[논문리뷰] MixFormer: Mixing Features across Windows and Dimensions
CVPR 2022. [Paper] [Github]
Qiang Chen, Qiman Wu, Jian Wang, Qinghao Hu, Tao Hu, Errui Ding, Jian Cheng, Jingdong Wang
Baidu VIS | Chinese Academy of Sciences
6 Apr 2022
Introduction
이미지 분류에서 ViT의 성공은 Transformer를 비전 task에 적용할 수 있는 가능성을 검증하였다. 다운스트림 task에는 여전히 과제가 남아 있다. 특히 고해상도 비전 task의 비효율성과 로컬 관계 포착의 비효율성은 더욱 그렇다. 한 가지 가능한 해결책은 local-window self-attention을 사용하는 것이다. 겹치지 않는 window 내에서 self-attention을 수행하고 채널 차원에 가중치를 공유한다. 이 프로세스는 효율성을 향상시키지만 제한된 receptive field와 취약한 모델링 능력 문제를 야기한다.
Receptive field를 확장하는 일반적인 접근 방식은 window 간 연결을 만드는 것이다. Window는 shift, expand, shuffle, convolution 연산을 통해 연결된다. 자연스러운 로컬 관계를 포착하기 위해 convolution layer도 사용된다. 이전 연구에서는 이를 기반으로 local-window self-attention과 depth-wise convolution을 결합하여 유망한 결과를 제공하였다. 그럼에도 불구하고 연산은 연속적인 단계에서 window 내 관계와 window 간 관계를 캡처하므로 이 두 가지 유형의 관계가 덜 얽혀 있다. 게다가 이러한 시도에서 모델링 약점을 무시하면 feature를 표현 학습의 추가 발전을 방해한다.
본 논문은 이 두 가지 문제를 모두 해결하기 위해 Mixing Block을 제안하였다.
- Local-window self-attention과 depth-wise connection을 병렬 방식으로 결합한다. 병렬 디자인은 window 내 관계와 window 간 관계를 동시에 모델링하여 receptive field를 확대한다.
- 분기 간 양방향 상호 작용을 도입한다. 상호 작용은 가중치 공유 메커니즘으로 인한 한계를 상쇄하고 local-window self-attention과 depth-wise convolution에 대한 보완적인 단서를 각각 제공하여 채널 및 공간 차원의 모델링 능력을 향상시킨다.
위의 디자인은 window와 차원 전반에 걸쳐 보완적인 feature 혼합을 달성하기 위해 통합되었다.
저자들은 블록의 효율성과 효과를 검증하기 위해 MixFormer를 제시하였다. 0.7G (B1) ~ 3.6G (B4) 범위의 계산 복잡도를 갖는 일련의 MixFormer는 이미지 분류, object detection, instance segmentation, semantic segmentation 등을 포함한 여러 비전 task에서 뛰어난 성능을 발휘하도록 구축되었다. ImageNet-1K에 대해서는 EfficientNet을 통해 RegNet과 Swin Transformer를 큰 차이로 능가하는 경쟁력 있는 결과를 달성하였다. MixFormer는 더 낮은 계산 비용으로 5가지 dense prediction task에서 다른 모델들보다 훨씬 뛰어난 성능을 발휘한다. MS COCO의 Mask R-CNN(1$\times$)을 사용하면 MixFormer-B4는 Swin-T에서 2.9 box mAP와 2.1 mask mAP의 향상을 보여주는 동시에 더 적은 계산 비용을 필요로 한다. UperNet의 backbone을 대체하는 MixFormer-B4는 ADE20k에서 Swin-T에 비해 2.2mIoU의 이득을 제공한다. 또한 MixFormer는 keypoint detection과 long-tail instance segmentation에 효과적이다. 간단히 말해서 MixFormer는 효율적인 범용 ViT로서 다양한 비전 task에서 SOTA 성능을 달성하였다.
Method
1. The Mixing Block
Mixing Block은 표준 window 기반 attention 블록에 두 가지 핵심 디자인을 추가하였다. Local-window self-attention과 depth-wise convolution을 결합하는 병렬 디자인을 채택하고, 분기 간 양방향 상호 작용을 도입한다. 이는 local-window self-attention의 제한된 receptive field와 약한 모델링 능력 문제를 해결하기 위해 제안되었다.
