[논문리뷰] MFIM: Megapixel Facial Identity Manipulation
EVCA 2022. [Paper]
Sangheyon Na
Kakao Brain
Introduction
Face-swapping 모델은 두 가지 목표를 가지고 있다.
- 고품질 이미지를 생성해야 한다.
- Source 이미지에서 target 이미지로 얼굴 모양 등의 ID 속성을 잘 옮겨야 한다.
고품질 이미지를 위해서 pre-trained StyleGAN을 사용하여 GAN inversion 방식으로 이미지를 생성한다. Facial attribute encoder라는 인코더를 설계하여 source 이미지에서 ID representaton를 추출하고 target 이미지에서 ID와 무관한 representaton을 추출한다. 이러한 representaton들을 pre-trained StyleGAN generator에 넣어 representaton을 혼합하고 고품질의 megapixel face-swapped image를 생성한다.
기본적으로 facial attribute encoder는 기존의 StyleGAN 기반의 GAN inversion 인코더와 비슷하게 style code를 추출한다. Face-swapping에서 중요한 것 중 하나는 표정이나 배경과 같은 target 이미지의 디테일을 정확하게 재구성해야 한다는 것이다. 그러나 공간 차원이 없는 ID-irrelevant style code는 target 이미지의 디테일을 보존하지 못할 수 있다. 따라서 face attribute encoder는 style code뿐만 아니라 target 이미지에서 공간 차원을 갖는 style map도 추출한다. 공간 차원을 활용하는 style map은 target 이미지의 디테일에 대한 추가 정보를 전파하여 ID-irrelevant style code를 보완할 수 있다. 결과적으로 style code와 style amp을 추출하는 face attribute encoder는 source 이미지의 ID 속성과 target 이미지의 디테일을 포함한 ID-irrelevant 속성을 효과적으로 포착할 수 있다. Pre-trained StyleGAN을 활용하는 이전 모델인 MegaFS는 style code만 사용하기 때문에 target 이미지의 디테일을 재구성하는 데 어려움을 겪는다. MegaFS는 이 문제를 해결하기 위해 segmentation label을 사용하여 target 이미지에서 디테일을 가져온다. 반면, MFIM는 segmentation label을 사용하는 대신 style map을 추출하여 이 문제를 해결한다.
효과적인 ID 변환을 위해 다양한 얼굴 속성을 포착할 수 있는 3DMM (2D 이미지로부터 3D parameter를 추출하는 모델)을 활용한다. 특히 identity를 인식하는 중요한 요소 중 하나인 얼굴형의 변화에 주목한다. 그러나 이 두가지 목표가 상충되기 때문에 target 이미지의 ID-irrelevant 속성을 동시에 유지하면서 얼굴 형태를 변형하는 것은 어렵다. 생성된 이미지를 원본 이미지와 동일한 얼굴 모양으로 만들면 생성된 이미지가 target 이미지와 많이 달라지고, 반대로 target 이미지의 ID-irrelevant 속성을 유지하면 target 이미지와 유사하게 된다.
이 상반된 두 목표를 동시에 달성하기 위해 주어진 이미지에서 모양, 포즈, 표정과 같은 다양한 얼굴 속성을 정확하고 명확하게 포착할 수 있는 3DMM을 활용한다. 특히, 3DMM을 사용하여 원하는 속성, 즉 source 이미지와 동일한 얼굴 모양이지만 target 이미지와 동일한 포즈와 표정을 가진 face-swapped 이미지를 생성하도록 모델을 학습시킨다. MFIM은 target 이미지의 ID-irrelevant 속성을 유지하면서 얼굴 모양을 잘 변형할 수 있다. 3DMM을 사용하는 HiFiFace의 경우 3DMM을 학습뿐만 아니라 inference에서도 사용하지만, MFIM은 3DMM을 inference에 사용하지 않는다.
추가로, 저자들은 ID mixing이라는 새로운 task를 제안하였다. ID mixing은 여러 source image로부터 생성한 새로운 identity와 face-swap을 하는 것이다. 여기서 저자들은 사용자가 ID 생성 과정을 의미적으로 제어할 수 있는 방법을 설계하는 것을 목표로 한다. 예를 들어, 하나의 source 이미지에서는 얼굴 모양을 추출하고 다른 source 이미지에서는 눈 모양을 추출하여 혼합한 새로운 ID를 생성하는 것이다.
