과이다.
다음은 FLASK에서의 결과이다.
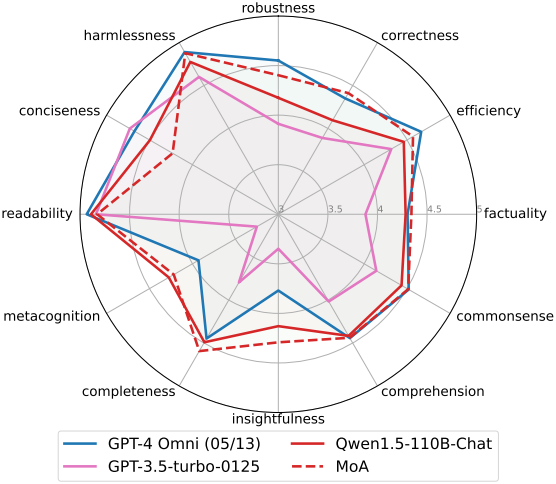
2. What Makes Mixture-of-Agents Work Well?
MoA는 LLM 랭커들보다 훨씬 뛰어난 성능을 발휘한다
다음은 다양한 aggregator에 대한 AlpacaEval 2.0의 LC 승률이다. 모든 MoA는 동일한 6개의 proposer 에이전트를 사용하며, 최종 aggregator만 다르다. LLM 랭커는 Qwen1.5-110B-Chat 모델이다. GPT-4o 모델은 출력을 집계하는 데만 사용되며 다음 레이어에 대한 proposer로 참여하지 않는다.
MoA는 제안된 가장 좋은 답변을 통합하는 경향이 있다
다음은 반영하는 BLEU 점수 (3-gram, 4-gram, 5-gram)를 통해 aggregator의 응답과 proposer의 응답을 비교한 결과이다. 각 샘플 내에서 proposer가 제안한 $n$개의 답변을 바탕으로 $n$개의 BLEU 점수와 GPT-4가 평가한 $n$개의 선호도 점수 사이의 Spearman 상관 계수를 계산한 결과이다.
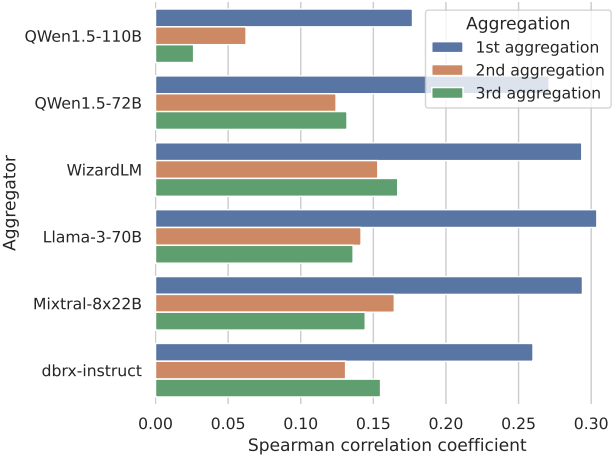
위 그래프의 결과는 실제로 승률과 BLEU 점수 사이에 양의 상관관계가 있음을 확인시켜 준다.
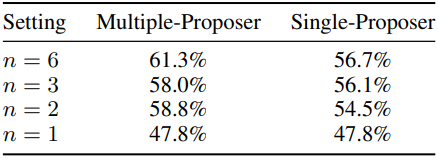
모델 다양성과 proposer 수의 영향
다음은 AlpacaEval 2.0에서 proposer 모델들의 수에 따른 영향을 비교한 표이다. $n$은 MoA 레이어의 에이전트 수 또는 single-proposer 설정에서 제안된 출력 수이다. Aggregator는 Qwen1.5-110B-Chat이며, 2개의 MoA 레이어를 사용하였다.
MoA 생태계의 모델 전문화
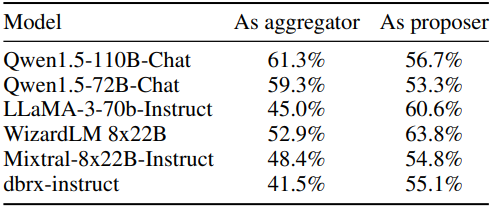
다음은 proposer와 aggregator 역할을 하는 다양한 모델의 영향을 비교한 표이다. Aggregator로 평가할 때 6개 모델 모두 proposer 역할을 한다. Proposer를 평가할 때는 Qwen1.5-110B-Chat이 aggregator 역할을 한다. 2개의 MoA 레이어를 사용하였다.
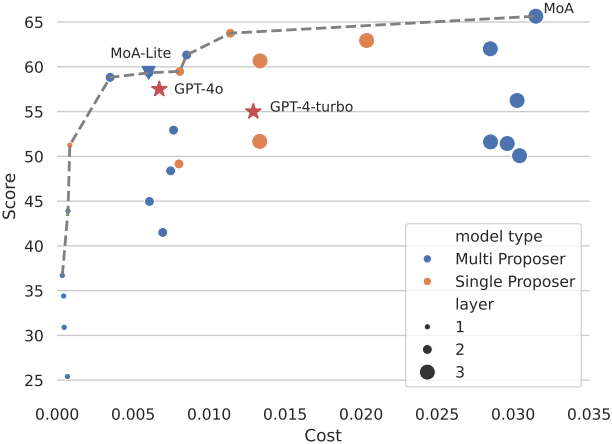
3. Budget and Token Analysis
다음은 성능과 비용 사이의 trade-off를 나타낸 그래프이다.
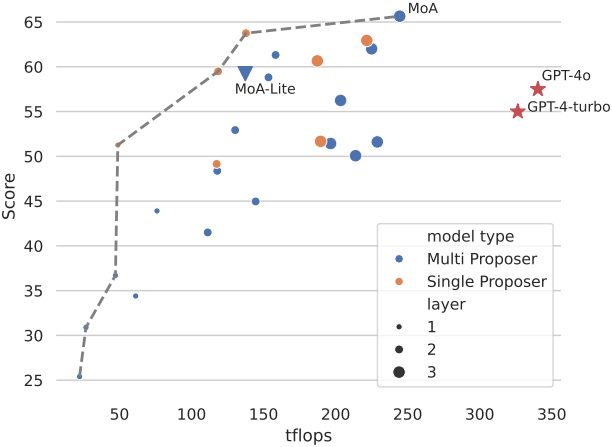
다음은 성능과 Tflops 사이의 trade-off를 나타낸 그래프이다.
Limitations
MoA는 모델 응답의 반복적인 집계가 필요하다. 이는 모델이 마지막 MoA 레이어에 도달할 때까지 첫 번째 토큰을 결정할 수 없음을 의미한다. 이로 인해 잠재적으로 Time to First Token (TTFT)이 길어져 사용자 경험에 부정적인 영향을 미칠 수 있다. 첫 번째 응답 집계가 생성 품질을 가장 크게 향상시키므로 이 문제를 완화하기 위해 MoA 레이어 수를 제한할 수 있다.