[논문리뷰] MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
CVPR 2023. [Paper] [Github]
Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, Baining Guo
Renmin University of China | Peking University | Microsoft Research
19 Dec 2022
Introduction
이미지, 동영상, 오디오 도메인에서 AI 기반 콘텐츠 생성은 최근 몇 년 동안 많은 관심을 끌었다. 예를 들어 DALL·E 2와 DiffWave는 각각 생생한 이미지와 고품질 오디오를 생성할 수 있다. 그러나 이렇게 생성된 콘텐츠는 single-modality 경험만 제공할 수 있으며, multi-modal 콘텐츠를 포함하는 인간이 만든 웹 콘텐츠와는 여전히 큰 격차가 있다. 본 논문에서 특히 열린 도메인에서 joint audio-video generation에 중점을 둔 새로운 multi-modality 생성 task를 연구하기 위해 한 걸음 더 나아간다.
생성 모델의 최근 발전은 diffusion model을 사용하여 이루어졌다. Task 레벨 관점에서 unconditional diffusion model과 conditional diffusion model의 두 가지 범주로 나눌 수 있다. Unconditional diffusion model은 가우시안 분포에서 샘플링된 noise를 입력으로 받아 이미지와 동영상을 생성한다. Conditional diffusion model은 일반적으로 하나의 modality에서 임베딩 기능과 결합된 샘플링된 noise를 가져오고 다른 modality를 출력으로 생성한다. 그러나 대부분의 기존 diffusion model은 single-modality 콘텐츠만 생성할 수 있으며, Multi-modal 생성을 위해 diffusion model을 활용하는 방법은 여전히 거의 연구되지 않는다.
Multimodal diffusion model 디자인의 어려움은 주로 다음 두 가지 측면에 있다. 첫째, 동영상와 오디오는 데이터 패턴이 서로 다르다. 특히 동영상은 일반적으로 공간과 시간적 차원 모두에서 RGB 값을 나타내는 3D 신호로 표현되는 반면 오디오는 시간적 차원에서 1D 파형 숫자로 표시된다. 하나의 joint diffusion model 내에서 병렬로 처리하는 방법은 여전히 문제로 남는다. 둘째, 동영상과 오디오는 실제 동영상에서 시간적 차원에서 동기화되므로 모델이 이 두 modality 간의 관련성을 캡처하고 서로에 대한 상호 영향을 미치도록 만들어야 한다.
이와 같은 어려움을 해결하기 위해 본 논문은 joint audio-video generation을 위한 첫번째 Multi-Modal Diffusion model (MM-Diffusion)을 제안한다. Timestep $t - 1$에서 각 modality의 noise가 적은 샘플은 timestep $t$에서 denoise되어 두 modality의 출력이 생성된다. 이러한 디자인을 통해 두 modality에 대한 결합 분포를 학습할 수 있다. 의미론적 동기성을 더 배우기 위해, 생성된 동영상 프레임과 오디오 세그먼트가 매 순간 상관될 수 있도록 하는 새로운 cross-modal attention block을 제안한다. 주어진 동영상 프레임과 인접한 기간에 임의로 샘플링된 오디오 세그먼트 간에 cross-attention를 수행하는 효율적인 random-shift 메커니즘을 디자인하여 동영상과 오디오의 시간적 중복을 크게 줄이고 cross-modal 상호 작용을 효율적으로 촉진한다.
Approach
1. Preliminaries of Vanilla Diffusion
DDPM 논문리뷰 참고
2. Multi-Modal Diffusion Models
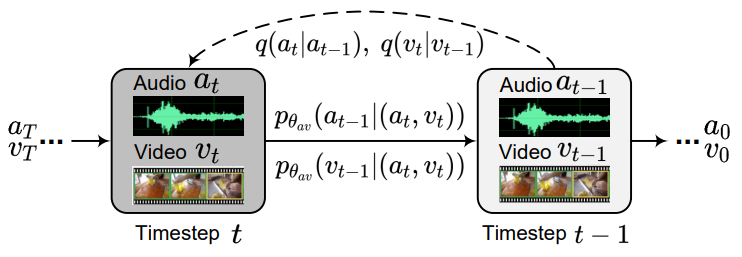
단일 modality가 생성되는 vanilla diffusion과 달리, 위 그림과 같이 본 논문의 목표는 하나의 diffsion process 내에서 두 개의 일관된 modality를 복구하는 것이다.