MFIM: Megapixel Facial Identity Manipulation
1. Facial Attribute Encoder
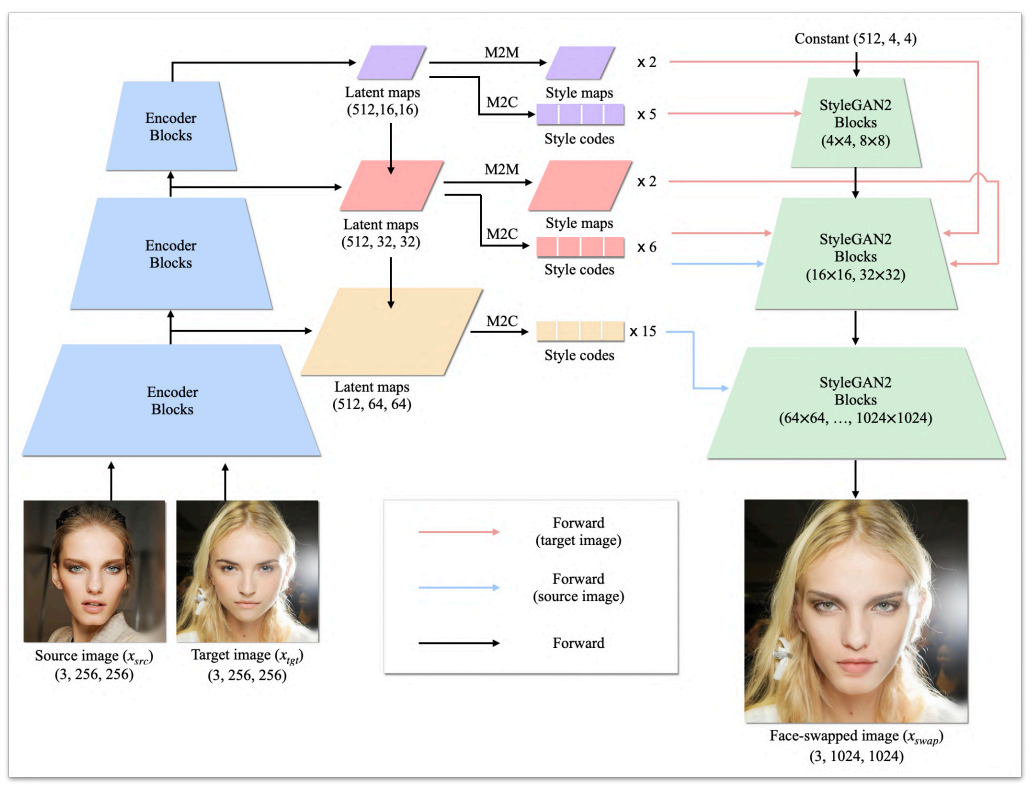
Facial attribute encoder의 구조는 위와 같다. 먼저 pSp 인코더와 같이 주어진 이미지로부터 hierarchical latent map들을 뽑는다. 그런 다음 map-to-code(M2C) 블럭과 map-to-map(M2M) 블럭으로 style code와 style map을 각각 생성한 뒤 pre-trained StyleGAN generator에 입력한다.
Style code
Facial attribute encoder는 주어진 이미지를 latent space $\mathcal{S}$로 매핑하여 style code 26개를 추출한다. Coarse resolution (4x4 ~ 16x16)에 해당하는 style code는 target 이미지 $x_{tgt}$로부터 추출되며 전체 구조나 포즈같은 전체적인 측면을 합성한다. 반대로 fine resolution (32x32 ~ 1024x1024)애 해당하는 style code는 source 이미지 $x_{src}$로부터 추출되며 얼굴 모양, 눈, 코, 입술과 같은 상대적으로 국소적인 측면을 합성한다. 이러한 관점에서 $x_{tgt}$로부터 추출된 style code를 ID-irrelevant style code, $x_{src}$로부터 추출된 style code를 ID style code라 부른다. 한편, target 이미지의 디테일(표정, 배경 등)을 재구성하는 것이 중요하지만 ID-irrelevant style code는 공간 차원이 없기 때문에 이러한 디테일을 잃는다.
Style map
$x_{tgt}$의 디테일을 보존하기 위하여 인코더에서 $x_{tgt}$로부터 공간 차원을 가지는 style map을 추출한다. 구체적으로, 인코더의 M2M 블럭들이 입력되는 latent map과 동일한 크기의 style map을 생성한다. 그런 다음 이 style map들이 noise input으로 pre-trained StyleGAN generator에 입력되어 미세한 디테일들을 생성한다.