병렬 디자인
겹치지 않는 window 내에서 self-attention을 수행하면 계산 효율성이 향상되지만 window 사이의 연결이 추출되지 않아 receptive field가 제한된다. 이전 연구들은 window 간 연결을 모델링하기 위해 shift, expand, shuffle, convolution을 사용하였다. Convolution layer가 로컬 관계를 모델링하도록 설계되었다는 점을 고려하여 window를 연결하는 유망한 방법으로 효율적인 대안인 depth-wise convolution을 선택한다.
그런 다음 attention은 local-window self-attention과 depth-wise convolution을 결합하는 적절한 방법을 채택하도록 한다. 이전 연구에서는 이 두 연산자를 연속적으로 쌓아 목표를 달성했다. 그러나 연속적인 단계에서 window 내 관계와 window 간 관계를 캡처하면 이 두 가지 유형의 관계가 덜 얽혀 있게 된다.
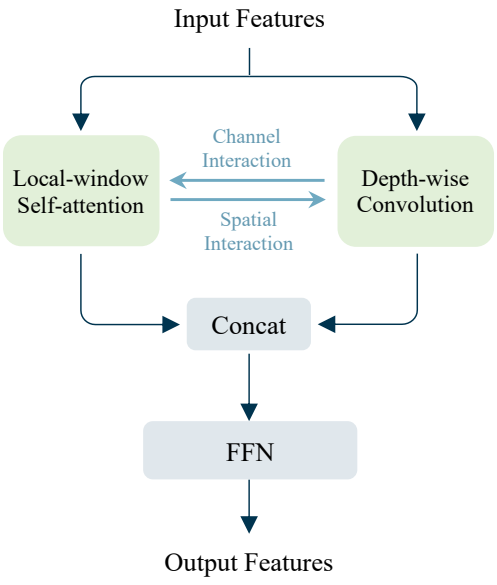
본 논문에서는 window 내 관계와 window 간 관계를 동시에 모델링하여 receptive field를 확대하는 병렬 디자인을 제안하였다. 위 그림에서 볼 수 있듯이 local-window self-attention과 depth-wise convolution은 두 개의 병렬 경로에 있다. 자세히 보면 서로 다른 window 크기를 사용한다. 이전 연구를 따라 local-window self-attention에는 7$\times$7 window가 채택되었다. Depth-wise convolution에서는 효율성을 고려하여 더 작은 커널 크기인 3$\times$3이 적용된다.

또한 FLOPs가 다르기 때문에 위 표의 FLOPs 비율에 따라 채널 수를 조정한다. 그런 다음 출력은 서로 다른 정규화 레이어로 정규화되고 concatenation을 통해 병합된다. 병합된 feature는 연속적인 Feed-Forward Network (FFN)로 전송되어 채널 전체에서 학습된 관계를 혼합하여 최종 출력 feature를 생성한다.
병렬 디자인은 두 가지 이점을 제공한다.
- Window 간 모델 연결을 통해 local-window self-attention과 depth-wise convolution을 결합하여 제한된 receptive field 문제를 해결한다.
- 병렬 디자인은 window 내 관계와 window 간 관계를 동시에 모델링하여 분기 전체에 feature를 엮을 수 있는 기회를 제공하고 더 나은 feature 표현 학습을 달성한다.
양방향 상호 작용
일반적으로 가중치를 공유하면 공유 차원의 모델링 능력이 제한된다. 이 딜레마를 해결하는 일반적인 방법은 동적 네트워크에서 수행되는 것처럼 데이터 의존 가중치를 생성하는 것이다. Local-window self-attention은 채널 전체에서 가중치를 공유하면서 공간 차원에서 즉시 가중치를 계산하므로 채널 차원에서 모델링 능력이 약한 문제가 발생한다.