1D 오디오 데이터셋 $A$와 3D 동영상 데이터셋 $V$애서 데이터 $(a, v)$가 주어지면, 둘의 분포가 다르기 때문에 각 modality의 독립적인 forward process를 고려할 수 있다. $t$에서의 forward procss는 다음과 같이 정의된다.
\[\begin{equation} q(a \vert a_{t-1}) = \mathcal{N}_a (a_t; \sqrt{1 - \beta_t} a_{t-1}, I), \quad t \in [1,T] \\ q(v \vert v_{t-1}) = \mathcal{N}_v (v_t; \sqrt{1 - \beta_t} v_{t-1}, I), \quad t \in [1,T] \\ \end{equation}\]Forward process가 독립적인 것과 달리, reverse process에서는 두 modality의 상관관계를 고려하여야 한다. 따라서, 바로 $q(a_{t-1} \vert a_t, a_0)$와 $q(v_{t-1} \vert v_t, v_0)$를 모델링하는 대신 unified model $\theta_{av}$를 사용하며, 두 modality를 입력으로 받아 서로의 품질을 개선한다. 특히, timestep $t$에서 reverse process는 다음과 같다.
\[\begin{equation} p_{\theta_{av}} (a_{t-1} \vert (a_t, v_t)) = \mathcal{N} (a_{t-1}; \mu_{\theta_{av}} (a_t, v_t, t)) \end{equation}\]전체 신경망을 최적화하기 위하여 다음과 같은 $\epsilon$-예측을 사용한다.
\[\begin{equation} \mathcal{L}_{\theta_{av}} = \mathbb{E}_{\epsilon \sim \mathcal{N}_a (0,I)} [\lambda (t) \| \tilde{\epsilon}_\theta (a_t, v_t, t) - \epsilon \|_2^2 ] \end{equation}\]$\lambda (t)$는 가중치 함수이다. 동영상에 대한 공식은 오디오와 비슷하게 표현된다.
Multi-modality 생성의 핵심 이점은 독립적인 가우스 분포에서 오디오-동영상 쌍을 공동으로 재구성할 수 있는 $\theta_{av}$에 있다. MM-Diffusion은 완전히 다른 모양과 패턴으로 이러한 두 가지 유형의 입력 modality를 적용할 수 있다.