2. Training Objectives
ID loss
$x_{swap}$이 $x_{src}$와 같은 identity를 가져야 하기 때문에 ID loss를 cosine similarity로 계산한다.
\[\begin{equation} \mathcal{L}_{id} = 1 - \cos (R(x_{swap}), R(x_{src})) \end{equation}\]($R$은 pre-train된 얼굴 인식 모델)
Reconstruction loss
ID와 관련된 영역을 제외하고는 $x_{swap}$이 $x_{tgt}$와 비슷해야 한다. 이 제약을 부과하기 위해 픽셀 수준 L1 loss와 LPIPS loss를 채택하여 다음과 같이 reconstruction loss를 정의한다.
\[\begin{equation} \mathcal{L}_{recon} = L_1 (x_{swap}, x_{tgt}) + LPIPS (x_{swap}, x_{tgt}) \end{equation}\]Adversarial loss
$x_{swap}$을 현실적으로 만들기 위해서 non-saturating adversarial loss와 R1 regularization을 사용한다.
3DMM supervision
$x_{src}$와 동일한 얼굴 모양, $x_{tgt}$와 동일한 포즈 및 표정을 갖도록 $x_{swap}$을 강제해야 한다. 이러한 제약 조건에 대해 3DMM을 사용하여 다음과 같은 loss를 정의한다.
\[\begin{equation} \mathcal{L}_{shape} = \| s_{swap} - s_{src} \|_2 \\ \mathcal{L}_{pose} = \| p_{swap} - p_{tgt} \|_2 \\ \mathcal{L}_{exp} = \| e_{swap} - e_{tgt} \|_2 \\ \end{equation}\]$s$, $p$, $e$는 3DMM의 인코더에서 추출한 얼굴 모양(shape), 포즈(pose), 표정(exp) 파라미터이다. 이와 같이 3DMM은 학습 과정에서 loss 계산을 위해서만 사용되면 inference에서는 사용되지 않는다.
Full objective
전체 loss $\mathcal{L}$은 다음과 같다.
\[\begin{aligned} \mathcal{L} = & \; \lambda_{id} \mathcal{L}_{id} + \lambda_{recon} \mathcal{L}_{recon} + \lambda_{adv} \mathcal{L}_{adv} + \lambda_{R_1} \mathcal{L}_{R_!} \\ & + \lambda_{shape} \mathcal{L}_{shape} + \lambda_{pose} \mathcal{L}_{pose} + \lambda_{exp} \mathcal{L}_{exp} \end{aligned}\]3. ID Mixing
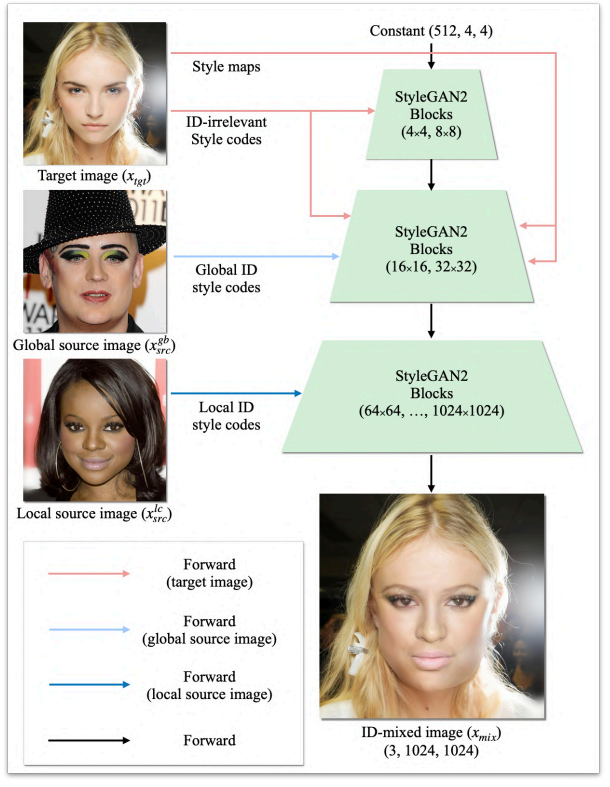
ID Mixing으로 사용자가 ID 생성 과정을 semantically control 할 수 있도록 여러 source 이미지로부터 ID style code를 뽑아 섞는다. 위 그림에서는 2개의 source 이미지로부터 ID mixing을 하지만 여러 source 이미지를 사용하는 것으로 일반화할 수 있다. 2개의 source 이미지를 사용하는 경우, 사용자는 하나의 source 이미지로부터 global ID 속성을 가져오고 다른 source 이미지로부터 local ID 속성을 가져와 섞은 뒤 ID-mixed 이미지 $x_{image}$를 합성할 수 있다.