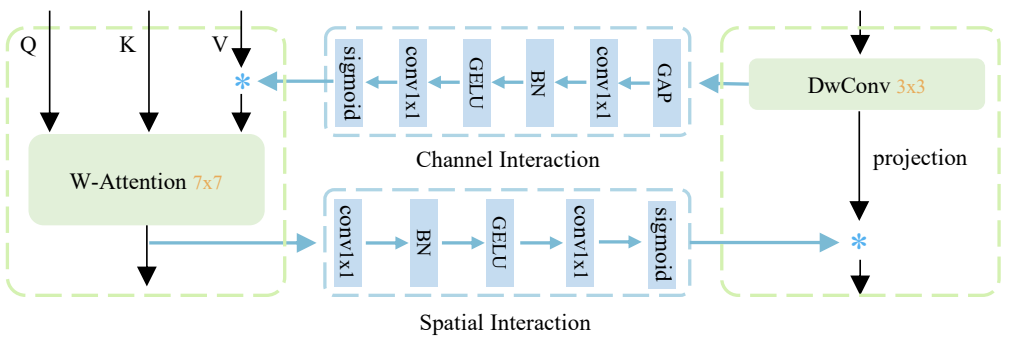
채널 차원에서 local-window self-attention의 모델링 용량을 향상시키기 위해 채널별 동적 가중치를 생성하는 것이 목표이다. Depth-wise convolution은 채널에 초점을 맞추면서 공간 차원에 가중치를 공유한다. 이는 local-window self-attention에 대한 보완적인 단서를 제공할 수 있으며 그 반대의 경우도 마찬가지이다.
따라서 본 논문은 local-window self-attention과 depth-wise convolution에 대한 채널 및 공간 차원의 모델링 능력을 향상시키기 위해 양방향 상호 작용을 제안한다. 양방향 상호 작용은 병렬 분기 간의 채널 및 공간 상호 작용으로 구성된다. Depth-wise convolution 분기의 정보는 채널 상호 작용을 통해 다른 분기로 흐르므로 채널 차원의 모델링 능력이 강화된다. 한편, 공간 상호 작용을 통해 공간 관계가 local-window self-attention 분기에서 다른 분기로 흐를 수 있다. 결과적으로 양방향 상호 작용은 서로 보완적인 단서를 제공한다.
채널 상호 작용을 위해 위 그림과 같이 SE layer의 디자인을 따른다. 채널 상호 작용에는 하나의 global average pooling layer가 포함되어 있으며, 그 뒤에 정규화 (BN)와 activation (GELU)이 있는 두 개의 연속적인 1$\times$1 convolution layer가 있다. 마지막으로 시그모이드를 사용하여 채널 차원에서 attention을 생성한다. 채널 상호 작용은 SE layer와 동일한 디자인을 공유하지만 두 가지 측면에서 다르다.
- Attention 모듈의 입력이 다르다. 채널 상호 작용의 입력은 다른 병렬 분기에서 나오는 반면 SE layer는 동일한 분기에서 수행된다.
- SE layer처럼 모듈의 출력에 채널 상호 작용을 적용하는 대신 local-window self-attention의 값에만 채널 상호 작용을 적용한다.
또한 저자들은 공간 상호 작용을 위해 두 개의 1$\times$1 convolution layer와 BN, GELU로 구성된 간단한 디자인을 채택했다. 자세한 디자인은 위 그림에 나와 있다. 이 두 레이어는 채널 수를 하나로 줄인다. 마지막으로 시그모이드를 사용하여 공간 attention map을 생성한다. 채널 상호 작용에서 했던 것과 마찬가지로 공간 attention는 local-window self-attention이 적용되는 다른 분기에 의해 생성된다. 이는 depth-wise 3$\times$3 convolution보다 더 큰 커널 크기 (7$\times$7)를 가지며 공간 차원에 초점을 맞춰 depth-wise convolution 분기에 대한 강력한 공간적 단서를 제공한다.
Mixing Block
위의 두 가지 디자인 덕분에 local-window self-attention의 두 가지 핵심 문제를 완화했다. 이를 통합하여 표준 window attention block 위에 새로운 transformer 블록인 Mixing Block을 구축한다. Mixing Block은 병렬 디자인, 양방향 상호 작용, Feed-Forward Network (FFN)로 구성된다. 이는 다음과 같이 공식화될 수 있다.
\[\begin{aligned} \hat{X}^{l+1} &= \textrm{MIX} (\textrm{LN} (X^l), \textrm{W-MSA}, \textrm{CONV}) + X^l \\ X^{l+1} &= \textrm{FFN} (\textrm{LN} (\hat{X}^{l+1})) + \hat{X}^{l+1} \end{aligned}\]여기서 MIX는 W-MSA (Window-based Multi-Head Self-Attention) 분기와 CONV (Depth-wise Convolution) 분기 간의 feature 혼합을 달성하는 함수를 나타낸다. MIX 함수는 먼저 두 개의 linear projection layer와 두 개의 norm layer를 통해 입력 feature를 병렬 분기로 project한다. 그런 다음 feature를 혼합한다. FFN의 경우 간단하게 유지하고 두 개의 linear layer와 그 사이에 하나의 GELU로 구성된 MLP인 이전 연구들을 따른다. 또한 저자들은 PVTv2와 HRFormer에서 수행된 것처럼 depth-wise convolution을 추가하려고 시도하였지만 이는 MLP 디자인에 비해 많은 개선을 제공하지 않았다. 따라서 블록을 단순하게 유지하기 위해 FFN에서 MLP를 사용한다.