3. Coupled U-Net for Joint Audio-Video Denoising
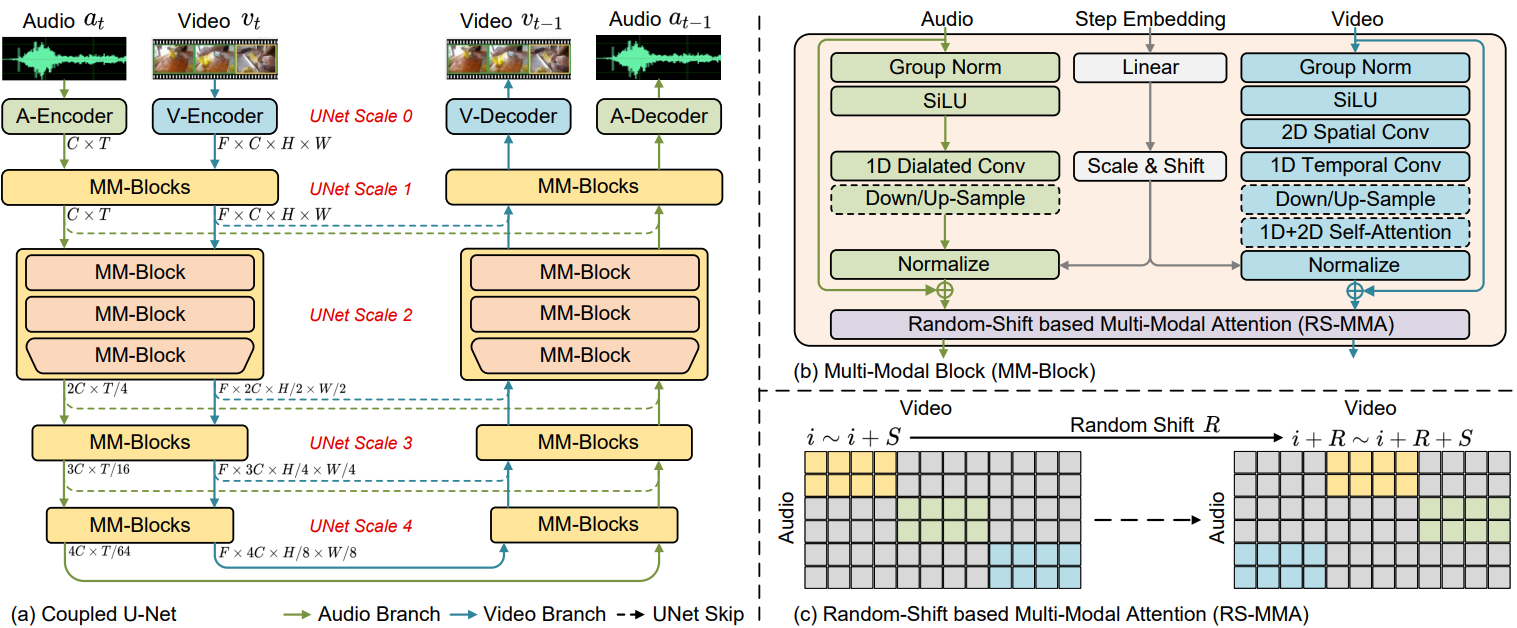
이전 연구에서는 U-Net을 모델 아키텍처로 사용하여 단일 modality를 생성하는 효과를 입증했다. 저자들은 이러한 연구에서 영감을 받아 오디오와 동영상 생성을 위한 두 개의 단일 modality U-Net으로 구성된 결합된 U-Net을 제안한다. (위 그림의 (a) 참고)
특히 입력 오디오와 동영상을 텐서 쌍 $(a, v) \in (A, V)$로 공식화한다. $a \in \mathbb{R}^{C \times T}$는 오디오 입력을 의미하며, $C$와 $T$는 각각 채널과 시간 차원이다. $v \in \mathbb{R}^{F \times C \times H \times W}$는 동영상 입력을 나타내며, 여기서 $F$, $C$, $H$, $W$는 각각 프레임 번호, 채널, 높이, 너비 차원이다.
Efficient Multi-Modal Blocks
위 그림의 (b)와 같이 동영상 sub-network 디자인을 위해 공간과 시간 차원을 분해하여 공간과 시간 정보를 효율적으로 모델링한다. 무거운 3D convolution을 사용하는 대신 동영상 인코더로 1D convolution 다음에 2D convolution을 쌓는다. 마찬가지로 동영상 attention 모듈은 2D와 1D attention으로 구성된다. 동영상과비디오와 달리 오디오 신호는 장기 종속성 모델링에 대한 요구가 더 높은 긴 1D 시퀀스이다. 따라서 오디오 블록을 위한 두 가지 특수 설계가 있다. 먼저 순수한 1D convolution을 채택하는 대신 dilated convolution 레이어를 쌓는다. Dilation은 1에서 $2^N$으로 두 배가 된다. 여기서 $N$은 hyperparameter다. 둘째, 계산량이 많고 예비 실험에서 제한된 효과를 보인 오디오 블록의 모든 시간적 attention를 삭제한다.