위 그림에서는 ID-irrelevant style code와 style map을 $x_{tgt}$에서 추출하고, ID style code를 global source 이미지 $x_{src}^{gb}$와 local source 이미지 $x_{src}^{lc}$에서 추출하였다. Global ID style code는 coarse resolution에서 사용되며 local ID style code는 fine resolution에서 사용된다.
Experiments
- Baseline: Deepfakes, FaceShifter, Sim-Swap, HifiFace, InfoSwap, MegaFs, SmoothSwap
- Dataset: FFHQ (train), FaceForensics++ & CelebA-HQ (evaluation)
- Evaluation metric
- identity, shape, expression: 얼굴 인식 모델의 feature space에서의 $L_2$ 거리
- pose: 3DMM의 파라미터 space에서의 $L_2$ 거리
- posh-HN: pose 예측 모델의 feature space에서의 $L_2$ 거리
다음은 CelebA-HQ에 대한 결과이다.

FaceForensics++와 CelebA-HQ에 대한 정량적 비교는 다음과 같다.
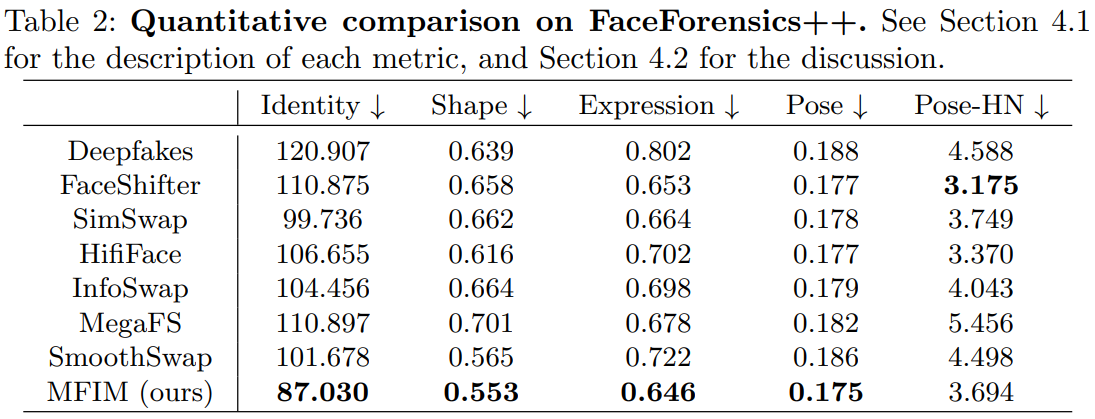

다음은 baseline들과의 정량적 비교이다.

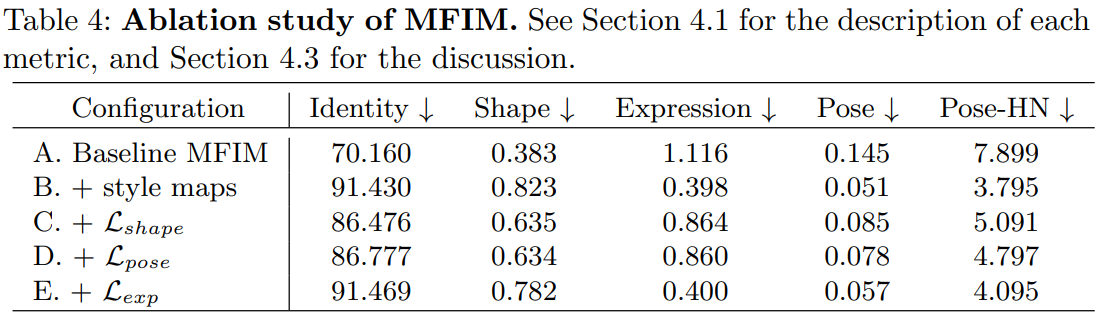
Ablation Study

ID Mixing