2. MixFormer
전체 아키텍처

저자들은 Mixing Block을 기반으로 pyramid feature map을 사용하여 효율적이고 범용적인 ViT인 MixFormer를 설계하였다. 다운샘플링 비율이 각각 {4, 8, 16, 32}인 4개의 stage가 있다. MixFormer는 stem layer와 downsampling layer 모두에서 convolution layer를 사용하는 하이브리드 ViT이다. 게다가 stage 끝 부분에 projection layer를 도입했다. Projection layer는 classification head 앞의 채널에서 더 많은 디테일을 보존하는 것을 목표로 linear layer와 activation layer를 사용하여 feature의 채널을 1280으로 늘린다. 이는 classification에서 더 높은 성능을 제공하며 특히 작은 모델에 잘 작동한다. MobileNet과 EfficeintNet과 같은 이전의 효율적인 네트워크에서도 동일한 디자인을 찾을 수 있다. MixFormer의 스케치는 위 그림에 나와 있다.
아키텍처 변형
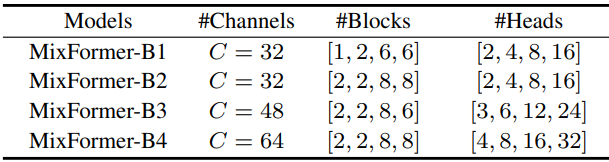
저자들은 각 stage의 블록을 수동으로 쌓고 계산 복잡도가 0.7G (B1)에서 3.6G (B4)에 이르는 다양한 크기의 여러 모델 형식을 지정하였다. 여러 stage의 블록 수는 마지막 두 stage에 더 많은 블록을 넣는 방식으로 설정된다. 모델들은 위 표의 세부 설정을 따른다.
Experiments
- 데이터셋: ImageNet-1K, MS COCO, ADE20k
1. Image Classification
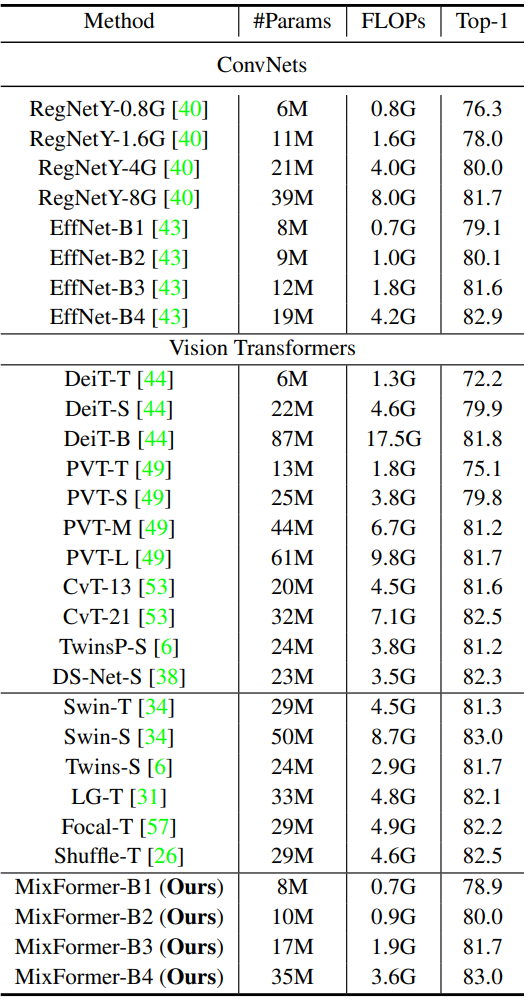
다음은 ImageNet validation set에서의 분류 정확도이다.