Random-Shift based Multi-Modal Attention
오디오와 동영상의 두 sub-network를 연결하고 이들의 alignment를 공동으로 학습하기 위한 가장 간단한 방법은 둘의 feature에 대한 cross-attention을 수행하는 것이다. 그러나 이 두가지 modality에 대한 attention map은 $O((F \times H \times W) \times T)$의 복잡성을 가지므로 계산하기에 너무 크다. 한편, 동영상과 오디오는 모두 시간적으로 중복되므로 모든 cross-modal attention 계산이 필요한 것은 아니다.
위 그림의 (c)와 같이, 이 문제를 해결하기 위해 저자들은 동영상과 오디오를 효율적인 방법으로 정렬하기 위해 Multi-Modal Attention mechanism with Random Shift-based attetion mask (RS-MMA)를 제안하였다. 구체적으로, coupled U-Net의 $l$번째 layer의 출력의 모양이 \(\{H^l \times W^l \times C^l \times T^l\}\)이라면 $F$개의 프레임으로 이루어진 3D 동영상 입력 텐서 $v$는 $F \times H^l \times W^l$개의 패치들로 표현할 수 있고, 1D 오디오 입력 텐서 $a$는 $C^l \times T^l$로 표현할 수 있다.
동영상 프레임과 오디오 신호를 더 잘 정렬하기 위하여 저자들은 다음과 같은 random-shift attention 방식을 제안하였다.
- 먼저 오디오를 동영상 프레임의 timestep에 맞춰 segment \(a_1, a_2, \cdots, a_F\)로 나눈다. 각 $a_i$의 모양은 $c^l \times (T^l / F)$이다.
- $F$보다 작은 window size $S$를 설정하고, random-shift number $R \in [0, F-S]$를 설정한다. 오디오에서 동영상으로의 attention 가중치는 각 오디오 segment $a_i$와 동영상 segment $v_j$ 사이에서 계산되며, 이는 프레임 $f_s = (i + R) \% F$부터 프레임 $f_e = (i + R + S) \% F$까지에 해당한다.
- $a_i$와 $v_j = v_{f_s : f_e}$의 cross attention은 아래 공식으로 계산된다.
($d_k$는 $K$의 차원이고 $\textrm{MMA}(v_j, a_i)$도 동일)
이 attention mechanism은 두 가지 장점이 있다.
- 계산 복잡도가 $O((S \times H \times W) \times (S \times T/F))$로 감소한다.
- 디자인이 주변에 대한 global attention 능력을 유지한다.
MM-Diffusion이 step $T$에서 0까지 반복되므로 reverse process 동안 동영상과 오디오가 충분히 상호 작용할 수 있다. 실제로 U-Net의 윗 부분에서는 작은 $S$를 사용하여 fine한 상관관계를 캡처하도록 설정하였고, 아랫 부분에서는 큰 $S$를 사용하여 높은 레벨의 의미론적 상관관계를 캡처하도록 하였다.
4. Zero-Shot Transfer to Conditional Generation
MM-Diffusion 모델은 unconditional 오디오-동영상 쌍 생성을 위해 학습되었지만 zero-shot transferring 방식으로 조건부 생성에도 활용할 수 있다. 모델이 이 두 양식 간의 상관 관계를 학습했기 때문에 강력한 zero-shot 조건부 생성 성능은 MM-Diffusion의 우수한 모델링 기능을 확인하는 데 도움이 될 수 있다. 실제로 Video Diffusion에서 영감을 받아 조건부 생성을 위해 두 가지 방법을 사용한다.
- Replacement-based method
- Gradient-guided method
Replacement-based 방법은 오디오 $a$를 동영상 $v$를 조건으로 하여 생성하기 위하여 각 step $t$에서 reverse process $p_{\theta_{av}} (a_t \vert (a_{t+1}, v_{t+1}))$의 $v_{t+1}$을 forward process \(q(\hat{v}_{t+1} \vert v)\)에서 샘플링한 \(\hat{v}_{t+1}\)로 대체하는 방법이다. 동영상을 오디오를 조건으로 하여 생성할 때도 비슷한 연산을 수행한다. 하지만, 강한 조건부 guidance를 제공하는 $v$가 무시될 수 있다. 따라서, 여기에 gradient-guided 방법을 추가로 사용한 변형된 공식을 사용한다.
\[\begin{equation} \mathbb{E}_q (a_t \vert (a_{t+1}, \hat{v}_{t+1}, v)) = \mathbb{E}_q (a_t \vert (a_{t+1}, \hat{v}_{t+1})) + \frac{1}{\sqrt{1 - \bar{\alpha}_t}} \nabla_{a_t} \log q (v_t \vert (a_{t+1}, \hat{v}_{t+1})) \\ \alpha = 1 - \beta, \quad \bar{\alpha}_t = \prod_{s=1}^t \alpha_s \end{equation}\]따라서, 다음 공식으로 오디오 $\tilde{a}_t$를 생성할 수 있다.
\[\begin{aligned} a_t, v_t &= \theta_{av} (a_{t+1}, \hat{v}_{t+1}), \\ \tilde{a}_t &= a_t - \lambda \sqrt{1 - \bar{\alpha}_t} \nabla_{a_t} \| v_t - \hat{v}_t \|_2^2 \end{aligned}\]이 공식은 $\lambda$가 컨디셔닝의 강도를 제어하는 기울기 가중치 역할을 하는 classifier-free conditional generation와도 유사하다. 