2. Object Detection and Instance Segmentation
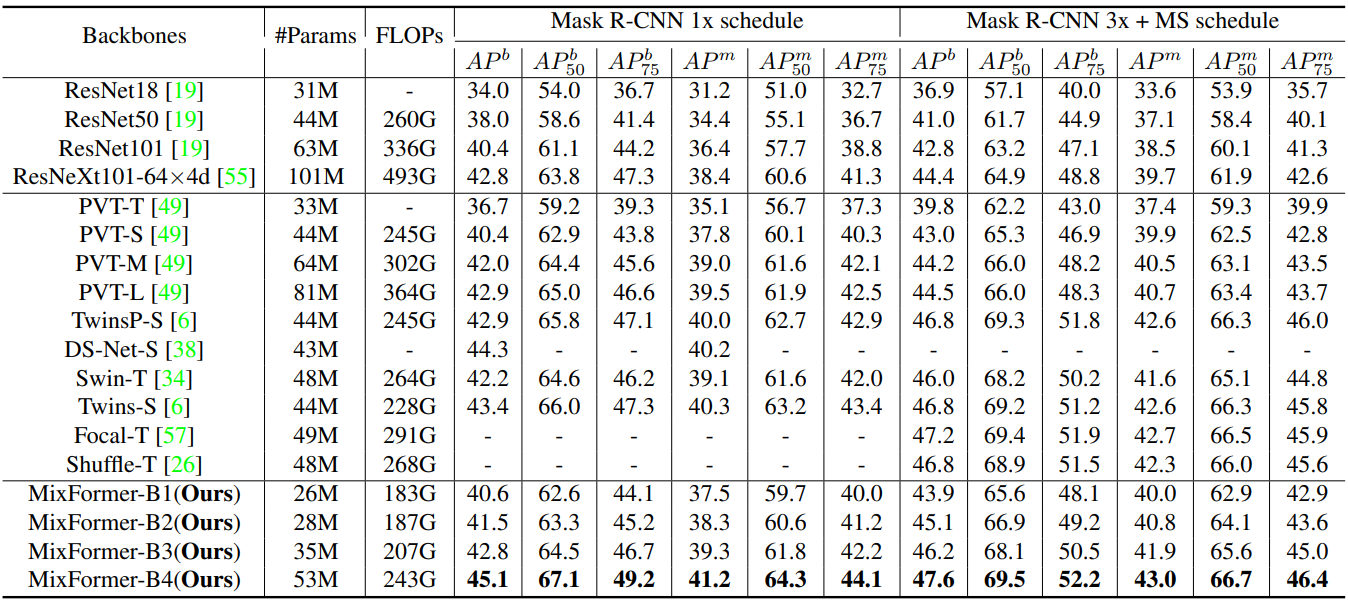
다음은 Mask R-CNN를 사용한 COCO detection 및 segmentation 결과이다.
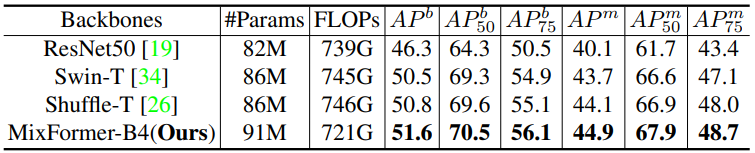
다음은 Cascade Mask R-CNN를 사용한 COCO detection 및 segmentation 결과이다.
3. Semantic Segmentation
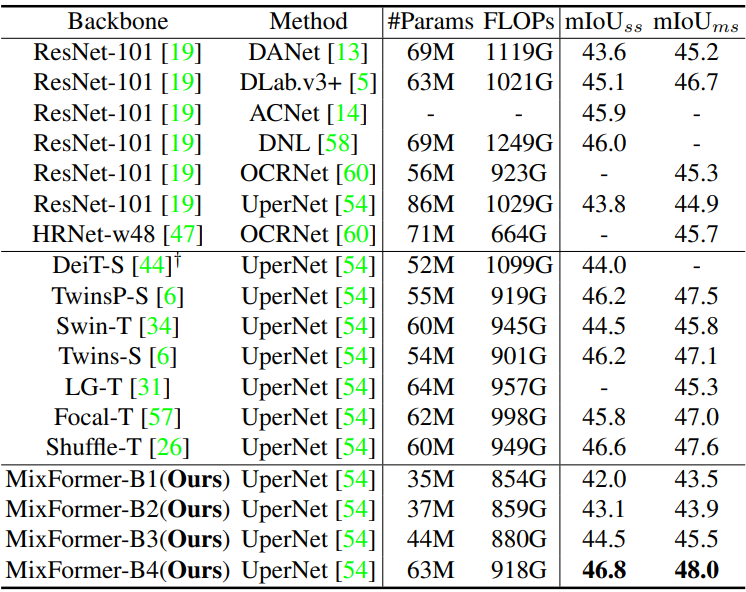
다음은 ADE20K semantic segmentation 결과이다.