주요 차이점은 전통적인 조건부 생성 모델은 조건 데이터에 맞추기 위해 종종 명시적 학습이 필요하다는 것이다. 따라서 샘플링 절차의 업데이트 프로세스는 조건을 변경할 필요가 없다. 반대로 unconditional한 학습 과정에 맞추려면 gradient-guided 방법의 조건부 입력은 reverse process가 진행됨에 따라 지속적인 교체가 필요하다. 결과적으로 조건부 입력에 적응하기 위해 추가 학습이 필요하지 않다.
Experiments
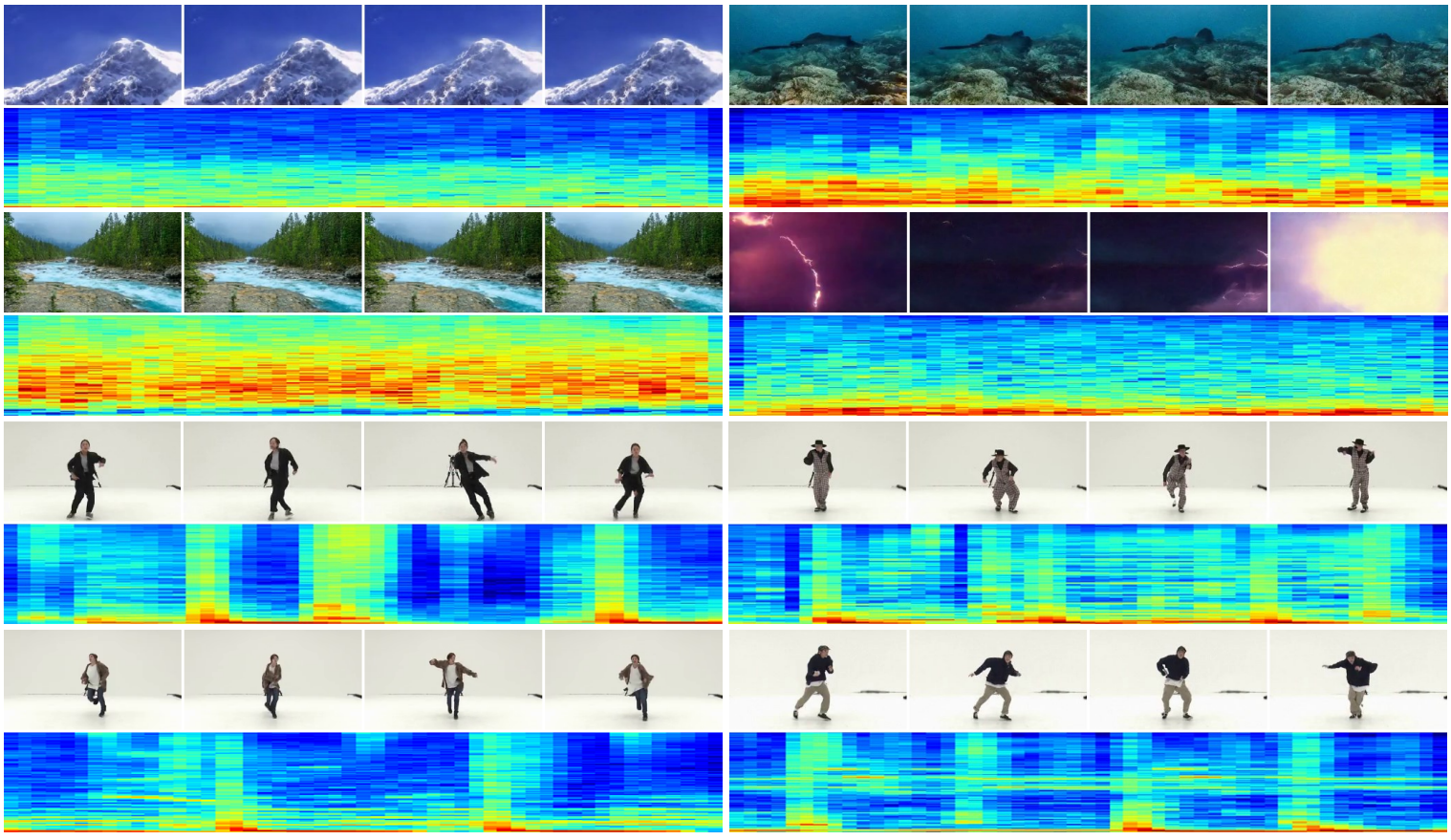
- 데이터셋: Landscape, AIST++
- Implementation Details
- Diffusion model: 샘플링을 가속하기 위하여 DPM-Solver를 사용. 공정한 평가를 위해 DPM-Solver의 설정을 따름.
- Model architecture
- Coupled U-Net으로 16$\times$3$\times$64$\times$64 크기의 동영상과 1$\times$25600 크기의 오디오를 생성하고, SR model을 사용하여 64에서 256으로 스케일링.
- Base coupled U-Net은 4개의 MM-Blocks으로 구성. 각 MM-Blocks은 2개의 일반 MM-Block과 1개의 down/up-sample block으로 구성
- U-Net scale [2, 3, 4]에서 동영상 attention과 cross-modal attention 적용
- Cross-modal attention의 각 window size는 [1, 4, 8]
- SR 모델은 ADM의 구조와 세팅 사용
- 전체 파라미터는 1억 1513만 개 (SR 모델은 3억 1103만 개)
1. Objective Comparison with SOTA methods
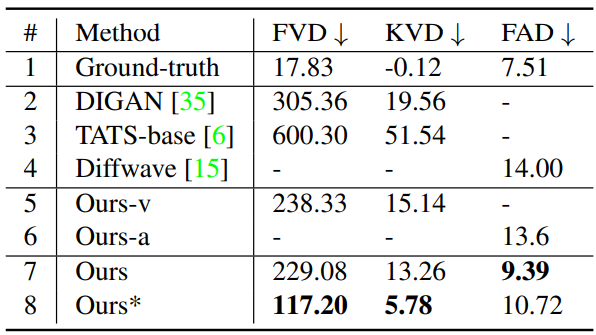
다음은 Landscape 데이터셋에서의 single-modal 방법들과의 비교이다. *는 완전한 DDPM 샘플링을 사용한 경우이다.
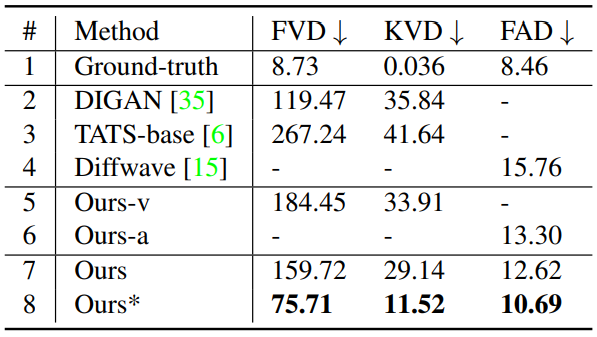
다음은 AIST++ 데이터셋에서의 single-modal 방법들과의 비교이다.
2. Ablation Studies
Random-Shift based Multi-modal Attention
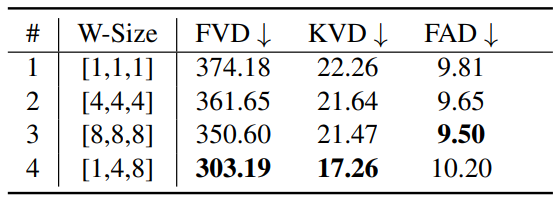
다음은 여러 window size에 대한 ablation study 결과를 나타낸 표이다.
다음은 여러 학습 step에서 random-shift attention의 유무에 따른 동영상과 오디오의 품질이다.

Zero-Shot Conditional Generation
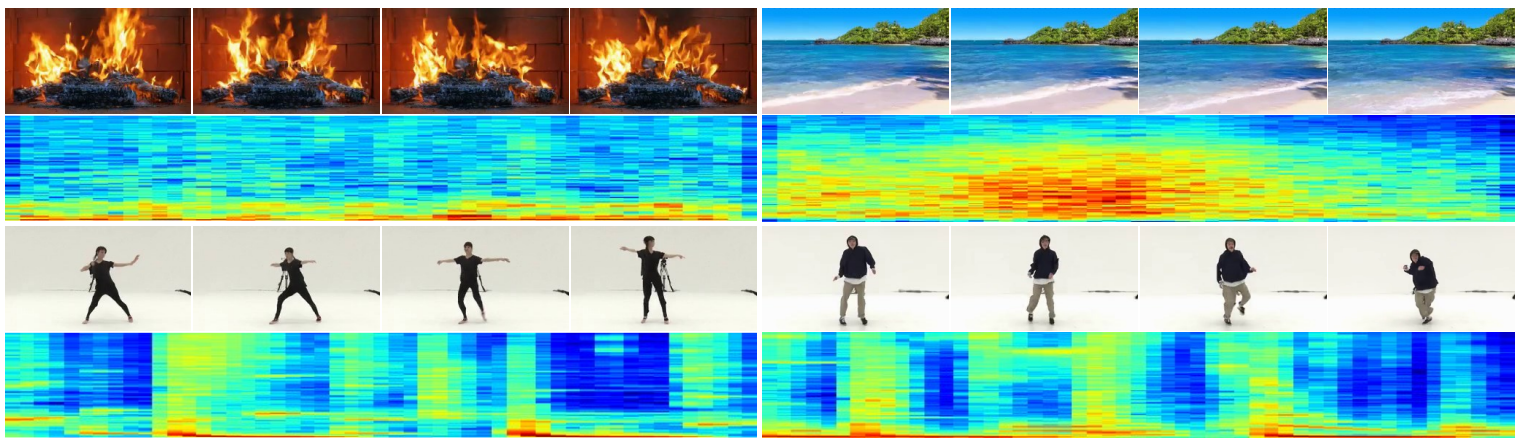
저자들은 zero-shot transferring을 위한 두 가지 방법의 효율성을 검증하고 두 가지 모두 동영상을 조건으로 사용하여 고품질 오디오를 생성할 수 있음을 발견했다. 다음 그림은 조건부 생성을 위한 zero-shot transferring에 의해 생성된 여러 샘플을 랜덤하게 선택한 것이다.