4. Ablation Study
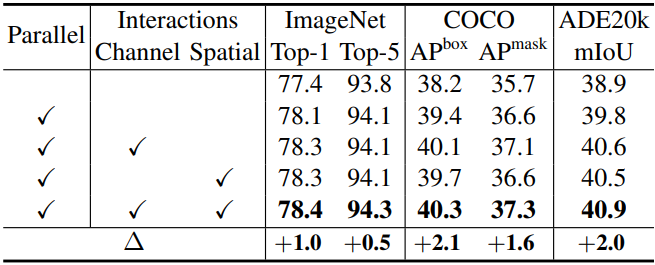
다음은 양방향 상호 작용을 사용한 병렬 디자인에 대한 ablation 결과이다.
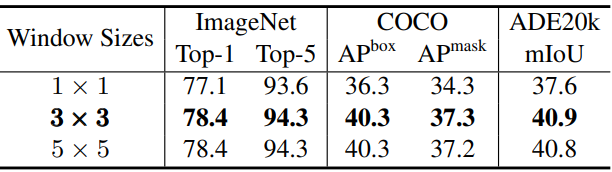
다음은 depth-wise convolution의 window 크기에 대한 ablation 결과이다.
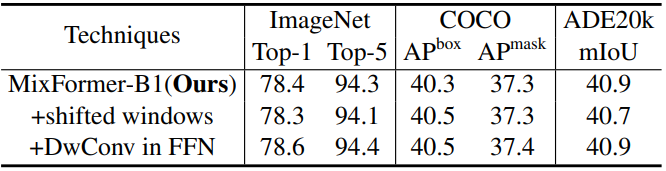
다음은 다른 테크닉에 대한 ablation 결과이다.
다음은 stage들의 블록 수에 대한 ablation 결과이다.

5. Generalization
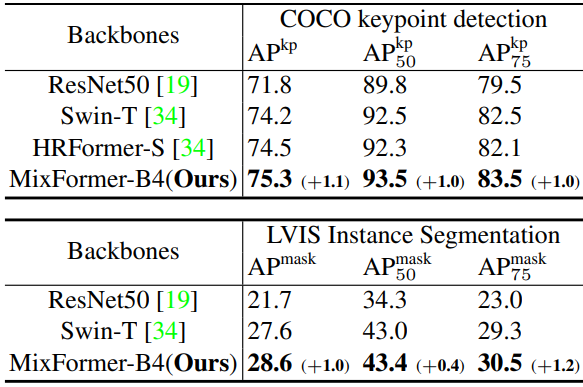
다음은 추가 다운스트림 task에 대한 결과이다.
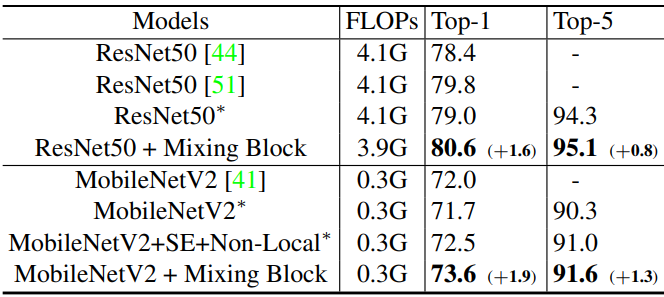
다음은 ConvNets애 Mixing Block을 적용한 결과이다. (ImageNet-1K)
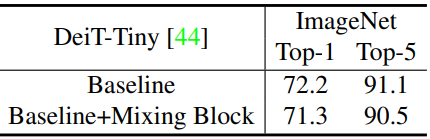
Limitations
MixFormer는 local-window self-attention 문제를 완화하기 위해 제안되었다. 따라서 본 논문에서는 window 기반 ViT로 제한될 수 있다. 병렬 디자인과 양방향 상호 작용이 글로벌 self-attention에 적용될 수 있지만 얼마나 많은 이득을 가져올 수 있는지는 확실하지 않다. 저자들은 DeiT-Tiny에 대한 간단한 실험을 수행하였다. 그러나 결과는 위 표와 같이 약간 악화된다. Mixing Block은 글로벌 attention에 적용하기 위해서는 더 많은 연구가 필요하다.