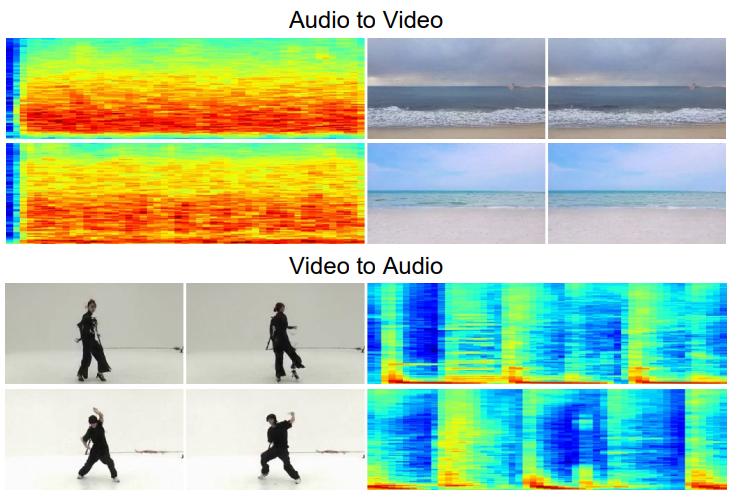
MM-Diffusion이 유사한 패턴의 오디오에서 유사한 장면의 동영상을 생성하고 입력된 댄스 동영상의 리듬과 일치하는 오디오를 생성할 수 있음을 보여준다.
오디오 기반의 동영상 생성의 경우 replacement 방법이 랜덤한 생성을 이끌고 gradient-guided 방법이 오디오 입력에 의미론적으로나 시간적으로 정렬되는 일관된 동영상을 생성한다. 또한 추가 학습 없이 modality transfer를 할 수 있음을 보여준다.
3. User Studies
Comparison with other Methods
저자들은 동영상 품질, 오디오 품질, 동영상-오디오 관련성로 task를 나누고 Amazon Mechanical Turk를 사용하여 각 task마다 5명씩 유저를 할당하였다. 각 유저마다 9천 개의 투표를 하여 각 task마다 45000개의 투표를 모아 Mean opinion score (5점 만점)를 측정하였다. 그 결과는 아래 표와 같다.
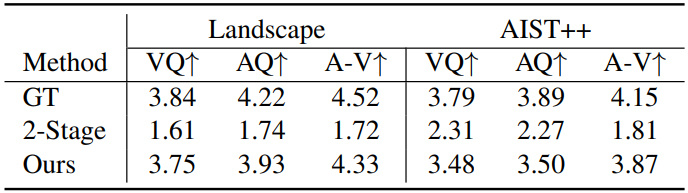
Baseline으로 사용한 2-stage 파이프라인은 2개의 single-modality 모델을 연결한 것으로, SOTA 오디오 diffusion model인 Diffwave와 audio-to-video 모델인 TATS를 연결하였다.
Turing Test
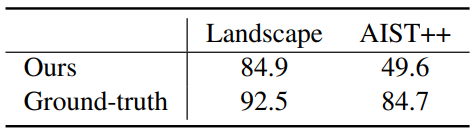
저자들은 생성된 동영상의 현실성을 평가하기 위해 Turing test를 수행하였다. 각 데이터셋에 대하여 MM-Diffusion으로 500개의 오디오-비디오 쌍을 샘플링하고, 500개의 ground-truth와 섞어 1000개의 샘플을 준비한다. 그런 다음 5명의 유저에게 현실의 데이터인지 판단하게 하여 총 1만 개의 투표를 얻는다. 아래 표는 현실의 데이터로 판단한 비율을 퍼센트로 나타낸 것이다.